




Managing Test Datasets for a Database: What's Required?
This article is part of a series on managing test data in a Flyway development:
- Safer Database Deployment: The Role of Test Data Management
- A Test Data Management Strategy for Database Migrations
- Dealing with Database Data and Metadata in Flyway Developments
- Adding Test Data to Databases During Flyway Migrations
- Getting Data In and Out of SQL Server Flyway Builds
- Bulk Loading of Data via a PowerShell Script in Flyway
- Managing Test Datasets for a Database: What's Required?
- Managing Datasets for Database Development Work using Flyway
- Simplifying Data Import and Export for Database Development
Also relevant are the series of related articles on Database testing with Flyway.
The short answer to "what's required" for managing test data, from the developer's perspective, is easy. You have an empty database of the version you want. You select the appropriate dataset, depending on the sort of work you want to do. You fire off a script and watch the data load in while you sip on a cup of artisanal coffee. It's as simple as putting a battery into a power tool, at least it should be.
What happens, however, when a branch of development produces a new release that requires new data, or affects existing data? Whoever oversees the test data will take the previous version (V2, say) from the branch, load it with the "V2 data", run the migration script to take it to the new version (V3), and check to see if there are any data changes. If so, the test data expert will first check the documentation for the new version. Thinks: "Hmm. A couple of new related tables there. I must check to see if I need to generate some data for them". After that, it is just a matter of saving to the network a new copy of the dataset, as a version of the data that is appropriate for the new database version.
If you've already reached this level of competence with managing test and development data, then I can't offer much more in this article. If not, then this article will briefly review all the ways that datasets are used in the development cycle, to be clear what the requirements are for the curation of datasets. I'll then the steps towards an automated 'canteen' style approach to loading a dataset into a database. For this, you need a reliable way of storing data that meets everyone's needs and allows you to save, edit and load the data unattended. I make the case for using JSON and JSON Schema as the standard medium for storing these datasets.
How do we manage dataset versions alongside database versions?
Data gets a lot of handling in a database development project. We use a variety of techniques to produce the test data sets that we need. We can store the data in a variety of formats, binary or text-based, often in a shared-access location on the file system. We can then use a range of techniques to load it into the database, ready for development work and testing.
The developers make the necessary changes to the database and run the tests. If the tests pass, they commit the schema changes to version control and, if required, update the saved datasets to reflect the changed structure of the new version. Why? Because if you change the design of tables between database versions, but fail to update the saved test datasets accordingly, the next the data import script runs, it will fail! This implies that when the data needs to be altered, we must somehow attach version information to the saved datasets. This done, we then have a way to ensure that the automated testing process always provides the correct dataset for the version of the database being tested.
I'll review the various requirements for generating, saving, sharing and loading the data we need for team-based database development, and then explain how we manage data transformation, between database versions, in a migration-based approach to database development, as typified by Flyway.
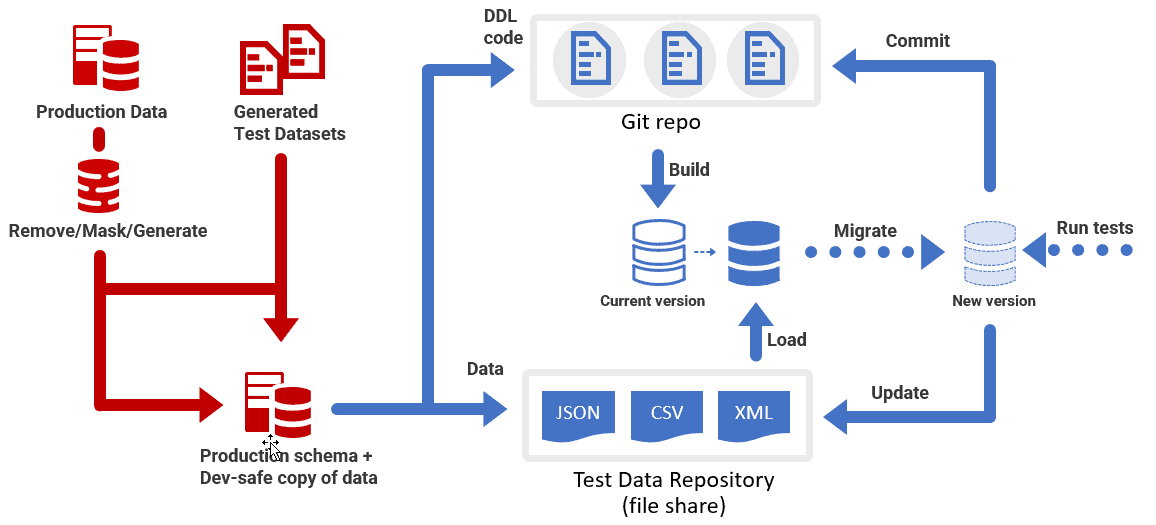
Generating, storing, loading and updating test data
At some point in the lifecycle of a database, development and test data must be generated and it is quite likely that there will be several datasets for any particular version. Your database project may require several different datasets for testing different aspects of the functioning of the database (see Test Data Management for Database Migrations). We need a standard format in which to save all these datasets, per database version, for use by other team members. We need a fast, automated way to load the datasets and we need a strategy for maintaining datasets between versions.
