





Database Deployments and Rocky Rollback Horrors: Where Does the New Data Go?
A migration script is used to move a database from one version to another. By far the most common route is to migrate 'forward' from one release version to the next, but the cautious development team will also create a 'rollback' migration script that will, if necessary, revert a database to the previous version.
With these two types of script, it is theoretically possible to move from one release version to any other, from v1 to v3, say, simply by chaining together the v1-v2 and v2-v3 migration scripts. Of course, it usually simpler to create a single script to move directly between from v1 to v3 (or in the reverse direction). However, script chaining becomes necessary when each migration script needs to provide the means of preserving existing data from one version to the next, specifying precisely how data must be moved to accommodate it on the new version.
SQL Compare or SQL Change Automation will do the hard work of preparing these scripts for you. Whether you're doing a migration, build, or rollback, the SQL Compare engine will produce a script that create or removes objects in in the correct dependency order, within a transaction, and with all the necessary error handling. It is a task that is best left to the resolute methodical nature of the computer. Human error generally makes us a distant second-best at this task. SQL Compare deals with many common issues in preserving data between versions, but if it spots a problem while doing this chore, it lets you know the tables, and you will then fine-tune the script it creates to move the data in line with the developer's intentions. We humans are still occasionally required.
Mostly, this is simple to do, as I've described elsewhere. However, occasionally, such as when you release a new version, users make subsequent changes to the data, but then you spot a problem and need to rollback. It can get complicated.
When delayed rollback happens
There are three cases where a database change must be rolled back. I've described them in detail in a previous article, but will summarize them. Only the third type features the problem we're describing here, which is when there is no obvious place to place the new data added since the release went online and live.
Transactional rollback of migration scripts
Migration scripts must account for what happens if they fail during execution. It is a bad idea to leave a database in an indeterminate state between versions. By far the easiest approach to prevent this is to run them in a transaction, with error handling that rolls back the entire transaction if an error happens. Build scripts have a related but simpler requirement: they start with an empty database or schema, unlike migration scripts, so they just have to leave a clean unoccupied database if they fail, but even these scripts are simpler done within a transaction.
Rollback scripts without subsequent data changes
If a migration script is executed outside a transaction, but when offline, in single-user mode, there must be a twin script that can be executed to undo any changes that were made before the script failed or hit an error. This must be idempotent so that it checks each change and undoes it only if it still exists. Because users have had no opportunity to access the system, there is no special problem with migrating data
Rollback scripts after data changes
If a migration to a new production version of a database fails after users have been able to make subsequent changes, we may be required to roll back to the previous version. However, we must not lose any data in doing so. With trivial changes in a release, it isn't likely, but if you've made more radical changes to the database to allow more sophisticated data structures, there is nowhere logical in the previous version to preserve all the new data that the users will have been keenly feeding into the system and using.
The data problem with rollback scripts
Let's imagine the far-fetched example. You are using the venerable PUBS database to run your wholesale book business. Suddenly, you become aware of the need to deal with audiobooks. The developers obligingly add the extra tables and columns. The new release of the Pubs application and database goes live, and the staff fall upon it and enter all the audiobooks on the market, along with wonderful images, videos, blurb and so on. After two week's work the system increasingly shows a horrible intermittent bug. Who know, maybe the developers used TEXT fields and their associated special functions, and a lot of COM components. In any case, you must roll back to the previous release while you locate and eliminate the problem. Rollbacks must preserve existing data, of course. However, there is a lot of data about audiobooks that has no location in the old version of the PUBS database.
What you want to do is to roll back to the previous version, fix the problem quickly, and then release the healed database as a subsequent version, with the extra data in place. You can't expect the business to use the increasingly fragile current release while you develop, test, and release the new version with all the fixes because the organization has to maintain its existing book wholesaling business.
The seasoned DBA, faced with this problem, will probably BCP out the new data from the tables, and squirrel the resulting BCP files away somewhere in the file system. This DBA will then have to devise a way of replacing the data within the new table design, when the new healed version is released, and before it goes live. The problem here will be keeping all the materials for the release together as part of the new deployment package and remembering the point in the sequence of the database development where this rollback happened in case it must be repeated in a subsequent migration. It also means that movement between versions can no longer be done using just the appropriate rollback and migration scripts.
There may be no possible place in the previous version to put the data that was added in the current 'broken' version. If you solve the problem by adding tables in the previous version to store the data in them, then it's no longer the previous version.
