





Simple SQL Change Automation Scripting: The Release Object
My previous article described the DatabaseConnection, iProject and iBuildArtifact objects, but much of SCA's power is unlocked when we create the release object (iReleaseArtifact), which we can use to synchronize an existing target database with the source, while preserving any existing data. The release object contains the Update script to do the synchronization, an HTML report of the release, and a report of any code issues.
In this article, I'll illustrate how to access and use some of this information and then demonstrate some basic scripts for SCA build and update operations, with the release object, using as little PowerShell as possible.
Creating the Release Artifact
SQL Change Automation's build phase, described in my previous article in this series, produces an 'immutable' package representing a version of the database, and containing the validated source to build a new database from scratch, at that version, as well as produce database documentation. It can, when necessary, produce a release package that can be used for even the most complex deployment process.
We use the New-DatabaseReleaseArtifact cmdlet to create the iReleaseArtifact from one of a variety of possible sources. Generally, the source for creating a release package would be the BuildArtifact object, or a BuildPackage produced from it. However, for simple releases we can, instead, create it directly from the source database or even just by providing a ScriptsDirectoryPath.
The Update.sql script it produces is appropriate for a specific target database, or database at the same version. This means that each 'target' has its own release artifact, which contains everything required to update the database from the current version to the required version, while preserving data. SCA doesn't let you make a mistake, of course: it checks. The so-called 'target' is more appropriately referred to as the 'intended target' or 'version source' because SCA just pulls the metadata from it to compare with the source. This means that you can represent the intended target with either a live database, scripts directory, project file, BuildArtifact object or a BuildPackage. A test cell, for example, might have ten database copies but metadata for each will be identical, so you only need one 'intended target' and then the resulting release artifact can be applied to all ten of the 'real targets'.
Figure 1 shows the processes and data around creating the release artifact.

Figure 1: Creating a release object from a source and target database
The 'or' symbol (plus in a circle) here represents the fact that one of the alternatives can be used as a source. The words source and target on the lines going to the Cmdlet signify the name of the parameter. As discussed, the target parameter represents the intended target (or list of intended targets).
The Update.sql script produced will synchronize the target database so that its schema matches that database defined in the source. If you want a script that does a complete build from an empty database, you just provide an empty database, or empty script directory as the potential target. A build script is, after all, just a synchronization with an empty database. The iReleaseArtifact can also contain the pre/post deployment scripts and static data. It also has various other properties that can provide a lot of useful information besides, such as the output from a code analysis, in a CodeAnalysisResult object, to tell you if there are any issues, details of filters used, the switches, options, and warnings, and a record of source and target. We'll be illustrating these a little later.
Using the Release Artifact
We can apply the iReleaseArtifact directly to the target database, using the Use-DatabaseReleaseArtifact cmdlet. On doing so, it executes the Update.sql script that will synchronize the target with the source. SCA will also apply any pre-and post-deployment scripts and check that any static or reference data in the source matches what is in the target.
If you are feeling cautious, you can inspect the script first, from the iReleaseArtifact, or you can export all the database deployment resources to a directory with Export-DatabaseReleaseArtifact, so that you can review all the other update resources as well, such as the change report and deployment warnings.

Figure 2: Using a release object
The Use-DatabaseReleaseArtifact cmdlet first checks to make sure you have specified the correct release artefact for the target database and that the migration script isn't being reapplied. It does this by checking that the target database schema matches the 'intended target' (indicated by the target parameter) that was originally used to create the iReleaseArtifact object. If the schemas match, the synchronisation goes ahead. If the schemas don't match, SQL Change Automation will then know that something has changed, and it will give an error.
If no error occurs, SCA then checks whether the target database schema matches the source schema that was used to create the iReleaseArtifact. If they do match, then the cmdlet will finish as it can assume that the synchronization has already been done and so it has nothing to do, otherwise . If they don't match that the Use-DatabaseReleaseArtifact cmdlet executes the SQL script to update the target database. It logs any errors that occur in the execution but will continue executing the whole script. After executing the script, the cmdlet checks that the target database schema has updated correctly.
Simple database build and update operations using the release object
By studying the different ways to create the iReleaseArtifact (Figure 1), we can see that we can bypass the need for a build artifact, by just supplying a ScriptDirectoryPath as the input to New-DatabaseReleaseArtifact. This is useful if we only want to perform simple operations. What simple operations, I hear you ask?