The goal is to provide the development team with all the test data they need to enable them to do as much testing as possible, as early as possible in development. I'll focus here only on the standardized test datasets, typical of what a developer needs to run basic functional tests (e.g. unit tests) over a wide range of data inputs, and simple integration tests. This is purely synthetic data. I've covered elsewhere some of the principals of masking production data, so that it can safely be used outside the secure confines of production and staging, and some of the techniques and tools available to do it.
Generating test datasets
For many types of database test, especially earlier in development, use of production data is either not required, or not possible (for security reasons, or because the application hasn't yet got into production, so there is no production data to use). Besides, unit and integration tests are best done using small, immutable datasets and these are easily generated in development. The two main challenges are:
- Maintaining all the correct relationships between tables – as specified by the
FOREIGNKEYandPRIMARYKEYconstraints - Tying together all the associated data in the row – so that cities match countries, start dates are before end dates and so on.
SQL Data Generator is SQL Server-only but is typical of data generation tools in that it will import the schema then generate the number of rows you specify for each table, in a target database. The biggest reason for using it is that manages the first task in the list, the otherwise-tedious job of creating all the foreign Key relationships. It deals with the second task too because you can configure the generation for each column, and for each table, by customizing the parameters and options for each column, by importing data from curated files, and use of pattern matching rules. Once you're familiar with the tool, you can get some quite realistic data.
You can then save this configuration (the .sdg project file), and update it for each version of the database. You then simply build an empty database at the right version and use the saved 'generator' to fill it with fake data. It is best to have a scripted process for producing the fake data that grows as the data model for the application grows.
This is excellent for scalability testing for a SQL Server database because you can specify the number of rows, but it doesn't help integration and regression tests. For those, you need a standard dataset. Therefore, once the generator has done its job and the result is tested to ensure that it is satisfactory, you should then save the data to a set of files, for distribution. This ensures that there is an "immutable" dataset that others can then use to load and test that version of the database.
Also, SQL Data Generator isn't a cross-RDBMS tool. If, however, you save the data files, you can then load them into any RDBMS. See Generating test data in JSON files using SQL Data Generator for an example of how to save SQL Server data in JSON files, which we can then use to test even a non-relational database, such as MongoDB.
Storing a dataset
Test data can either be stored inside the database, as a backup, or stored as a set of data files. Backups provide more convenient storage, and they ensure that all constrained keys and values are correct. However, to use the data we must restore the backup and then export the data or transfer it via a script. It is difficult to get around the requirement for a robust and reliable way of storing datasets outside the database as files.
For data files, each RDBMS has a preferred data format for bulk import and export. I demonstrate the SQL Server and BCP approach here, in Getting Data In and Out of SQL Server Flyway Builds. However, if you are using more than one RDBMS, you must consider storing data in a neutral format.
Text-based data documents are useful because they can be edited by a script, or in a good text-editing application that is optimized for handling large files. CSV is ideal for storing data if it meets the RFC 4180 and MIME standards. It must properly handle text with embedded double-quotes and commas). TSV (Tab Data Package) is a generally-reliable variant, though neither have a check for data truncation.
My preference, though, is to use JSON because it now has such good support from frameworks and relational database systems and because you can use JSON schema to validate data during loading, which I demonstrate in Transferring Data with JSON in SQL Server and How to validate JSON Data before you import it into a database (PowerShell 7.4 onwards now supports JSON Schema with the Test-JSON cmdlet). Its advantage over CSV, TSV and YAML is that you are protected against a truncation that cuts off some of the rows: if that final bracket is missing, it won't even parse.
