




Moving from application automation to true DevOps by including the database
The goal of database DevOps automation is synchronized deployment of tested and reliable database schema changes, for each application update. The biggest motivation for including the database in your DevOps strategy is to increase the speed of delivery of database changes, improve the reliability of those changes, and decrease the incidence of deployment failures that can results in rollbacks and prolonged service downtime.
The biggest challenges are the perceived difficulties in overcoming different development approaches to the application and its underlying database, and the disruption that is anticipated, as a result. Therefore, any DevOps automation tool must allow an organization to integrate and synchronize database changes with the deployment process for the application. It should also allow a standard way of managing database changes across different databases.
State of Database DevOps report
There is a growing motivation, in many organizations, to integrate database changes into a DevOps process. The recent State of Database DevOps Report revealed 89% of companies have now adopted some aspects DevOps, or will within two years, and that 70% of companies now have to manage changes across two or more different database systems.
What's required is a pipeline that automates database script deployment in a way that coordinates these database upgrades directly with changes to the associated application. The best way to achieve this is to always build a database from a known version of the code, stored in the source control system. This will allow the team to automatically deploy the tested and verified database changes that ensure that the database and application are always at compatible versions. I'll describe how this can be achieved with Redgate's DevOps automation solution, Redgate Deploy.
Application deployment pipelines
In a typical application automated script pipeline for application deployments, each new release is linked to source-controlled versions of the application code so the changes made in development can be associated directly to what has been deployed.
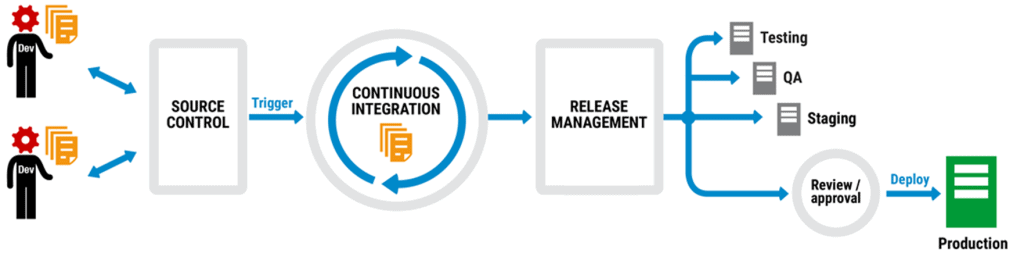
Figure 1
SQL deployment challenges
Any deployment, whether for the application or database, needs to be linked to a source-controlled version so we can associate the changes made in development to what has been deployed. So, we'd like to put the database into source control, and treat database changes in a similar way to application changes, but there are some additional challenges.
Persisting data during upgrades
Application code is easy to change, but with a database the data must persist. You can't simply drop and replace the database, like you would an application.
When we update the database schema, for example altering a column's data type, we must do so in a way that preserves the business data. This may require additional 'migration scripts', which must also be in source control, to enable existing data to fit in any changed schema. An example might be trying to deploy a change that added a NOT NULL constraint to a column with existing data. We'd need to write a migration script that loaded a default value to any NULL columns in the table, store that script in source control, and incorporate it in the automated deployment process.
Loading static data and test data
While your database is designed to store customer and transaction data, it will not function unless certain tables are "pre-stocked" with any immutable data required for dependent applications to function. It might be something as small and simple as a list of countries within which your organization can trade. This sort of lookup data, as well as seed data, enumerations, and more, all the data that makes your system work, and it all needs to be stored in source control and deployed alongside schema changes.
You also need to think about how to provision realistic data for development and testing. How do you test the latest build in development with production or production-like data, for example, while ensuring that private and sensitive data is protected, in all environments?
A working database system is more than schema-plus-static data
A SQL Server database of any size will consist of many components on top of the SQL DDL code. As well as database-scoped objects and configuration settings, there are instance and server-level objects and settings to consider.
