
SQL Server supports native JSON export (FOR JSON) and import (OPENJSON) as alternatives to BCP or CSV for transferring data between databases or systems. JSON transfer is slower than native BCP but faster than CSV for complex data, handles nested structures without flattening, and can be validated against a JSON Schema at either end of the transfer to catch malformed or contract-breaking data before it enters the target database.
This article walks through exporting an AdventureWorks table to JSON using FOR JSON PATH, reading it back with OPENJSON, and validating it against a JSON Schema definition. It also covers transferring nested data (objects with embedded arrays) and compares JSON performance with native BCP for the same workload. The main trade-off: native BCP wins on raw speed for large relational tables; JSON wins on schema flexibility, nested-structure support, and validation.
JSON has two distinct uses, to transmit data and to store it. They are best considered separately. When you use JSON to store data, you are generally forced down the route of using a special-purpose database, though SQL Server is happy to accommodate JSON as an NVARCHAR(MAX). For transmitting and transferring data, JSON should be part of your toolkit because it is so widely used and supported. SQL server has at last provided enough functionality to allow us to use JSON to transmit data within applications and between applications and receive data from web services and network sources. There is a rich infrastructure of both standards, resources, and components that make this easy.
Why do we stick to ODBC and TDS to send and receive tables? Well, it is for three reasons; the conventions within ODBC quietly send the metadata, or ‘data about the data,’ along with the data itself. Secondly, TDS (Tabular Data Stream) is a very efficient application-layer protocol; finally, it is bullet-proof in its reliability. Now that JSON is acquiring a standard for JSON Schema which is being adopted widely, is it time to reconsider? With network speeds a thousand times faster than when SQL Server was first created, are we still bound to the traditional ways of transferring data? Should we consider other ways?
I have long had a dream of transferring data in such a way that the recipient has enough information to create a table automatically to receive the data. In other words, it transfers the metadata as well as the data. It makes it possible to transfer tables between different systems. Sure, ODBC actually does this, but it is not a file-based transfer.
I will be showing how to save SQL Server tables as JSON files that include the metadata and import them into SQL Server. We’ll test it out by attempting this on AdventureWorks.
If you are interested in checking out JSON to see if it works for you, I’ll be showing you how you can transfer both the data and the metadata or schema, using JSON with JSON Schema, with standard conventions, and avoid the quirks in the SQL Server implementation.
Why Bother with JSON Schema?
JSON Schema allows you to validate the contents of a JSON file and to specify constraints. It also provides a standard way of providing metadata for other purposes beyond JSON-based storage. MongoDB, for example, can use JSON Schema to validate a collection. NewtonSoft provides an excellent version of JSON that has full JSON Schema support and an online JSON Validator. You can even generate JSON Schemas from NET types. For me, the attraction is that I can avoid having to invent a way of transferring the metadata of file-based JSON Data. Data is always better with its metadata.
Why Use JSON at All When We Have Good Old CSV?
JSON wasn’t originally intended for relational data which is constrained by a schema or where the order of data within a row is invariant, as it is in CSV. However, raw JSON is good-natured enough not to object if you want to use it that way. No matter how you choose to use it, you’ll notice something useful if you are accustomed to CSV: JSON supports null values as well as the bit values true and false. At last, you can distinguish between a blank string and a null one.
If one can send the metadata in a way that is useful enough to allow creating a table successfully with it, then it is worth the effort. However, there are other benefits, because nowadays the front-end developers understand, and are happy with, JSON. They are content just to send and receive data in this format. This suits me, because they lose interest in accessing the base tables.
The CSV standard allows the first ‘header’ line to display the name of the column rather than the first line of data. The header line is in the same format as normal record lines. This goes some small way towards portability, but with JSON, we have the opportunity to associate far more of the metadata or a schema with the data. CSV can only be used effectively if both ends of the conversation know what every column means based on the name of the file and the header row, but with JSON, we don’t have to be so restrictive, because we can send a schema with the data.
I’ll explain more about this later, but first, we need to be confident that we are able to use JSON to reliably copy a table from one server to another. We will, for this article, stick to the most common way of rendering tabular data, as an array of objects. It is probably the simplest because it represents the way used by FOR JSON queries.
Transferring Data as an Array of Objects.
We need to consider both the Data and the Schema. For this article, we’ll just stick to tables, rather than the broader topic of results of queries of maybe several tables. We need to provide a way of reading and writing these files.
There are some interesting things we have to take into account in reading data into a table.
- OPENJson function can’t have certain deprecated datatypes in its ‘explicit schema’ syntax. We have to specify them as NVARCHAR(x)
- FOR JSON cannot use some of Microsoft’s own CLR datatypes.
- We have to cope properly with identity fields.
- If importing data into a group of related tables, we need to temporarily disable all constraints before we start and turn them back on when we finish, and we need to wrap the operation in a transaction.
- JSON files are, by convention, written in UTF-8 file format.
This makes the process a bit more complicated than you’d imagine and makes the requirement for a schema more important. We’ll look at what is required in small bites rather than the grand overview.
