Reporting on Changes Made by Flyway Migration Scripts
Phil Factor demonstrates some PowerShell tasks that will produce a high-level overview, or narrative, of the main differences in the metadata between two versions of a database, during Flyway Teams migrations.
Often, during development, it’s useful to be able to see, at a glance, which objects have been changed, between successive versions of a database. It is handy for such things as merges, after creating a branch, or for generating reports of what changed in what version.
I’ve previously shown a cross-RDBMS way to generate these change reports, by creating generic models of the database from ODBC metadata, in Discovering What’s Changed by Flyway Migrations. It works well enough and can be used by most databases that have JDBC connectivity, but it lacks some of the details you often need, especially with indexes and keys.
In this article, I’ll show an alternative approach for those who are using predominantly a single RDBMS (SQL Server) with Flyway and who need some of the extra detail that just isn’t available in the ODBC metadata. It’s based on my “Gloop” method of saving the details of the metadata of your database, including tables and routines, in JSON files. It is intended to be used with Flyway, SMO or Redgate Deploy. It works hand-in-glove with SQL Compare, providing the reports that SQL Compare can then use to home in on the details.
Keeping track of database design changes
Even if you are solely responsible for a database, it is useful to know when changes were made. If you are doing teamwork, it can prevent collisions taking place. If you are adopting branching and merging teamwork strategies, it becomes essential.
If you can keep a record of your database in a structured form, then you can track changes in the design of the database, over time. Traditionally, we used to do this by saving build scripts into source control and seeing the differences in the script via the ‘diff’ tools provided with the source control system. After all, what is a build script if not an accurate description of the structural schema of your database? Predictably, though, the method breaks down as the database grows. It is also a very manual process. To make matters worse, database developers won’t always work directly from a script, but prefer to use ER modelling tools, table-builders and so on: this means that scripts are likely to be generated. These are migration scripts, and they must be applied to the database, from which you then generate a build script. You then can’t track changes because the script may use slightly different syntax or script the objects in a different order, so you’ll inevitably find changes flagged-up where no change to a table or view is made.
At some point, you adapt to using object-level build scripts for each table, view, procedure and so on, which are better able to tell you where the changes happened. That’s fine as far as it goes, but tables, especially, can become remarkably complex and so you need to be able to drill deeper the details of what changed. Even a simple change to a constraint can cause a database release to fail.
Is there a better way of comparing databases than by using a build script? Sure. Relational databases can be represented as hierarchical networks. Databases have schemas that have tables that have columns, that have all sorts of attributes. In truth they are more like a network than a hierarchy if you add in dependencies. By creating a model of a database, rather than a build script, it is much easier to compare different versions of the same database to see what has changed. This is the way that any database comparison tool works, including SQL Compare. It allows database developers to get a summary of what has changed between versions of a database.
Recording database metadata in JSON
The Gloop technique works by saving the state of the database metadata at various points, in JSON form, so that we can use it to verify that a database is at the version that we think it is and to produce a narrative of changes or detect drift.
Unlike SQL Compare, it only checks the main objects, ignores SQL Server-specific features such a query store, and doesn’t check scripts within procedures. It has no visual interface and doesn’t generate any scripts. It’s not the point, because its use is merely to provide a general narrative of changes between versions to allow database developers to get an overview.
Getting a database’s metadata as a JSON document
I want a hierarchy that can be represented by JSON and is lean enough to be easily stored and scanned. SQL Server can be used to produce hierarchies by means of outer joins and the FOR JSON AUTO keywords. I’ve used this technique elsewhere to create and maintain a ‘data dictionary’ for your databases, in JSON format.
It is a good start, but it cannot produce lean hierarchies. When you think about it, object names, column names, type names and index names in relational databases are keys, so this would allow us to assume that they are unique and so to use the names as hashtable keys, where possible. In this way, we can make hierarchical paths closer to the RDBMS naming conventions.
