SQL Change Automation: Adding SQL Clone to the Mix
Tony Davis explores how SQL Change Automation is increasingly providing ways of working with SQL Clone, to improve the quality of testing for database changes. With SCA v4.3, developers can now use the SSMS plugin to create a clone of the target database, to be used as a reference database, or baseline, for the deployment project.
SQL Change Automation can support whatever approach you use for your database development and deployment work. You can choose the state-based approach, allowing the use of CREATE scripts for each object, or the migrations-based approach, based on change scripts that modify existing tables with ALTER statements, or the hybrid approach, using state for development and migrations for deployments.
SCA inhabits the middle-ground, in that it deals with the chores that are common to all methods of developing and deploying databases, and so are essential whatever methodology is adopted by the development team. For example, SCA’s development add-ins for Visual Studio (VS) or SQL Server Management Studio (SSMS) help you manage the database source, and all associated scripts, which then provide an auditable record of the changes. These tools, along with the SCA PowerShell cmdlets, allow you to manage and automate a deployment pipeline that involves tests, checks and other team processes that are required to support continuous integration and rapid delivery.
Although SCA deals with the deployment process, it is designed to work together with SQL Clone as a database provisioning tool. Both tools can be automated by PowerShell cmdlets to work cooperatively together, and SCA is increasingly providing ways of using SQL Clone directly, via its GUI add-ins. Together, they can provide a way of assisting the whole range of requirements that database developers have, from testing migration scripts against realistic data, prior to deployment, to running all manner of unit, integration and other tests, during the development phase.
This article explains why and when the use of SQL Clone technology, in combination with SQL Change Automation, makes things easier for all these basic requirements.
Using a clone as a ‘baseline’ in the migration-based approach
A database developer will find SCA-Clone integration very useful during the development of a new version of a database, for unit testing, and whatever integration tests are done before check-in (covered later in the article), but it is perhaps most valuable for testing the migration scripts that ensure that data is preserved, when the production system is altered to bring it up to the new version.
When you create a migrations-based SCA project, using the VS or SSMS development add-ins, it is a best practice to create a ‘baseline’ for the project, essentially a reference database that represents the currently released version of the database as closely as possible. This provides the starting point for generating subsequent change (migration) scripts, and SCA also uses it for other tasks, such as to set up a build database for CI, and ultimately to verify that the migrations scripts will deploy correctly to the nominated target database, and that the target has not ‘drifted’.
In SCA versions prior to v4.3, the supplied reference database was used to generate a ‘baseline’ script that represented the state of the target schema. Now, SCA’s add-in to SSMS can use SQL Clone to create the reference database, or baseline.
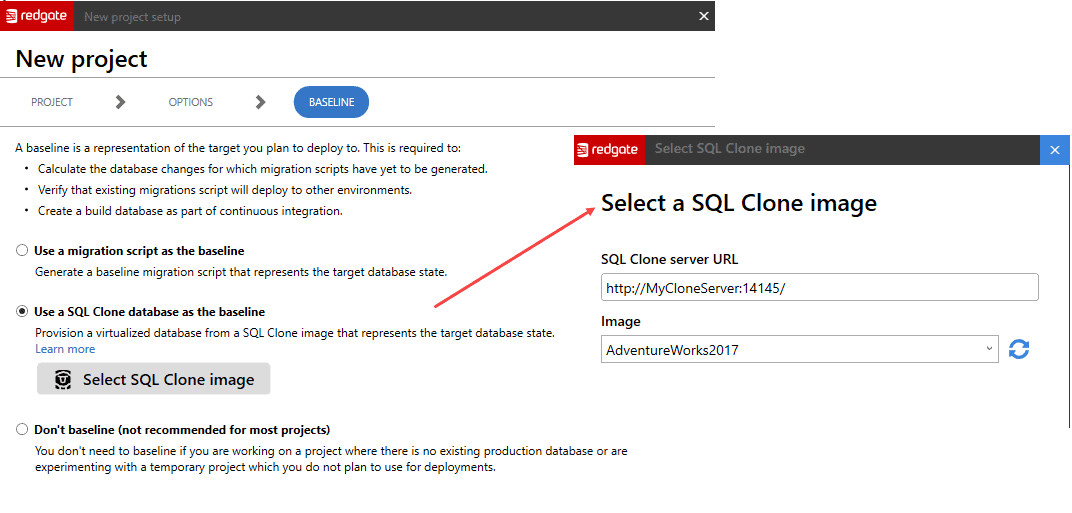
See this tutorial for full details, but in short we simply supply the address of the SQL Clone Server and the name the image, taken from the currently released version of the database, and SQL Clone will deploy a clone of this database to the development server, and SCA will use the clone as the ‘baseline’.
Therefore, instead of SCA needing to build a copy of the reference database from a baseline script, which sometimes causes issues for complex databases with cross-dependencies on others, it can simply reference a fully functioning clone database, complete with data. As well making it easier to baseline a complex database, using a clone has many other advantages, during development, testing and deployment, as described in the Using a SQL Clone image as a baseline section of the documentation.
Perhaps the most striking advantage is that, with a Clone, developers can verify their migration scripts on a copy of the currently released database, fully stocked with data. This is a much more effective way to test, repeatedly, that schema migrations, such as a table split or column renaming, or datatype change, correctly preserve the existing data.
In rare cases, you can create the SQL Clone image from a copy of the current production data, although for thorough testing you still may choose to add in the known ‘breakers’ that test people love to put into the test data for a person database such as a Mr. Null or Mrs. O’Brien. If a database must be pseudonymized before use, it can get more complicated, but here SQL Clone comes to the rescue with an interface into Data Masker. This allows you to create a pseudonymized or anonymized clone image directly from a production backup, without human intervention.
The image on which the baseline clone is created can be refreshed regularly, so that its data remains as representative as possible of the real production data, for accurate testing.
Testing changes during development
Whatever methodology a database development team uses, the unit and integration tests are both essential and tricky to do. They often involve creating a database at a particular version, running the test, assessing the result and then tearing it down when you’ve finished. Because these tests are difficult to set up accurately and are tedious to perform, it is tempting for the team to neglect them in favor of more ‘visible’ activities due to time pressure.
For general database testing, they will often create the reference database as a ‘de-productionized’ copy of the currently released version, stocked with realistic data. As development progresses, they can automate delivery of the current build using SCA, stocking it with generated data using a tool such as SQL Data Generator, then test it.