Writing the File Out
Here is what we’d like to achieve first: it is a JSON rendering of the AdventureWorks PhoneNumberType table, stored in a file. It contains both the data and the schema. You can keep data and schema separate if you prefer or have the two together in the one file. The schema has extra fields beyond the reserved JSON Schema fields just to make life convenient for us. It tells us where the table came from and what the columns consisted of. It also tells us if the columns are nullable. As we can add fields, we can even transfer column-level or table-level check constraints if we want to. The schema should have a unique identifier, the $id. Eventually, this should resolve to a reference to a file, but this is not currently a requirement. It is intended to enable the reuse of JSON schemas. It should also have a $schema keyword to identify the JSON object as a JSON schema. However, the schema can be blank, which means that all the JSON data with correct syntax that is validated against it passes validation. Here is an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
{ "schema":{ "$id":"https://mml.uk/jsonSchema/Person-PhoneNumberType.json", "$schema":"http://json-schema.org/draft-07/schema#", "title":"PhoneNumberType", "SQLtablename":"[Person].[PhoneNumberType]", "SQLschema":"Person", "type":"array", "items":{ "type":"object", "required":[ "PhoneNumberTypeID", "Name", "ModifiedDate" ], "maxProperties":4, "minProperties":3, "properties":{ "PhoneNumberTypeID":{ "type":[ "number" ], "sqltype":"int", "columnNo":1, "nullable":0, "Description":"" }, "Name":{ "type":[ "string" ], "sqltype":"nvarchar(50)", "columnNo":2, "nullable":0, "Description":"" }, "ModifiedDate":{ "type":[ "string" ], "sqltype":"datetime", "columnNo":3, "nullable":0, "Description":"" } } } }, "data":[ { "PhoneNumberTypeID":1, "Name":"Cell", "ModifiedDate":"2017-12-13T13:19:22.273" }, { "PhoneNumberTypeID":2, "Name":"Home", "ModifiedDate":"2017-12-13T13:19:22.273" }, { "PhoneNumberTypeID":3, "Name":"Work", "ModifiedDate":"2017-12-13T13:19:22.273" } ] } |
The schema object contains a valid JSON Schema for our result, tested to the json-schema.org standard (4 upwards). It enforces the object-within-array structure of the JSON and the order and general data type of each column. You’ll see that I’ve added some fields that we need for SQL Server to SQL Server transfer.
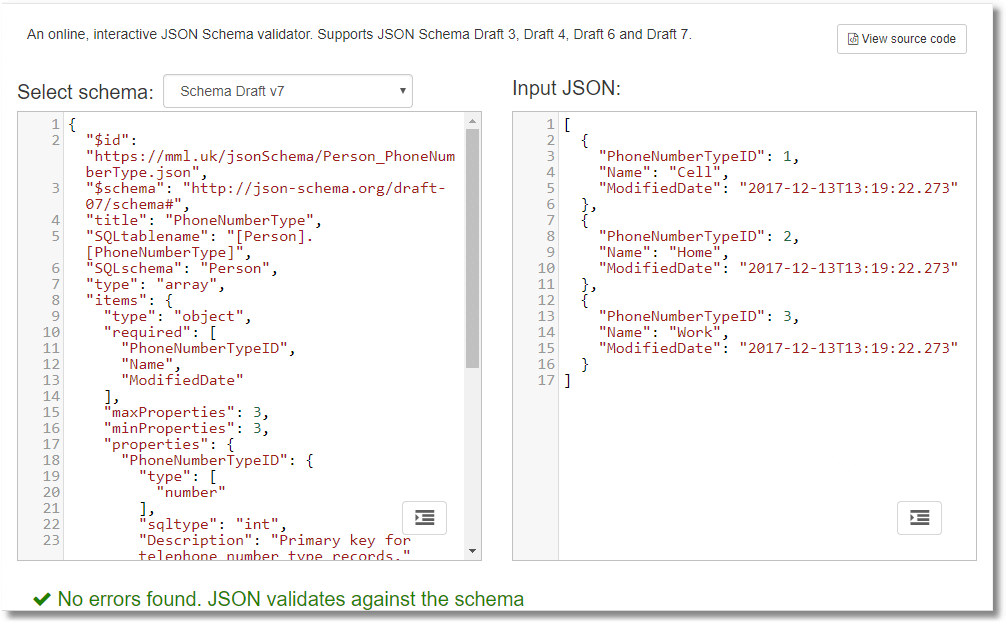
It is worth trying this out with the NewtonSoft validator seen above, manipulating the data and seeing when it notices! I haven’t added a regex to check the date format because our JSON is generated automatically, but there are a lot of useful checks you can add. This can be done in PowerShell and is a useful routine way of checking JSON data before you import it.
This schema is for the JSON version of the data as an array of objects. Fortunately, it is easy to generate the data because this is the natural way of FOR JSON AUTO.
|
1 2 3 |
declare @Thedata nvarchar(max)= (SELECT * FROM adventureworks2016.person.PhoneNumbertype FOR JSON auto, INCLUDE_NULL_VALUES) Print @TheData; |
…which gives the result …
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[ { "PhoneNumberTypeID":1, "Name":"Cell", "ModifiedDate":"2017-12-13T13:19:22.273" }, { "PhoneNumberTypeID":2, "Name":"Home", "ModifiedDate":"2017-12-13T13:19:22.273" }, { "PhoneNumberTypeID":3, "Name":"Work", "ModifiedDate":"2017-12-13T13:19:22.273" } ] |
The only complication is the fact that we need to include null values. Otherwise, the path specifications we need to use in OpenJSON to create a SQL result don’t always work, and the error it gives doesn’t tell you why. It is a good idea to provide a list of columns rather than a Select *, because we can then coerce tricky data types or do data conversions explicitly. If everything we have to do is as easy as that, it will be a short article.
We soon find out that it isn’t that easy.
|
1 |
SELECT * FROM Adventureworks2016.person.address FOR JSON auto, INCLUDE_NULL_VALUES |
Gives the error

Alas, the JSON implementation has not yet come to grips with the geography datatype. Even to reliably export a table, we must spell out the columns if the table has CLR user types other than hierarchyid. This works.
|
1 2 3 4 |
SELECT AddressID, AddressLine1, AddressLine2, City, Address.StateProvinceID, PostalCode, Convert(VARBINARY(80),SpatialLocation) AS SpatialLocation, rowguid, ModifiedDate FROM Adventureworks2016.person.address FOR JSON auto, INCLUDE_NULL_VALUES |
Although it provides the JSON, you need to carry the information about the SQL Server data type that the spatialLocation represents. As you can appreciate, to make it easy to consume a JSON document in SQL Server, you also need a schema.
