





Using SQL Change Automation in SSMS to Track Static Data Changes
Often, a database build will need to supply any 'static' or 'immutable' data required for dependent applications to function. This might include ZIP or postal codes, the names of countries or currencies, standard tax rates, and so on. This static data should be relatively small in volume and, as its name suggests, is not expected to change frequently. However, if it does change, or new static data is added, during development, then the scripts that deploy these data changes, along with those that deploy the schema changes, need to be included in the build package.
The SQL Change Automation Development tools include extensions that integrate directly into your chosen SQL Server development GUI, Visual Studio or SQL Server Management Studio. This allows teams to develop new databases and modify existing databases, using migrations, in a way that promotes DevOps practices.
In SQL Change Automation v4.1, we've added support for the tracking of static data tables to the SSMS extension, alongside existing support in the VS extension. In this article, I'll show how to add static data tables that you wish to track directly through a new Data tab in the SSMS extension, and which columns within those tables. I'll demonstrate how SCA will then automatically create migration scripts to deploy any changes to this data, allowing the team to see a preview of the changes before generating the migrations.
Configuring static data tracking from within SSMS
Version 4.1 of SQL Change Automation in SSMS adds a new Data tab to the project view, where the users can pick the tables to track. In previous versions, this had to be done manually, by adding tables to the SQL Change Automation project settings (.sqlproj) file. Users that have databases with large number of tables will also benefit from using the filter that will allow them to find the tables they want to add easily.
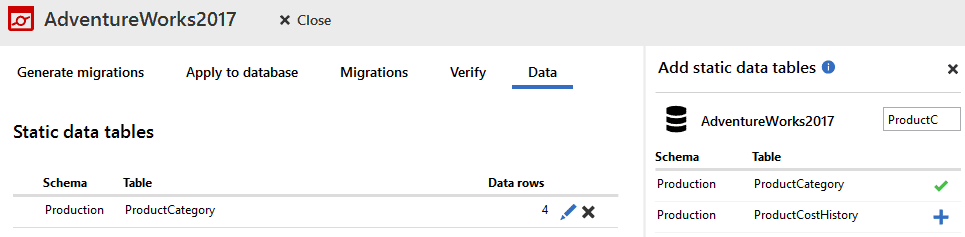
Adding tables to the Data tab
Tracking tables with large volumes of data, via migrations can deteriorate performance because SQL Change Automation generates the static data in the form of individual INSERT statements for each row, and tracks changes via a line by line comparison between data in the source and target. Our recommendation is that it's fine to track tables with less than 10K rows, but for larger data sets we recommend the 'Seed data' method, where all data is saved to a flat data file and uploaded via a BULK INSERT statement. We display the number of rows each tracked table contains helping the user set up their project in a sensible way.
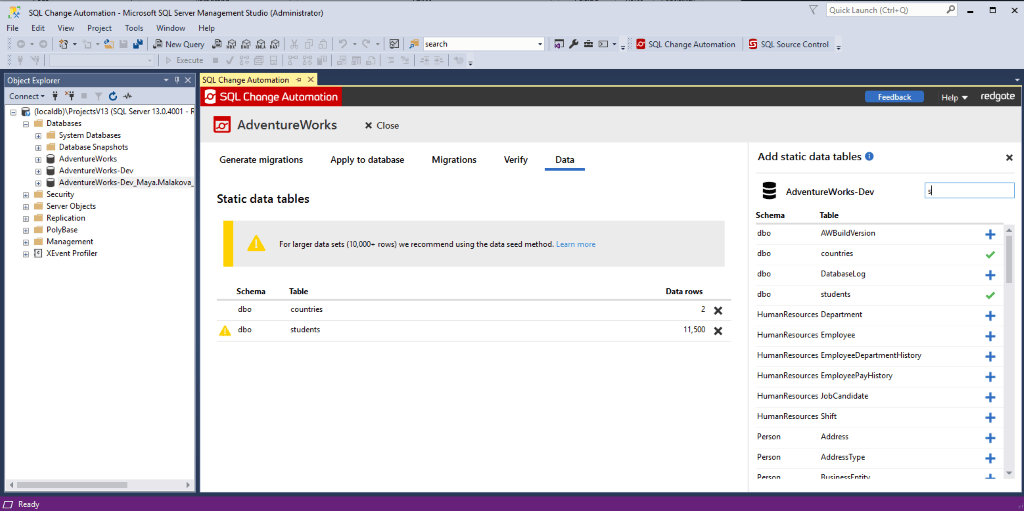 Row number warning
Row number warning
SQL Change Automation needs a primary key in order to track data so we try to make it obvious which tables can be tracked, and which ones would require adding a primary key first.
