





SQL Change Automation Scripting: Getting Data into a Target Database
When you build a database from scripts using SCA, and need to get data into the target database, you can choose one of two strategies.
- Use
INSERTINTO…SELECTstatements – add a separate data directory to your source scripts, consisting of a series of executable data insertion statements - BCP the data in at speed – preferably with native format, using a post-deployment script.
The first strategy creates a data migration script, so it ensures that the data in the target is exactly what was in the data files in source control. When you are using SCA, it will first create a migration script for the schema, by comparing the source 'state' to the target database (SCA assumes the target database of any release already exists), and then do the same for any data. In other words, it will compare the scripts in the data directory with data in the target and generate a migration script to synchronize them. This ensures that the target schema and data is always the same as what's in source control. This is fine for small volumes of 'static' data, but it makes for a slow process with data of any quantity.
The second strategy is much faster, but if you need to be certain that the data in the directory is the same as what's in the target, then you will need to read it all in on every release, having first removed (truncated) existing data. This strategy also requires more PowerShell to make it happen.
My previous article Static Data and Database Builds explored more the theoretical side of deployments, builds and data, explaining the types of static data in databases, how to provide each type, and the implications for the deployment process.
The first strategy: data insert statements
I'll demonstrate the first strategy, using a data directory populated with scripts that load data into each table of the venerable pubs database, using INSERT INTO…SELECT statements.
To follow along, you'll need a copy of the pubs database, filled with a decent volume of spoofed data (generated using SQL Data Generator in my case), and an empty Data directory within your project's scripts directory in Git, which represents the current database version.
From the stocked pubs database, we create the SQL files that represent the data and copy them to the Data directory. These are easily produced from either SSMS by point 'n click, or automatically via SMO. I show how to do this automatically here in Scripting out SQL Server Data as Insert statements via PowerShell. If you use the PowerShell script, you'll need to change the line near the end so that each data file is in the form <schema>.<tablename>_Data.sql, which is what SCA understands:
"$($FilePath)\$($s.Name)\$($TheDatabase.Name)\Data\$($.Schema).$($.Name)_Data.sql";
Your Data directory will now have all the data scripts, in the right form for SCA to recognize We'll provide all this as a sample project to go with this article just to get you started.
Normally, you'd only want to do 'static' data tables with this method, but we're doing the entire database. On your target SQL Server instance, create a new database. I called mine, Adeliza, but if your cat has a different name such as Tom or Tabitha, please use that instead.
Now we will create a script to create a build artefact, and from that a release artefact that we can use on our target database. I describe the basics of this process in my first article in this series, Simple Steps in SQL Change Automation Scripting.
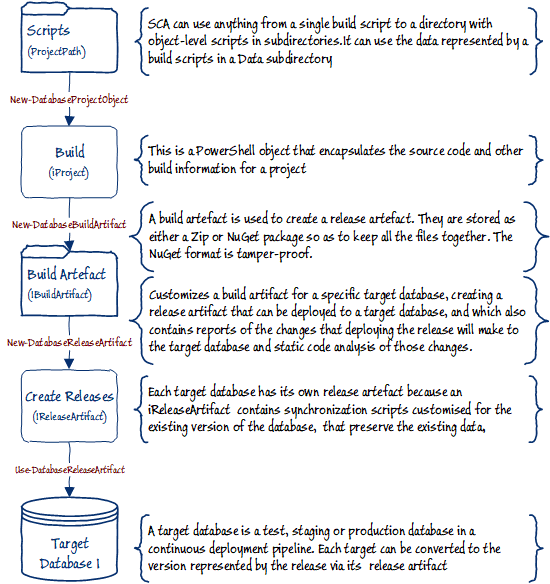
Here is the PowerShell script. You will, of course, need to fill in all your own details into the $project object, you will need to add the path to your scripts directory and the connection string to the SQL Server instance where you want to build the database.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