Now we need to create the JSON.Schema of that JSON we just produced. There is a draft standard for this that is understood by the best .NET JSON package (NewtonSoft) as well as MongoDB 3.6 onwards. At the moment, it can do basic constraints and datatype checks, but it can also allow us to create a SQL table if we add sufficient information. Our extra information doesn’t interfere with JSON schema validation as long as we don’t use reserved words.
SQL Server doesn’t support any type of JSON schema information other than the one used in OpenJSON WITH. It is optimistically called ‘explicit schema.’ Although this is very useful, it can’t be transferred with the data or referenced from a URL. Sadly, it cannot be passed to the OpenJSON function as a string or as JSON. Ideally, one would want to use JSON Schema, which is now also used increasingly in MongoDB.
The application that is using the database will probably know about JSON Schema because the NewtonSoft JSON library is so popular and can pass it to you. Unfortunately, the datatypes in SQL Server are a rich superset of the basic JSON number, string, and Boolean. You won’t even get a datetime. JSON Schema, however, allows you to extend the basics with other fields, so we’ll do just that.
If you aren’t interested in JSON Schemas, you can still use them, just using { } or true as your schema, which means ‘anything goes’ or ‘live free and die, earlier than you think.’
We need to enforce nullability from the JSON perspective. This is done by defining the number type as an array. A nullable number allows both numbers and nulls, whereas a nullable string allows both nulls and strings. Because the sensible database developer adds descriptions to columns via the ms_description extended property, we can include that. We have added fields that aren’t part of the standard just to help us: SQLtype, column_ordinal, is_nullable, for example. This is allowed by the standard.
We use the handy sys.dm_exec_describe_first_result_set table function that gives us even more information than we want. I’m writing this for SQL Server 2017. SQL Server 2016 is usable, but the STRING_AGG() function is much neater for demonstration purposes than the XML concatenation trick.
I will demonstrate, in this article, how to create a batch to save all the JSON Schemas for all the tables in the current database. But first, you’ll need two procedures. They are temporary so there is no mopping up to be done afterward, but you can easily make them permanent in a ‘utility’ database if they are useful to you later. The schemas are saved into a directory within C:\data\RawData\ on your server. (Obviously, you alter this to suit) The files will be stored in a subdirectory based on the name of the database, followed by Schema. Be sure to create the directory before running the code.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 |
CREATE OR ALTER PROCEDURE #CreateJSONSchemaFromTable /** Summary: > This creates a JSON schema from a table that matches the JSON you will get from doing a classic FOR JSON select * statement on the entire table Author: Phil factor Date: 26/10/2018 Examples: > DECLARE @Json NVARCHAR(MAX) EXECUTE #CreateJSONSchemaFromTable @database='pubs', @Schema ='dbo', @table= 'authors',@JSONSchema=@json OUTPUT PRINT @Json SELECT @json='' EXECUTE #CreateJSONSchemaFromTable @TableSpec='pubs.dbo.authors',@JSONSchema=@json OUTPUT PRINT @Json Returns: > nothing **/ (@database sysname=null, @Schema sysname=NULL, @table sysname=null, @Tablespec sysname=NULL,@jsonSchema NVARCHAR(MAX) output) --WITH ENCRYPTION|SCHEMABINDING, ... AS DECLARE @required NVARCHAR(max), @NoColumns INT, @properties NVARCHAR(max); IF Coalesce(@table,@Tablespec) IS NULL OR Coalesce(@schema,@Tablespec) IS NULL RAISERROR ('{"error":"must have the table details"}',16,1) IF @table is NULL SELECT @table=ParseName(@Tablespec,1) IF @Schema is NULL SELECT @schema=ParseName(@Tablespec,2) IF @Database is NULL SELECT @Database=ParseName(@Tablespec,3) IF @table IS NULL OR @schema IS NULL OR @database IS NULL RAISERROR ('{"error":"must have the table details"}',16,1) DECLARE @SourceCode NVARCHAR(255)= (SELECT 'SELECT * FROM '+QuoteName(@database)+ '.'+ QuoteName(@Schema)+'.'