





Better Database Development: The Role of Test Data Management
This article is part of a series on managing test data in a Flyway development:
- Better Database Development: The Role of Test Data Management
- A Test Data Management Strategy for Database Migrations
- Dealing with Database Data and Metadata in Flyway Developments
- Adding Test Data to Databases During Flyway Migrations
- Getting Data In and Out of SQL Server Flyway Builds
- Bulk Loading of Data via a PowerShell Script in Flyway
- Managing Test Datasets for a Database: What's Required?
- Managing Datasets for Database Development Work using Flyway
Also relevant are the series of related articles on Database testing with Flyway.
Despite the drive toward more frequent database deployments, many teams still do not have any particular test data management (TDM) strategy in place. As developers, we are left to do the best we can, often developing and testing with a single set of test data that is far from representative of the real thing.
The result, unfortunately, is lower quality software, more bugs reaching the production system, and frequent database deployment failures. This includes failure to deploy the new database version, as well as deployments that 'succeed' but subsequently cause problems that affect the availability, performance, or security of the associated business applications. Often, even production hotfixes, designed to fix a previous deployment problem, cause further unanticipated issues. Again, this is usually because the hotfix was rushed out without proper testing.
This article will start by giving an overview of a test data management strategy that will allow you to address these issues. It will walk you through the steps to achieve this and explain the measurable benefits.
Overview of the TDM strategy
The following diagram sets out the basic characteristics of our test data management strategy. The workflow looks like this:
- Choose dataset – choose the required data set, appropriate for the sort of tests that need to be run.
- Provision – use the chosen test data to provision 'dedicated' databases, one per developer (or per branch of development).
- Develop or Test – each developer develops and tests code independently, before merging their work into the main development branch.
- Reset environment – developers should be able to reset databases, on demand, so that tests can be run consistently and repeatedly.
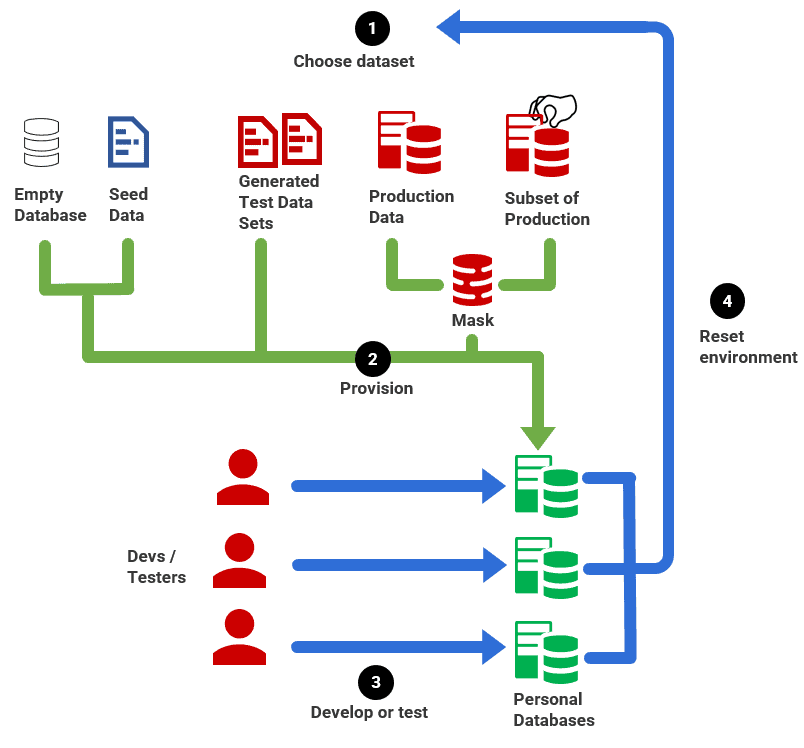
Step-by-step to TDM
Of course, we do not need to achieve this full TDM strategy in a single leap. We can get to the benefits in smaller steps…
1. Moving to dedicated development databases
In my experience, the developers' ability to work creatively and test their work properly is severely restricted by the requirement to use a single, shared development database. We've all encountered cases where that shared database environment was set up by a DBA some time ago, no-one is quite sure when, from a production backup. It hasn't been refreshed since and while the team have a migration workflow in place to manage changes to the structure, there is no strategy for maintaining the data.
As a result, the data gradually becomes stale, lower quality, and unrepresentative of the current state of the production system. If a developer runs tests that mess up the data, the whole team is disrupted until the DBA can provide a 'refresh'. This fear of disrupting the work of others means that testing is often sporadic or delayed to a later stage in the project and so bugs are caught later when they are harder to fix and cause delays.