The 'Limbo' solution
Limbo refers to the place that those who die in original sin are left if they have not been assigned to the Hell of the Damned. I refer to a database Limbo as being the place that data is stored if it cannot, in this version of the database, be assigned to one or more relational tables. This was difficult to do before XML and JSON.
With this strategy, every database is provided with a single 'Limbo' table that stores as many JSON collections as are necessary. Only a Sysadmin can access these collections. This allows you to store the data and associated metadata for as many tables or views as you need without any metadata changes at all. If a rollback script is faced with removing a table without having any place for the data in the source version of the database, it is stored in 'Limbo'. This means that the data stays within the production database: it simply isn't easily accessible from that version. In our case, the version that we regress to has no understanding of audiobooks yet can store the data in a format that is easily restored when necessary.
The data is all held within the access control of the database, so it presents no security issues. Also, the data is backed up with the rest of the database, so there isn't a recovery problem. An upgrade to the next version just requires a post-deployment script to re-insert the existing data.
It is possible to provide a JSON schema for each reverted table, but I think this is probably overkill. There is little danger of forgetting the table design because it will be in source control. It will, however, need enough attached information to be certain of selecting the right table-source for each table, at the right version.
Storing data in a limbo table is easy. As an example, we'll save all the data from the Prices table into just one row in the limbo table:
|
1
2
3
|
INSERT INTO limbo (version, sourceName, JSON)
SELECT '1-2-1', 'All prices',
(SELECT * FROM prices FOR JSON AUTO);
|
