





Getting Started with Automatic Database Branch Switching
A team of developers who need to work on different features of a database often need to separate and coordinate the various stands or work, in a way that minimizes the likelihood of different developers making overlapping and conflicting changes. A version control system like Git, or any other, allows the team to split the various strands of the development work into different branches. For example, teams might create various feature branches or create one branch per customer when they need to maintain several customer-specific variations of the same database.
However, in order to work on and test features in different branches, it would normally require the developer to create multiple local copies of the database, in development, each one named differently, according to the branch for which it was created. The team would also need to put in place mechanisms to ensure that each local copy could only be updated from, or commit changes to, the correct branch in the version control system. This can be time consuming and error prone and becomes logistically difficult if each developer needs many copies of a large database.
In this article, I'll show how, with a little bit of preparation and utilizing the existing functions in SQL Change Automation, SQL Clone and Git, you can set up a fast, lightweight way to supply a development environment with all required database copies. The team will be able to work on different features in different branches in the repository, and switch between them, while their development database automatically remains in sync with the state of the branch to which it's currently associated.
The problem of synchronizing the version control repository with the development database
When developing database using SQL Change Automation, in SSMS (or Visual Studio), each developer might work on their own local development copy of the database, and use SCA to commit changes to their local repository and push them to the remote, shared repo, as well as to pull changes made by others, and then update their local development databases to reflect them.
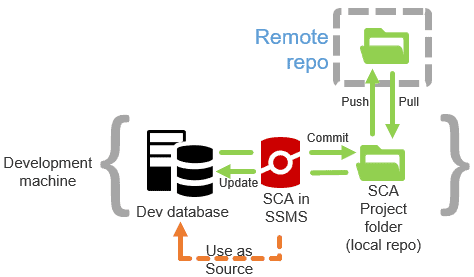
In SQL Change Automation, the logical connection from the SCA project in the repository to the development database is defined by the database name. If you change the name of a database in SQL Server, this connection gets broken. Likewise, if you provide a new database with a name from an existing connection, this link will be established.
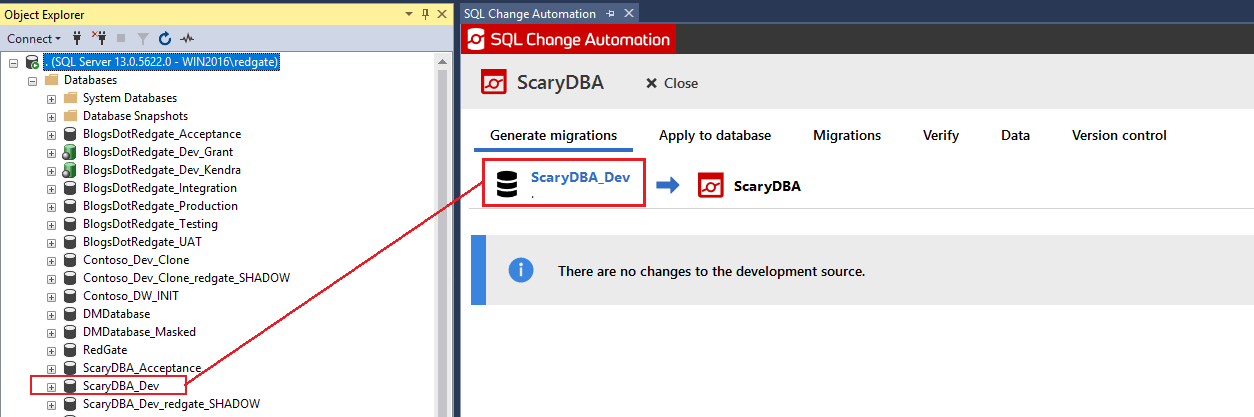
The following screenshot shows what this looks like in SQL Change Automation, where a development database called ScaryDBA_Dev is the source database for a SCA project called ScaryDBA, which in turn links to a branch in the Git repository (you will see this link in the Version control tab).
This all works fine if the team are all working on a single branch (master, say). However, if the team use feature branches then a developer might create a new branch called feature_A, and switch to it, like this:
git checkout -b feature_A
This new branch contains a full copy of the original source code. The developer now creates a new stored procedure in his development database and commits the change. So far, this works fine. Each branch in version control, in this case the Feature_A branch, represents a specific state of the source code, and this state is also reflected in the development database.
However, what if the developer now needs to add a column in a table in a Feature_B branch that someone else in the team has been working on? The developer switches the SCA project to the Feature_B branch. The local version control repository now reflects the state of the source code in the Feature_B branch, but his local development database has not changed, and so still reflects the state of the source code in the Feature_A branch. In other words, they are out of sync.
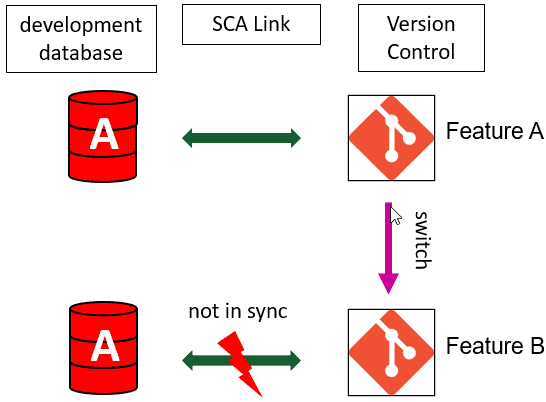
What developers would like, instead, is that their working database should keep remain in sync, when they switch branches. In other words, each branch should always be connected to a development database that reflects only the state of the source code in that branch.
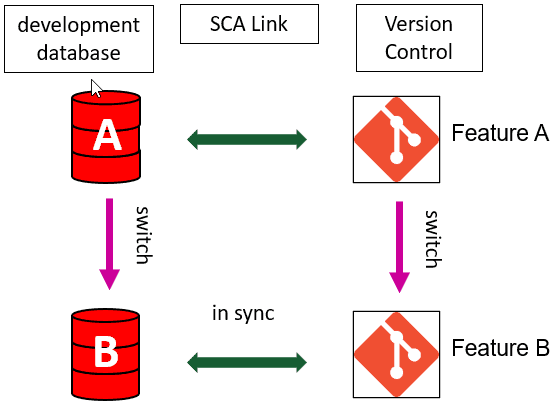
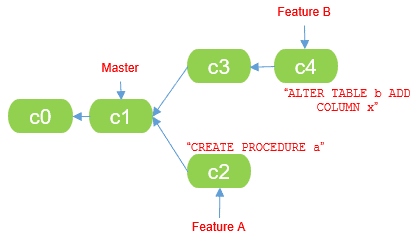
For example, in the following representation of some branches, within Git, the development database A, for Feature A branch, should contain only commits c0, c1 and c2, and the development database B, for Feature B branch, should contain only commits c0, c1, c3 and c4.