Well, sometimes we aren't encumbered by all the usual real-life complications. For example, all sources and databases are reachable within the same network and there is no workflow, signoffs or coordinated build process with an application. In such cases, we can create the release object directly from the source, without needing the build object or package.
Deploying a database, along with pre- and post- deployment scripts and static data
This script will synchronize my target database with the Adeliza source directory. The Use-DatababaseReleaseArtifact cmdlet will deploy static data to the target database as well if the scripts for the data are contained in the source folder, indicated by the ScriptDirectoryPath. You can opt not to sync this data. The SQL Compare options specified in the iReleaseArtifact object will be used in the schema comparison checks before and after running the update.
|
1
2
3
4
5
6
7
8
|
Import-Module SqlChangeAutomation
<# ------- Synchronize a single target from source --------#>
$iReleaseArtifact = new-DatabaseReleaseArtifact `
-Source 'C:\Projects\GitHub\Adeliza' `
-Target "Server=MyServer;Database=MyDatabase;User Id=Phil;Password=MyPassword;"
-SQLCompareOptions 'NoTransactions' `
-AbortOnWarningLevel None
Use-DatabaseReleaseArtifact -InputObject $iReleaseArtifact -DeployTo $_.connection -SkipPostUpdateSchemaCheck >"$($env:TMP)\MyLog.txt"
|
The collection of the output into a file is to switch off verbosity in the main output stream, rather than for any real desire for a log. A detailed commentary is sent to the output by the cmdlet. We've chosen to use the scripts directory, but you can opt to use the NuGet build package or zip file, if you prefer. You still get the same good things happening.
Deploying several databases
This script shows a deployment to several target databases, each from its own source. It not only does the synchronization but also checks before to ensure that the target database is the same as the one used to generate the iReleaseArtifact, and afterwards to ensure that it worked. It will also automatically execute any pre- or post-deployment scripts and ensure that static data is synchronized.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
$targetsAndSources=(
@{'connection'= ' Server=FirstServer;Database=DatabaseFirst;User Id=Phil;Password=dunno;Persist Security Info=False';
'source'= 'S:\work\github\FirstDatabase\SQL'},
@{'connection'=' Server=FirstServer;Database=DatabaseSecond;User Id=Phil;Password=dunno;Persist Security Info=False';
'source'='S:\work\github\SecondDatabase\SQL'}
)
$ReleaseArtifacts=@()
$targetsAndSources|foreach {
$iReleaseArtifact=new-DatabaseReleaseArtifact `
-Source $_.source `
-Target $_.connection -SQLCompareOptions 'NoTransactions' `
-AbortOnWarningLevel None
Use-DatabaseReleaseArtifact -InputObject $iReleaseArtifact -DeployTo $_.connection >"$($env:TMP)\MyLog.txt"
$ReleaseArtifacts+=$iReleaseArtifact
}
|
As well as bringing the targets up to the same database version as the sources, this provides you with a list of reports from the individual release artifacts, contained in the $ReleaseArtifacts variable. You can iterate through them to find out the script used, the objects that need to be changed and so on.
Here you get each HTML report generated in a separate browser tab.
|
1
2
|
$ii=1
$ReleaseArtifacts|foreach{$ii++; $dest="$env:TEMP\$($_.Source.Name)($ii)changes.html";$_.ReportHtml>$dest;Start $dest }
|
Comparing two copies of a database
This script will compare the source and target database and display a tabbed HTML page with the script that would make the target identical to the source (see Figure 7), and a list of all objects that are different.(see Figure 8)
|
1
2
3
4
5
6
7
8
|
Import-Module SqlChangeAutomation
<# ------- Compare a source database with a target database --------#>
$iReleaseArtifact = new-DatabaseReleaseArtifact `
-Source 'Server=MyFirstServer;Database=MyDatabase;User Id=Phil;Password=WhoKnows;Persist Security Info=False' `
-Target 'Server=MySecondServer;Database=MyOtherDatabase;User Id=Phil;Password=HeavenOnlyKnows;Persist Security Info=False' `
<# now display the results as an HTML page #>
$iReleaseArtifact.ReportHtml> "$env:TEMP\changes.html"
Start "$env:TEMP\changes.html
|
Creating a single build script from a directory of object-level source files
This script uses create a release artifact using a directory of object scripts, or a single build script, as the source, and a blank (empty) directory as the target. It outputs the resulting Update.sql script and saves it as a build script to your temp folder.