To restore it into a relational form, we just have a query like this:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
SELECT Price_id, Edition_id, price, advance, royalty, ytd_sales,
PriceStartDate
FROM
OpenJson(--we retrieve the table from limbo.
(SELECT JSON FROM limbo
WHERE version = '1-2-1'
AND sourceName = 'all prices'),
'$'
)
WITH
(--we can instantly convert it to tabular form.
Price_id INT, Edition_id INT, price NUMERIC(14, 4),
advance NUMERIC(14, 4), royalty INT, ytd_sales INT,
PriceStartDate NVARCHAR(27)
);
|
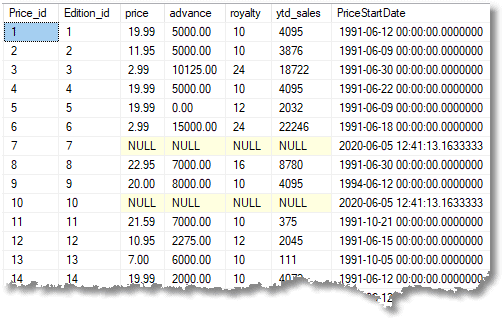
Why not just create a table to store the data? This would cause pursed lips for any database developer because a table is a metadata change, so it would not be the same version. This is frowned on, and rightly so because of the complications involved with keeping track of anomalies of this sort, and because it would cause false positives with auditing software. A lot of IT shops simply don't allow it, learning from bitter experience.
Refactoring PUBS for audiobooks and other book formats
So, what changes did we need to make to PUBS so that it accommodates audiobooks? We can map PUBS, as it exists, like this:
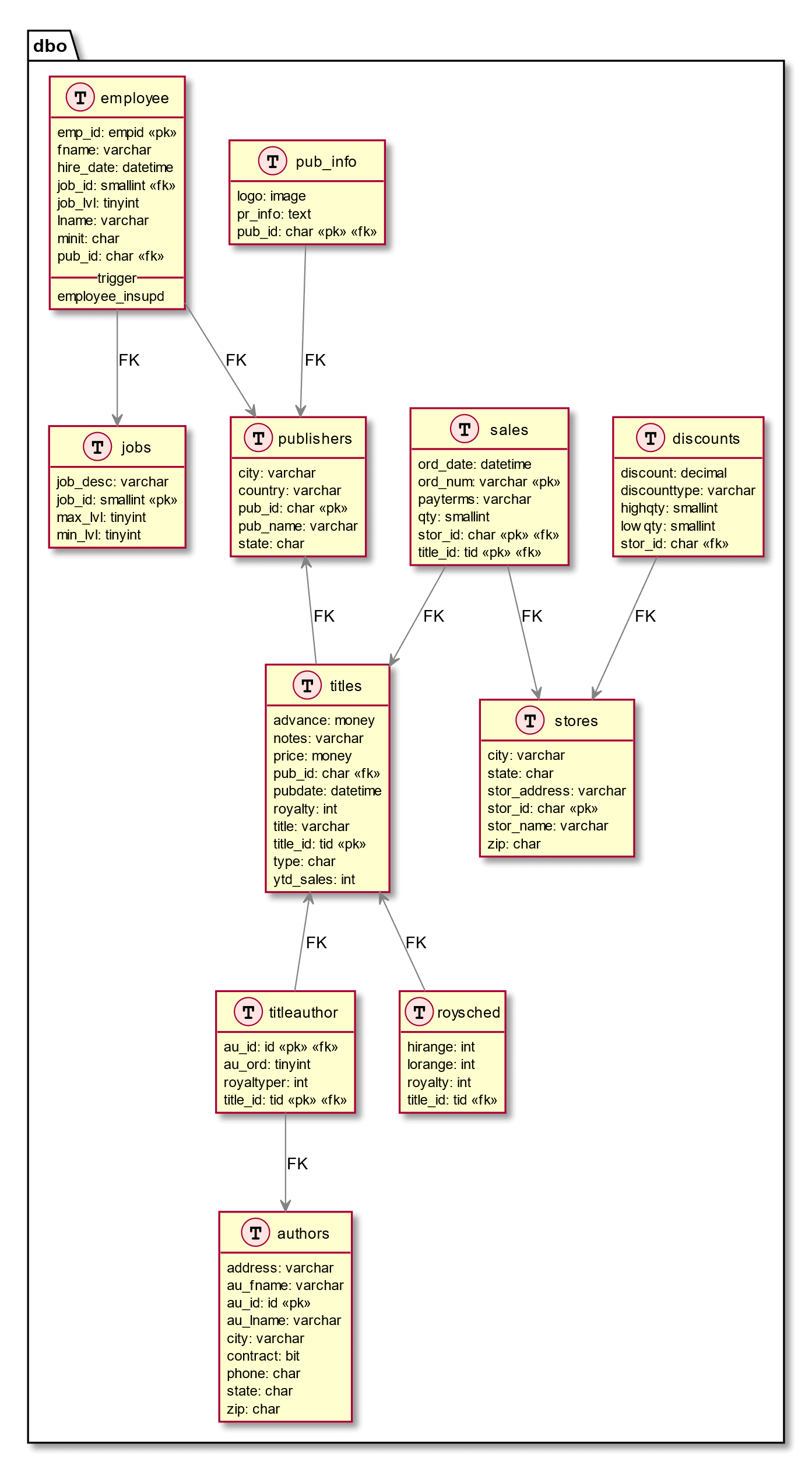
To resolve various design flaws, and deal with the lack of any way to deal with audiobooks or any other sort of publication, we make the following alterations to the base tables:
- Enable
Titlesto have tags for two or more different subjects (e.g. romance and comedy) - Split out
EditionsfromTitles - Split out
Pricesso that editions can have several date-related (temporal) prices. - Rename what was left of the
Titlestable asPublications
The new table structure looks like this:
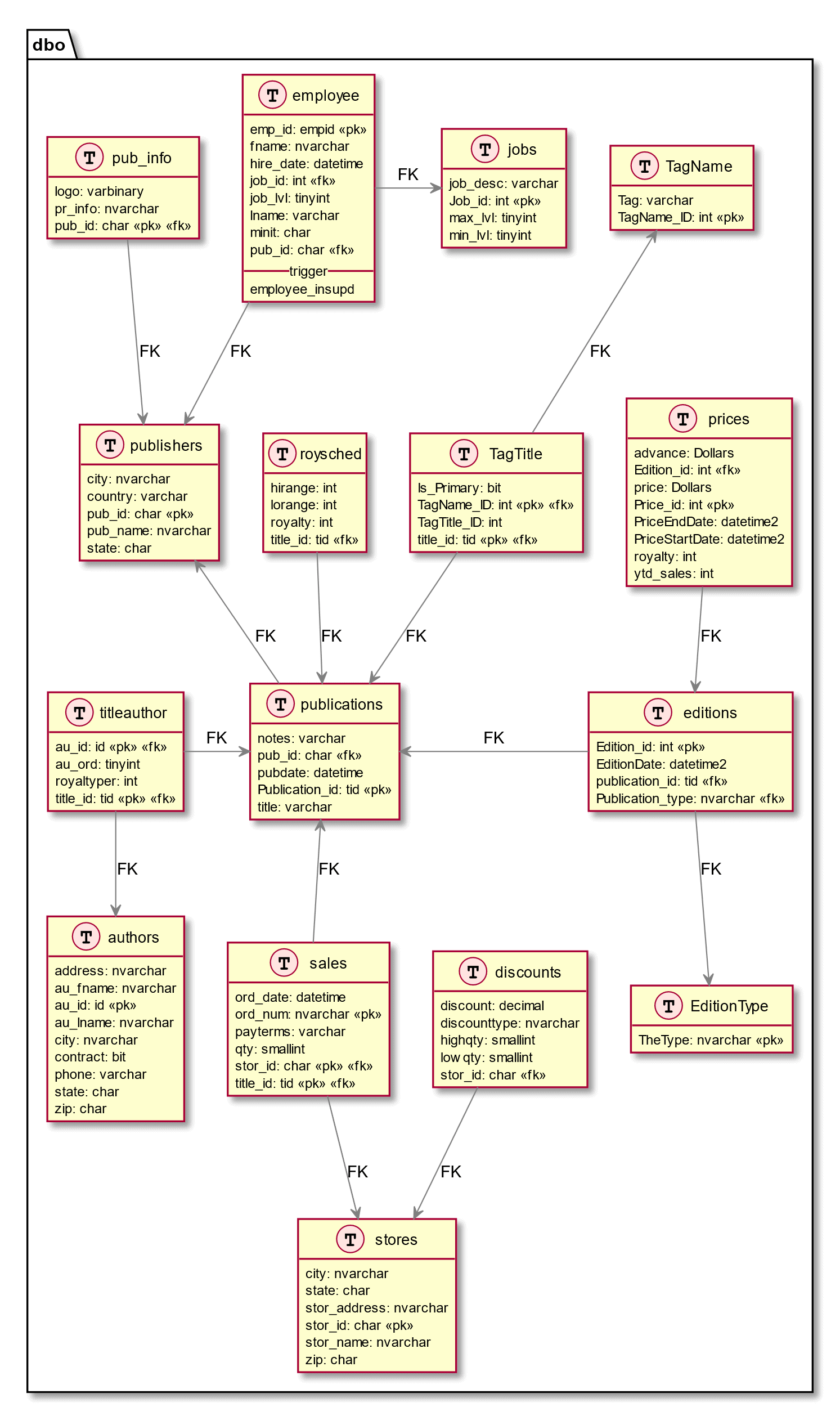
Finally, we also add a view that replicates the old Titles table and with the same name but referencing the new table structure. This means existing stored procedures will still work:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
CREATE VIEW dbo.titles
/* this view replaces the old TITLES table and shows only those books that represent each publication and only the current price */
AS
SELECT publications.Publication_id AS title_id, publications.title,
Tag AS [Type], pub_id, price, advance, royalty, ytd_sales, notes, pubdate
FROM publications
INNER JOIN editions
ON editions.publication_id = publications.Publication_id
AND Publication_type = 'book'
INNER JOIN prices
ON prices.Edition_id = editions.Edition_id
LEFT OUTER JOIN TagTitle
ON TagTitle.title_id = publications.Publication_id
AND TagTitle.Is_Primary = 1 --just the first, primary, tag
LEFT OUTER JOIN dbo.TagName
ON TagTitle.TagName_ID = TagName.TagName_ID
WHERE prices.PriceEndDate IS NULL;
|
Download the source code
If you want to play along, you can grab the scripts from my public GitHub repository, here: https://github.com/Phil-Factor/PubsRevived. The build script for my current version of the expanded database is in the source folder, and the build script for the original version is in scripts.
The migration script
The team decide to release this and so make a migration script using SQL Compare. It creates the deployment script but warns us that we need to also provide a custom deployment script that looks after the data migration for a list of tables. We need to provide a pre-and post-deployment script and add it to the script folder.
We need both a pre- and post- deployment script because we need to stock each table within the new table structure from the contents of the Titles table. The pre- script is attached to the start of the actual deployment script, when it is created, and the post-script to the end. Because the Titles table gets destroyed as part of the reorganization, we keep the data as a temporary table before the main work of changing the database starts, so we can stock the new table structure after the deployment of the new tables has finished.
More on SQL Compare pre- and post-deployment scripts
See Using Custom Deployment Scripts with SQL Compare or SQL Change Automation for more details on how to work with these scripts, their requirements and limitations.
