





How SQL Clone and SQL Change Automation enable seamless Database Branch Switching
Creating a development database for each branch
Over the past 10 years Git has become the most widely adopted version control software. Its distributed nature allows developers to create local branches of their code instantly and share changes simply. Branches make it easy to manage multiple streams of work in parallel and try out different approaches to solving a problem. Branching is fast and straight forward if all you need is the application code, but if you want each branch to have test data attached to it, life quickly becomes complicated.
Learn more about database branching
This article requires a basic understanding of branching. If you're new to the topic a good place to start is this Simple-Talk article by Tony Davis: Database Branching and Merging Strategies
SQL Change Automation and SQL Source Control enable development databases to be linked to a branch in the source code repository, so the team can manage merging and committing any changes. However, the process of linking a copy of the database to each branch carries significant overhead (time to restore, disk space, extra workload for the DBA and so on), especially if multiple local branches exist at the same time. Since SQL Server doesn't allow for multiple databases with the same name to exist in the same instance, provisioning multiple copies of the same database to enable one per branch would also require them to be installed in a different instance (or all on the same instance with different names), with each linked to the correct branch in version control.
However, if development teams use SQL Clone they can create virtual database copies that will be automatically created and linked to any Git branch, without requiring multiple instances or databases to be renamed. Clones are full copies of their source database that can be developed against and used for testing, but because they're a fraction of their original size (around 50MB each), they're fast to create and take up very little local disk space. This means that developers can create branches containing both a copy of the application code and a full copy of the production database in seconds simply by using Git commands or a GUI such as Tortoise Git.
Why create database branches?
There are many examples of why you'd want to branch your database like you do your application code. Here are just a few:
- You're working on some refactoring to improve performance in your local copy of the database but then must respond to an urgent fix. You don't want to commit the refactoring work to the repository just yet, but instead pause the current state and create a new branch, complete with a dataset mirroring production to test with, to make the fix.
- During the development of a new feature you've uncovered a couple of different ways to address a performance issue that you'd like to test out on different branches containing the same production-like dataset.
- You need to maintain multiple customer-specific variants of a standard code base.
Overview of SQL Clone branch switching
SQL Clone 4.4 and SQL Change Automation 4.2, together with the capability of Git to invoke commands on specific events (Git hooks), makes creating and switching branches seamless, providing new levels of flexibility in your software development process. The team develop the database using a SQL Change Automation project, which in turn uses SQL Clone to create full copies of each development database for each piece of work, and switch between them automatically when changing branch in Git.
How to get started
You can find a full demo of how it works in Getting Started with Automatic Database Branch Switching.
Briefly, it relies on a simple Git hook called post-checkout, which is invoked immediately after the Git checkout command is issued, to switch to a different branch, or to create a new branch and switch to it, in a single step. The hook script simply opens a PowerShell session and executes a clone-branch.ps1 script, which we also provide. This PowerShell script uses the SQL Clone API to create a dedicated development database, a clone (called MyClone, say), specifically for the current branch (master, for example). It applies any commits in that branch that don't exist in the clone, so that it represents the exact state of the branch.
A developer can make changes to MyClone and commit them to master, and then switch to a different branch, such as the Hotfix branch. This invokes the Git hook, and SQL Clone saves a copy of the clone for the master branch (it renames it, let's say to MyClone_master), creates a new clone for the Hotfix branch called MyClone and aligns its state with the state of the Hotfix branch.
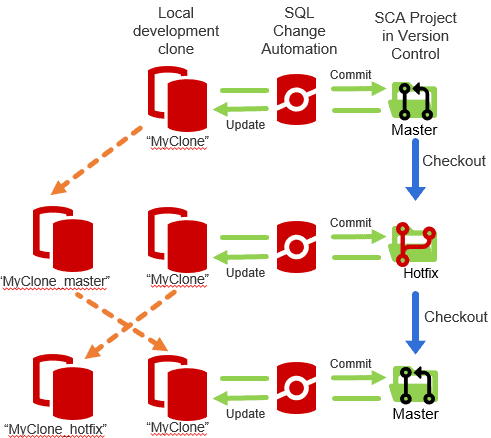
When the developer switches back to the master branch, SQL Clone saves a copy of the clone for the Hotfix branch (MyClone_hotfix) and renames MyClone_master back to MyClone, where all the developer's committed changes on that branch, and all the data, will be preserved.
By persisting the name of a database, the same database connection string will be available regardless of which branch you're on. This means you don't need to reconfigure your application code depending on which branch you're on.
SQL Clone maintains the link between branch and associated development database, irrespective of how many branches and copies of the database exist locally, so you'll be able to create and switch branches in your SQL Change Automation project as freely as you like without the need to manage multiple instances, rename databases or worry about local disk space.
Conclusion
By using Git hooks together with SQL Clone, switching database branches becomes as quick and easy as branching your code. As SQL Clone enables multiple copies of the same database to exist on a single instance, developers can set up a work environment that lets them switch branches with automatic synchronization between version control and development database, so multiple features and branches can be worked on simultaneously.
Learn more about SQL Clone and how it can enhance your development processes.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Deploying and Reverting Clones for Database Development and Testing
Demonstrating how to use PowerShell automation to create a suite of clones, for testing or development work, with the ability to revert a clone to its original state, instantly, ready for the next set of tests to begin.

Article
Questions about SQL Change Automation that you were Too Shy to Ask
Phil Factor takes on tricky SQL Change Automation questions about database builds, migrations, deployments and releases.

Article
Getting Started with Database Development Using SQL Provision
Steve Jones shares how he migrates his existing development databases to clones, using SQL Provision and a simple PowerShell function.

Article
SQL Server Database Deployment: What Could Go Wrong?
Phil Factor tackles the tricky questions you will need to answer when deciding how to automate your SQL Server database builds and deployments with Redgate's development, version control and deployment tools.
Article
Bringing DevOps to the database – Moody’s Analytics and SQL Clone
Moody's Analytics had a constant need to provision database copies, particularly for the Test Engineers who needed to run multiple daily database integration and acceptance tests. SQL Clone reduced the time taken to deploy a database copy to minutes, instead of hours.
Article
SQL Provision adds fully integrated data masking
Karis Brummit announces SQL Provision, which combines SQL Clone's fast, lightweight database copying and centralized management of provisioning, with Data Maskers's ability to obfuscate sensitive or personal data, prior to distribution.
Loading comments...