





Simple SQL Change Automation Scripting: Connections, iProjects and Builds
SQL Change Automation can seem bewildering at first, because of the number of different routes that it allows you to take, in order to build a database, or update an existing one. Whichever route you decide on, however, the basic principle is the same. SCA will work out what script is needed to change a target database to be the same as the source, in terms of the tables and routines. To build a database in its entirety becomes just an extreme form of this. SCA will tackle a source directory of one or more database build scripts as if it were a database.
Working with SCA is rather like using a Mechanical Lego set; it pays to know what all the main building blocks and connecting pieces do, even if you don't need all of them every time. In SCA parlance, the lego blocks are the PowerShell cmdlets, and the connectors are the various data objects, or artifacts, that pass in and out of them. In all the diagrams in this article, the red boxes represent the data objects, and the blue boxes the PowerShell cmdlets.
My first article in this "SCA simple steps" series gave the bird's eye view of the SCA cmdlets and described the different ways to use them to build or update a database, from source control. Here, I'm going to explain each of the main SCA "data objects", namely the database connection, project and build objects, how to work with them, the useful information they contain, and the benefits they bring to your automated database build processes, such as build validation and database documentation. The next article in this series covers the release object.
The DatabaseConnection object and connection string
In SCA, you often need to specify a source or target database. To do so, one can generally use either a connection string or SCA's own DatabaseConnection object, created using the New-DatabaseConnection cmdlet. In either case, you can test the connection before you use it; using a DatabaseConnection object just makes it a bit easier.

Figure 1: Connecting to a target database
A connection string, which you can use instead of a DatabaseConnection for specifying a database connection, is merely the standard ODBC string in all its exotic permutations. Where a DatabaseConnection object scores is when you are using other ways of connecting to SQL Server, as part of the script. The DatabaseConnection object provides a credentials object for SMO or SQL Client connection, as well as a connection string, and allows you to determine the server and database within a script more easily.
If you aren't already a connection-string ninja, the New-DatabaseConnection cmdlet will do it for you.
|
1
2
3
4
|
<# ------- Create a connection string --------#>
$MyConnection = New-DatabaseConnection -ServerInstance "MyServer" `
-Database "MyDatabase" -Username "Phil" -Password "WouldntYouLikeToKnow"
$MyConnection.ConnectionString.UnmaskedValue
|
And you can even test it out!
|
1
2
3
4
5
6
7
|
<# ------- Create a connection string --------#>
$MyConnection = New-DatabaseConnection -ServerInstance "MyServer" `
-Database "MyDatabase" -Username "Phil" -Password "WouldntYouLikeToKnow"
try {Test-DatabaseConnection $MyConnection}
catch{Write-Warning "Sorry but the connection string $(
$MyConnection.ConnectionString.MaskedValue) didn't work. Try again"}
$MyConnection.ConnectionString.UnmaskedValue
|
You can also pass a connection string to Test-DatabaseConnection and define a timeout, like this:
|
1
|
$MyConnection = Test-DatabaseConnection "Initial Catalog=dbName;Server=Server\Instance;Integrated Security=true;Connect Timeout=5"
|
You'll notice that it returns a DatabaseConnection object, so you now have a shortcut to creating and testing it. Once you have either a DatabaseConnection or a valid connection string, you can use it to synchronize your build script with a target.
In the rest of this article, we'll stick to using a simple connection string because I want to keep the code as simple as possible, focussing first on a solution that uses just a single PowerShell cmdlet. If you are unsure how to create a connection string, then use the code above to get it.
My article, Deploying Multiple Databases from Source Control using SQL Change Automation, shows how to use a DatabaseConnection object to create and test connections for a set of target databases at the start of a routine, so that a single mistyped credential doesn't abort a script after a tedious passage of time. If you have a complex script whose finale, after an hour or so, is to update several databases on various servers, you really don't want a fatal error after that long wait!
Using a ScriptsDirectoryPath with Sync-DatabaseSchema
In my first article in this series, I showed that, its simplest form, developers can use a single SCA cmdlet, Sync-DatabaseSchema, to build a database from, or synchronize an existing database with, a source directory. It is a good way to wet your feet with SCA scripting, despite its limitations.
|
1
2
3
4
5
|
Import-Module SqlChangeAutomation
<# -------Synchronize a target with the scripts --------#>
Sync-DatabaseSchema `
-Source 'C:\Projects\GitHub\Adeliza' `
-Target "Server=MyServer;Database=MyDatabase;User Id=Phil;Password=MyPassword;"
|
The source is simply a string containing the path to a directory that contains one or more source scripts. The target is a database connection, in this case specified by a connection string (though we could have used a DatabaseConnection object).