By creating a clone of this latest build, a developer can repeatedly make changes to their local clone, without affecting the work of others, and have these changes scrubbed clean away almost instantly. It also allows the team to set up several copies of a large database, using a single network file image to hold the actual database data. If you decide to change a clone of this image, the changes are held locally to the server hosting the clone but does not change the image. Each clone can be changed but, with a simple operation, will revert to the image. You can spawn many clones, or you can use a single clone as a punchbag, hitting it repeatedly but having it spring back to its original form. All of this, of course, can be automated via PowerShell.
For testing migrations scripts that affect existing data, during development, you need the current build of the release candidate, and two clones of the reference database. You apply the migration script to one of the clones, leaving the other as a reference to check that the migration worked properly. Then, first, you check that the resulting database really is at the new version by comparing the metadata of the reference version with that of the release candidate. Next, you ensure that the data is preserved, after the schema refactoring, by running queries on each of the clones. The queries will be different (due to the refactoring) but they should still produce an identical result. With SQL Clone it is the work of a moment to recreate a fresh clone, after testing the migration script, as part of the tear-down of the test after every test run.
Advanced problems: database variants
With some PowerShell automation, a combination of SCA and SQL Clone can open new possibilities that aren’t otherwise realistic. For example, one can deal with the classic database problem of having many variants of each release.
Sometimes, a database has special variants. A classic example is that of a payroll database that must operate in several legislative and tax areas. The same could apply to banking or other financial applications. There is a fundamental database with all the common data structures and routines that is developed, maintained, and tested as normal. However, there might be ten versions for ten different countries. How do you organize development?
This can be effectively developed as a trunk development for the fundamental database, stored as static scripts, but with ten different migration scripts that are used to change the database to each variant. The Payroll system for each country or region can be built by applying a migration script to the built trunk database. Unless you are making significant changes, the migration scripts will change only slightly between releases, and every change to the trunk system will also be in the build of the specific release, unless the migration script specifically removes objects.
One problem with this arrangement would come with a developer who specializes in maintaining a single aspect that is different in each legislative area, such as international shipping regulations. Developers who must work with several variants concurrently need to be able to move between the variants rapidly and test or compare each one.
SQL Clone can allow all variants to be stored as images and be cloned as required. The application build process would build the database once and then create each variant by creating a clone of the trunk development before applying the migration scripts and then saving it as an image of the variant. The result of the build would be the ten variants. The appropriate variant can be cloned from its image ‘on-demand’.
Where the database development team requires a more conventional approach based on source control branches, this too can be accommodated by the use of SQL Clone, by creating a development database for each branch, updating the build on every commit.
Conclusions
SQL Change Automation and SQL Clone, used together, allow database developers to do the things that they wanted to do but couldn’t, because they were constrained by the size of the task, using the available tools. It was not just about building a database, checking the version and the integrity of the build, running routine tests, encapsulating a database release in a NuGet package and so on. It is also about provisioning servers, creating databases, running repeated destructive tests on a database, ensuring they are at the correct version, anonymizing data, and all the other chores that are part of the work of rapidly and reliably releasing new features and improvements to production databases.
Keen to learn more? Check out the following resources:
- Development and testing with Clones (product articles)
- How Clones enable fast onboarding for Database DevOps (webinar)
- Getting started with SQL Change Automation with Migrations (online videos)
Tools in this post
You may also like
-

Article
Database Development with GitHub
How can you use GitHub to do team-based database development? This article proposes a process that splits development work into task-based GitHub branches, incorporates daily database builds and integration testing, and uses Redgate tools to automate tasks such as provisioning, database scripting, and testing.
-

Article
Why is my clone so small?
How is it possible that the cloned databases could be so small and lightweight, and yet behave exactly like any normal database, complete with all the data? It sounds like magic, but it's not. It simply makes clever use of native Windows virtualization technology.
-
Article
Cloning all the Databases on a Server
Phil Factor shows uses SQL Clone and PowerShell to automatically create images of all databases on an instance, if they don't already exist, and then create or refresh clones of each one, on all your development servers.
-
Article
SQL Clone on your Laptop
Phil Factor provides a PowerShell script to disconnect your laptop without risking error 21, if you're working with SQL Clone and need to go offline. The same script will then bring the clone database back online smoothly, once you're reconnected.
-

Article
The Database DevOps Challenges SQL Provision Solves
SQL Provision helps to accelerate the delivery of database changes, by enabling an organization to provide database copies, and the right data, to all parts of the deployment pipeline that need it, with a light footprint, and securely. Tony Davis explains how.