Here is the pre-deployment script:
|
1
2
3
4
|
IF not EXISTS (SELECT name FROM tempdb.sys.tables WHERE name LIKE '#titles%')
SELECT title_id, title, pub_id, price, advance, royalty, ytd_sales, notes,pubdate
INTO #titles
FROM titles;
|
Then, after we've executed the SQL Compare deployment script, the attached post-deployment script gets executed.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
INSERT INTO publications (Publication_id, title, pub_id, notes, pubdate)
SELECT title_id, title, pub_id, notes, pubdate FROM #titles;
IF @@ERROR <> 0 SET NOEXEC ON
INSERT INTO editions (publication_id, Publication_type, EditionDate)
SELECT title_id, 'book', pubdate FROM #titles;
IF @@ERROR <> 0 SET NOEXEC ON
INSERT INTO dbo.prices (Edition_id, price, advance, royalty, ytd_sales,
PriceStartDate, PriceEndDate)
SELECT Edition_id, price, advance, royalty, ytd_sales, pubdate, NULL
FROM #titles t
INNER JOIN editions
ON t.title_id = editions.publication_id;
INSERT INTO publications (Publication_id, title, pub_id, notes, pubdate)
SELECT title_id, title, pub_id, notes, pubdate FROM #titles;
IF @@ERROR <> 0 SET NOEXEC ON
INSERT INTO editions (publication_id, Publication_type, EditionDate)
SELECT title_id, 'book', pubdate FROM #titles;
IF @@ERROR <> 0 SET NOEXEC ON
INSERT INTO dbo.prices (Edition_id, price, advance, royalty, ytd_sales,
PriceStartDate, PriceEndDate)
SELECT Edition_id, price, advance, royalty, ytd_sales, pubdate, NULL
FROM #titles t
INNER JOIN editions
ON t.title_id = editions.publication_id;
INSERT INTO dbo.EditionType (TheType)
VALUES
(N'AudioBook'),(N'Book'),(N'Calendar'),
(N'Ebook'),(N'Hardback'), (N'Map'),
(N'Paperback');
|
We also, in this script, stock the tag tables that allow us to apply several tags to a publication:
|
1
2
3
4
5
|
INSERT INTO TagName (Tag) SELECT DISTINCT type FROM #titles;
IF @@ERROR <> 0 SET NOEXEC ON
INSERT INTO TagTitle (title_id,Is_Primary,TagName_ID)
SELECT title_id, 1, TagName_ID FROM #titles
INNER JOIN TagName ON #titles.type = TagName.Tag;
|
The rollback script
We can revert to the current, audiobook-less version of the database quite easily because we have SQL Compare to do all the detail work for us. However, it warns us that because some tables will be deleted, and so without evasive action, we will lose the following data: EditionType, TagName, TagTitle, Editions, Prices and Publications. It is easy to preserve the data in some of these tables, but others are more of a problem. There will be data that would be lost because there is nowhere that we can store it within the previous version's design. From the time of the deployment to the time we need to roll back the release, the organisation has been busy with the new version and they've added all sorts of new editions of the existing publications, including eBooks, audiobooks, maps, paperbacks and so on. Each edition has had different prices and the business has made some price changes. The old prices are kept in order allow the business to generate copies of each invoice with the price agreed at the time.
All this data would be lost unless we find places to save it. We can easily recreate the data in the Titles table because there is a place for it in the previous version, in the form of the Titles compatibility view, shown earlier. We can use this view in a pre-deployment script to create a temporary table that will contain all the books that are currently published at the time of the rollback. This data will then be restored to the old Titles table, in the post-deployment script.
However, the other tables have data that can't be placed in the previous version, so we must store it in Limbo. For example, we have an EditionType table, just used to prevent you mistyping a type of edition (e.g. Book, Audiobook, Map, Hardback, Paperback)
|
1
2
3
|
INSERT INTO limbo (version, sourceName, JSON)
SELECT '1-2-2', 'All EditionType',
(SELECT TheType FROM editionType FOR JSON AUTO);
|
It will be very easy to restore this type of data in the future whenever you need to do so. Just to demonstrate how we'd do it, this is the code to extract it as a table-source:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
SELECT TheType
FROM
OpenJson( --we retrieve the table from limbo.
(
SELECT JSON FROM limbo
WHERE version = '1-2-2'
AND sourceName = 'all EditionType'
),'$' )
WITH
( --we can instantly convert it to tabular form.
TheType NVARCHAR(20)
);
|
Where a table has foreign keys, we need to hesitate before saving it by itself, and work out if the key could be different when, in future, we come to restore the table.
If we can be certain that none of the primary keys (Edition_ID, in this case) have been reassigned between the saving and restoring of the data, then we can save each table as we did with EditionType, and, when we want to restore the data, import the tables in much the same way as we would with BCP, by using SET_IDENTITY <Tablename> ON and inserting the data. Otherwise, we would need to save the data from a group of related tables in a way that preserves the relationships.
For this example, we'll assume that there is no guarantee that the IDENTITY fields we're using will be the same when we come to restore the tables. By saving the data within the related tables in hierarchical form rather than the tabular form, using JSON, it means that we can also preserve the relationships, but without using keys. This way, we can do all the other tables that SQL Compare warned us about in one JSON array of documents.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
INSERT INTO limbo (version, sourceName, JSON)
SELECT '1-2-2', 'AllPublicationsTagsEditionsAndPrices',
/* we produce a JSON document of the publications with every edition and tag
for each edition we list every price. */
SELECT publications.Publication_id, title, pub_id, notes, pubdate,
Json_Query(--now we get the tags out via a correlated subquery
(
SELECT Tag
FROM TagTitle
INNER JOIN dbo.TagName
ON TagTitle.TagName_ID = TagName.TagName_ID
WHERE TagTitle.title_id = publications.Publication_id
AND TagTitle.Is_Primary = 1 --just the first, primary, tag
FOR JSON AUTO
)
) AS Tags,
Json_Query(-- we list all the current editions of the publication
(
SELECT e.Edition_id, e.publication_id, Publication_type, EditionDate,
Json_Query(--and all the prices for each edition
(
SELECT Price_id, p.Edition_id, price, advance, royalty, ytd_sales,
PriceStartDate, PriceEndDate
FROM prices p
WHERE p.Edition_id = e.Edition_id
FOR JSON AUTO
)
) AS Prices
FROM editions e
WHERE e.publication_id = publications.Publication_id
FOR JSON AUTO
)
) AS Editions
FROM publications
FOR JSON AUTO;
|
This will store the data in a more natural JSON format. Unfortunately, the FOR JSON AUTO format gets confused by the SQL used to get the tag list, which is why we had to go for the more complicated correlated subquery. However, the output is straightforward. Here is an example of one publication. I've kept the original keys just to provide several alternative ways to restore the data.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
{
"Publication_id":"PS7777",
"title":"Emotional Security: A New Algorithm",
"pub_id":"0736 ",
"notes":"Protecting yourself and your loved ones from undue emotional stress in the modern world. Use of computer and nutritional aids emphasized.",
"pubdate":"1991-06-12T00:00:00",
"Tags":[
{
"Tag":"psychology "
}
],
"Editions":[
{
"Edition_id":2,
"publication_id":"PS7777",
"Publication_type":"Paperback",
"EditionDate":"2020-03-27T19:18:13.8412796",
"Prices":[
{
"Price_id":102,
"Edition_id":2,
"price":12.47,
"advance":1246.20,
"royalty":41470,
"ytd_sales":2326,
"PriceStartDate":"2019-10-26T15:59:38.1014800"
}
]
},
{
"Edition_id":46,
"publication_id":"PS7777",
"Publication_type":"Map",
"EditionDate":"2020-12-21T17:03:19.3547845",
"Prices":[
{
"Price_id":116,
"Edition_id":46,
"price":30.50,
"advance":1380.33,
"royalty":8717,
"ytd_sales":7568,
"PriceStartDate":"2019-07-08T18:56:37.8407045"
}
]
}
]
}
|
The next migration script should be usable whether the previous release was reached 'naturally' via a build script, or a series of migration scripts, or 'unnaturally' via a rollback script. I like to do this by a simple batch that only restores the data from limbo if it is there, and deletes it from limbo, or flags it as redundant, once the data has been merged with the existing data in the database.
Restoring the data from Limbo
Now, in development, you create another migration script that deploys a new, 'fixed' audiobook-friendly version of PUBS, restoring the necessary data from limbo in the process.
We can import data into relational tables from a hierarchical JSON data document like the one we've just generated. The complication is that we need to add the foreign keys that are appropriate, rather than assume that the old ones will still work. In this example, we can assume that the publication_id of each publication (formerly 'title') is assigned by the business and so we can safely use that without fear of duplicating one that is already assigned. However, the edition_id and price_id are IDENTITY fields and we have to assume that they will have been reused by the time we do our data restoration (it's not necessarily true but let's keep things tricky just in case).
In this example, we need to iterate through the array of documents (publications) within the JSON document. For each publication, we first save the general facts about the titles into the new publications table, and then add its tags. Then we can add the editions that the publication has, using the publication_id. Then we need to add every price, but in order to add each price for the one or more editions of each title, we need to retrieve the IDENTITY value used for the primary key of each edition and add that as the foreign key to each of the associated prices.
Here's the coded to do all this, which you'd run as a post-deployment script for the migration (and replaces the pre- and post- scripts used for the previous migration):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
|
/* we keep a temporary table of each publication, which includes the
editions and prices as JSON objects */
drop table if exists #tempPublication
CREATE TABLE #tempPublication
(
TheOrder INT IDENTITY,
[Publication_id] NVARCHAR(8) NOT NULL,
[title] [VARCHAR](80) NOT NULL,
[pub_id] [CHAR](8) NULL,
[notes] [VARCHAR](200) NULL,
[pubdate] [DATETIME2] NOT NULL,
[Tags] NVARCHAR(4000),
[Editions] NVARCHAR(MAX)
);
GO
INSERT INTO #tempPublication (Publication_id, title, pub_id, notes, pubdate,
Tags, Editions)
SELECT Publication_id, title, pub_id, notes, pubdate, Tags, Editions
FROM
OpenJson( --we retrieve the table from limbo.
(
SELECT JSON FROM limbo
WHERE version = '1-2-1'
AND sourceName = 'AllPublicationsEditionsAndPrices'
),'$'
)
WITH
(
Publication_id NVARCHAR(8), title [VARCHAR](80), pub_id [CHAR](8),
notes [VARCHAR](200), pubdate [DATETIME2], Tags NVARCHAR(MAX) AS JSON,
Editions NVARCHAR(MAX) AS JSON
);
GO
DECLARE @ii INT, @jj INT, @kk INT, @kkMax INT, @Reference VARCHAR(80),
@TheEditionID INT, @RowCount INT, @InnerReference VARCHAR(80),
@InnerRowCount INT;
--and our information for each publication
DECLARE @Publication_id NVARCHAR(8), @title VARCHAR(80), @pub_id [CHAR](8),
@notes [VARCHAR](200), @pubdate [DATETIME2], @Tags NVARCHAR(4000),
@Editions NVARCHAR(MAX);
--we loop through each row of our temporary table storing each
--publication, so as to be able to stitch in each edition
--we leave the primary keys of each publication (formerly title)
--because these are defined by the business
--check how many rows to do
SELECT @kk = 1, @kkMax = Count(*) FROM #tempPublication;
WHILE @kk <= @kkMax--the outer loop is k
BEGIN
--get the next publication and insert it into the publications
--normally, you'd check to make sure it wasn't there already
--get the next publication
SELECT @Publication_id=Publication_id, @title=title, @pub_id=pub_id,
@notes=notes, @pubdate=pubdate, @tags=Tags, @editions=@editions
FROM #tempPublication WHERE TheOrder= @kk
INSERT INTO #publications (Publication_id, title, pub_id, notes, pubdate)
SELECT @Publication_id, @title, @pub_id, @notes, @pubdate
--now we get the tags into our tag tables
INSERT INTO #Tagname (Tag)
SELECT assigned.tag --only insert the tag if necessary.
FROM
OpenJson(@tags,@Reference)
WITH (Tag NVARCHAR(20))Assigned
LEFT OUTER JOIN #Tagname AS existing
ON assigned.tag=existing.tag
WHERE existing.tag IS null
insert into #TagTitle (title_id ,Is_Primary,TagName_ID)
SELECT @publication_id,
case when ROW_NUMBER() OVER (
ORDER BY Tagname_id ) =1
then 1 else 0 end as [Is_Primary],
existing.Tagname_id --only insert the tag if necessary.SELECT ]
FROM
OpenJson(@tags,@Reference )
WITH (Tag NVARCHAR(20)) as new
inner join #Tagname existing
ON new.tag=existing.tag
--we've done the tags. Now to do the editions
SELECT @ii = 0, @RowCount = -1; --@rowcount must be non-zero
WHILE @RowCount <> 0 --we just keep getting editions until no more
BEGIN --get the next edition for this publication
SELECT @Reference = '$[' + Convert(VARCHAR(3), @ii) + ']';
--insert it into the table in Pubs
INSERT INTO editions (publication_id, Publication_type, EditionDate)
SELECT publication_id, Publication_type, EditionDate
FROM--we retrieve the table from limbo.
OpenJson( @editions,@Reference) --this is OK in SQL Server 2017 onwards
WITH--specify what you want in the result
(
Edition_id INT, publication_id NVARCHAR(8),
Publication_type NVARCHAR(20), EditionDate DATETIME2,
Prices NVARCHAR(MAX) AS JSON
);
--did it find the reference?
SELECT @RowCount = @@RowCount;--0 if it dodn't find anything
IF @RowCount > 0 --there was another edition so get its prices
BEGIN --getting the prices
SELECT @jj = 0, @ii = @ii + 1, @TheEditionID = @@Identity,
@InnerRowCount = -1; --get the next price
WHILE @InnerRowCount <> 0
BEGIN--get the next price
SET @InnerReference =
@Reference + '.Prices[' + Convert(VARCHAR(3), @jj) + ']';
--now insert the next price if there was one
INSERT INTO prices (Edition_id, price, advance, royalty,
ytd_sales, PriceStartDate, PriceEndDate)
SELECT @TheEditionID, price, advance, royalty, ytd_sales,
PriceStartDate, PriceEndDate
FROM
OpenJson( --we get the row from our temporary table
@Editions, @InnerReference-- e.g.'$[0].Prices'
)
WITH
(
[price] [dbo].[Dollars], [advance] [dbo].[Dollars],
[royalty] [INT], [ytd_sales] [INT],
PriceStartDate DATETIME2, PriceEndDate DATETIME2
);
SELECT @InnerRowCount = @@RowCount;
SELECT @jj = @jj + 1;
END;
END;
END;
SELECT @kk = @kk + 1; --bump the outermost loop
END;
drop table if exists #tempPublication
|
Conclusion
The use of a table that doesn't change from version to version seems, from a distance, to be an unnatural and rather dubious way of storing data. However, we're not referencing, just preserving it because the version that the database is migrating to has no other way of preserving the data.
If we are obliged to preserve data within the database, and there is no relational, table-level, means of storing it, and it is done in line with all the disciplines in place within the development, such as insisting on atomicity in the columns of all tables, then it is OK. A delayed rollback of a database to a previous version is one of the few cases where storing document data such as JSON or XML might be appropriate. It is, though, another thing to remember about, especially if you must rebuild a database and restore the data.
Roll-back scripts are always an irritation because they take some time to write, and even more to test. They are even more irritating if it becomes essential to preserve all the data, even if there is no logical place for it. After all, they are rarely required, mercifully, but when they are used, they must work. You could say the same about fire-extinguishers, seat belts and parachutes. I create Rollback scripts conscientiously nowadays because things can go wrong: I've seen the pain when a database deployment went bad and there was a loss of data because there was no rested rollback script.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Practical PowerShell Processes with SQL Change Automation
Starting from the object-level source code for a database, Phil Factor shows how SCA can create a NuGet build package, use it to migrate target database to the same version, and publish web-based database documentation, a report of what changed on the target and the results of a static code analysis assessment.

Article
Using SQL Change Automation in SSMS to Track Static Data Changes
SQL Change Automation 4.1 now allows users to develop static data changes from SQL Server Management Studio.

Article
How SQL Clone and SQL Change Automation enable seamless Database Branch Switching
Learn how SQL Clone and SQL Change Automation, used together, now allow you to branch your database in Git as quickly and simply as your code.

Article
Custom Deployments from Source Control using SQL Compare Command line
Giorgi Abashidze explains how his team use a 2-phase deployment process with SQL Compare Command line, and some SQL Synonyms, to automate custom deployments for each of their customers, while only needing to maintain one branch per release in source control.
Article
Simple SQL Change Automation Scripting: The Release Object
Once you understand the SCA data objects, it can give you a certain glow of to discover, suddenly, that SCA can do some complicated and time-consuming tasks with just a few lines of code. Phil Factor demonstrates how to get the most of SCA's Release object.
Article
Getting Started with Automatic Database Branch Switching
Alexander Diab demonstrates how a team of developers can work on and test features in different branches of a SQL Server database development project, while their local development database automatically remains 'synchronized' with the current branch in version control.
Loading comments...