In SCA jargon, the source is specified by a ScriptsDirectoryPath. This scripts directory can contain just a simple build script or can be a series of object level scripts, each stored separately in their own subdirectory, along with an optional XML config file that allows you to specify details that aren't scriptable such the text Encoding of the files (e.g. UTF8), the default collation and the database version.
It can also contain a data directory with data insertion scripts to load any data that is essential for the functioning of the database, and it can contain a pre-deployment SQL Script and a Post-deployment script, executed before and after the main build script, respectively.
The ScriptsDirectoryPath is only one of the possible inputs to the Sync-DatabaseSchema cmdlet. We could also have synchronised an existing target database with either a source database, or an SCA build package.
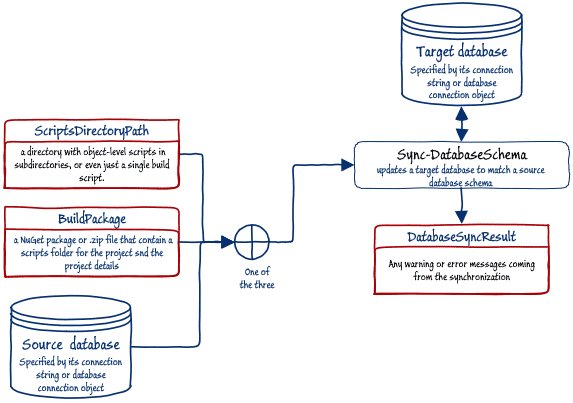
Figure 2: Inputs to, and outputs from, the Sync-DatabaseSchema cmdlet
This diagram also shows us that the Sync-DatabaseSchema cmdlet also produces a useful data object as output, which is the DatabaseSyncResult, in which are stored a record of any warnings, as the basis for a log of what happened.
Sync'ing multiple database with the same source directory
We can expand our single-cmdlet solution to keep several servers in synch with the current source. We've added a couple of switches to cope with the building of a copy of AdventureWorks.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
Import-Module SqlChangeAutomation
<# ------- Synchronize a collection of targets --------#>
$targets=("Server=FirstServer;Database=DatabaseFirst;User Id=Phil;Password=dunno;Persist Security Info=False",
"Server=SecondServer;Database=DatabaseSecond;User Id=Phil;Password=noIdea;Persist Security Info=False",
"Server=ThirdServer;Database=DatabaseThird;Trusted_Connection=True",
"Server=FourthServer;Database=DatabaseFourth;Trusted_Connection=True"
)
$SyncResult=@()
$SyncResult+=$targets|foreach{Sync-DatabaseSchema `
-Source 'C:\Projects\GitHub\MyDatabase\SQL' `
-Target $_ -SQLCompareOptions 'NoTransactions' `
-AbortOnWarningLevel None}
|
Sync'ing each database with its own source directory
If you have several source and target databases in the build, as when you need to build several databases on several servers, then it is the work of a moment to modify the script to synch them all
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
Import-Module SqlChangeAutomation
<# ------- Synchronize a collection of sources and targets --------#>
<a id="post-485687-_Hlk11925749"></a>$targetsAndSources=(
@{'connection'= ' Server=FirstServer;Database=DatabaseFirst;User Id=Phil;Password=dunno;Persist Security Info=False';
'source'= 'S:\work\github\FirstDatabase\SQL'},
@{'connection'=' Server=FirstServer;Database=DatabaseSecond;User Id=Phil;Password=dunno;Persist Security Info=False';
'source'='S:\work\github\SecondDatabase\SQL'}
)
$SyncResult=@()
$SyncResult+=$targetsAndSources|foreach {Sync-DatabaseSchema `
-Source $_.source `
-Target $_.connection -SQLCompareOptions 'NoTransactions' `
-AbortOnWarningLevel None}
|
Limitations of using Sync-DatabaseSchema
Although this is fine to get started, there are some obvious issues. We are just going ahead with the migration of all the list of databases without bothering to inspect the scripts first. We are using connection strings that might have passwords in plain text. We're not checking that the source compiles without error either. We also can't prevent someone changing the source once the build process has begun, meaning that we can't then be certain that everyone has the same source. Though we can include pre-deployment and post-deployment scripts, and static data scripts, in the folder, Sync-DatabaseSchema can't use them. It can only take a source directory and use it to synchronize a target database.
To overcome these limitations, we need to use some of the other cmdlets and data objects.
The iProject object
A database project object is just a container for the source scripts. If we pass the path to the source of the database (scriptsDirectoryPath) to the New-DatabaseProjectObject cmdlet, we get an iProject object that represents all the components of the source, at a point in time. This can be exported or published once it has been used to create the build artifact, so that the source from source control need not be accessed directly.

Figure 3: Creating an iProject Object using NewDatabaseProjectObject
However, the New-DatabaseProjectObject cmdlet does not check that the source is valid and can be built; it assumes you don't need to validate the source or have already validated it by other means. Otherwise, use the Invoke-DatabaseBuild cmdlet instead, with the source indicated by ScriptsDirectoryPath. This produces the iProject object that is far more likely to build a database without error.
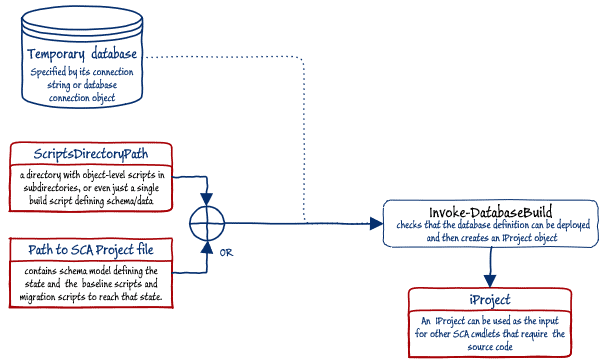
Figure 4: Creating an iProject Object using Invoke-DatabaseBuild
Now we have the iProject object, we can create the build artifact.
The iBuldArtifact
With the iproject object created, we can go further and create a build package, which SCA calls an iBuildArtifact object. This build object can then be exported to the file system, either as standard NuGet package or as a ZIP file. NuGet has the advantage that it can't be subsequently modified and can then be distributed from a package server. Once we have the build packaged exported, we are then no longer reliant on the contents of the source directory, meaning that access to source control can be restricted.
The New-DatabaseBuildArtifact PowerShell cmdlet creates the build artifact from the iProject object, and we provide the name and version of the package, and any other useful information. The iProject is also an input for the New-DatabaseDocumentation PowerShell cmdlet, so we can also include in the build artifact the database documentation generated from SQL Doc, as described in Documenting your Database with SQL Change Automation.
If we need to, we then use the Export-DatabaseBuildArtifact PowerShell cmdlet to export the build package to a file. This can form a BuildDirectory archive of previous releases that can be used without having to access a previous version in source control.
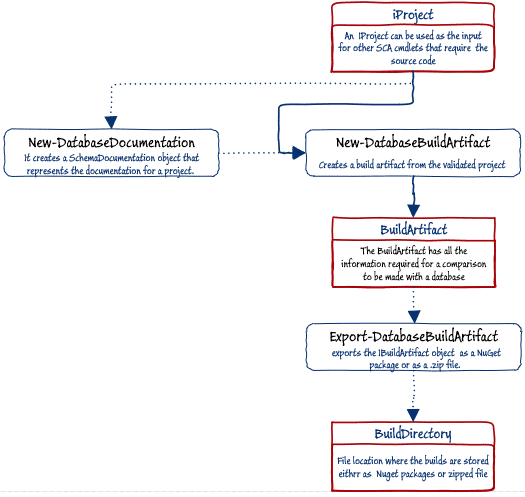
Figure 5: Creating and exporting a build object (iBuildArtifact)
My previous article, Simple Steps in SQL Change Automation Scripting shows the basics of creating and exporting the build package, and SQL Change Automation with PowerShell Scripts: getting up-and-running offers a more detailed example.