One way to enable this is to create two different SQL Change Automation projects, each connected to a copy of the database with a different name, such as ScaryDBADev_FeatureA and ScaryDBADev_FeatureB. When you now work in one project, representing one feature branch, and want to change to the other to do some work there, you would:
- Commit your changes and close the first SQL Change Automation project
- Go into your git user interface (e.g. Tortoise git) and switch the branch
- Open the second SQL Change Automation project representing the other feature branch in the same repository.
This is cumbersome and additionally a source of potential confusion, working with different branches and manually attempting to find the correct SCA project for the right Git branch.
Wouldn't it be better if you could simply work with a single SCA project, and use it to switch to a different branch, such as the Feature_B branch and have the associated development database automatically reflect the state of that branch, make and commit changes, then switch back to Feature_A branch and have the development database automatically switch back as well?
How can we make this work?
Enabling easy branch switching with SQL Clone and SQL Change Automation
The new workflow requires use of both SQL Clone and SQL Change Automation (either in SSMS or Visual Studio).
You will need SQL Change Automation version 4.2.20066 (from 6th March 2020) or later, which supports the ability to create and switch between Git branches, during database development work.
You'll need SQL Clone version 4.2.0 (from 21st November 2019), or later, to provision all development copies of the database, for working on any branch of the development project, and to enable the branch switching workflow, where the working development database always remains in-sync with the currently-connected branch in Git.
The solution relies on the ability of SQL Clone to create a new copy, or clone, of the database, dynamically, as the developer switches to a new branch, and also to rename existing clones so that it preserves any work the developer committed to the previous branch, before switching (you'll see a full example of how it works, later). This is realized by utilizing two small functions. One is the ability for SQL Clone to rename existing clones, and consequently the database name on the SQL Server instance This requires use of the Rename-SqlClone PowerShell cmdlet (introduced in v4.2.0).
The second is a Git hook, a feature in the Git version control system, which executes scripts within the Git bash-shell, in response to defined 'actions'. These script executions are triggered by certain events in Git, that is why they called hooks. So, for example, you could provide a script, which is executed every time, before a commit is done to the repository or after someone pulls from the remote repository to update their local repo with changes made by others. The git hook, in this case, will be invoked after the branch in a repository is switched to a different branch, or after a new branch is created and then the branch is switched to this new one. It will execute an associated PowerShell script and will use SQL Clone to ensure that the developer's working database is in sync with the state of the branch on which he or she is currently working.
With this in place, you will, from a single SCA project, be able to connect to a Git repository, then commit and push changes, switch between Git branches and even create new branches, and the associated development database will remain "in sync", without the developer having to do any extra work.
Prepare the development environment
This setup assumes, that the work environment is tooled by SQL Server Management Studio with a SQL Change Automation plugin. It is also assumed that the common case being an existing development project, consisting of a Git repository, a SQL Change Automation project, and a development database.
To prepare the environment the following steps need to be done:
1. Create a SQL Clone image and a clone
In SQL Clone create an image of the source database, ideally in the state at which the development starts (i.e. consistent with the current state of the Git repository).
Ideally, you should capture the image from a database on the same SQL Server instance as the one that hosts the development database. If not, then at least make sure that the SQL Server instance and machine hosting the source database is registered with the SQL Clone Server (such as by doing a 'test' clone provisioning operation, beforehand). My image is called ScaryDBA_IM.

Next, create a clone from that image and deploy it to the development SQL Server instance. My clone is called ScaryDBA_CL_BR.
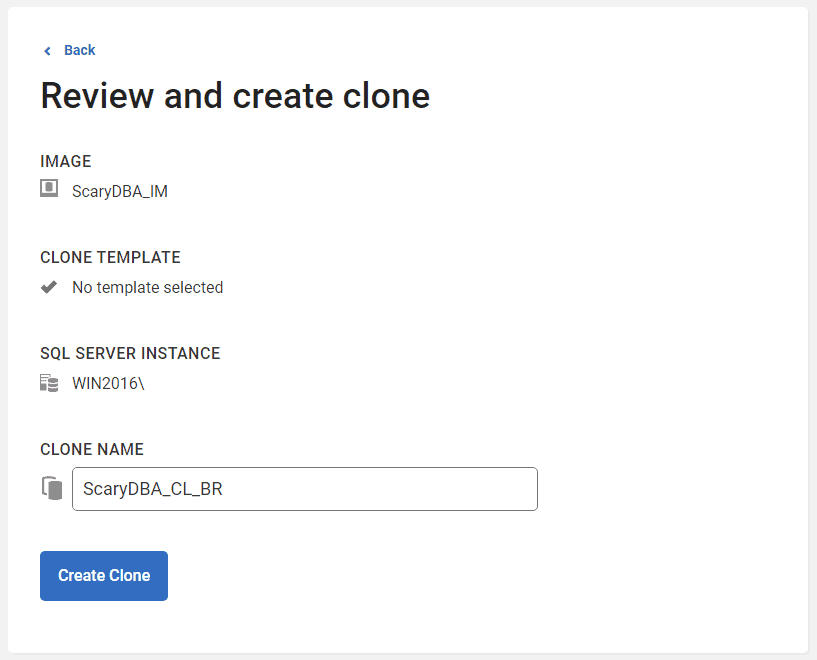
Once this is complete, you should see in the SQL Clone dashboard that both the image and its clone have been created, successfully.

2. Install the Githook and PowerShell scripts
Next you need to install two scripts. One is a "hook" file called post-checkout, with no file extension. The filename specifies the event in Git that will invoke the "hook", in this case after issuing the checkout command to switch between existing branches, or create a new branch and switch to it.
This githook opens a PowerShell session and executes the second script, called clone-branch.ps1, which performs all the actions required to ensure the correct clone is always mapped to the correct Git branch.
Place both scripts inside the folder: ./.git/hooks/ folder of the Git repository (if you place the PowerShell script elsewhere, then you will need to update the reference path in the post-checkout script).
3. Configure the clone-branch script
Open the clone-branch.ps1 script and edit the following variables in the script header:
|
1
2
3
4
5
|
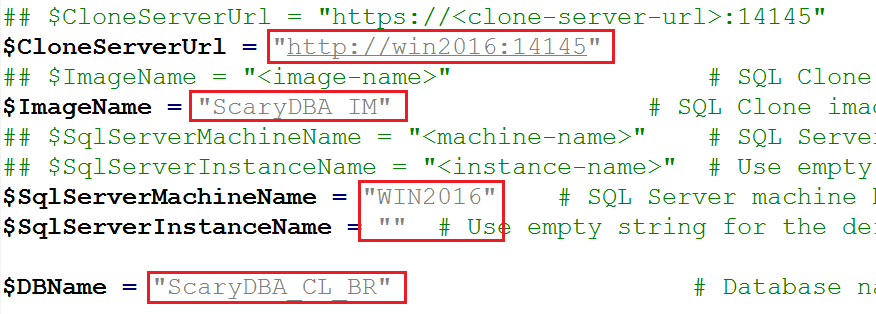
$CloneServerUrl = "https://<clone-server-url>:14145"
$ImageName = "<image-name>"
$SqlServerMachineName = "<machine-name>"
$SqlServerInstanceName = "<instance-name>"
$DBName = "<your_name_for_the_clone"
|
You'll need to enter the URL of your SQL Clone Server, the name of the image, and names of the machine and the SQL Server instance, where the database development takes place. Finally, provide the name of the development database, DBName, which in this example should be the name of the clone, created in step one. This will be the name of the actual development database clone.
Once this is accomplished, we can go to SQL Server Management Studio, open the SQL Change Automation project, and utilize the new branch-switching workflow.
Using branch switching with clones in SQL Change Automation
The following screenshot shows an existing SQL Change Automation project, called ScrayDBA.sqlproj, which is committed to a Git repository:
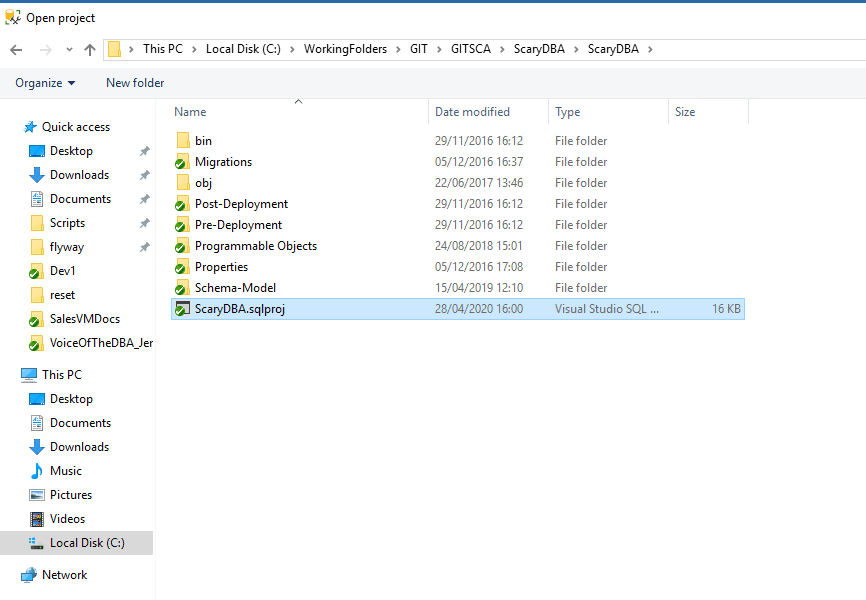