We can do this ‘lean’ conversion in PowerShell, after getting the JSON document from a single SQL query. The SQL Query can get us a long way towards what we want, but it needs extra help to get to this level of compactness, which is intelligible to most database professionals at a glance because it uses database names and database terms as keys.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
{ "dbo":{ "table":{ "publishers":{ "check constraint":[ "CK__publisher__pub_i__3C69FB99" ], "default constraint":[ "DF__publisher__count__3D5E1FD2" ], "Columns":[ "pub_id char(4)", "pub_name varchar(40)", "city varchar(20)", "state char(2)", "country varchar(30)" ], "primary key constraint":[ "UPKCL_pubind (pub_id)" ] }, "roysched":{ "foreign key constraint":[ "FK__roysched__title___4D94879B" ], "Columns":[ "title_id tid", "lorange int", "hirange int", "royalty int" ], …etc etc… |
You can see that this is quite an accessible record of what’s in the database. We can compare objects like this easily in PowerShell to see changes in the database objects we’ve chosen to return. I must emphasize that you need a comparison tool to get a definitive comparison: here we just want the overview for our model because we only want to track changes in the objects in which we’re interested, for development work.
The single query that produces the database model, in a JSON document, is quite long, so I’ll just point you to the GitHub Repository where I keep it, TheGloopDatabaseModel.sql.
Download the file and we’ll run it in from the following PowerShell test routine, which transforms the JSON model into its’ sparse form. Under the covers, I’m converting it to PowerShell object notation which is then executed. I do this to be certain of the form of the resulting object. Doing it in a pipeline can be like nailing jelly to the ceiling.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
Set-Alias SQLCmd "$($env:ProgramFiles)\Microsoft SQL Server\Client SDK\ODBC\130\Tools\Binn\sqlcmd.exe" <# parameters for the routine to get JSON result from database #> $Param = @{ 'server' = '<MyServer>'; 'Database' = '<MyDatabase>'; 'Routine' = '<MyPathToThe>\TheGloopDatabaseModel.sql'; 'uid' = '<MyUID>'; 'password' = '<MyPassword>' } # The JSON Query must have 'SET NOCOUNT ON' and assign the result to # a variable defines as 'NVARCHAR MAX' which you select from. # Just don't ask why.... $login = if ($Param.uid -ne $null) #if we need to use credentials { $MyJSON = sqlcmd -S "$($param.server)" -d "$($param.database)" ` -i $param.Routine -U $($param.uid) -P $($param.password) ` -o "$($env:Temp)\Temp.json" -u -y0 } else #we are using integrated security { $MyJSON = sqlcmd -S "$($param.server)" -d "$($param.database)" ` -i $param.Routine -E -o "$($env:Temp)\Temp.json" -u -y0 } if (!($?)) #sqlcmd error { Write-error "sqlcmd failed with code $LASTEXITCODE" } #we interpret the JSON into a model of the database. $DatabaseModel = [IO.File]::ReadAllText("$($env:Temp)\Temp.json") try{ $JSONMetadata=$DatabaseModel | ConvertFrom-json } catch { write-error "the SQL came up with an error $DatabaseModel" } $dlm0='';#the first level delimiter $PSSourceCode=$JSONMetadata | foreach{ $dlm1='';#the second level delimiter "$dlm0`"$($_.Schema -replace '"','`"')`"= @{" $_.types | foreach{ $dlm2='';#the third leveldelimiter " $dlm1`"$($_.type -replace '"','`"')`"= @{" $_.names | foreach{ $dlm3=''; #the fourth-level delimiter if ($_.attributes[0].attr[0].name -eq $null) {" $dlm2`"$($_.Name -replace '"','`"')`"= `'' "} else { " $dlm2`"$($_.Name -replace '"','`"')`"= @{" $_.attributes | #where {$_.attr[0].name -ne $null}| foreach{ $dlm4='';#the fifth-level delimiter " $dlm3`"$($_.TheType -replace '"','`"')`"= @(" $_.attr | #where {$_.name -ne $null}| foreach{ " $dlm4`"$($_.name -replace '"','`"')`""; $dlm4=',' } " )" $dlm3=';' } " }" } $dlm2=';' } " }" $dlm1=';' } " }" $dlm0=';' } $DataObject=Invoke-Expression "@{$PSSourceCode}" $dataObject|convertTo-json -depth 10 >"$env:temp\Gloop$($param.database)Model.json" |
Generating database models during Flyway migrations
Once we’ve satisfied ourselves that it works, we just need to transfer it into a form that allows us to add it to the list of tasks in our DatabaseBuildAndMigrateTasks.ps1 PowerShell library.