+QuoteName(@table)) SELECT @properties= String_Agg(' "'+f.name+'": {"type":["'+Replace(type,' ','","')+'"],"sqltype":"'+sqltype+'", "columnNo":'+ Convert(VARCHAR(3), f.column_ordinal) +', "nullable":'+Convert(CHAR(1),f.is_nullable)+', "Description":"' +String_Escape(Coalesce(Convert(NvARCHAR(875),EP.value),''),'json')+'"}',','), @NoColumns=Max(f.column_ordinal), @required=String_Agg('"'+f.Name+'"',',') FROM ( --the basic columns we need. (the type is used more than once in the outer query) SELECT r.name, r.system_type_name AS sqltype, r.source_column, r.is_nullable,r.column_ordinal, CASE WHEN r.system_type_id IN (48, 52, 56, 58, 59, 60, 62, 106, 108, 122, 127) THEN 'number' WHEN system_type_id = 104 THEN 'boolean' ELSE 'string' END + CASE WHEN r.is_nullable = 1 THEN ' null' ELSE '' END AS type, Object_Id(r.source_database + '.' + r.source_schema + '.' + r.source_table) AS table_id FROM sys.dm_exec_describe_first_result_set (@sourcecode, NULL, 1) AS r ) AS f LEFT OUTER JOIN sys.extended_properties AS EP -- to get the extended properties ON EP.major_id = f.table_id AND EP.minor_id = ColumnProperty(f.table_id, f.source_column, 'ColumnId') AND EP.name = 'MS_Description' AND EP.class = 1 SELECT @JSONschema = Replace( Replace( Replace( Replace( Replace('{ "$id": "https://mml.uk/jsonSchema/<-schema->-<-table->.json", "$schema": "http://json-schema.org/draft-07/schema#", "title": "<-table->", "SQLtablename":"'+quotename(@schema)+'.'+quotename(@table)+'", "SQLschema":"<-schema->", "type": "array", "items": { "type": "object", "required": [<-Required->], "maxProperties": <-MaxColumns->, "minProperties": <-MinColumns->, "properties":{'+@properties+'} } }', '<-minColumns->', Convert(VARCHAR(5),@NoColumns) COLLATE DATABASE_DEFAULT ) , '<-maxColumns->',Convert(VARCHAR(5),@NoColumns +1) COLLATE DATABASE_DEFAULT ) , '<-Required->',@required COLLATE DATABASE_DEFAULT ) ,'<-schema->',@Schema COLLATE DATABASE_DEFAULT ) ,'<-table->', @table COLLATE DATABASE_DEFAULT ); IF(IsJson(@jsonschema)=0) RAISERROR ('invalid schema "%s"',16,1,@jsonSchema) IF @jsonschema IS NULL RAISERROR ('Null schema',16,1) GO go CREATE OR ALTER PROCEDURE #SaveJSONToFile @TheString NVARCHAR(MAX), @Filename NVARCHAR(255), @Unicode INT=8 --0 for not unicode, 8 for utf8 and 16 for utf16 AS SET NOCOUNT ON DECLARE @MySpecialTempTable sysname DECLARE @Command NVARCHAR(4000) DECLARE @RESULT INT --firstly we create a global temp table with a unique name SELECT @MySpecialTempTable = '##temp' + CONVERT(VARCHAR(12), CONVERT(INT, RAND() * 1000000)) --then we create it using dynamic SQL, & insert a single row --in it with the MAX Varchar stocked with the string we want SELECT @Command = 'create table [' + @MySpecialTempTable + '] (MyID int identity(1,1), Bulkcol nvarchar(MAX)) insert into [' + @MySpecialTempTable + '](BulkCol) select @TheString' EXECUTE sp_ExecuteSQL @command, N'@TheString nvarchar(MAX)', @TheString SELECT @command --then we execute the BCP to save the file SELECT @Command = 'bcp "select BulkCol from [' + @MySpecialTempTable + ']' + '" queryout ' + @Filename + ' ' + CASE @Unicode WHEN 0 THEN '-c' WHEN 8 THEN '-c -C 65001' ELSE '-w' END + ' -T -S' + @@ServerName SELECT @command EXECUTE @RESULT= MASTER..xp_cmdshell @command EXECUTE ( 'Drop table ' + @MySpecialTempTable ) RETURN @result go |
To create a valid JSON.Schema file in that #CreateJSONSchemaFromTable stored procedure, I’ve had to create it as a string because SQL Server’s FOR JSON couldn’t do all the work. That is the joy of JSON: it is so simple that you have the option of creating it as a string if the automatic version doesn’t quite do what you want. It is doing a few quite tricky things such as the array of JSON types that are necessary to check for nullability in JSON. You can verify it, too, with ISJSON() to be doubly certain it’s proper JSON, as I’ve done.
Once these procedures are in place, you can work considerable magic. To start fairly simply, here is how you can create the JSON for a specific table, both schema and data, and save it to disk on the server
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
DECLARE @TheJSONSchema NVARCHAR(MAX); EXECUTE #CreateJSONSchemaFromTable @Tablespec = 'adventureworks2016.HumanResources.Employee', @jsonSchema = @TheJSONSchema OUTPUT; DECLARE @TheJSONdata NVARCHAR(MAX) = ( SELECT * FROM AdventureWorks2016.HumanResources.Employee FOR JSON AUTO, INCLUDE_NULL_VALUES ); DECLARE @TheJSON NVARCHAR(MAX) = ( SELECT * FROM (VALUES (Json_Query(@TheJSONSchema), Json_Query(@TheJSONdata))) AS f ( [schema], data ) FOR JSON AUTO, WITHOUT_ARRAY_WRAPPER ); EXECUTE #SaveJSONToFile @TheJSON, 'C:\data\RawData\HumanResources-Employee.json', 8; |
You can, of course, save the JSON Schema file of all the tables in your database:
|
1 2 3 4 5 6 |
DECLARE @TheCommand NVARCHAR(4000) SELECT @TheCommand='DECLARE @ourJSONSchema NVARCHAR(MAX) --our JSON Schema EXECUTE #CreateJSONSchemaFromTable @TableSpec='''+Db_Name()+'.?'',@JSONSchema=@ourJSONSchema OUTPUT DECLARE @destination NVARCHAR(MAX) = (Select ''C:\data\RawData\'+Db_Name()+'Schema\''+Replace(Replace(Replace(''?'',''.'',''-''),'']'',''''),''['','''')+''.json'') Execute #SaveJSONToFile @theString=@ourJSONSchema, @filename=@destination' EXECUTE sp_MSforeachtable @command1=@TheCommand |
You can run the script to create the schema for all the tables of any database just by running it within the context of that database or add the USE directive.