If we now use the BuildPackage, contained in our BuildDirectory, as the source for the Sync-DatabaseSchema cmdlet (see Figure 2), then SCA will not only build the database, but can also, unless you object, run any pre- and post-deployment scripts, and insert any static data, that it contains. Any new data will be loaded using single row INSERT statements, by default. If you start from an SCA project (.sqlproj) file, you have access to SQLCMD Variables and can instead run a bulk load (bcp) process. If you merely use a ScriptDirectoryPath (see previous article) to a folder containing the object scripts, then see my article, SQL Change Automation Scripting: Getting Data into a Target Database.
Alternatively, and more usually, you'll use the BuildArtifact (after inspection and checking) as the source for creating a release object. To do this, you need to use the Import-DatabaseBuildArtifact cmdlet, which will read an on-disk build package to create a IBuildArtifact object, which can be used as the input for other cmdlets. Normally you would want to use it to create an iReleaseArtifact, which I explain in detail in Simple SQL Change Automation Scripting: The Release Object. You can also publish an iBuildArtifact to a NuGet feed, with Publish-DatabaseBuildArtifact.
Conclusions
Once we understand not only the SCA PowerShell cmdlets, but also the 'data objects' that pass between them and the useful information these contain, we start to get a much better idea of the value that the tool adds to each stage of the database delivery process, and how to most easily get the system to do what we need. This article gives most of the background, by describing all the data objects, except those that are associated with the iReleaseArtifact, which I'll tackle in a separate article.
We started with the DatabaseConnection object allows us to create and test a connection for a database. This allows us to immediately perform useful database tasks. The Sync_DatabaseSchema cmdlet, for example, just needs a DatabaseConnection to a target database, and a path to a source folder; SCA will then sync the schema of the target with the source.
The iProject object allows us to create a point-in-time 'snapshot' of all the components of the source, which then provides the source for creating a build object. We can validate that the source contents can be used to build a working database and export the resulting build package. The iBuildArtifact package contains the scripts, documentation and all the other information required to deploy the new build, or to update an existing database. It can be inspected and tested by others, without needing direct access to source control. Since the build package is 'immutable' it removes all confusion about what exactly is being checked.
Finally, it can be released, either by doing a simple synchronization, or by using the build package as the source for creating a release object (iReleaseArtifact), which contains the synchronization script for changing the version of the target server to that of the source, and to which is added more useful information, such as a code analysis report, and a report of the changes that will be made, as a result of deploying the release.
Tools in this post
You may also like

Article
SQL Change Automation: Adding SQL Clone to the Mix
Tony Davis explores how SQL Change Automation is increasingly providing ways of working with SQL Clone, to improve the quality of testing for database changes. With SCA v4.3, developers can now use the SSMS plugin to create a clone of the target database, to be used as a reference database, or baseline, for the deployment project.

Article
Allowing for manual checks and changes during database deployments
SQL Change Automation enables users to make database changes to production safely and efficiently using PowerShell cmdlets, which can be integrated easily into any release management tool. This article will show you how to automate database deployments safely, by using SQL Change Automation from within PowerShell scripts, and how a deployment script for a release can be checked and amended as part of the process.

Article
Practical PowerShell Processes with SQL Change Automation
Starting from the object-level source code for a database, Phil Factor shows how SCA can create a NuGet build package, use it to migrate target database to the same version, and publish web-based database documentation, a report of what changed on the target and the results of a static code analysis assessment.
Article
Sometimes the tool just fits - using SQL Change Automation and Octopus Deploy for Data Change Control
From a business risk perspective, data change can be just as significant as code or schema change. Sometimes even more so; an incorrect static (or reference, or master) data change can drive your software’s behaviour more dangerously askew than pretty much any bug can. Imagine treating a retail customer for an investment fund as a corporate by mistake, or vice versa (a potential regulatory breach). Or booking the repatriation trades in the wrong currency (and not finding out until they settle, and hit the wrong cash balance). And what are your web customers going to do when the ‘choose credit card type’ drop-down is
Article
Questions about SQL Change Automation that you were Too Shy to Ask
Phil Factor takes on tricky SQL Change Automation questions about database builds, migrations, deployments and releases.
Article
Recreating Databases from Scratch with SQL Change Automation
Phil Factor starts with the basics how to rebuild a set of development database from scratch, using SQL Change Automation, and then demonstrates how to check for any active sessions before rebuilding, import test data using BCP, and secure passwords if connecting to the target with SQL Server credentials.
Loading comments...