Special care needs to be given to the security configuration of any database. Certain objects (database users and roles) are database-scoped, but other users, roles and permissions are server-scoped. Ideally, you'll separate out entirely your handling of users, roles and permissions, from the handling of code and schema changes.
To deploy a complete, and standardized database environment, you'll need a configuration file, in source control, that provides a single reference file for all login and user details and the roles to which these users belong, and then another to define the permissions assigned to these roles.
In addition to security objects and static data, there is also likely to be agent jobs, external files, SSIS components, .NET libraries, PowerShell scripts, R and python scripts and modules, and a host of other components.
Our 'deployment package', in source control, needs to contain everything that is are essential for the working database, and to create the basic database and environment, reproducibly, on every target SQL Server instance, in both development and pre-production environments.
Database drift
How long does it take to make a one-line database change, run it through the normal testing process and get it to production? If your answer is measured in days, weeks or months, then you have a few problems. Firstly, delivery time for any significant new functionality will be slow. Secondly, then when you hit a production issue, you won't always have time to go back to the source code, make the fix, test it, and then redeploy. Instead, the DBA will often perform a hot fix, directly on the production database.
This drift causes inconsistencies that undermine tests and can cause failed deployments, either because code clashes, or because important fixes are accidentally rolled back.
Approaches to database source control
If you just want to tear down the current database version and build a new version then, leaving aside for a second all the "extra bits", all you need in source control is the SQL DDL scripts describing the current 'state' of every database object (plus any required static data), and an automated means to create each database object in the correct dependency order.
However, what if you need to update an existing database? For database code objects, such as stored procedures and functions, your strategy is the same. For table changes, however, you may also need to store a set of change, or migration, scripts describing how to alter the metadata of the database, as defined by its constituent DDL creation scripts, from one database version to another, whilst preserving the data held within it.
So, what database artifacts should be in source control? The database DDL code, or the migration scripts? The answer is "both", but different tools take different approaches.
In Redgate Deploy each of the database changes, often ALTER commands, are organized in SQL scripts. These migration scripts are executed automatically, in order, to migrate a database from one version to the next, while preserving any existing business data. The tool automatically tracks which script have been applies to the target database, and the final version of that database.
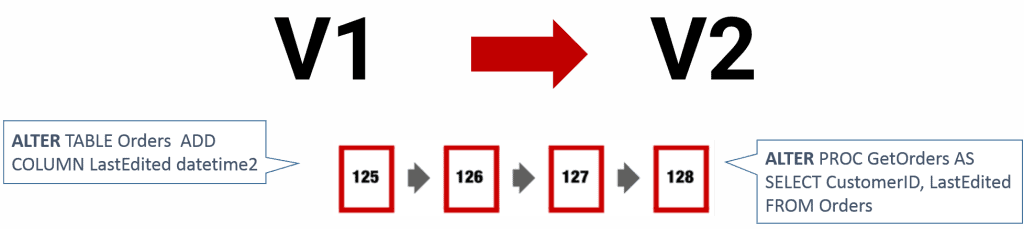
Figure 2
Alternatively, a tool like SQL Source Control, which is a plug-in for SQL Server Management Studio (SSMS), stores in source control the current state of each object in the database, as a CREATE script. SQL Source Control compares the set of CREATE scripts to the target database and auto-generates a script to synchronize the two states, again using the SQL Compare engine.