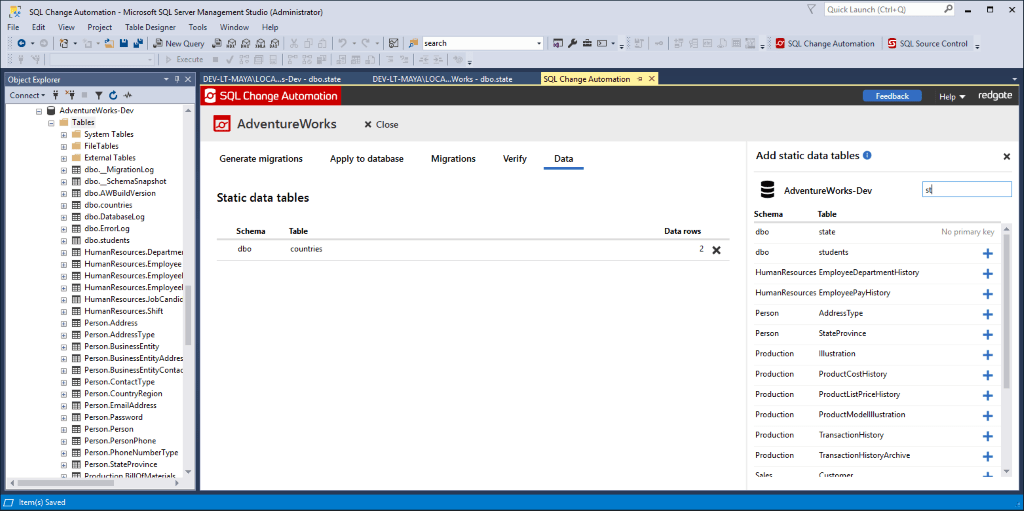 Table without primary key
Table without primary key
Column-level control of static data tracking
Some columns within static data tables, such as Date Created or Date Updated columns, might hold values that we don't want to replace with new values from development. Just hit the Edit pencil for a table you're tracking and select which columns you want to track (previously, it was only possible to exclude columns from tracking by manually editing the project settings file).
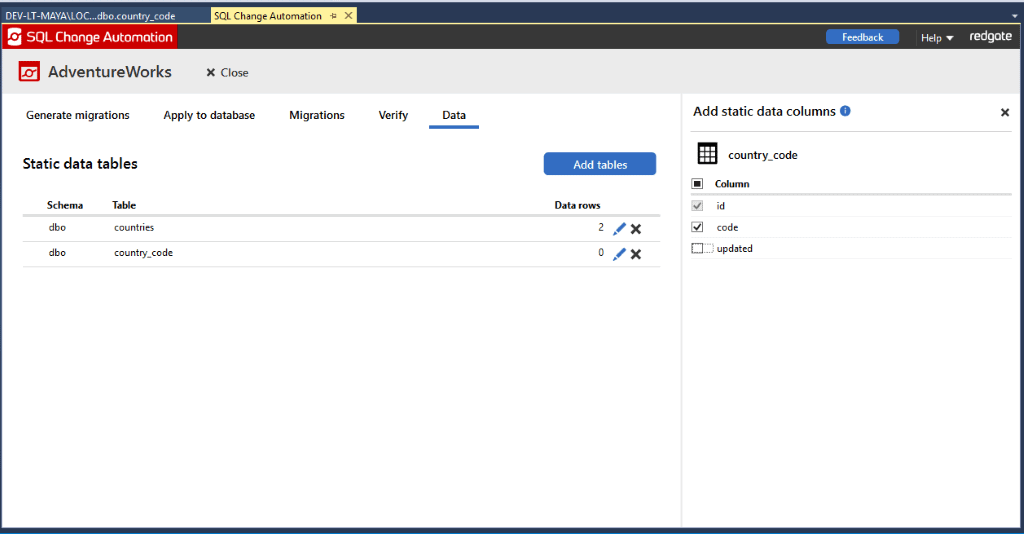 Column level configuration of static data
Column level configuration of static data
Seeing static data changes from within SSMS
Changes in static data are now visible on the Generate migrations view of the SSMS add-in.