# Identify the project.
$project=@{
'version'='1.34';
'name'='Pubs';
$Description='A Demonstration of an SCA Release with the BCP of table data';
}
# the part of the shared path to this project
$PathToProject="Install\$($project.Name)"
# the essential details to define your source (a directory in our case)
$Source=@{
# Where the build scripts are stored (e.g. in Git)
'ScriptDirectory'='MyFilePathToScriptsscripts';
};
# the essential details to define your Target (an empty database in our case)
$Target=@{
# the connection string specifying the server and database
'ConnectionString'='Server=MyInstance;Database=Adeliza;User Id=PhilFactor;Password=MySecurePassword;';
}
#create the build artefact, using a project object
$buildArtifact= $Source.ScriptDirectory |
New-DatabaseProjectObject | #wrap up the script and create a build artefact
New-DatabaseBuildArtifact -PackageId $project.name -PackageVersion $project.version `
-PackageDescription $project.Description
#Create the release artifact
$iReleaseArtifact=New-DatabaseReleaseArtifact `
-Source $buildArtifact `
-Target $Target.ConnectionString
Use-DatabaseReleaseArtifact $iReleaseArtifact `
-DeployTo $TargetConnectionString `
-SkipPostUpdateSchemaCheck `
-SkipPreUpdateSchemaCheck
|
Run this, and you will find that your target database is the same version of the pubs database, with spoofed data in it.
There are good and bad sides to this strategy for doing the build. The downside is that for anything more than a small volume of data, say a few hundred rows, this is going to be dead slow, for two reasons. Firstly, SCA stores all this data in the release artefact, and then compares this data, row by row, with any data that exists in the target. Secondly, the actual data loading process uses single row INSERT statements. This is hardly going to worry you if it is a routine overnight automated build, but it might if you were doing continuous builds on every commit, or if your database is still doing its overnight build when you start work.
There are upsides too. Firstly, you can run it safely with an existing database and it will just check that both the schema and data match what is in source. Secondly, the data can be packaged up in a zip or NuGet package and this package can then be used to create individual release packages for each target server.
For any significant volume of data, however, you will want to use a fast bulk-import way of inserting the data into a database. There comes a point where having all those duplicate copies of the database data, one for each release, starts to get silly. Also, the 'static data' device will just be too slow.
The second strategy: native BCP
The second strategy is to use a network-based data directory that contains bcp files and use bulk insert to put the data in the database, as a post-release script. This is more suitable for a fresh build rather than a migration so as the script stands, it will only perform an insertion of data if there is none there already. As an alternative, you can of course truncate the table before you bcp the data into it.
To do a bcp, you can either:
- 'Pull': import the data from a file that is local to the server hosting your target SQL Server instance, using SQL-based
BULKINSERT. - 'Push': import the data via TDS using a network connection.
To keep things simple, and to keep as much as possible within SCA, we'll use a post-release SQL script for this, rather than extending our PowerShell script to perform the data input.
The only complication of doing this is that, before we do the release, either we need to copy the bcp files onto the server, or give SQL Server the rights to access a file across the network. The latter can get complicated to do securely with a SQL Server login unless you enable security account delegation, so we'll use the former strategy, setting up a file-share on the Windows server hosting the target database, and copying the bcp files into it. This allows SQL Server, with the sysadmin login, whether a Windows-based or SQL Server login, to read the local bcp files for the BULK INSERT.
Let's try it out. First, we'll create some bcp files. We aren't going to include this lot in the package but instead we'll put them in a directory of our choosing. Here, in Scripting out SQL Server Data as Insert statements via PowerShell, is a routine for extracting a set of bcp files from a database. You just change the $UseBCP =$false; statement to $UseBCP =$true; and out they pop as bcp files.
We create another new target database, called Tabitha, or whatever you like, on whatever available SQL Server instance you choose, to create a copy of our pubs database. Having done this, you can then use this information to create a connection string to your new database.