Just to show that we have the power, here is how you can save all the JSON files, containing both the schema and data for all your tables all in one go. We still have some way to go because the CLR datatypes aren’t yet handled. We’ll deal with that soon.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DECLARE @TheCommand NVARCHAR(4000) SELECT @TheCommand=' DECLARE @TheJSONSchema NVARCHAR(MAX) --our JSON Schema EXECUTE #CreateJSONSchemaFromTable @TableSpec='''+Db_Name()+'.?'',@JSONSchema=@TheJSONSchema OUTPUT DECLARE @destination NVARCHAR(MAX) = (Select ''C:\data\RawData\'+Db_Name()+'SchemaData\''+Replace(Replace(Replace(''?'',''.'',''-''),'']'',''''),''['','''')+''.json'') DECLARE @TheJSONdata nvarchar(max)= (SELECT * FROM '+Db_Name()+'.? FOR JSON auto, INCLUDE_NULL_VALUES); DECLARE @TheJSON NVARCHAR(MAX)= (SELECT * FROM (VALUES(Json_Query(@Thejsonschema), Json_Query(@TheJSONData)))f([schema],[data]) FOR JSON AUTO, WITHOUT_ARRAY_WRAPPER); Execute #SaveJSONToFile @theString=@TheJSON, @filename=@destination' EXECUTE sp_MSforeachtable @command1=@TheCommand |
If you attempted this on AdventureWorks, you’ll appreciate that it will be a difficult article after all. This is because we have still to tackle the task of getting the JSON data when we have difficult datatypes such as CLR. Here is the procedure that will do that:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
CREATE OR ALTER PROCEDURE #SaveJsonDataFromTable /** Summary: > This gets the JSON data from a table Author: phil factor Date: 26/10/2018 Examples: > USE pubs DECLARE @Json NVARCHAR(MAX) EXECUTE #SaveJsonDataFromTable @database='pubs', @Schema ='dbo', @table= 'authors', @JSONData=@json OUTPUT PRINT @Json Returns: > The JSON data **/ (@database sysname = NULL, @Schema sysname = NULL, @table sysname = NULL, @Tablespec sysname = NULL, @jsonData NVARCHAR(MAX) OUTPUT ) AS BEGIN DECLARE @Data NVARCHAR(MAX); IF Coalesce(@table, @Tablespec) IS NULL OR Coalesce(@Schema, @Tablespec) IS NULL RAISERROR('{"error":"must have the table details"}', 16, 1); IF @table IS NULL SELECT @table = ParseName(@Tablespec, 1); IF @Schema IS NULL SELECT @Schema = ParseName(@Tablespec, 2); IF @database IS NULL SELECT @database = ParseName(@Tablespec, 3); IF @table IS NULL OR @Schema IS NULL OR @database IS NULL RAISERROR('{"error":"must have the table details"}', 16, 1); DECLARE @SourceCode NVARCHAR(255) = ( SELECT 'SELECT * FROM ' + QuoteName(@database) + '.' + QuoteName(@Schema) + '.' + QuoteName(@table) ); DECLARE @params NVARCHAR(MAX) = ( SELECT String_Agg( CASE WHEN user_type_id IN (128, 129, 130) THEN 'convert(nvarchar(max),' + name + ') as "' + name + '"' --hierarchyid (128) geometry (130) and geography types (129) can be coerced. WHEN user_type_id IN (35) THEN 'convert(varchar(max),' + name + ') as "' + name + '"' WHEN user_type_id IN (99) THEN 'convert(nvarchar(max),' + name + ') as "' + name + '"' WHEN user_type_id IN (34) THEN 'convert(varbinary(max),' + name + ') as "' + name + '"' ELSE QuoteName(name) END, ', ' ) FROM sys.dm_exec_describe_first_result_set(@SourceCode, NULL, 1) ); DECLARE @expression NVARCHAR(800) = ' USE ' + @database + ' SELECT @TheData=(SELECT ' + @params + ' FROM ' + QuoteName(@database) + '.' + QuoteName(@Schema) + '.' + QuoteName(@table) + ' FOR JSON auto, INCLUDE_NULL_VALUES)'; EXECUTE sp_executesql @expression, N'@TheData nvarchar(max) output', @TheData = @jsonData OUTPUT; END; GO |
You’d use it like this to get the data (make sure you create the directory first!):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE WideWorldImporters DECLARE @TheCommand NVARCHAR(4000) SELECT @TheCommand=' Declare @Path sysname =''C:\data\RawData\'+Db_Name()+'Data\'' DECLARE @destination NVARCHAR(MAX) = (Select @path+Replace(Replace(Replace(''?'',''.'',''-''),'']'',''''),''['','''')+''.json'') DECLARE @Json NVARCHAR(MAX) EXECUTE #SaveJsonDataFromTable @database='''+Db_Name()+''', @tablespec= ''?'', @JSONData=@json OUTPUT Execute #SaveJSONToFile @theString=@Json, @filename=@destination' EXECUTE sp_MSforeachtable @command1=@TheCommand |
To create files with the data and schema together, you’d do this
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DECLARE @TheCommand NVARCHAR(4000) SELECT @TheCommand=' DECLARE @TheJSONSchema NVARCHAR(MAX) --our JSON Schema EXECUTE #CreateJSONSchemaFromTable @TableSpec='''+Db_Name()+'.?'',@JSONSchema=@TheJSONSchema OUTPUT DECLARE @destination NVARCHAR(MAX) = (Select ''C:\data\RawData\'+Db_Name()+'SchemaData\''+Replace(Replace(Replace(''?'',''.'',''-''),'']'',''''),''['','''')+''.json'') DECLARE @TheJsonData NVARCHAR(MAX) EXECUTE #SaveJsonDataFromTable @database='''+Db_Name()+''', @tablespec= ''?'', @JSONData=@TheJsonData OUTPUT DECLARE @TheJSON NVARCHAR(MAX)= (SELECT * FROM (VALUES(Json_Query(@Thejsonschema), Json_Query(@TheJSONData)))f([schema],[data]) FOR JSON AUTO, WITHOUT_ARRAY_WRAPPER); Execute #SaveJSONToFile @theString=@TheJSON, @filename=@destination' EXECUTE sp_MSforeachtable @command1=@TheCommand |
We can read out AdventureWorks into files, one per table, in around forty seconds. Sure, it takes a bit longer than BCP, but the data is easier to edit!