Whichever format you choose to store a dataset, we're then going to use it to stock a particular version of a database with suitable data. A database build or migration is easier to manage if the data is added as a separate post-build process. As part of testing, you may even need to load several datasets, one for each type of test.
Loading a dataset
To do this loading of a dataset, you need two processes, 'kill' which removes any existing table data, and 'fill' which fills the tables with the rows from the dataset. I demonstrate how to do this in Database Kill and Fill. Were it not for constraints, this would be easy.
CHECK constraints are essential, but if you haven't checked your dataset for data conformance, they can spring errors on you. You can of course disable them but that merely postpones the grief to the point where you need to re-enable them. FOREIGN KEY constraints could prove difficult if rows referenced in the table are not yet loaded.
If you can disable or defer constraints, as some RDDMSs allow, then "Kill and fill" is easy, so embarrassingly easy that I've seen people do a 'Kill' by mistake and remove all the data in the database, so be careful. If you do disable them, make sure you re-enable them after loading all the data into all the tables. It helps performance to update statistics, indexes and constraints, and in some cases, to sort the data appropriately.
To avoid any accidental kills and because not all RDBMS support the disabling of all constraints, kill and fill are operations that are best done in the right dependency order. However, there are plenty of 'gotchas' in the 'Fill' process, though. In SQL Server, for example, you cannot INSERT into a calculated column or TIMESTAMP column. You need to use SET IDENTITY INSERT TableA ON, if TableA has an IDENTITY column. Of course, if you try this with a table that hasn't got an IDENTITY column, you get an error. Inserting XML into an XML column results in an error unless you do an explicit conversion, because of the possibility of a different XML Schema.
If you can work through these issues, so the job of loading an appropriate dataset becomes easy, then there is less temptation to pine for production data, even when it is possible to do so. It is also easier to face the prospect of regression testing without flinching. The idea of a more thorough testing of a database must bring a glint into any team-leader's eye.
Updating a dataset
Obviously, data isn't part of database design. When you change the data in a database, the database version doesn't change, just the version of the dataset. Conversely, if the schema changes, then you need to ensure that existing data remains consistent with the updated schema or constraints. The general approach is to use a scripted transformation in which you write scripts to transform any data that needs to be changed or moved from the previous version to conform to any changes in the database table-design. This may involve altering column values, splitting or merging columns, or handling changes in data types.
In the old "build first" approach to development you could, unwisely, find yourself needing to do these data transformations at the point where you need to upgrade a database that is already in production. You would need to determine where these table changes are, and where the data affected by these changes should be placed, where data needs to be transformed or altered to comply with constraints, and where any new data should be placed. Then, of course, you'd need to test that it works.
With a migration-based approach to database development, such as with Flyway, it becomes much simpler to make the migration script responsible for all the data transformations that are required. This is because the database developers would already have had to do this work to test the new version. After all, the migration approach requires that each database version change must preserve the existing data, and you can't adequately check your code without ensuring that it does so! The developer must always write the SQL migration code as though the script was being applied to a production system, and so must preserve the production data when deployed.
In a Flyway development, we can prepare and test the data transformations as part of testing the migration script for the new version, and then save the datasets for the new version, ready for use by others. When saving datasets for each version, we need a system that ensures that the correct dataset is provided for the version of the database version being tested. As I've explained elsewhere, your database project may require several different datasets for testing different aspects of the functioning of the database.
Managing test data during Flyway development
It is easier, when using the migration approach, to confuse the DDL that defines the database, and the DML that determines its data. To keep things simple in a Flyway development, new data that is required for any tables that are created for the new version of the database ought to be loaded as a separate process to the migration, perhaps in a Flyway callback. The rest of the data will become available because, once the migration script is tested, you just load the data into the previous version of the database, run the migration to the current version, and save the newly transformed data as a new dataset. In this way, we always prepare a new data set up-front, at the time that the database version is created, and then save it so it can be loaded for all further installations, without needing any "transformation script".