When we execute a migration run, in Flyway, it will trigger a script callback that detects the version number and fills in our credentials, before calling the $SaveDatabaseModelIfNecesary task to generate a database model for the new version.
The afterversioned callback script
This is the body of the afterVersioned callback, which I’ve called afterVersioned__Narrative, and which I’ve included within the Scripts folder of the GitHub project. It is called after the final versioned migration script in a migration run completes. I can’t use an afterEachVersion callback because all the ‘Each’ callbacks take place within the same transaction as the migrate, which gives Flyway its rollback abilities. Any metadata SQL call that happens in this callback is likely to deadlock the database.
When we run the Flyway migrate command (later) we need to pass into the callback the flyway ‘schemas’ list, via a placeholder. It isn’t strictly necessary for SQL Server, but it is essential for other database systems.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 |
# run the library script, assuming it is in the project directory containing the script directory . "..\DatabaseBuildAndMigrateTasks.ps1" # Before running this, you will need to have TheGloopDatabaseModel.sql in the same directory as # DatabaseBuildAndMigrateTasks.ps1 #this FLYWAY_URL contains the current database, port and server so # it is worth grabbing $ConnectionInfo = $env:FLYWAY_URL #get the environment variable if ($ConnectionInfo -eq $null) #OMG... it isn't there for some reason { Write-error 'missing value for flyway url' } <# a reference to this Hashtable is passed to each process (it is a scriptBlock) so as to make debugging easy. We'll be a bit cagey about adding key-value pairs as it can trigger the generation of a copy which can cause bewilderment and problems- values don't get passed back. Don't fill anything in here!!! The script does that for you#> $DatabaseDetails = @{ 'RDBMS'=''; # necessary for systems with several RDBMS on the same server 'server' = ''; #the name of your server 'database' = ''; #the name of the database 'version' = ''; #the version 'ProjectFolder' = Split-Path $PWD -Parent; #where all the migration files are 'project' = $env:FP__projectName__; #the name of your project 'schemas'=$env:FP__schemas__ # only needed if you are calling flyway 'historyTable'="$($env:FP__flyway_defaultSchema__).$($env_FP__flyway_filename__ )"; 'projectDescription'=$env:FP__projectDescription__; #a brief description of the project 'uid' = $env:FLYWAY_USER; #optional if you are using windows authewntication 'pwd' = ''; #only if you use a uid. Leave blank. we fill it in for you 'locations' = @{ }; # for reporting file locations used 'problems' = @{ }; # for reporting any big problems 'warnings' = @{ } # for reporting any issues } # for reporting any warnings #our regex for gathering variables from Flyway's URL $FlywayURLRegex = 'jdbc:(?<RDBMS>[\w]{1,20})://(?<server>[\w\-\.]{1,40})(?<port>:[\d]{1,4}|)(;.*databaseName=|/)(?<database>[\w]{1,20})' $FlywayURLTruncationRegex ='jdbc:.{1,30}://.{1,30}(;|/)' #this FLYWAY_URL contains the current database, port and server so # it is worth grabbing $ConnectionInfo = $env:FLYWAY_URL #get the environment variable if ($ConnectionInfo -eq $null) #OMG... it isn't there for some reason { $internalLog+='missing value for flyway url'; $WeCanContinue=$false; } $uid = $env:FLYWAY_USER; $ProjectFolder = $PWD.Path; if ($ConnectionInfo -imatch $FlywayURLRegex) #This copes with having no port. {#we can extract all the info we need $DatabaseDetails.RDBMS = $matches['RDBMS']; $DatabaseDetails.server = $matches['server']; $DatabaseDetails.port = $matches['port']; $DatabaseDetails.database = $matches['database'] } elseif ($ConnectionInfo -imatch 'jdbc:(?<RDBMS>[\w]{1,20}):(?