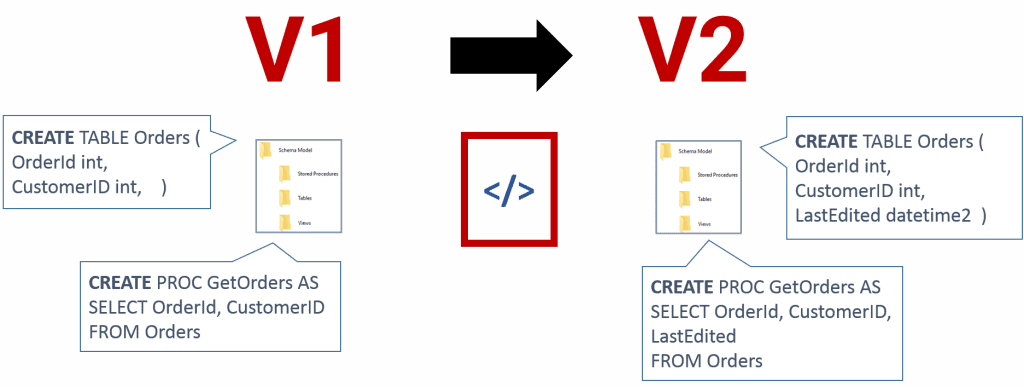
Figure 3
The two approaches are not mutually exclusive. Sometimes, you'll need the per-object history and rollback advantages of the state-based approach. Other times, you'll want the closer control over the deployment code or the dependency ordering that the migrations-based approach offers. If you use the state-based approach, you'll occasionally need to handcraft correct change scripts to define the correct route for migrations that affect existing data. Tools that use the migrations approach often "back fill" the state of each object, at each version, so that we can see easily how the object has changed over time.
Also, it makes little sense to retain a string of changes scripts of a code-based database. All you need to store in source control is a single script that creates the object, if it doesn't exist, or alters it otherwise, so that existing permissions on that object are retained.
Automated database script deployments from source control
For Oracle and SQL Server databases, Redgate Deploy provides additional functionality to help you control and automate database build, continuous integration, and deployment processes. For example, to automate these processes for SQL Server databases, Redgate Deploy includes SQL Change Automation, which has the following components:
- A Visual Studio plug-in – to auto-generate database migration scripts for a source-controlled database
- PowerShell Build components – to validate the database build or update scripts, create and test the build, and produce a build package you can publish
- PowerShell Release components – for automated deployment of the build package.
- Add-ins - to extend some of the more common delivery tools such as TeamCity, Visual Studio Team Services (VSTS), MS Build, Bamboo, Jenkins, Octopus Deploy and TFS.
You can use SQL Change Automation directly in Visual Studio, and it will auto-generate the correct deployment script from all the required change scripts. It also supports a state-based approach for source control of stored procedures, triggers, views, and functions. Alternatively, SQL Change Automation will generate the deployment scripts from the latest versions of the CREATE scripts for each object, as defined by a SQL Source Control project. In fact, it will work with whatever is in source control, if the directory structure is compatible with SQL Compare.
Regardless of your starting point, once your database and application are in source control, the deployment pipeline is the same, and can use the same tools and techniques. SQL Change Automation is designed to adapt to your chosen development techniques, and to integrate smoothly with your existing development toolchain, including source control, build, integration, deployment tools. SQL Change Automation is a PowerShell-based tool, making it easy extend and adapt the processes that run as part of a database build or migration. Simply include the PowerShell scripts in deployment package (a NuGet package) and run them pre- or post-deployment.
Our goal was that by using SQL Change Automation, our original application deployment pipeline, shown in Figure 1, needs a subtle tweak to incorporate the database.

Figure 4
It looks tempting, doesn't it? The changes to both the application and database are committed to source control, which can then trigger a continuous integration process to test the changes, before they go through to release management, where the DBA can check the database deployment scripts before they leave development.
SQL Change Automation, and other components of Redgate Deploy, will help address many of the database deployment challenges we discussed earlier in the article, but, for example, SCA will:
- Wrap into a single Nuget package all the components you need to build or update a database and establish a functioning database system. A tool such as Octopus Deploy or PowerShell Remoting can then deploy the package across a network.
- Build or update the database automatically from the build script, migration script or object source
- Validate the build – it will run pre-build syntax checks and can perform static code analysis. It will also integrate with a tool such as SQL Doc to document the database.
- Perform database testing – it can run tSQLt unit tests directly, and other tests using PowerShell scripting, and through integration with your CI Server.
- Automate deployments – you can run simple deployments directly within SCA, using PowerShell, and integrate with a release management tool such as Octopus deploy
Redate Deploy is useful not just for moving database changes towards production, but also for provisioning individual developers with their own copies of databases to use in sandboxes, and for rapidly setting up test servers.
SQL Change Automation will produce the validated and tested build, plus any 'static' data and then you can then load test data, either from the NuGet package, or by integrating with a tool like SQL Data Generator. SQL Clone will then create an image of this database and then quickly deploy copies (clones) to each required development server, allowing developers to self-serve databases, as required.
Closing thoughts
I gave a presentation on this topic at the Computing DevOps Summit in London, in 2017. In the Q&A session afterwards, I was asked what I though was the biggest hurdle to implementing Database DevOps. The answer is simple: getting people working together in the right ways.
The right people must talk to each other, work with each other, and collaborate with each other. As Donovan Brown, Senior DevOps Program Manager at Microsoft, puts it:
"DevOps is the union of people, process, and products to enable continuous delivery of value to our end users."
Note that he puts people first. A tool like Redgate Deploy encourages collaboration. It promotes an agile approach to change management, with small changes committed frequently, tested continuously and released early, for inspection and verification by others. For example, packages together all the tested scripts, change reports and other deliverables of release in a way that it is easy for others to review. This will make the development and delivery process more visible so that it becomes much easier for other parts of IT, such as operations, to get involved as early as possible to provide their expertise.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Live training session
How and When to Use the Hybrid Workflow of SQL Source Control with SQL Change Automation Migrations
Redgate’s SQL Toolbelt gives you options: you may customize the way you author, version control, and deploy your code depending on how you want to work. In this training session, Kendra Little will show you: - How to choose the right workflow to fit your team’s skills, preferences, and goals - How to get the process right with build processes, environment creation, and automated testing - A technical look at an implementation of the hybrid workflow in action - Best practices for teams implementing the hybrid workflow

Article
Using database replication with automated deployments
For the SQL Change Automation team, it’s important that we take time out from development, occasionally, to explore some of the issues our customers face when automating database deployment. Following on from previous posts about cross-database and cross-server dependencies and production database drift, this article shares some of our thoughts about how to deal with database replication. Database replication is the copying and synchronizing of selected data and database objects from one database to another. When making automated deployments to databases that are being replicated, you can easily run into problems. We experienced this recently when we tried to make changes to
Article
Deploying cross-database dependencies to different environments
The SQL Change Automation team here at Redgate occasionally take time out from development to explore some of the issues our customers face when automating deployment of database changes. As part of one such exercise, we took a closer look at cross-database and cross-server dependencies – these can cause problems when deploying databases to multiple environments which might be configured differently. To better understand the issues, we created a test application we could work with; this was a system for a fictional company called Lightning Works. We used SQL Change Automation and Octopus Deploy to deploy two databases, a website, and
Article
Baselining a SQL Change Automation project from an existing database
This article show how to create a 'baseline' for your Visual Studio SQL Change Automation project, from an existing, target SQL Server database, so that the team can start making changes and easily deploy them to the target database.

Article
Deploying Data and Schema Together with SQL Compare or SQL Change Automation
You want to use SQL Compare or SQL Change Automation (SCA) to create or update a database, and at the same time ensure that its data is as you expect. You want to avoid running any additional PowerShell scripting every time you do it, and you want to keep everything in source control, including the data. You just want to keep everything simple. Phil Factor demonstrates how it's done, by generating
MERGEscripts from a stored procedure.
Article
Overcoming Database DevOps Challenges: Part 1
As part of our research for the 2021 State of Database DevOps report, we asked 3,000+ recipients what they consider to be the greatest challenge when integrating database changes into a DevOps process. According to the respondents, these are the most important challenges facing database professionals when introducing DevOps practices to database development. Three of these relate directly to the need to standardize and coordinate, where possible, the parallel approaches to application and database development. They are: Synchronizing application and database changes Overcoming different approaches to application and database development Keeping up with the speed of delivery of applications This
Loading comments...