Reading the File Back in
Now on another computer, we can pick the file up and easily shred it back into a table. We might want to complete one of two common tasks. If we are creating a table from the imported data, then we have to get the data from the schema and SELECT INTO the table. If we want to stock an existing table, then we want to INSERT INTO. In the second case, we can get the metadata from the table instead of the JSON file in order to do this.
Reading the JSON Data into an NVARCHAR(MAX) Variable
This should work to read in the data from a file that is local to the server, but it doesn’t seem to import utf-8 data properly. However, for this test harness, it is OK.
|
1 2 3 |
DECLARE @JSONImport NVARCHAR(MAX) = (SELECT BulkColumn FROM OPENROWSET (BULK 'C:\data\RawData\AdventureWorks2016SchemaData\HumanResources-Employee.json', SINGLE_CLOB, CODEPAGE='65001') AS json ) |
Shredding JSON into a Table Source Manually
Now, assuming we have a JSON file that has both the schema and the data, we can do this to get a result when either doing a SELECT INTO or an INSERT INTO.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SELECT * FROM OpenJson(@JSONImport,'strict $.data') WITH ( BusinessEntityID int '$.BusinessEntityID', NationalIDNumber nvarchar(15) '$.NationalIDNumber', LoginID nvarchar(256) '$.LoginID', --OrganizationNode hierarchyid '$.OrganizationNode', OrganizationLevel smallint '$.OrganizationLevel', JobTitle nvarchar(50) '$.JobTitle', BirthDate date '$.BirthDate', MaritalStatus nchar(1) '$.MaritalStatus', Gender nchar(1) '$.Gender', HireDate date '$.HireDate', SalariedFlag bit '$.SalariedFlag', VacationHours smallint '$.VacationHours', SickLeaveHours smallint '$.SickLeaveHours', CurrentFlag bit '$.CurrentFlag', rowguid uniqueidentifier '$.rowguid', ModifiedDate datetime '$.ModifiedDate' ); |
If you have made it to this point without reading the first part of the article, you might have thought that I’d typed all that SQL code out. No. I could have done it, but it’s a bit boring to do so, and I make mistakes.
You will notice that I had to comment out the organisationNode field. This is because CLR datatypes aren’t yet supported with the Explicit Schema (WITH (…)) syntax.
You need to do this instead
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECT BusinessEntityID, NationalIDNumber, LoginID, Convert(HIERARCHYID,OrganizationNode) AS OrganizationNode, OrganizationLevel, JobTitle, BirthDate, MaritalStatus, Gender, HireDate, SalariedFlag, VacationHours, SickLeaveHours, CurrentFlag, rowguid, ModifiedDate FROM OpenJson(@JSONImport,'strict $.data') WITH ( BusinessEntityID int '$.BusinessEntityID', NationalIDNumber nvarchar(15) '$.NationalIDNumber', LoginID nvarchar(256) '$.LoginID', OrganizationNode NVARCHAR(100) '$.OrganizationNode', OrganizationLevel smallint '$.OrganizationLevel', JobTitle nvarchar(50) '$.JobTitle', BirthDate date '$.BirthDate', MaritalStatus nchar(1) '$.MaritalStatus', Gender nchar(1) '$.Gender', HireDate date '$.HireDate', SalariedFlag bit '$.SalariedFlag', VacationHours smallint '$.VacationHours', SickLeaveHours smallint '$.SickLeaveHours', CurrentFlag bit '$.CurrentFlag', rowguid uniqueidentifier '$.rowguid', ModifiedDate datetime '$.ModifiedDate' ); |
You’ll also find that you can’t use legacy types such a text, image and image either. In this case, you need to specify the equivalent MAX type instead.
Automating the Shredding of the JSON with the Help of JSON Schema
This means. that to import JSON reliably into a lot of tables, you will need to resort to assembling and executing code as a string using sp_executesql. This allows you to generate both the rather tedious column list and that rather daunting list of column specifications called the OpenJSON explicit schema automatically from the JSON Schema, or even an existing table if you wish. This now means that we can take any data from a file and read it straight into a suitable table.
Of course, you will probably want to make sure that the JSON is valid before importing into a database. I have written a post that describes how to automate this for a large number of files.