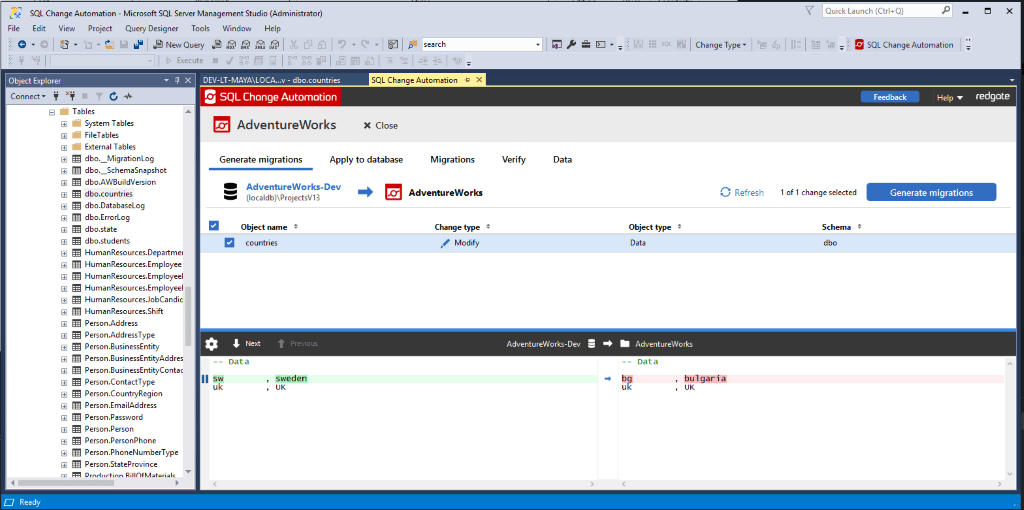 Data changes diff
Data changes diff
After confirmation, the newly generated migration gets included in the project. Once shared in version control the changes will be picked up automatically by the deployment components of SQL Change Automation, such as our Azure DevOps plugins, and deployed to a target database.
What do you think?
We'd love to find out what you think. Drop us an email at SCA-SSMS@red-gate.com
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Transaction-handling techniques in T-SQL deployments
How are transaction handled when deploying databases with SQL Change Automation? For the most part, we have resisted putting excess structure around the way that changes are deployed to your database. Unlike database projects that use the declarative-style of deployment, which work by synchronizing a source-controlled model of your schema to a target database, we opted for the imperative approach of migrations which hand the control of state transition over to you. The idea being that you don’t spend your time fighting a DSL which may offer productivity gains for common types of schema changes but tie you up in
Article
Documenting your Database with SQL Change Automation
Phil Factor uses SQL Change Automation and PowerShell to verify that the source code for the current database version builds successfully and, if so, to generate web-based database documentation using SQL Doc.
Article
Database Delivery with Docker and SQL Change Automation
Phil Factor demonstrates how to integrate SQL Change Automation into containerized workflows, such as are typical of a microservices architecture. He shows how to automate database builds into a Linux SQL Server container running on Windows, and then backup the containerized database and restore it into dedicated containerized development copies for each developer and tester.
Article
Moving from application automation to true DevOps by including the database
This article explains the challenges of DevOps automation for databases, starting with how to manage the database, as a set of SQL scripts, in the version control system, and then how to start building an integrated and automated script pipeline for continuously testing and deploying database schema changes, alongside the application code.
Article
We don't need no documentation - automating schema docs in SQL Change Automation
“Understanding the existing product consumes roughly 30 percent of the total maintenance time.” Facts and Fallacies of Software Engineering by Robert L. Glass. You should be documenting your database schema. I know it, you know it. Having current, accurate documentation available accelerates time-to-resolution for faults, aids tech-to-business conversations, and is a regulatory requirement for a great number of firms. Yet a majority of 214 respondent to our survey admitted that while they didn’t always have up-to-date docs, they knew they should. Do you work in a US-listed organization? Sarbanes-Oxley (SOX) clearly requires up-to-date documentation on where the financial data resides within your firm and how it’s
Article
Deploying Multiple Databases from Source Control using SQL Change Automation
How to automatically build multiple test databases, from source control, and then fill them with standard test data sets, using SQL Change Automation, BCP and some PowerShell magic.
Loading comments...