|
1
2
3
4
5
|
<# ------- Create a single executable build script file from a source directory --------#>
$iReleaseArtifact=new-DatabaseReleaseArtifact `
-Source 'S:\work\github\AdventureWorks\SQL' `
-Target 'S:\work\github\AdventureWorks\Blank'
$iReleaseArtifact.UpdateSql>"$($env:TMP)\BuildScript.SQL"
|
Here's the sample build script:
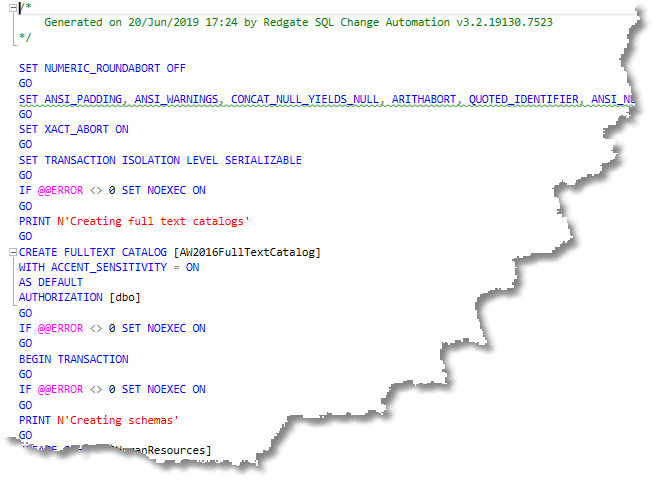
Figure 3: A build script created using New-DatabaseReleaseArtifact
Analysing the source code for issues
Here is how to do a static code analysis on your script, anything from a single script to a collection of object scripts, each in their own directory. Again, we compare the source directory to an empty directory and output the contents of the CodeAnalysisResult object, in the iReleaseArtifact, to a temp folder.
|
1
2
3
4
5
|
<# ------- Create a Code report from a database --------#>
$iReleaseArtifact=new-DatabaseReleaseArtifact `
-Source 'S:\work\github\AdventureWorks\SQL' `
-Target 'S:\work\github\AdventureWorks\Blank'
$iReleaseArtifact.CodeAnalysisResult.Issues>"$($env:TMP)\CodeIssues.txt"
|
Here's the report:

Figure 4: A code analysis report for the object-level source scripts, or single build script
If the long-from report is a bit unwieldy, you can just do a short-form list, sorted by line number of the error. Just change the last line of the previous listing to:
|
1
2
|
$iReleaseArtifact.CodeAnalysisResult.issues|sort-Object @{expression={$_.CodeAnalysisSelection.LineStart}}|
select CodeAnalysisSelection, IssueCodeName,ShortDescription >"$($env:TMP)\ShortCodeIssues.txt"
|
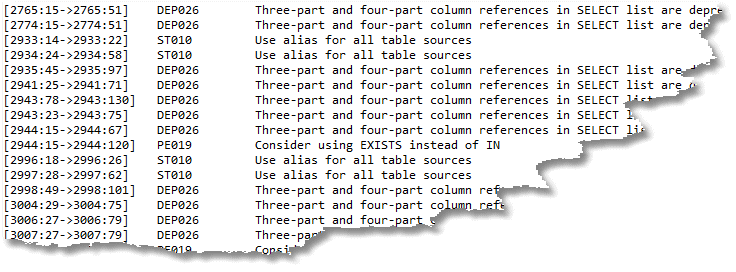
Figure 5: A short-form code analysis report
The code analysis is also included in the release report (Report.html), which we can save to our temp directory.
|
1
2
3
|
<# now display the results as an HTML page #>
$iReleaseArtifact.ReportHtml> "$env:TEMP\changes.html"
Start "$env:TEMP\changes.html"
|
Here are the list of the SQL Code issues, when viewing the report in your default browser.