We’ll start with a little test harness with a sample JSON schema and show how you can generate these two strings, the column specification, and the explicit schema. We need to do it in a way that will get around the restrictions of the OpenJSON implementation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
Declare @jsonSchema NVARCHAR(max)= '{ "$id": "https://mml.uk/jsonSchema/Person-Address.json", "$schema": "http://json-schema.org/draft-07/schema#", "title": "Address", "SQLtablename":"Person.Address", "SQLschema":"Person", "type": "array", "items": { "type": "object", "required": ["AddressID","AddressLine1","AddressLine2","City","StateProvinceID","PostalCode","SpatialLocation","rowguid","ModifiedDate"], "maxProperties": 9, "minProperties": 9, "properties":{ "AddressID": {"type":["number"],"sqltype":"int", "columnNo":1, "nullable":0, "Description":"Primary key for Address records."}, "AddressLine1": {"type":["string"],"sqltype":"nvarchar(60)", "columnNo":2, "nullable":0, "Description":"First street address line."}, "AddressLine2": {"type":["string","null"],"sqltype":"nvarchar(60)", "columnNo":3, "nullable":1, "Description":"Second street address line."}, "City": {"type":["string"],"sqltype":"nvarchar(30)", "columnNo":4, "nullable":0, "Description":"Name of the city."}, "StateProvinceID": {"type":["number"],"sqltype":"int", "columnNo":5, "nullable":0, "Description":"Unique identification number for the state or province. Foreign key to StateProvince table."}, "PostalCode": {"type":["string"],"sqltype":"nvarchar(15)", "columnNo":6, "nullable":0, "Description":"Postal code for the street address."}, "SpatialLocation": {"type":["string","null"],"sqltype":"geography", "columnNo":7, "nullable":1, "Description":"Latitude and longitude of this address."}, "rowguid": {"type":["string"],"sqltype":"uniqueidentifier", "columnNo":8, "nullable":0, "Description":"ROWGUIDCOL number uniquely identifying the record. Used to support a merge replication sample."}, "ModifiedDate": {"type":["string"],"sqltype":"datetime", "columnNo":9, "nullable":0, "Description":"Date and time the record was last updated."}} } } ' /* the 'explicit schema'*/ SELECT String_Agg(quotename(property.[key])+' '+ CASE sqltype WHEN 'hierarchyid' THEN 'nvarchar(30)' WHEN 'geometry'THEN 'nvarchar(100)' WHEN 'geography' THEN 'nvarchar(100)' WHEN 'image' THEN 'Varbinary(max)' WHEN 'text' THEN 'Varchar(max)' WHEN 'ntext' THEN 'Nvarchar(max)' ELSE sqltype end+ ' ''$."'+property.[key]+'"''',',') FROM OpenJson(@jsonSchema,'strict $.items.properties') property OUTER APPLY OpenJson(property.value) WITH (sqltype VARCHAR(20) 'strict $.sqltype'); /* the parameter list */ SELECT String_Agg( CASE WHEN sqltype IN ( 'hierarchyid', 'geometry', 'geography') THEN 'Convert('+sqlType+','+QuoteName(property.[key])+') AS "'+property.[key]+'"' ELSE property.[key] end,', ') FROM OpenJson(@jsonSchema,'strict $.items.properties') property OUTER APPLY OpenJson(property.value) WITH (sqltype VARCHAR(20) 'strict $.sqltype'); |
In this case, what we get is this ‘explicit schema’ to place in OpenJSON’s WITH clause,
|
1 |
[AddressID] int '$."AddressID"',[AddressLine1] nvarchar(60) '$."AddressLine1"',[AddressLine2] nvarchar(60) '$."AddressLine2"',[City] nvarchar(30) '$."City"',[StateProvinceID] int '$."StateProvinceID"',[PostalCode] nvarchar(15) '$."PostalCode"',[SpatialLocation] nvarchar(100) '$."SpatialLocation"',[rowguid] uniqueidentifier '$."rowguid"',[ModifiedDate] datetime '$."ModifiedDate"' |
…and a list of parameters for the SQL Expression …
|
1 |
AddressID, AddressLine1, AddressLine2, City, StateProvinceID, PostalCode, Convert(geography,[SpatialLocation]) AS "SpatialLocation", rowguid, ModifiedDate |
Now we just need to put this all together in a way that is convenient! Note that you’ll need to add scripting logic to ensure that the schema is created first in the destination database.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
CREATE OR ALTER PROCEDURE #SelectJsonIntoTable (@database sysname, @JSONSchemaAndData NVARCHAR(MAX) ) AS DECLARE @ExplicitSchema NVARCHAR(MAX); DECLARE @columnlist NVARCHAR(4000); DECLARE @tableSpec sysname; IF @JSONSchemaAndData IS NULL OR @Database IS NULL RAISERROR('{"error":"must have the database and JSON details"}', 16, 1); SELECT @ExplicitSchema = String_Agg(quotename(property.[key])+' '+ CASE sqltype WHEN 'hierarchyid' THEN 'nvarchar(30)' WHEN 'geometry'THEN 'nvarchar(100)' WHEN 'geography' THEN 'nvarchar(100)' WHEN 'image' THEN 'Varbinary(max)' WHEN 'text' THEN 'Varchar(max)' WHEN 'ntext' THEN 'Nvarchar(max)' ELSE sqltype end+ ' ''$."'+property.[key]+'"''',',') FROM OpenJson(@JSONSchemaAndData,'strict $.schema.items.properties') property OUTER APPLY OpenJson(property.value) WITH (sqltype VARCHAR(20) 'strict $.sqltype'); SELECT @columnlist = String_Agg( CASE WHEN sqltype IN ( 'hierarchyid', 'geometry', 'geography') THEN 'Convert('+sqlType+','+QuoteName(property.[key])+') AS "'+property.[key]+'"' ELSE property.[key] end,', ') FROM OpenJson(@JSONSchemaAndData,'strict $.schema.items.properties') property OUTER APPLY OpenJson(property.value) WITH (sqltype VARCHAR(20) 'strict $.sqltype'); IF @ExplicitSchema IS NULL RAISERROR('Cannot locate the schema', 16, 1); SELECT @Tablespec=Json_Value(@JSONSchemaAndData,'strict $.schema.SQLtablename') DECLARE @command NVARCHAR(MAX) = ( SELECT ' use ' + @database + ' DROP TABLE IF EXISTS '+@TableSpec+' SELECT '+@columnlist+' into '+@TableSpec+' FROM OpenJson(@jsonData,''strict $.data'') WITH ( '+@explicitSchema+' ); ') EXECUTE sp_executesql @command, N'@jsonData nvarchar(max)', @jsonData = @JSONSchemaAndData; GO |
