





Code Visibility: Browsing through Flyway Migration Files
The technique I'll demonstrate relies on a SQL tokenizer that will break down a SQL script into "tokens", identifying keywords, comments, strings, and so on, so that we can then assign colors to each token based on its type.
I've provided some PowerShell scripts that use this tokenizer to allow you to maintain an HTML catalog file, essentially a list of your Flyway migration files, maybe under different categories, with links to each of the migration files in HTML, all neatly colorized, and with the same formatting you used in your IDE. Just to make it more useful, the catalog file will also let you know if a file has just been changed or been added. Of course, once you have this, you can then also make use of browser facilities such as text search.
These scripts are designed to work with Flyway but can be adapted for general use.
Delivering migration code as part of database documentation
With Flyway, you can add functionality at many points in any of the Flyway processes that are executed by a command, such as migrate, clean or info. After you do a migration, for example, you might want to make sure that your documentation is updated. In several previous articles, I've given examples of the sort of documentation that is useful, such as UML ER diagrams, documented build and migration scripts, or reports on the changes between migrations.
What I've not explained before is how you might want to pull together all these diagrams, scripts, and reports into a single set of database documentation, in HTML format. Once you have an ordered list of all your Flyway migrations as an index, with links to the actual HTML rendering of the source files, you have the start of an HTML-based IDE, and there are all sorts of reports that you can add to it such as the narrative of changes between versions. It is also good to have this collection of HTML files on a shareable, network-based website for the project, so you can see what is happening immediately.
You wouldn't need this while developing your code. After all, you have an IDE for working on code, or maybe your favourite code editor, but neither are as quick for scanning through a lot of code as a browser.
Converting SQL to HTML
We'll start with displaying migration files in HTML. It is so much easier to see them 'colorized' in the same way as in your IDE, Text editor, or an external website that uses JavaScript.
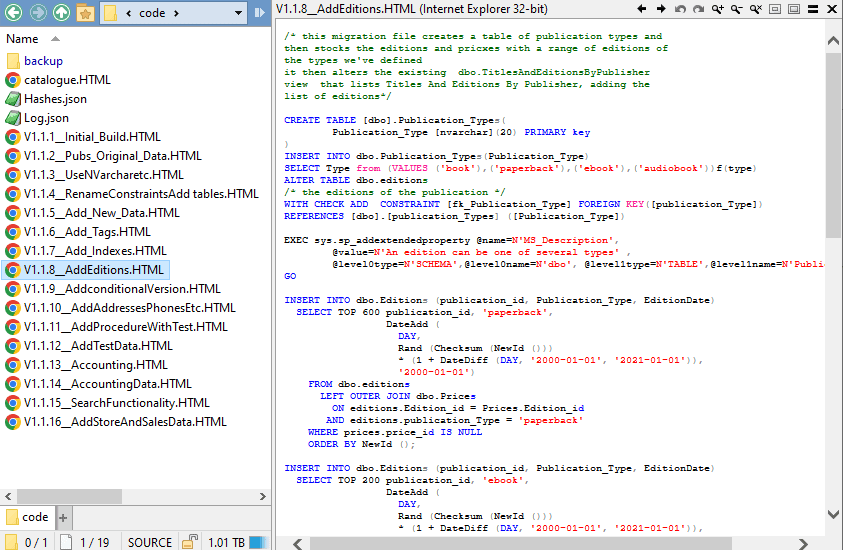
It isn't exactly trivial to convert a SQL code file into HTML, while maintaining the highlighting with which you are familiar. One option is to install a JavaScript utility in your website, to do this for you. However, all you need is a reasonably good tokenizer and then once you have the HTML itself colorized, you can use any viewing tool, such as Directory Opus, to render the HTML content. It also makes it easy to convert to PDF, a Word document, Markdown, and a host of other formats.
The process of rendering SQL actually isn't that hard. After all, if JavaScript can do it, it would seem silly if PowerShell couldn't do it. The biggest problem is to get enough performance for a scripting language like PowerShell to plough through a whole mass of migration files. With a Flyway migration approach, it is probably less of a chore because the migration files don't change or at least they shouldn't. Flyway migrations are generally immutable once they've been used, otherwise it is very easy to sow 'version-confusion'.
Nevertheless, to implement such a system, while avoiding any unnecessary generation of HTML, you need an approach that only does the conversion for a migration file that is new or has been altered. It is also worth limiting the amount of code that needs to be colorized, in the files that you include. Large migration files are generally just vast streams of insert statements, or data changes, and you wouldn't want to read them. If you need to search them, you can use a text editor that is optimized for the task.
Maintaining a HMTL catalog of migration files
To have a system that maintains an 'index list' of files, and documents whether a file is new, altered or unchanged, could well be more useful to a team leader than even the prettifying of code, so I added it to the menu.

Click the link and you'll view the file, of course!
If you also write this out to a log, adding the modification date of a changed file, or the creation date of a new file and you run the routine after every migration, you have the basis of some very useful information that will tell you if a file has been added or changed and when it happened. If a migration hasn't been used, then changes are fine, but if it is likely to upset Flyway next time it is used, then it gives you time to remedy things.
Recording a Flyway project as HTML
I've added to the Flyway Teamwork Framework a PowerShell function called Record-FlywayProjectAsHTML, the purpose of which is to record SQL migration files from a Flyway project as colorized HTML files, in a specified directory, together with an index that links to these files. This allows the team to maintain an easily-browsed HTML form of the current migration code of the current project.
The function goes through each SQL migration file in the specified "flyway locations". For each file, it checks the file type (versioned, repeatable, baseline, undo), if it is newly added (or deleted) or whether the content of the file has changed since the last run. It does this by saving the hash value for each file (in hashes.json) and comparing its current value with the value from the previous run.
If the file is new or its content has changed, it outputs a message in a log file to notify the user and then constructs the HTML for the file, by calling the Convert-SQLtoHTML cmdlet. This is a generic cmdlet that can be used with any SQL string. As its name suggests, it will parse most dialects of SQL and turn it into HTML. You can then, of course, turn it from HTML into many other forms of document.
It saves the generated HTML files within the \Versions\Current\Code sub-folder and updates the index list (catalogue.html), as required. It creates a log of the changes (Log.json). It also maintains a backup directory containing the version of the file seen last time you ran the code, to allow you to make a detailed comparison with a DIFF utility.
The reason for making Record-FlywayProjectAsHTML part of the framework is that it needs a good list of the locations so it can find all the migration files. Also, it needs the location of your 'Versions' directory to find and maintain the 'Current' directory in the project that tells you the current state of the project. Running it within the framework will also make it easy to run Record-FlywayProjectAsHTML in a callback, after every migration run, if you are using Flyway Teams. For a flourish, it allows you to add the name, branch and description of the project.
You can try it out using one of my Flyway Teamwork projects on GitHub. The simplest way of running it would be like this. It will run in the main script or in a callback:
|
1
2
3
4
|
cd '<MyPathTo…>\GitHub\FlywayTeamwork\Pubs\Branches\develop'
. '.\preliminary.ps1' # we are using the framework just to get a comprehensive list of file locations
Record-FlywayProjectAsHTML $DBDetails
Start-Process -FilePath "$($DBDetails.reportlocation)\Current\code\catalogue.HTML"
|
This will generate the catalogue.html, as shown earlier, and clicking the link for any of the Flyway migration files will take you to the HTML version, colorized and formatted nicely.
How it works: the SQL tokenizer
To convert a SQL script into a colorized HTML document, we need a tokenizer that will break down the SQL script into "tokens" (keywords, comments, strings, and so on) and then assign colors to each token based on its type.
For this we use Tokenize_SQLString cmdlet, which is called by the Convert-SQLtoHTML cmdlet. If you feed it a SQL string, it will provide a stream of token objects that tell you what type of token each one is, what the value of the token is (e.g., FROM) and where it is within the file. Working backwards from the last token, it is then possible to insert the appropriate HTML that specifies the colour of the string that represents the token such as SELECT, FROM, and so on, depending on the nature of the token. A block-comment token will be one colour, whereas a string token will be another. The tokenizer will tell you the standard functions such as COUNT, SUM, AVG and so on, and the various other types of keywords.
Armed with all these different types of tokens, it is possible to colorize the code to whatever standard convention that you choose. It might seem strange to work backwards from the end of a string to insert the markup, but that ensures that the information about the location of each token within the string remains correct until the markup is inserted.
Because this process is relatively slow, in a script language that supports pipelines it is necessary to determine whether a file has changed or is new, before regenerating or generating it. As a by-product of this, we pass the information onto the user.
Conclusion
One of the frustrating chores for any database developer is that of accessing the source code of a 'table-source' such as a table, view or function, every time you are trying to understand or write queries. That is especially true of any migration-first approach. By this, I mean that, if you are using a migration-first approach, you sometimes have to leaf through a lot of migration files to find where a change was made. If you are taking files from several locations, it can become very tiresome. To work quickly, you need either an excellent memory or, for the rest of us, a slick and rapid way of finding the information we need.
Flyway uses, as its 'source of truth', a series of migrations. This means either having a directory of generated build scripts for your version or developing a quick way of finding and viewing the DDL script of the migrations. Having a local website of colorized versions of the source code is a start. At least one can quickly flick through migrations. However, there is some interesting potential. Because we do this by tokenizing, it becomes possible to use the tokenized version to develop a 'search' system that, for example, finds all the migrations where a particular table-source was modified. But that's another story…
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Database Branching and Merging without the Tears
Armed with a schema comparison engine and an object-level directory of the source for every recent version of the database, you'll be able to remove a lot of the uncertainty around merging database changes back into development.
Article
Running Unit and Integration Tests during Flyway Migrations
In this article I'll give a practical example of developing a database, with Flyway, in such a way that it is automatically tested with whatever unit tests and integration tests you specify whenever you migrate the branch you're working on to the next version. If a test fails, you can work out why, undo the migration and then try again.
Article
Flyway Branching Walkthrough
We'll step through the process of using Flyway Teams to support database branching and merging, where the team split the development effort into isolated, task-based branches, and each branch has its own development database.
Article
Re-baselining a Database using Flyway Desktop
Over time, Flyway projects can accumulate a lot of migration scripts, with many database objects being created, altered, and dropped across many files. Tonie Huizer explains why you might want to create a new baseline migration file to create the latest version of a Flyway-managed database in a single leap, and how to persuade Flyway Desktop to do it.
Article
Flyway Teams and the Problem of Database Variants
The 'ShouldExecute' script configuration option in Flyway Teams simplifies 'conditional execution' of SQL migration files. This makes it easier to support multiple application versions from the same Flyway project, to deal with different cultural or legislative requirements. It also helps developers handle environmental differences between development, test and staging, such as the need to support multiple versions or releases of the RDBMS.
Article
Reporting on Changes Made by Flyway Migration Scripts
Phil Factor demonstrates some PowerShell tasks that will produce a high-level overview, or narrative, of the main differences in the metadata between two versions of a database, during Flyway Teams migrations.
Loading comments...