You then can execute a rather more complicated version of the previous script, although the diagram is the same as before. The only difference is the creation of a post-deployment script which is executed by SCA once the database is built. This script just creates a string containing a series of BULK INSERT statements, one for each table and then executes it. I've written it so that it checks for the existence of each table and allows you to provide a comma-delimited list of all the tables that you want filled with data. It defaults to all (%) tables but you just give a list of all the tables you want, using the SQL wildcard syntax, and the routine removes duplicates for you.
After it is all done, it enables constraints. If you don't want to do this, as when you merely want certain tables filled at this stage, then you just blank out the '$afterthought' string in the PowerShell script.
Again, fill in all your own details into the $project object, add the path to your scripts directory and the connection string to the SQL Server instance where you want to build the database. You also need to tell the script the UNC address of the file-share on the Windows server hosting SQL Server, and the local address to the file-share on the Windows server. This local address will be used by the SQL BULK INSERT to get the file via a local directory for which the sysadmin user will have the rights.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
|
# Identify the project.
$project=@{
'version'='1.34';
'name'='Pubs';
$Description='A Demonstration of an SCA Release with the BCP of table data';
}
# the part of the shared path to this project
$PathToProject="Install\$($project.Name)"
$TableList='%' #comma-delimited list of files, use the SQL LIKE syntax % and _ rather than * and ?
# the essential details to define your source (a directory in our case)
$Source=@{
# Where the build scripts are stored (e.g. in Git)
'ScriptDirectory'='MyFilePathToScriptsBCPscripts';
};
# the essential details to define your Target (an empty database in our case)
$Target=@{
# The network address of the shared directory on the server
'NetworkShare'='\\MYINSTANCE\Data';
# the local file address of the shared directory above
'LocalDirectory'='D:';
# the connection string
'ConnectionString'='Server=MyInstance;Database=Adeliza;User Id=PhilFactor;Password=MySecurePassword;';
}
# The network path to the data for the project on the server
$TargetDataNetworkDirectory="$($Target.NetworkShare)\$PathToProject\Data"
# the local path to the data
# Enable constraints after a BCP. Only a good idea if all tables are filled.
# leave blank if you don't want then rnabled.
$Afterthought='EXEC sp_msforeachtable "ALTER TABLE ? WITH CHECK CHECK CONSTRAINT all"'
<# we create the SQL Post-build script that puts the data in for all the tables
that you want. If you want them all just specify with a % sign in the list. The
SQL prevents duplicates #>
$SQLString=@"
DECLARE @ourPath sysname = '$($Target.LocalDirectory)\$PathToProject\Data';
Declare @OurFiles nvarchar(max)= '$TableList';
Declare @command NVARCHAR(4000)
Declare @next int,@End int
Declare @TableNames table (tablename sysname)
Declare @file nvarchar(80)
Select @next=1 --parse the list and scan the tables for each.