My technique for ensuring that our load process always picks the right dataset version is to copy the standard Flyway convention and save each dataset in a directory named with the starting version number for which that dataset is appropriate. The same dataset might be valid for several versions, so the data load process simply selects the data set with the most recent version, before or equal to the version of the database being tested. See Getting Data In and Out of SQL Server Flyway Builds for a demo.
You will need to archive datasets for all the current versions of the database. This only needs to be retained for as long as it might be required for test purposes, but when tracking down an obscure bug in a previous version, it is much easier to restore from a backup.
Once you have this sort of system in place, you are ready for an automated 'canteen' style approach to loading a dataset into a database.
I demonstrate a way of saving and loading JSON datasets, using this system, in Managing Datasets for Database Development Work using Flyway, using my Flyway Teamwork framework to take care of a lot of the 'heavy lifting'.
Running the tests
Finally, of course, we get to use these datasets as part of our database testing. I've written a whole series of articles describing various aspects of what types of tests we need to run, and how to run them in Flyway. It includes coverage of test-driven developer using transactions, and examples of automating routine unit and integration tests, assertion tests and performance tests.
This is the first article in the 'database testing' series, and contains links to all the others: Testing Databases: What's Required?
Conclusions
At the start, I made the analogy of the power tool battery for the dataset. Can you store data for the 'consumer' as simply as electricity?
To try to answer this question, we've reviewed what's required of test datasets in database development. There are many ways of managing test data, and there are flaws in most of them. Only the JSON format, with JSON Schema, has the potential to be used for all the tasks I've mentioned in this article. CSV has never been properly standardized, TSV doesn't allow tabs inside text, and neither of these can detect truncated files or errors in the data. XML is too complicated, tricky to edit, and 'wordy' for bulk data. YAML is poorly supported and has no schema
The management of datasets is intrinsic to effective team-based database development. For example, the transformation of datasets is part of the task of development, but it doesn't always happen. I have experienced occasions where a developer has done arcane table-splits that have required undocumented, semi-manual processes involving regex-savvy tools, but provided no copy of the transformed data or documentation. This can risk causing consequential chaos for other team processes.
With an automated system that adopts a common standard for the storage of datasets, and documents the dataset, it becomes easier to spin up a database with whatever data you need for your task. Sure, it can seem at the time to be a nuisance to have to add the required logic to manage the existing data, especially as it is only test data, but a build-based approach to database development just postpones the inevitable need for successful data migration, and it is a lot more painful, and visible, when it delays the deployment process. An additional advantage is the discipline of 'versioning' the database. If you 'version' the data as well, you are unlikely to fall foul of the consequences of trying to load the wrong dataset for the database version.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Working with Flyway and Entity Framework Code First: Automation
This article will demonstrate how to automate a hybrid database change management system that uses Entity Framework Code First for development and Flyway for deployments. We automatically convert C# migrations, produced by EF, to the Flyway format and then use Flyway command line to deploy the migrations and save the 'object-level state' of each new database version, so we can track exactly which objects changed, and how, between versions.
Article
Dealing with Database Data and Metadata in Flyway Developments
Before you get very far with database development and testing, you need to be clear about your strategy for handling data. In this article I'll explain some of these issues in general terms, and then demonstrate how you can navigate these problems easily with Flyway.

Article
Automatically Tracking and Deploying Static Data in Flyway Enterprise
Static data is often required for the basic functioning of a database and any dependent applications. Therefore, it's vital that we can track this static data to understand how, when, and why it changed, and that we include any static data changes in our database deployments. Flyway Enterprise will now do both tasks automatically.
Article
New Redgate Flyway Release - Automate Even More
Read on to learn about how you can automate even more things with Flyway like project setup and state-based deployments. We’ll share how you can get the latest version and things you need to know when upgrading.
Article
Simple Workflows for Flyway and Entity Framework Code First
Entity Framework Code First is great for development, but its abstractions can hide risky database changes until deployment. This article explores three practical EF–Flyway hybrid workflows that add visibility and control, helping teams stabilize deployments for complex, legacy databases such as monoliths.
Article
Planning a Database Testing Strategy for Flyway
With Flyway, you can adopt a test-driven development strategy that will allow you to test and evaluate databases, and database objects, at every phase of the database development lifecycle. The further down the delivery pipeline that bugs appear, the more costly in time and resources they are to fix. This approach will allow you to catch many of them before the database change even gets committed to version control, making a continuous delivery process much easier to adopt and sustain.
Loading comments...