All this is why I suggest that the first improvement that needs to be made is to allow each developer to use a personal development database, instance, server or container. Sometimes this is tricky to achieve, because the 'single shared database' requirement is usually the result of a valid logistical or security concern that we first need to overcome.
Alleviating security issues
If the production data contains personal or sensitive information, it can usually be made available only to restricted personnel, in an environment with the same security as production. If your TDM strategy includes the requirement to work with copies of production data, then it will need to provide an effective and automated way to first remove any sensitive or personal data, or 'mask' and obfuscate it to the point where it could never identify any individual.
The alternative would be for your TDM process to incorporate a way to generate "fake but realistic" data for development work.
Dealing with very large databases
Often, maintaining more than one or two development copies of a very large production database takes too much time and management and requires too much disk storage space.
If so, then your TDM strategy will need to provide a way to reduce the size of the distributed production data sets, such as by using data subsets, or by allowing a lightweight way to create and rapidly reset copies of the full production data set, such as by using database clones and containers. Another alternative would be the use of smaller generated data sets for development and testing.
TDM for complex data systems
Similarly, for complex Enterprise applications supported by many interdependent databases; supplying individual, dedicated copies of this system is often impractical.
In these situations, it can be a challenge to create and maintain generated test data for interlinked databases, or even just to provide and seed data that needs to be in sync between the databases. Use of technology such as 'containerized clones' as part of a TDM strategy helps a lot here. It allows teams to capture an image of an entire instance, consisting of any number or interconnected databases. We can then distribute a lightweight clone of that image to each developer, as a data container.
2. Provisioning development and test environments
The dedicated databases must be not only easy to create but also, just as importantly, easy to remove or reset. A test run generally requires a set up that creates a copy of the database at the right version, including the data, runs the test, assesses the result, and then tears down the test set up, resetting the database to its original state, ready for the next test. Since tests don't always pass the first time, this can mean creating and resetting a database many times, over and again.
If your TDM strategy is implemented using clones and containers then these have the advantage of an almost 'push button' reset process. Simply run the test, then an automated, scripted method should reset the data container back to its initial state.
An alternative is to use a script method alongside a database migration tool like Flyway. The scripted process will create an empty database at the right version, load the required dataset, run the test, teardown, repeat. A Flyway baseline migration script will create the database at the required version and then you can use Flyway callback to load the required dataset automatically. See, for example, Running Unit and Integration Tests during Flyway Migrations.
Of course, these scripts don't have to be run by the user; pipelines for automated provisioning and testing are the solution here!
3. Creating and maintaining the right test data sets
With your own database environment in place, it's time to get the data right, or rather to get the right data! What data and how much is really needed? Initially, your TDM strategy may only support a single method of providing dev and test databases, complete with data. You can then start to build out the strategy, adding support for all the different data sets that developers need for the different types of tests. The data sets should be easy to create and maintain, and switching between data sets should be simple.
The data you need depends on the task. If the tests require data that is highly representative of the real production data then using a copy of the production data might be the best choice. However, this assumes the data is first masked and obfuscated to comply with GDPR and any other data protection regulations for your industry. Often only a subset of the full production dataset is required, in which case you need a subsetting tool that will extract a fraction of the full production data, leaving all the structure and relations of the database in-tact.
For many types of tests that a developer will wish to run, such as unit or integration tests, use of production data is unnecessary, and also won't necessarily contain all the different types of data required to run the tests (such as edge case data or invalid data). These tests are sometimes best served with a process that separates the management of schema and data. It will, for example, use a build script to create an empty database at the right version, complete with any required seed data. There might be cases where an empty database is used for tests, for example to test the first run of your software from the perspective of a new customer. More often, of course, you'll then need the script to load the required test dataset.
The datasets might be created in a number of ways:
- Curated by the developers – such as when producing data sets to test that valid but 'edge case' data is handled correctly or that invalid data is excluded.
- Created using a data generation tool – to generate larger volumes of "realistic-looking" but fake data that conforms as far as possible to the distribution and nature of the live data.
- Supplied by the business – for example integration tests often start from a standard dataset, run the process then check the result against what the business supplied as the "correct result"
- Sniffed from production – with a tool like Extended Events, valid test data can be generated from use cases that are executed in production.
One challenge will be in maintaining all these data sets in response to changes to the database structure during development, and understanding which versions of the data are valid for which versions of the database. Whoever creates or alters one or more of the tables in a way that affects existing data must also do the work of altering the datasets.
Whichever way the test data sets are supplied, the provisioning of the right dataset (empty, generated, subset or everything) should be a highly automated self-service process. All the developer needs to do is specify what test data they want. This can be a mandatory step during the refinement process of new work in a sprint, or an ad-hoc choice made during the development or test process.
Once an automated system for serving test data is in place, you'll start to see measurable benefits.
Measurable benefits of a TDM strategy
A lot of the benefits of a TDM strategy come from the ability to move toward a test-driven development system, where developers run extensive database tests in their own dedicated databases (such as when working on a feature branch), before even committing the code to the main branch of development. We catch far more bugs long before they ever reach production.
Other benefits include:
- Wider test coverage –ability to catch edge case problems, run full process checks as well as unit tests, and so on
- Improved testing accuracy with realistic test data – I still remember the example of a software vendor delivering an upgrade of having only tested against IDs below 10. The production system had more than ten thousand IDs. The result? Down time in production, that could have been prevented.
- Reproduce difficult production bugs, develop better hotfixes – with a TDM strategy that offers lightweight support for producing production data sets, safely.
- Protecting data integrity/security – the ability to produce data sets that can be used to test that invalid data is prevented from entering the database, or that the database is safe from injection attacks.
With proper test data management in place the quality of your work (product) will increase. The software is now tested in a more structured way, repeatable and suitable for the scenario. As a result, you should start to measure positive changes in many of the so-called DORA metrics, and other related productivity measures.
For example, you should expect to see a measurable decrease in the number of bugs detected in Staging or Production, and in the overall change failure rate. There will also be a reduction in the time spent testing, and in the lead time for changes. This will increase your deployment frequency and time to market for new software.
Summary
A well-planned TDM strategy will support a test-driven approach to database development, where developers extensively test code in their dedicated databases before integration. It will make it easy for the team to load, switch between and maintain all the different types of test data they need for their testing. This leads to broader test coverage, improved testing accuracy with realistic data, better bug detection, and therefore to more regular and resilient deployments of higher quality database changes.
What to Read Next
If you're interested in how to implement a TDM strategy as part of a database migration system, try Test Data Management for Database Migrations, along with related articles in the Test Data Management section of this website. Some of the advantages of using 'disposable clones' as a part of the TDM implementation are explained in Self-service, disposable databases for development and testing.
The following articles provide useful background to the topics covered in this article:
- What is Test Data Management?
- Test Data Management (TDM): A Complete View
- DORA metrics - The predictive link between DevOps practice and business outcomes
- Managing Test Data for Database Development
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
 Redgate Test Data Manager
Redgate Test Data ManagerYou may also like

Article
Redgate Test Data Manager Product Updates - March 2026
Redgate Test Data Manager's latest release adds Entra ID authentication, multi-target anonymization, and direct treatment code editing with workflow improvements to make pipeline management faster and more flexible.

Article
Test Data Management and SOC 2 Compliance
Using live data outside production is one of the fastest ways to create compliance risk, because it quickly becomes harder to control who can access it, how it is handled, and how long it is kept. A Test Data Management (TDM) approach provides exactly the kind of controls SOC 2 auditors look for in this situation: an automated, traceable end-to-end process for protecting, provisioning, and removing customer data so it can be used safely in non-production environments.

Article
Detecting Data Masking Gaps in a CI Pipeline
If you use Redgate Test Data Manager to anonymize production-derived test data and Flyway to manage schema changes, you need a way to keep masking rules aligned with schema evolution. The most reliable approach is to validate masking coverage in CI: run a masking drift check as part of the Flyway pipeline and fail the build if schema changes introduce sensitive columns that aren’t yet covered by the masking configuration. This article shows how the check works, what it validates, and where it can fit into a typical delivery workflow.
Article
Redgate Test Data Manager Product Updates - November 2025
Redgate Test Data Manager’s November’s release brings advanced table configuration for large databases and the ability to save connection strings. Two features that make setting up subsets and managing database connections smoother, easier, and faster. Advanced Table Configuration – simplifying subsetting for large databases Configure subsets on databases with thousands of tables using faceted search, filtering, and bulk actions. Filter tables instantly by schema, name, or size, then bulk-exclude entire groups – audit tables, system tables, or any problematic tables – in one action. This evolution of our subsetting configuration means teams working with a large number of tables can
Article
Test Data Management and DORA Compliance in Financial Organizations
DORA requires financial institutions to run tests that prove their systems can withstand operational disruption, without exposing sensitive data. This article explains how Test Data Management (TDM) provides the realistic but safe data needed for resilience testing and the governance controls required under DORA’s ICT risk management rules.
Article
Redgate Test Data Manager Product Updates - October 2025
Redgate Test Data Manager’s October release focuses on improving core security features with AI, and stability refinements based on your feedback. These updates strengthen core functionality, making sensitive data classification more comprehensive, and the product even simpler to use. AI-Powered Data Classification – intelligent sensitive data detection Automatically identify sensitive data with machine learning models that scan your database locally to get more in-depth and comprehensive sensitive data identification for masking. No data leaves your environment – classification runs entirely within your infrastructure. This capability is available to a select group of early access customers; contact us to enable this
Loading comments...