Inserting Data into a New Table
You can read in a file with the schema and data, importing into a new database, in this case called Demos:
|
1 2 3 4 |
DECLARE @JSONImport NVARCHAR(MAX) = (SELECT BulkColumn FROM OPENROWSET (BULK 'C:\data\RawData\AdventureWorks2016SchemaData\HumanResources-Employee.json', SINGLE_CLOB, CODEPAGE='65001') AS json ) EXEC #SelectJsonIntoTable @Database = 'Demos', @JSONSchemaAndData = @JSONImport; |
Inserting into an Existing Table
In order to insert into an existing table, we need to use the principles we’ve shown. We can adopt several approaches to this. I prefer to use PowerShell with SMO, iterating through the tables, but the whole process can be done in SQL if need be. Whichever approach you take, the essential procedure is this which takes a file with just the data and inserts it into an existing table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
CREATE OR ALTER PROCEDURE #SaveJsonValueToTable (@database sysname = NULL, @Schema sysname = NULL, @table sysname = NULL, @Tablespec sysname = NULL, @jsonData NVARCHAR(MAX) ) AS DECLARE @parameters NVARCHAR(MAX); DECLARE @hasIdentityColumn INT; DECLARE @columnlist NVARCHAR(4000); IF Coalesce(@table, @Tablespec) IS NULL OR Coalesce(@Schema, @Tablespec) IS NULL RAISERROR('{"error":"must have the table details"}', 16, 1); IF @table IS NULL SELECT @table = ParseName(@Tablespec, 1); IF @Schema IS NULL SELECT @Schema = ParseName(@Tablespec, 2); IF @database IS NULL SELECT @database = ParseName(@Tablespec, 3); IF @table IS NULL OR @Schema IS NULL OR @database IS NULL RAISERROR('{"error":"must have the table details"}', 16, 1); DECLARE @SelectStatement NVARCHAR(200) = (SELECT 'SELECT * FROM '+QuoteName(@database)+ '.'+ QuoteName(@Schema)+'.'+QuoteName(@table)) SELECT @parameters = String_Agg( QuoteName(name) + ' ' + CASE f.system_type_name WHEN 'hierarchyid' THEN 'nvarchar(30)' WHEN 'geometry' THEN 'nvarchar(100)' WHEN 'geography' THEN 'nvarchar(100)' WHEN 'image' THEN 'Varbinary(max)' WHEN 'text' THEN 'Varchar(max)' WHEN 'ntext' THEN 'Nvarchar(max)' ELSE f.system_type_name END + ' ''$."' + name + '"''', ', ' ), @hasIdentityColumn = Max(Convert(INT, is_identity_column)), @columnlist = String_Agg(name, ', ') FROM sys.dm_exec_describe_first_result_set(@SelectStatement, NULL, 1) AS f; IF @parameters IS NULL RAISERROR('cannot execute %s', 16, 1, @SelectStatement); DECLARE @command NVARCHAR(MAX) = ( SELECT ' use ' + @database + ' Delete from ' + QuoteName(@database)+ '.'+ QuoteName(@Schema)+'.'+QuoteName(@table) + CASE WHEN @hasIdentityColumn > 0 THEN ' SET IDENTITY_INSERT ' + QuoteName(@database)+ '.'+ QuoteName(@Schema)+'.'+QuoteName(@table) + ' ON ' ELSE '' END + ' INSERT INTO ' + QuoteName(@database)+ '.'+ QuoteName(@Schema)+'.'+QuoteName(@table) + ' (' + @columnlist + ') SELECT ' + @columnlist + ' FROM OpenJson(@jsonData) WITH ( ' + @parameters + ' ); ' + CASE WHEN @hasIdentityColumn > 0 THEN ' SET IDENTITY_INSERT ' + QuoteName(@database)+ '.'+ QuoteName(@Schema)+'.'+QuoteName(@table) + ' OFF ' ELSE '' END ); EXECUTE sp_executesql @command, N'@jsonData nvarchar(max)', @jsonData = @jsonData; GO |
We didn’t have to use the schema because we can get everything we need from the table. Note that if you opt to have a single JSON document that holds both the data and the schema, you need to alter the OpenJson(@jsonData) to OpenJson(@jsonData, 'strict $.data')in the procedure.
Conclusion
If you want to copy data between SQL Server databases, nothing matches the performance of native mode BCP. If, on the other hand, you are sharing data with a range of heterogeneous data stores, services or applications, then you need to use JSON, I reckon. Nowadays, it is best to pass the schema with the data and the rise of the JSON Schema standard means that now we can do it reliably with checks for data integrity. Sure, we can stick to CSV, and it is great for legacy systems if you can find a reliable way of doing it for SQL Server, but CSV has no standard schema yet, and the application developers understand JSON better.
I get a certain pleasure in being able to write data straight into a database without the preliminaries of puzzling out the schema that would be required from a CSV file. It is so fast that I weep for all those lost hours doing it the hard way.
I also look forward to being able to check and validate data before I allow it anywhere near the database. Somehow JSON schema has opened up new possibilities.
SourceCode
The source to this article and various blogs on the topic of importing, validating and exporting both JSON Schema and data in SQL Server is on github here.
More articles by Phil about JSON Schema and JSON
- Producing Data and Schemas in JSON array-of-array format.
- How to validate JSON Data before you import it into a database.
- Build and fill a database using JSON and SQL Change Automation
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments