





A Hybrid Approach to Database DevOps
Redgate's Database DevOps tools allow you to automate the process by which teams develop, test and deploy a database, from a version in source control. They are designed to support whatever techniques and methodologies are deemed most appropriate by the database development team and organization, while always ensuring that organizational requirements for version control and for deployment checks are maintained. They can support a migrations-first approach, a state-first approach, or both, at different phases of development and deployment.
This article describes just one possible approach, a combined or 'hybrid' approach designed to offer teams a relatively simple way to get started building an automated development and deployment pipeline. Teams will use a state-based tool for database development and version control, and then at certain key stages, such as the end of a feature sprint, or as they approach the point of having stable release candidate, they use a migrations-based automated deployment tool to generate and customize the deployment script that will be used in their automated pipeline.
If you'd like to learn more, you can also check out Kendra Little's online training course, How and When to Use the Hybrid Workflow of SQL Source Control with SQL Change Automation Migrations.
The basic requirements of database development and deployment
There are many ways to develop and maintain a database, ranging from the use of an Entity-Relationship diagramming tool to keying in the CREATE statements by hand, and an experienced development team will probably use them all, at various points. However, there are generally only three end-products that are required by the organization:
- A set of documented scripts in version control that build a database from scratch.
- One or more scripts in version control that will create or update the production system.
- A 'manual' for the database with explanations that allow maintenance, support and training to take place, and facilitate collaborative teamworking.
It is difficult to achieve these deliverables without additional tools and scripts. Firstly, you will need tools to help you maintain the database source in version control, during development. These tools tend to use two different ways of scripting the source: either 'migration-first' or 'state-first'. With migration-first, you script the progressive addition and alteration of database objects. With state-first, you maintain the scripts that directly create the current version of each object.
Secondly, you need tools that will automate the way you build database and deploy changes to existing databases. Depending on your approach, this is done by running all the migration scripts that haven't previously been applied on the target database, in the correct order, or by using a schema comparison tool to compare the object source to the target and auto-generate a script that would make the latter the same as the former.
These approaches are not fundamentally different and need not be mutually exclusive. They have the same goal, which is to produce in the version control system the set of scripts that can then be used to build a new version of a database, or 'migrate' an existing database, safely, from one version to another. Furthermore, a team may need either approach, at different times, or for different tasks, or for different parts of the system. You would, for example, expect a migration approach to both development and deployment to dominate, for continuous delivery of changes to a production database, and conversely a state approach to dominate if modifying only the database "API" (views, stored procedures, functions and so on) rather than the underlying tables.
This article describes a development and deployment process that uses both. Teams will benefit from the simplicity and speed of the state-based approach during development, for capturing and sharing database changes, in version control, and performing development builds. When the focus of the team turns to upgrading the production database to the latest version, and they start testing deployment mechanisms for the new version, they can generate and customize migration scripts, which will describe the exact sequence of operations required to update a target database from version A to version B, safely.
Redgate Database DevOps tools for development and deployment
This section summarizes the Redgate Database DevOps tools that support the development and deployment processes, and which approaches they support. Throughout the article, I'll refer simply to the category of tool rather than attempt to name each of the possible tools each time.
Redgate's database development and version control tools are designed to help the team develop and maintain the source of a database in version control. They provide a direct interface between each developer's local working copy of the database and what is the version control system, such as Git.
Redgate's automated deployment tools will make it easier to manage a deployment pipeline that involves tests, checks and other team processes that are required to support the major aspects of rapid delivery. The build and release components of these tools work with all major build, continuous integration and release management servers.
I've included Redgate's standalone schema comparison tools in the table as well, because all Redgate's Database DevOps tools use a schema-comparison engine under the hood, in different ways, to support the development and deployment processes.
| Category | SQL Server | Oracle | ||
| State | Migrations | State | Migrations | |
| Schema comparison tools
(standalone) |
SQL Compare | N/A | Schema Compare for Oracle | N/A |
| Database development and version control tools | SQL Source Control | SQL Change Automation development add-ins for Visual Studio or SSMS | Source Control for Oracle | Redgate Change Control |
| Automated deployment tools | SQL Change Automation PowerShell cmdlets with SQL Source Control projects | SQL Change Automation PowerShell cmdlets with SCA projects | Schema Compare for Oracle command line | Redgate Change Automation |
The approach suggested here means the teams will use the appropriate SQL Server or Oracle state-based tool, for database development and version control, and then at the end of a sprint, for example, or as they approach the point of having stable release candidate, they use a migrations-based automated deployment tool for subsequent deployments.
Database Development and version control (state-based)
Whatever technique is used for developing a database, the tools and approach used ought to make it possible to build any version of a database purely from what is stored in source control, the 'canonical source'. Data can then be loaded in, so that the team have a means to produce a fully working copy of any version of a database, for testing or whatever other purpose they require.
The nature of this source varies depending on your preferred approach, and therefore the tools you choose. For example, the source for each table will either be the individual scripts to create that table in its final 'state (state-based), or it will be the initial CREATE script, and then individual ALTER scripts (as well as INSERT and UPDATE scripts) thereafter, to describe every subsequent committed change required to 'migrate' the table to its final state.
In this example, we'll use a state-based approach.
Committing and sharing database changes
During a development 'sprint', the team members use one of Redgate's state-based database development and version control tools to make changes to the local development databases and maintain the latest 'state' of each object, in version control. This means that during development, the 'canonical source', or source of truth, for any database version is the desired final 'state' of the database. It is a set of DDL CREATE scripts to create each object in the database. More accurately, it consists of the batches to create each parent database object, with all the objects it comprises (for a table, this means indexes, triggers and so on). When ordered correctly, you'll have a script that will build the database from scratch.
Redgate's state-based version control tools use Redgate's schema comparison engines to capture the DDL CREATE scripts for each database object into a separate file in version control, and then keep track of any changes made to a developer's local database, which haven't yet been committed to version control.
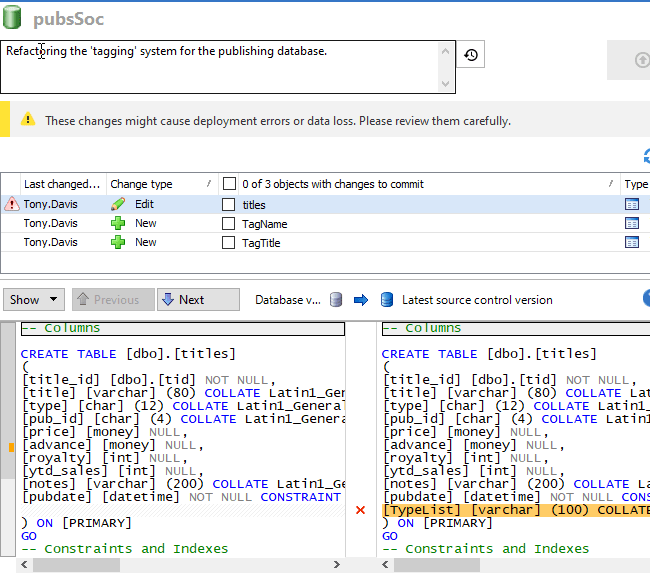
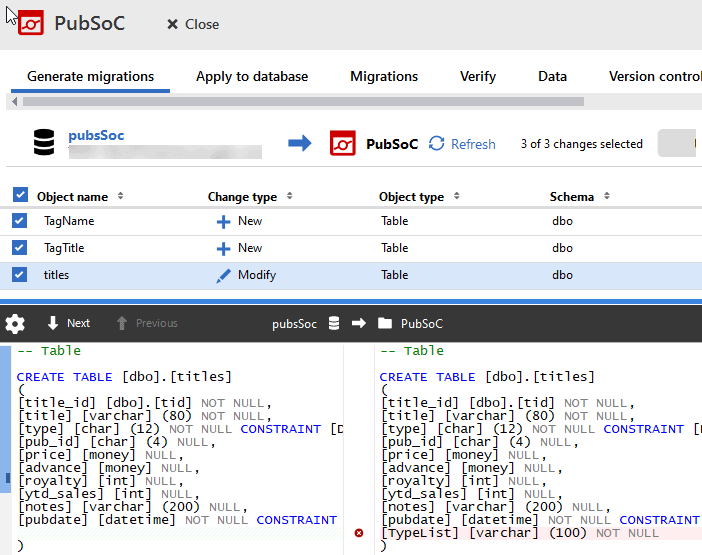
In the following example (taken from SQL Source Control), a developer has refactored the 'tagging' system in his local copy of a publishing database, dropping the Typelist column in the Titles table, and creating two new tables (TagTitle and TagName). The tool will generate CREATE scripts for the two new tables and update the CREATE script for the Titles table so that it no longer has the TypeList column. These changes can then be committed to version control, capturing who made the change and why.
Notice that the tool offers a warning of danger, in this case that dropping the TypeList column during a subsequent deployment could cause data loss. While this may not be concern during the early stages of development, it will of course be an issue when it's time to deploy the new database source to an existing production database. The team should 'flag' all such schema changes that might affect existing data in unpredictable ways and start to plan for how to handle them.
As team members complete their work on an object, or set of objects, they simply push and pull to the shared team repository, to share their changes and merge and resolve conflicts in the usual ways. They can, as well, frequently update their own work with the changes of others.
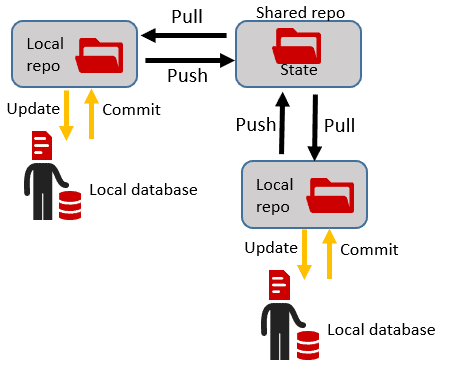
During development, this approach of committing and sharing the latest 'state' of each object, tends to work extremely well because it is a natural fit for standard version control mechanisms, which all work exactly as normal. From the source DDL scripts, plus the basic versioning functionality of the source control system, the team can see immediately the history of each table's object's evolution and who did what, why, and when.
Development Builds and Integration
Throughout the development process, the team will need to continuously check that the source code and data files can be used to successfully create the database, with its development data, to the correct version. In this simple approach, these could be done using one of Redgate's automated deployment tools, with the current 'state' folder as the source.
The team can perform overnight builds or integrate the tool into a Continuous Integration system for CI builds. The CI process takes the current version, creates a build script from it, builds it on the build server, and then loads in test data, for example from a BCP data store.
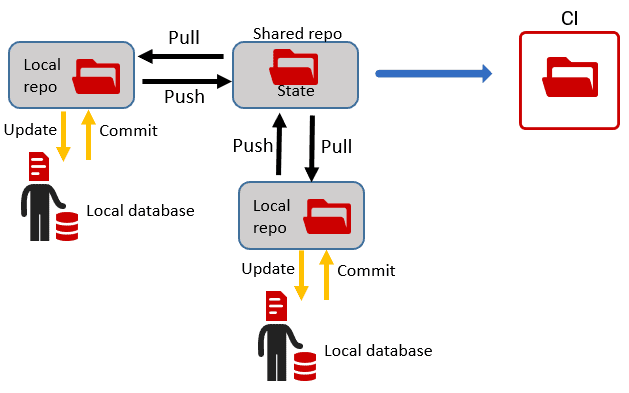
Redgate's state-based deployment approach uses a schema comparison engine to generate a 'model' of the source database, from the DDL (state) scripts, and then compares this to the metadata of a target database. It auto-generates a single deployment script that will make the target the same as the source, regardless of the version of the source and target. If the target database is empty, then the auto-generated script will contain the SQL to create all the required objects, in the correct dependency order, in effect migrating a database at version "zero", to the version described in the source. This approach works perfectly well for any development builds where preserving existing data is not required.
If the current build becomes a candidate for release, and we continue with the same approach, then the tool would generate a deployment script that will modify the schema of any target database so that it matches the version represented by the release candidate. However, if the development involves making substantial schema alterations, such as to rename tables or columns, or split tables and remodel relationships then it will be impossible for the automated script to understand how to make them while preserving existing data.
Teams that avoid tackling these issues or believe that an auto-generated script will somehow cope, will find too late that 'breaking changes' build up to the point that deployments become daunting, and releases are delayed. It pays to gauge the size of this task as early as possible, by testing deployment of the source to a target database whose schema and data match the production target as closely as possible. SQL Clone is an ideal tool for this.
For each schema changes that affects data, we would need to work around these problems. We need to customize 'around' the auto-generated model for the deployment, by writing idempotent pre-deployment and post-deployment scripts that handle such changes correctly and makes sure the data is taken into consideration (see for example, Handling Tricky Data Migrations during State-based Database Deployments). However, this approach can introduce complications. The problem, distilled, is that a schema comparison tool doesn't care about the version of the source and target; it will just auto-generate a script to make them match. Once we start adding pre- and post-deployment scripts around it, to alter the target, such as to move data around in a new design, then everything is suddenly version specific: that deployment process should only be used to migrate between one specific version and another. It can be hard to ensure that this sort of partly-customized, partly auto-generated deployment is always safe, even if accidentally run on the wrong target version.
An alternative and often simpler way to deploy a database, data and metadata, especially before and after schema re-engineering, will often be to use a migration script, hand cut for the purpose of moving the database between two specific versions.
Automated Deployments (migrations-based)
When the team reaches the end of a sprint and has a release candidate for the new database version, they will need to start fully testing how to deploy it, which in this approach they will do by generating and customizing a migration script to take the target database from its current version (A), to the version described by their release candidate (B).
To do this, a developer or DBA in the team pulls that latest 'state' for their release candidate so that their development copy is at the latest state, and then creates a new project using a migrations-based development and version control tool that uses this as the development source. He or she creates a baseline schema for the target database, such as the team's staging copy of the database (which will be at version A). This example is from the SQL Change Automation development add-in for SQL Server Management Studio.
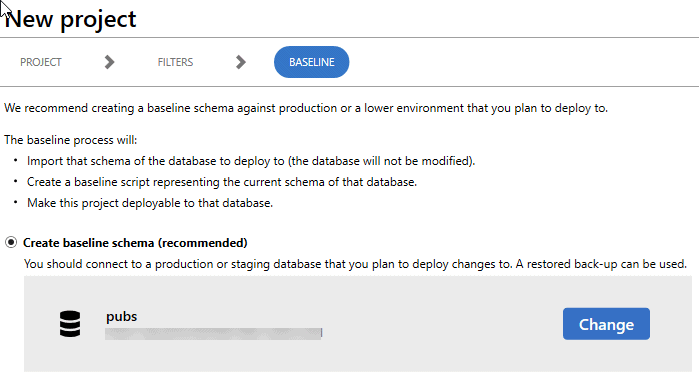
The tool uses Redgate's schema comparison technology to generate a baseline script that will create the version of the database that is already deployed (version A). It then updates a shadow database so that its schema matches that described in the baseline and will then generate migration scripts that will describe any differences between the baseline and the imported 'state' of the development source, which you import into the new migrations-based deployment project.
In the following example, the development source (pubsSoc) is at version B and the tool has generated migrations to describe the changes not yet applied to the target database, as represented by the baseline schema, which we're about to import into the project (PubSoc). Notice that the migrations are simply describing the changes we made in development, dropping the Typelist column in the Titles table, and creating two new tables (TagTitle and TagName).
However, once this script (or scripts) is added to the migrations project, and committed to version control, it is simple to customize it in preparation for an automated deployment to update a target database.
We can simply edit the parts that create the TagTitle and TagName tables so that they also stock these tables with the data from the titles Titles table. Then we simply need to ensure that these changes run before the one that drops the TypeList column, which is handled by adding numeric prefixes to the names of the migration scripts.
Any scripts that insert data or make changes to database settings can simply be added to the project as migrations scripts, to be run at the appropriate point in the deployment sequence. Each migration script gets a unique ID, used to ensure it never runs more than once on a target.
Of course, all this still requires careful planning. In some projects there be could be many migration scripts and the team need to be aware of which scripts contain changes that could entail data loss, or might fail due to existing database constraints, since you do not get currently get 'warnings' when these scripts are generated.
Another advantage of the migrations-based automated deployment tools is that they directly incorporate a "Verify" operation (shown in previous figure) that will validate that the deployment will run without error on a "baseline" of the target database. The baseline will generally be a script representing the current schema of the target database. However, in the latest releases, it can also be a SQL Clone database, including data, meaning that the Verify operation is, in effect, a simulated deployment.
If the team need to make further schema changes, they make them in the state-based version control tool, updating the state folder, and then return to the migration deployment tool and generate and customize the new migration scripts.
When everything is ready, the migration project is pushed to the shared repo and become the source of any subsequent deployment. This does involve a mental 'switch' for the team, in that whereas during development the state folder was the 'source of truth' for the database, for deployments, a migrations folder becomes the source of truth, and the team, or whoever is responsible for release management, can review, validate, customize the code in the migration scripts.
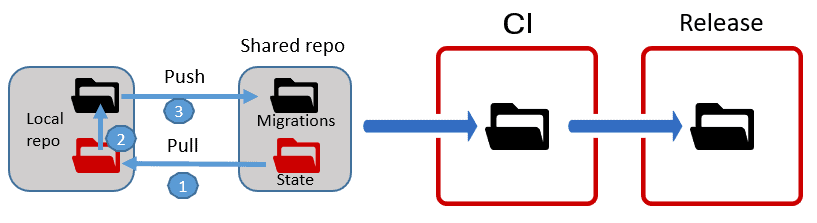
The team can execute a migrations-based automated deployment with the migrations folder as the source and the staging database as the target and test the deployment until it runs flawlessly.
Conclusions
There are several different approaches to database development and deployment, and any Database DevOps solution needs to support the way that the teams need to work. Whereas some development projects need different methods of working at different stages, others are, by their nature, suitable for only one approach. Redgate's Database DevOps tools fit in with the requirements of diverse team practices
For teams that are ready to do Continuous Deployment, with every change going all the way through to Production, then a migration approach to both development and deployment will work well, since they'll be small changes and you have full control over the script that will be run for the deployment.
Conversely, if a large team of developers are mainly just building out and adapting code modules, then a state approach to both development and deployment will make it simpler for the team to track and share changes and minimize conflicts, and to run deployments. However, any occasional problems with preserving data during schema changes will require use of pre- and post-deployment scripts.
This article has proposed a simple approach that allows the relatively simplicity of state-based version control and development coupled with the control and customization of a migration-based automated deployment project. It will suit a team that wishes to employ Database DevOps techniques, since it encourages the testing and deployment of changes in frequent, small batches. Each time a team finishes a "feature sprint", or otherwise approaches a release candidate, they can generate the migrations scripts and then customize them as required, or add new scripts to deal with data migration, configuration changes and so on, as required for a successful deployment. Of course, this approach can be adapted to suit the team, for example to generate migrations for each schema change committed to the 'state' folder, rather than doing this at set 'stages'.
If you're not sure what approach your team falls into, then start with the state-based approach to get your database changes into version control. You can then manually deploy from version control to follow best practices. From here, you can start to automate in either a state-based or migrations-based by using this hybrid approach when you're ready to start automating your deployments.
Tools in this post
 Deployment Suite for Oracle
Deployment Suite for Oracle
DevOps for Oracle Databases - Speed up and simplify Oracle development
You may also like

Article
How to examine differences with SQL Compare Summary View and SQL View
Jamie Wallis introduces the new Summary View, which is a tab that sits alongside SQL View and provides a more concise breakdown of the differences between two objects.
Article
On Quickly Investigating a Redgate Monitor Custom Security Alert
Phil Factor offers a clever way to report on a SQL Server intrusion, with a query that shows a full narrative description of all the security-related changes that have been detected by a set of Redgate Monitor custom metrics.
Article
How to create a directory of object-level scripts using SQL Compare
How to create a directory of object-level scripts from an existing database using SQL Compare GUI or command line.

Article
Using SQL Data Compare to Sync Reference Data
Let's say your QA team maintain two similar test databases. They run tests to verify that different versions of the same application still produce the same, correct results. Therefore, any differences in the test data, between the two databases, needs to be corrected before the tests start. This is the sort of task for which SQL Data Compare is ideally suited, and Bob Sheldon explains how it all works.
Article
Checking for Database Drift using Extended Events and Redgate Monitor
Phil Factor uses Extended Events and a Redgate Monitor custom metric to detect when the metadata of a database has 'drifted', meaning that a database object has been created, deleted or modified outside of the official change management process.

Article
Exploring the SQL Compare Options
You need to compare database schema objects in two SQL Server databases, and then automatically generate a SQL deployment script that when executed will remove these differences, either making the schema of the target database match the source, or vice-versa. It sounds easy, but the problems lie in the details of the schema comparison options.
Loading comments...