<database>[\w:\\]{1,80})') {#no server or port $DatabaseDetails.RDBMS = $matches['RDBMS']; $DatabaseDetails.server = 'LocalHost'; $DatabaseDetails.port = 'default'; $DatabaseDetails.database = $matches['database'] } else { $DatabaseDetails.RDBMS = 'sqlserver'; $DatabaseDetails.server = 'LocalHost'; $DatabaseDetails.port = 'default'; $DatabaseDetails.database = $env:FP__flyway_database__; $internalLog+='unmatched connection info' } <# this assumes that reports will go in "$($env:USERPROFILE)\Documents\GitHub\$( $param1.EscapedProject)\$($param1.Version)\Reports" but will return the path in the $DatabaseDetails if you need it. Set it to whatever you want in ..\DatabaseBuildAndMigrateTasks.ps1 You will also need to set SQLCMD to the correct value. This is set by a string $SQLCmdAlias in ..\DatabaseBuildAndMigrateTasks.ps1 in order to execute tasks, you just load them up in the order you want. It is like loading a revolver. #> if ($InternalLog) {if ($InternalLog.count -gt 0) {$InternalLog|foreach{write-warning "$_"}}} $PostMigrationInvocations = @( $FetchAnyRequiredPasswords, #checks the hash table to see if there is a username without a password. #if so, it fetches the password from store or asks you for the password if it is a new connection $GetCurrentVersion, #checks the database and gets the current version number #it does this by reading the Flyway schema history table. $SaveDatabaseModelIfNecessary #Save the model for this version of the file ) Process-FlywayTasks $DatabaseDetails $PostMigrationInvocations |
Trying it out
To see this in action, I’ve provided a test harness that, first, runs a series of Flyway migrations, generating a database model for each new version, and then produces a summary report of the changes made in each successive version.
It’s all one script, stored here as CreateNarrative.ps1, but I’ll demo it in those two parts, first generating the models then producing the change report.
Generating a database model for each flyway migration
To make this happen, you’ll need to copy the sample Pubs project from GitHub, here in PubsAndFlyway/PubsFlywayTeamsMigration/. You’ll also need to install Diff-Objects and Display-Object from my Phil-Factor/PowerShell-Utility-Cmdlets.
Normally, if you were astute enough to already be running the afterVersioned__Narrative.ps1 file in your Flyway Teams projects, then every version you get to will already have that lean JSON model of the database, so you can move smugly on to the report-generating part of this article.
Otherwise, you’ll need to run the following harness. It runs the sample Pubs database through eleven versioned migrations, one by one. For each version, the call to the $SaveDatabaseModelIfNecessary task, from the script callback, writes out its JSON database model. Make sure that you have afterVersioned__Narrative.ps1 in the Scripts directory (it may have a ‘DontDo’ prefix; if it has, remove it).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 |
Set-Alias Flyway 'C:\ProgramData\chocolatey\lib\flyway.commandline\tools\flyway-8.2.0\flyway.cmd' -Scope local <# tell PowerShell where Flyway is. You need to change that to the correct path for your installation. You only need to do this if your flyway installation has not provideded a path cvommand #> $Details = @{ 'server' = '<MyServer>'; #The Server name 'database' = '<MyDatabaseName>'; #The Database 'Port' = '<Database Port>'; #not all rdbms have these 'uid' = '<MyUserName>'; #The User ID. you only need this if there is no domain authentication or secrets store #> 'pwd' = ''; # The password. This gets filled in if you request it 'version' = ''; # The Current Version. This gets filled in if you request it 'schemas' = '<listOfTheSchemas>'; 'project' = '<NameOfTheProject>'; #Just the simple name of the project 'ProjectFolder' = '<MyPathTo>\PubsAndFlyway\PubsFlywayTeamsMigration'; #parent the scripts directory 'ProjectDescription' = '<whatever you want attached to the project>' 'Warnings' = @{ }; # Just leave this be. Filled in for your information 'Problems' = @{ }; # Just leave this be. Filled in for your information 'Locations' = @{ }; # Just leave this be. Filled in for your information } # add a bit of error-checking. Is the project directory there if (-not (Test-Path "$($Details.ProjectFolder)")) { Write-Error "Sorry, but I couldn't find a project directory at the $ProjectFolder location" } # ...and is the script directory there? if (-not (Test-Path "$($Details.ProjectFolder)\Scripts")) { Write-Error "Sorry, but I couldn't find a scripts directory at the $ProjectFolder\Scripts location" } # now we get the password if necessary if ($Details.uid -ne '') #then it is using SQL Server Credentials { # we see if we've got these stored already $SqlEncryptedPasswordFile = "$env:USERPROFILE\$($Details.uid)-$($Details.server)-sqlserver.xml" # test to see if we know about the password in a secure string stored in the user area if (Test-Path -path $SqlEncryptedPasswordFile -PathType leaf) { #has already got this set for this login so fetch it $SqlCredentials = Import-CliXml $SqlEncryptedPasswordFile } else #then we have to ask the user for it (once only) { # hasn't got this set for this login $SqlCredentials = get-credential -Credential $Details.uid # Save in the user area $SqlCredentials | Export-CliXml -Path $SqlEncryptedPasswordFile <# Export-Clixml only exports encrypted credentials on Windows. otherwise it just offers some obfuscation but does not provide encryption. #> } $FlywayNarrativeArgs = @("-url=jdbc:sqlserver://$($Details.Server)$(if([string]::IsNullOrEmpty($Details.port)){''}else{':'+$Details.port});databaseName=$($Details.database)", "-locations=filesystem:$($Details.projectFolder)\Scripts", <# the migration folder #> "-user=$($SqlCredentials.UserName)", "-password=$($SqlCredentials.GetNetworkCredential().password)") $Details.pwd=$SqlCredentials.GetNetworkCredential().password; $Details.uid=$SqlCredentials.UserName } else { $FlywayNarrativeArgs = @("-url=jdbc:sqlserver://$($Server):$port;databaseName=$Details.Database;integratedSecurity=true". "-locations=filesystem:$ProjectFolder\Scripts")<# the migration folder #> } $FlywayNarrativeArgs += <# the project variables that we reference with placeholders #> @( "-schemas=$($Details.schemas)", '-errorOverrides=S0001:0:I-', #,S0001:50000:W-', "-placeholders.schemas=$($Details.schemas)", #This isn't passed to callbacks otherwise "-placeholders.projectDescription=$($Details.ProjectDescription)", "-placeholders.projectName=$($Details.Project)") cd "$($details.ProjectFolder)\scripts" . ..\DatabaseBuildAndMigrateTasks.ps1 # now we use the scriptblock to determine the version number and name from SQL Server $ServerVersion = $GetdataFromSQLCMD.Invoke($details, " Select Cast(ParseName ( Cast(ServerProperty ('productversion') AS VARCHAR(20)), 4) AS INT)") [int]$VersionNumber = $ServerVersion[0] if ($VersionNumber -ne $null) { $FlywayNarrativeArgs += @("-placeholders.canDoJSON=$(if ($VersionNumber -ge 13) { 'true' } else { 'false' })", "-placeholders.canDoStringAgg=$(if ($VersionNumber -ge 14) { 'true' } else { 'false' })") } #if this works we're probably good to go Flyway @FlywayNarrativeArgs info <# now we iterate through the versions we've actually achieved, and after doing each migration successfully, we can then store a model of the metadata as a JSON file to disk in the $versionpath we've just defined #> $VersionsSoFar = @('1.1.1', '1.1.2', '1.1.3', '1.1.4', '1.1.5', '1.1.6', '1.1.7', '1.1.8', '1.1.9', '1.1.10', '1.1.11') $VersionsSoFar | foreach -begin { Flyway @FlywayNarrativeArgs clean } -process { Flyway @FlywayNarrativeArgs migrate "-target=$($_)" } |
If all works well, your copy of the Pubs database should now be at v1.1.11 and in the specified location for your project reports ($MyDatabasePath in the DatabaseBuildAndMigrateTasks.ps1 PowerShell library) you’ll find a subdirectory for your database, and in that, a JSON model has been generated for every version:
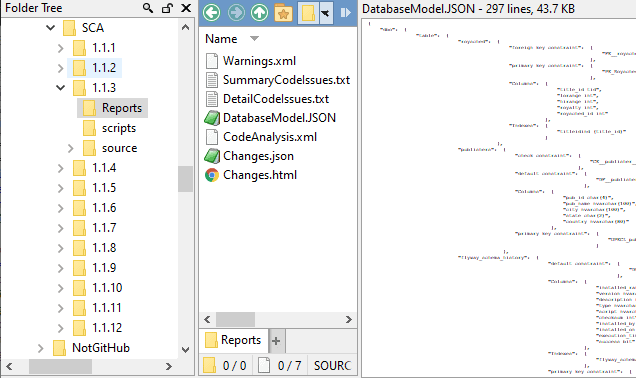
Getting the “diff” reports
What we want is a report of the changes for every version as a markdown file that looks nice in GitHub. The second part of the test harness reads every model, in order, and compares it with the previous version. It then generates and publishes a markdown report providing a narrative pf the changes between each version.
This part of CreateNarrative.ps1 requires my Diff-Objects and Display-Object PowerShell cmdlets (the latter is used by the former) to perform the “diff”, both of which you can get from my Phil-Factor/PowerShell-Utility-Cmdlets. I explain how it works in a Simple-talk blog, and used the same cmdlet in my Discovering What’s Changed by Flyway Migrations article, which demos the alternative, cross-RDBMS technique of generating models of the database from ODBC metadata.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
#Now we can generate a report for every migration but the first. We store them in the project directory #(not the scripts location directories) that contain all our reports and scripts $PreviousVersion = $null; # $ProjectLocation = "$($env:USERPROFILE)\Documents\GitHub\$($Details.Project)" $VersionsSoFar | foreach{ $Version = $_; if ($PreviousVersion -ne $null) { #see what is changed by comparing the models before and after the migration $Comparison = Diff-Objects -Parent $Details.Database -depth 10 <#get the previous model from file#>` ([IO.File]::ReadAllText("$ProjectLocation\$PreviousVersion\Reports\DatabaseModel.JSON") | ConvertFrom-JSON)<#and get the current model from file#> ` ([IO.File]::ReadAllText("$ProjectLocation\$Version\Reports\DatabaseModel.JSON") | ConvertFrom-JSON) | where { $_.match -ne '==' } $Comparison | Export-CSV -Path "$ProjectLocation\$Version\Reports\MetadataChanges.report" $Comparison | ConvertTo-JSON > "$ProjectLocation\$Version\Reports\MetadataChanges.json" #we can do all sorts of more intutive reports from the output } $PreviousVersion = $Version; } <# Now we can generate the narrative. We use the changes report we generated in order to produce the report. Here we've generated a markdown report but it can be almost anything you wish. Markdown is a useful intermediary and it looks good in Github.#> $ItsCool = $true; # unless something goes wrong $ProjectLocation = "$($env:USERPROFILE)\Documents\GitHub\$($Details.Project)" #firstly we ask Flyway for the history table ... $report = Flyway info @FlywayNarrativeArgs -outputType=json | convertFrom-json if ($report.error -ne $null) #if an error was reported by Flyway { #if an error (usually bad parameters) error out. $report.error | foreach { "$($_.errorCode): $($_.message)" $ItsCool = $false } } if ($report.allSchemasEmpty) #if it is an empty database { $ItsCool = $false; "all schemas of $($Details.database) are empty." } # unless we hit errors, we then produce the narrative if ($ItsCool) { #first put in the title $FinalReport = "# $($Details.database) Migration`n`n$($Details.ProjectDescription)`n`n" # skip the first version because there is no previous version to # compare it with $FinalReport += $VersionsSoFar | Select-Object -Skip 1 | foreach{ $Version = $_; $VersionContent="## Version $Version`n" #fetch the changes report... $changes = ([IO.File]::ReadAllText("$ProjectLocation\$Version\Reports\MetadataChanges.json") ) | ConvertFrom-JSON $VersionContent += $report.migrations | where { $_.version -eq $version } | foreach{ "A $($_.type) migration, $($_.description), installed on $(([datetime]$_.installedOnUTC).tostring(“MM-dd-yyyy”)) by $($_.installedBy) taking $($_.executionTime) ms.`n" } # we actually only read the record for the current version #now we document each change $VersionContent += $changes | foreach{ $current = $_; switch ($current.Match) { '->' { "$(if ($current.Target -ne 'PSCustomObject') { "- Added '$($current.Target)' to" } else { "- Added" }) '$($current.Ref)`n" } '<>' { "- Changed '$($current.Source)' to '$($current.Target )' at '$($current.Ref)`n" } '<-' { "- Deleted '$($current.Source)' at '$($current.Ref ) with version $version'`n" } default { "No metadata change `n" } } } $VersionContent > "$ProjectLocation\$Version\Reports\Narrative.md" $VersionContent } } $FinalReport > "$ProjectLocation\NarrativeofVersions.md" |
If all went well, each version would have three new files, which should provide you with enough flexibility to generate a report to taste. There will be a narrative.md that explains in what way the version changed the metadata. There is a CSV report of the changes and their location, and a JSON version of these metadata changes:
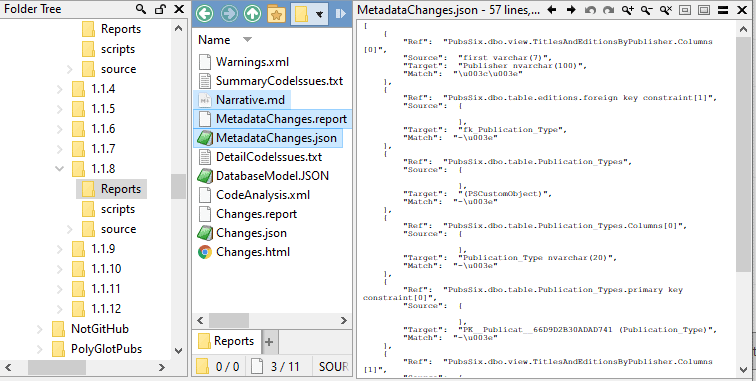
The narrative.md report for each version describes what changed. In GitHub (or Typora, or similar), this will look like this, for one migration chosen at random:

In the root of the output folder, you’ll find the NarativeOfVersions.md report, which details what changed across all versions, the start of which should look something like this…

Conclusions
It may be hitting you that if you make the build or migration process the heart of your database development work, you have a much better chance of providing the means of controlling and documenting what is happening and giving the whole development process better visibility. This is essentially what I’m trying to illustrate here, with the production of the narrative. With script callbacks, a lot of work can happen entirely automatically, producing analysis, code reviews, alerts or documentation. OK, it is a fair amount of up-front work, but once it is bedded down and working, it grids away to liberate you from the stultifying chores that would otherwise conspire to make your job a dull one.
Tools in this post
You may also like
-

Article
Building dbRosetta Part 5: We Need an API
Because I don’t want to have to fight with our support team (they’re awesome, but busy) I decided that, initially, I’m going to host dbRosetta at ScaryDBA.com. I have full control of the web site, and I won’t be breaking Redgate Software entirely if I accidently do something silly. Before starting the process of developing
-
Article
Organising your Migrations
In Flyway 6.4.0 we introduced a new feature, support for wildcards in the locations. With this feature a new set of solutions to organizing your migration files has now become available. In this post we hope to detail some of them, to aid the users of Flyway in deciding the solution that best suits their environment. Wildcards
-

Workshop
Workshop: Get started with Redgate Flyway using Autopilot
Join our exclusive workshop to get started with Redgate Flyway using Autopilot, an interactive, ready-made sample project that allows you to experience Redgate Flyway Enterprise with minimal setup.
-
Article
Flyway 7.1.0 Released
Flyway 7.1.0 is out! This release contains new features and improvements over Flyway 7.0.0. Highlights You can find a detailed list of the changes in the release notes. Filtering info output Flyway Teams In the Flyway CLI output from info can be filtered to only the parts of the history that you care about using the following 4 parameters,
-
Article
Flyway and Optimized Partition Management for Oracle Databases
I’m pleased to announce that Flyway continues to improve its support for Oracle databases with every release, focusing on performance, reliability, and developer efficiency. The most recent updates to Flyway Desktop and Flyway CLI specifically target a long-standing challenge for Oracle users: unnecessary table rebuilds when migrating to partitions or when managing partitions. This post
-
Article
A Simple Example of Flyway Development using GitHub Branching
This article demonstrates one way to do branch-based database development with Flyway, using GitHub to manage the branches and Flyway configuration files to allow Flyway to switch smoothly between databases, when we move between branches in GitHub.