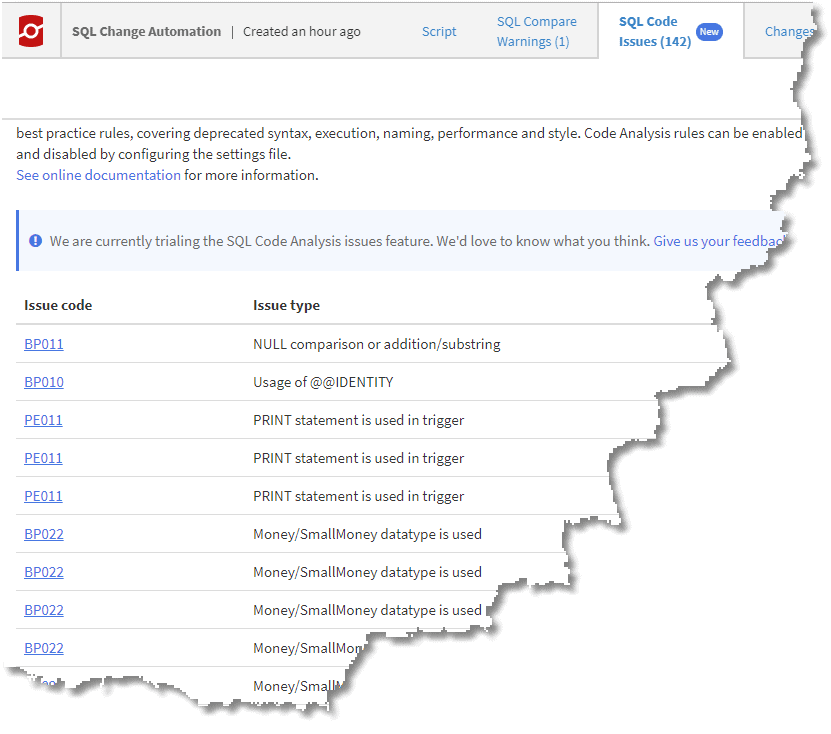
Figure 6: SQL Code Issues in the tabbed report
We also see the synchronization script that will be used.
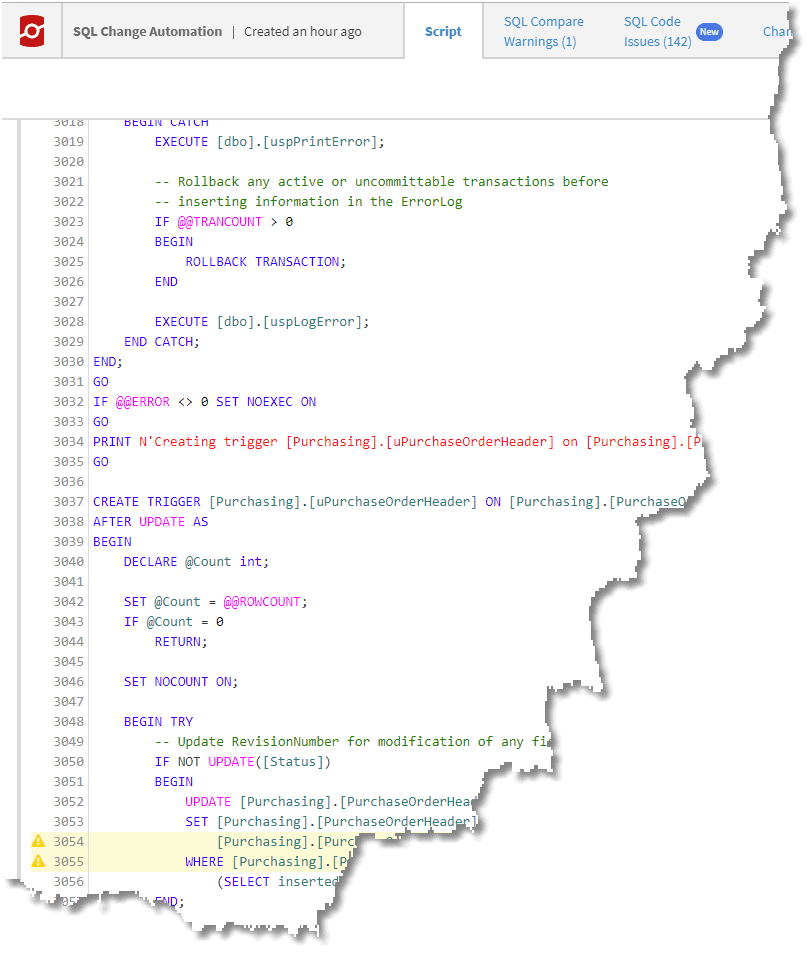
Figure 7: The change script in the tabbed report
All changes to the target are also obligingly listed, in the change tab of the report. These are useful, because they effectively list every object in the build script because we compared with a blank database.