while (1=1)
begin
Select @End=CharINDEX (',',@OurFiles+', ',@next)
if @End=0 break;
Select @file=rtrim(ltrim(SUBSTRING(@OurFiles,@next,@end-@next))),@next=@End+1
Insert into @TableNames(tablename) select object_Schema_Name(object_id)+'.'+name
from sys.tables
left outer join @TableNames already
on object_Schema_Name(object_id)+'.'+name like TableName
where already.tablename is null
and name like @file
end
Select @command=''
Select @command=@command+
'
print ''Reading Bulk Data into '+tablename+'''
BULK INSERT '+tablename+'
FROM '''+@OurPath+'\'+replace(tablename,'.','_')+'.bcp''
WITH
(
DATAFILETYPE = ''native''
);
'
from @TableNames
Execute (@Command)
$Afterthought
"@
<# we now save the post deployment script. The script will only load the data
if it hasn't already been done #>
$SQLstring >"$($Source.ScriptDirectory)\Custom Scripts\Post-Deployment\PostScript.sql"
#create the build artefact, using a project object
$buildArtifact= $Source.ScriptDirectory |
New-DatabaseProjectObject | #wrap up the script and create a build artefact
New-DatabaseBuildArtifact -PackageId $project.name -PackageVersion $project.version `
-PackageDescription $project.Description
#Create the release artifact
$iReleaseArtifact=New-DatabaseReleaseArtifact `
-Source $buildArtifact `
-Target $Target.ConnectionString
<# Now we can copy the data over. First make sure the data directory
exists #>
if (-not (Test-Path -PathType Container $TargetDataNetworkDirectory))
{
<# we create the directory if it doesn't already exist #>
$null = New-Item -ItemType Directory -Force -Path $TargetDataNetworkDirectory;
}
<# Now copy the data to the local file system so it can be accessed by SQL Server
without having to give exptra permissions #>
Copy-Item -Path "$($Source.DataDirectory)\*.bcp" -Destination $TargetDataNetworkDirectory
# use the releaseArtifact to update or create the database
Use-DatabaseReleaseArtifact $iReleaseArtifact `
-DeployTo $TargetConnectionString `
-SkipPostUpdateSchemaCheck `
-SkipPreUpdateSchemaCheck
<# now display the results as an HTML page #>
$iReleaseArtifact.ReportHtml> "$env:TEMP\changes.html"
Start "$env:TEMP\changes.html"
|
If all goes well, you will have a very much more rapid build of your database, fully stocked with anonymized data.
If you try out both versions, it is better to create two separate script directories in Git, one for each strategy. The problem is that they fight: if there is a Data directory, then SCA will it, and if there is a post-release script, then it will also be executed.
Conclusions
There are many reasons for needing data in your database build. You can use SCA to build a database and stock it with data in some or all the tables. For a small database, or a database where you only need just a few small tables, stocked with 'static' data, it is fine to use the strategy of specifying the data for your static tables via INSERT statements, in a data directory. Where you need to insert more than a few hundred rows, then you will be faced with needing to use bulk input of data, preferably in native-format data files. Fortunately, SCA can be used with either strategy.
Resources
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Handling System-named Constraints in SQL Compare
If some of your database constraints have system-generated names, they can cause 'false positives' when comparing schemas and generating build scripts using SQL Compare or SQL Change Automation. Phil Factor explains the difficulties, and the Compare option you need to enable to avoid them.
Article
Using Filters to Fine-tune Redgate Database Deployments
Filters are used by Redgate's SQL Compare, SQL Source Control, DLM Dashboard, and SQL Change Automation. A typical use for a filter is to work on just one schema within a database or just a limited set of tables and routines. You would also want to use a filter to exclude certain object, such as database users, from comparisons. Phil Factor explains how they work, and how to create, edit and then use them within the various Redgate tools.
Article
The Whys and Wherefores of Untrusted or Disabled Constraints
Having untrusted or disabled
FOREIGNKEYorCHECKconstraints in your databases will degrade data consistency and integrity and can cause query performance problems. Phil Factor explains how to detect these and other table-related issues, during development, before they cause trouble further down the line.Article
Baselining a SQL Change Automation project from an existing database
This article show how to create a 'baseline' for your Visual Studio SQL Change Automation project, from an existing, target SQL Server database, so that the team can start making changes and easily deploy them to the target database.
Article
Automating Builds from Source Control for the WideWorldImporters Database
Kendra Little shows how to get the WideWorldImporters database into version control, using SQL Source Control, and then set up an automated database build process, using Azure DevOps with SQL Change Automation.
Article
Database Development with GitHub
How can you use GitHub to do team-based database development? This article proposes a process that splits development work into task-based GitHub branches, incorporates daily database builds and integration testing, and uses Redgate tools to automate tasks such as provisioning, database scripting, and testing.
Loading comments...