The project will be linked to development database, by its name. Currently this database is in the same state as the source code in the repository. Currently there is only one branch, master, in this repository.
Switch the development database to a clone
The first step from here is to switch the development database for the current branch (master) to use the clone we created earlier.
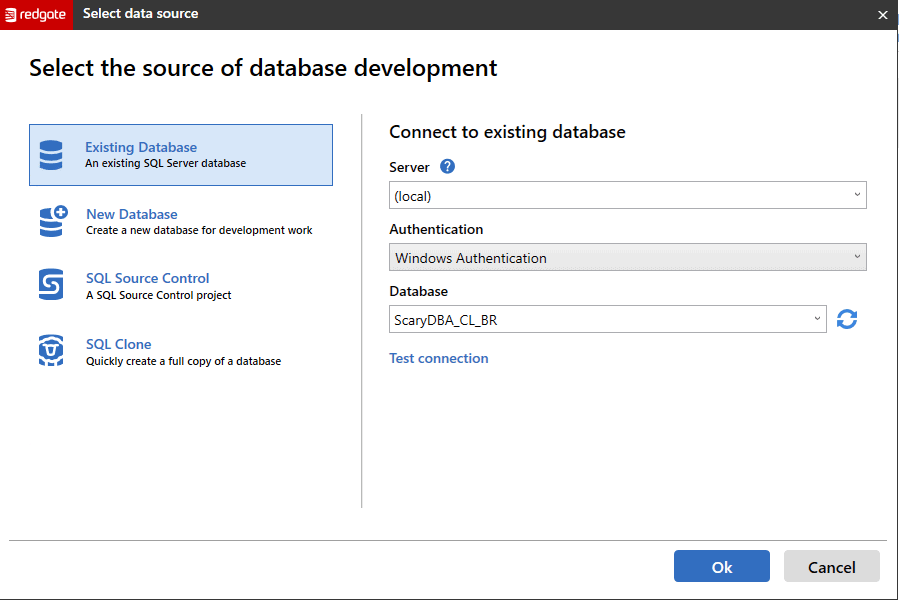
In SQL Change Automation user interface, click on the database name (here, ScaryDBA_dev), open the Database dropdown box and select the previously created clone (here called ScaryDBA_CL_BR):
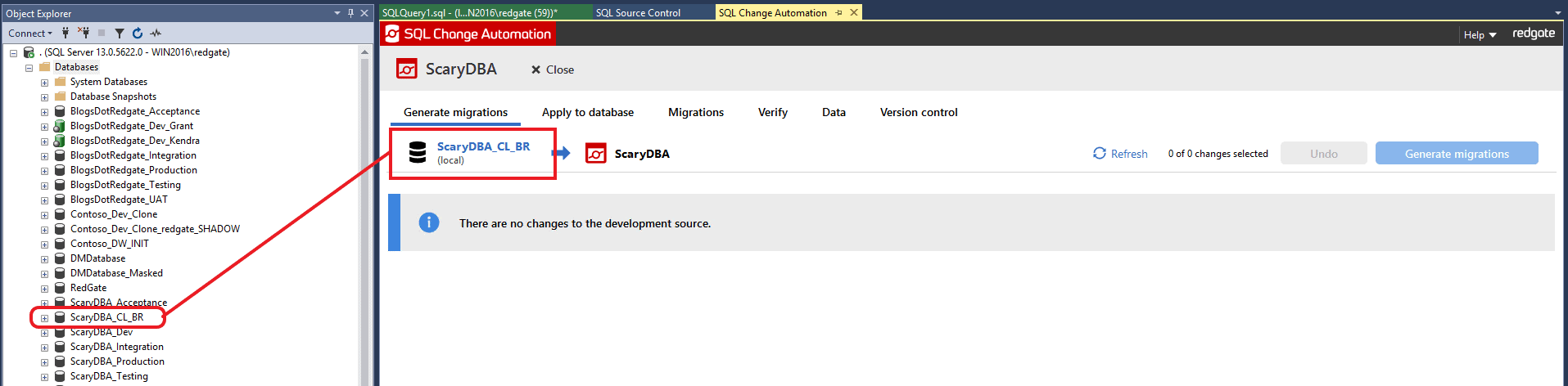
You will see that the ScaryDBA_CL_BR clone is now linked to the existing ScaryDBA SCA project:
Creating and switching branches
Next, create a new Feature_A branch in the Git repository. You can now do this in the SQL Change Automation interface, or you can use the Git management tool of your choice.
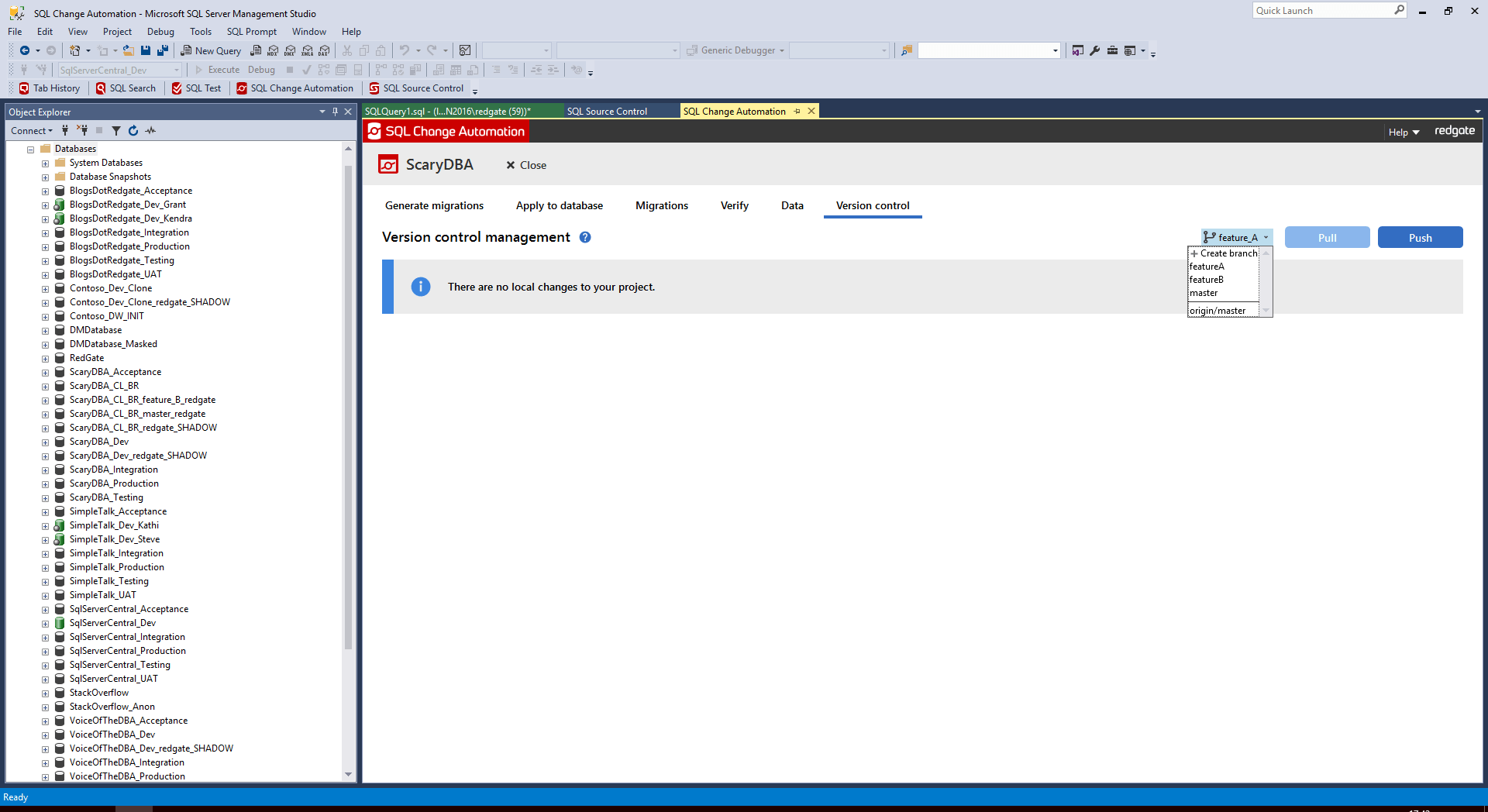
In SCA, we can do it by clicking in the branch dropdown, in the Version control tab, and choosing +Create branch:

A dialog pops up where you enter the name of the new branch, in my case Feature_A, and a couple of seconds after hitting Create, you should see that the new branch is created, the Git repository is now switched to this branch, and our SCA project folder will now reflect the state of this new branch.

In effect, we've used SCA to issue the git checkout -b feature_A command that I showed earlier, and therefore this has also invoked the post-checkout githook and executed the associated clone-branch.ps1 script.
What you can observe, as a result, is that you can see a new clone called ScaryDBA_CL_BR_master_redgate, alongside ScaryDBA_CL_BR.

In fact, what has happened is that, on switching from the master to the Feature_A branch, the clone-branch.ps1 invoked the following SQL Clone operations:
- Rename the original clone, connected to the master branch, to ScaryDBA_CL_BR_master_redgate. The name is a concatenation of the name of the clone, the branch to which it belongs and the username (here, redgate).
- Create a new clone with the same original name, ScaryDBA_CL_BR, but now linked to the SCA project in the branch feature_A
You can now make changes to the ScaryDBA_CL_BR clone such as creating a new stored procedure. After you have committed your work to the branch Feature_A (do not forget to do this), you might now need to create another new branch, Feature_B, and switch to it.
The same operations happen again, so the clone for the Feature_A branch is renamed to ScaryDBA_CL_BR_Feature_A_redgate (and will contain the new stored procedure) and the ScaryDBA_CL_BR is a fresh clone, created from the SQL clone image, and mapped to the Feature_B branch.

Once again, you make your changes on the Feature_B branch, such as adding a new column called twitter to the contacts table, commit your changes and then want to switch back to the existing Feature_A branch and continue your work there. To do this, you simply select it from the branch dropdown, which displays all existing branches.
As we would expect, by now, SQL Clone has renamed the ScaryDBA_CL_BR clone for Feature_B branch to ScaryDBA_CL_BR_Feature_B_redgate, and the latter will now have the twitter column in the contacts table.
Also, the database ScaryDBA_CL_BR_Feature_A_redgate has 'disappeared' and we have a new working database, a clone with the usual name of ScaryDBA_CL_BR, and you will find it still has the all the work done in Feature_A, in this case our new stored procedure. What really happened was that the Feature_A clone database has been renamed, back from the "archive" name of ScaryDBA_CL_BR_Feature_A_redgate name to the "working" name, ScaryDBA_CL_BR, of the development database.

In this way, as a developer, you are always working on a development database of the same name (ScaryDBA_CL_BR), and SQL Clone just automatically ensures it's in sync with the current branch, and also, by renaming existing clones, any work you committed to previous branches is preserved.
Conclusion
By utilizing the Git function of invoking hooks together with the SQL Clone API of creating and renaming clones, developers can set up a development environment that allows them to switch branches and databases back and forth in a single step. They can work on several features and branches at the same time without the trouble of securing the synchronicity between version control and development database.
Tools in this post
You may also like

Article
Simple SQL Change Automation Scripting: The Release Object
Once you understand the SCA data objects, it can give you a certain glow of to discover, suddenly, that SCA can do some complicated and time-consuming tasks with just a few lines of code. Phil Factor demonstrates how to get the most of SCA's Release object.

Article
Designing an automated database deployment process: case study
In my previous article, How to design an automated database deployment process, I wrote about the steps companies and organizations should take to introduce automation to their database deployments. In this article, I’m going talk about the challenges I faced when I embarked on my own automation journey. Prior to joining Octopus Deploy, I was the lead developer on a pilot team that automated database deployments and reduced the time required from two to four hours per deployment down to ten minutes. Why automate? One of the DBAs in the company summed it up best when they said, “Our database

Article
Static Data and Database Builds
Whichever way you wish to ensure that a database, when built, has all the data that will enable it to function properly, there are reasonably simple ways of doing it. Phil Factor explains the alternatives.

Article
Scripting Custom SQL Server Clones for Database Development and Testing
Phil Factor shows how to automatically apply T-SQL modification scripts during image and clone creation. Using this technique you can, for example, apply data masking to all clones, or customize an individual clone to work on a special variant or branch version, or set up instance level objects like Agent jobs or linked servers.
Article
Simple Database Development with SQL Change Automation
SQL Change Automation makes automation simple enough that it can adapt to suit many different approaches to SQL Server database development. Phil Factor describes a project to update the Pubs database, using it in combination with a PowerShell function and to maintain in source control the build scripts, migration scripts and object-level scripts, for every version of the database.

Article
A behind the scenes glimpse of SQL Clone
It has always been a difficult task to provision development and test environments so that they reflect as closely as possible what’s present in production. With the rise of containerization and Infrastructure as Code (IaC) technologies, some parts of this are becoming much easier. We can automate the process of spinning up and configuring new virtual machines, of installing and configuring SQL Server, and so on. However, we still have one missing piece here: data. This final step of being able to deploy and then tear down, on demand, a database filled with realistic volumes of data, on multiple development and test
Loading comments...