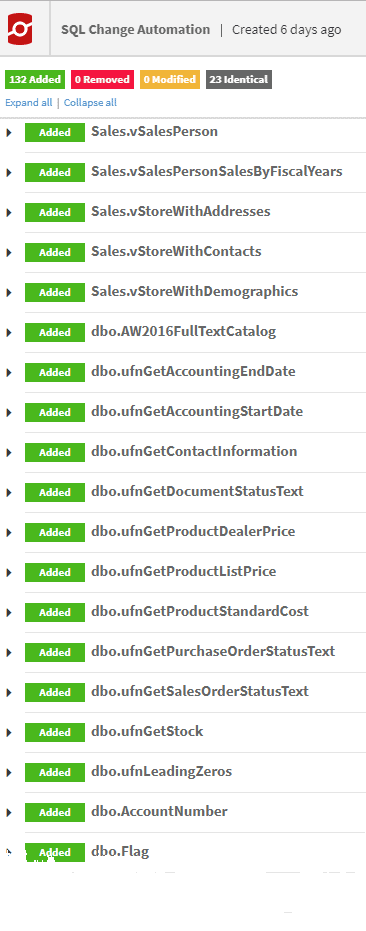
Figure 8: The list of objects on the target that will be changed
Conclusions
SCA automation is designed to be able to accommodate a wide range of activities associated with integrating, building, testing and deploying a database, and allow this process to participate in an application deployment, along with all the approvals, signoff, and other workflow processes. It provides all the objects necessary for this to happen. However, it can also be used, as I've illustrated in this article, for even routine database development operations.
To understand how SCA works and how to make full use of its features, it pays to understand the range of parameters the cmdlets can accept, and the nature of the data objects passed between these cmdlets.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Integrating SQL Server Tools into SQL Change Automation Deployments
Phil Factor shows how to integrate use of SQL Change Automation, SSMS registered servers, SMO, and BCP to automatically build or update a database on all servers in a group.
Article
Dealing with production database drift
For the SQL Change Automation team, it’s important that we take time out from development, occasionally, to explore some of the issues our customers face when automating database deployment. Following on from previous posts about cross-database and cross-server dependencies, this article shares some of our thoughts about how to deal with production database drift. If you’re using automated deployment for your databases, direct changes to your production environment can cause a headache. These unmanaged changes are known as database drift. To better understand the issues this can cause, our team created a test application we could work with; this was a
Article
SQL Change Automation 4.0: Collaborative Database Development Across Visual Studio and SQL Server Management Studio
SQL Change Automation's Development component for developing new databases and modifying existing databases, using migrations, now integrates directly into SQL Server Management Studio as well Visual Studio. It allows teams to collaborate effectively during development, regardless of their preferred IDE, and in a way that integrates easily with common build/integration servers and release management tools.

Article
Database Development with GitHub
How can you use GitHub to do team-based database development? This article proposes a process that splits development work into task-based GitHub branches, incorporates daily database builds and integration testing, and uses Redgate tools to automate tasks such as provisioning, database scripting, and testing.

Article
Using Filters to Fine-tune Redgate Database Deployments
Filters are used by Redgate's SQL Compare, SQL Source Control, DLM Dashboard, and SQL Change Automation. A typical use for a filter is to work on just one schema within a database or just a limited set of tables and routines. You would also want to use a filter to exclude certain object, such as database users, from comparisons. Phil Factor explains how they work, and how to create, edit and then use them within the various Redgate tools.

Article
Database Delivery with Docker and SQL Change Automation
Phil Factor demonstrates how to integrate SQL Change Automation into containerized workflows, such as are typical of a microservices architecture. He shows how to automate database builds into a Linux SQL Server container running on Windows, and then backup the containerized database and restore it into dedicated containerized development copies for each developer and tester.
Loading comments...