Handling Tricky Data Migrations during State-based Database Deployments
This article demonstrates how to use a 'state' approach to database source control, when the nature of the database changes cause you to hit difficulties with migrating existing data. These difficulties happen when the differences are such that it is impossible for any automated script to make the changes whilst preserving existing data.
In the classic state-based approach to database development, the source control directory contains, in one or more files, the SQL DDL statements that can build the database, if they are executed in the correct order. These DDL files can be created in several ways, but the current version of the source code must contain everything required to build the database.
Frequently, you don’t want to do a build, but instead you need to update all the existing development databases to reflect the current build version, or the relevant development branch of it. To do this we need a software ‘database synchronization’ tool such as Redgate SQL Compare. Such a tool works by creating a ‘model’ object of the database from the source and comparing it to the target database. From the resulting map of all the differences in the metadata between the source code and the target database, the tool will generate an automated script that will, if executed, alter the target so that its metadata conforms with the source.
This saves a lot of time because even minor changes can take work in SQL. You’ll know the dreaded message in the SSMS table-design tool.
‘Saving changes is not permitted. The changes you have made require the following tables to be dropped and re-created. You have either made changes to a table that can’t be re-created or enabled the option Prevent saving changes that require the table to be recreated.’
There are a host of changes that a good synchronization tool can make without having to recreate the table, such as explicit changes to datatypes, or applying the default values to existing NULL values when you make a column NOT NULL. It can generally do it under the covers while preserving the data. If you do this by hand, you soon realize the time and tedious effort that a good sync tool can save.
Where problems lie
In my experience, things rarely go wrong with a database build or update done using synchronization. When they do, it is generally sorted out by tweaking the synchronization options. The difficulties come if the target contains data and there is more than one possible way of migrating the existing data from an old table design to a new one. What goes where?
The extensive renaming of columns can sometimes cause any sync tool to shrug and give up when there is no single obvious way of working out what happened. A table split is renowned for causing problems to a deployment that updates an existing database, because it is difficult for the tool to divine where the data will all move. It won’t necessarily cause an error unless there is a danger that you’ll lose data in the process. Otherwise, it just won’t get done. Similarly, a conversion of the data from one datatype to another that isn’t implicit, or some other large-scale re-engineering of the tables can also cause grief.
At some point, the changes are such that you can no longer update the target database purely by automatic synchronization or by using table ALTER statements. In fact, automatic synchronization that preserves the existing data is never fully guaranteed, and the less similar the source and target, the less successful it is likely to be. Boyce, Codd and Date would surely shake their heads sadly at the idea.
Instead, you need to ‘flag’ those schema changes that might affect existing data in unpredictable ways, and for those cases provide the automated build system with some help, in the form of a manually written script to deal with the complexities of determining where and how the existing data should go in the new arrangement. These scripts will need to be executed before running the synchronization. You can include in your source an entire narrative of changes to describe how to migrate the data, but if you then simply let the synchronization tool compare that source to the target and generate a script, any extra executable code in the source that isn’t part of an object definition won’t be included.
Solving the problem
Let’s take an example. We’ve created a version of pubs with a respectable amount of data. Full instructions on doing so are here: Generating Data for Database Tests.
We now decide to do some re-engineering. We’ll start by converting the archaic datatypes into types that reflect current best practice. We’ll also try to remove some nullable columns. However, we then spot that at some point, an unnamed and ill-advised developer decided to introduce a rudimentary ‘tag’ system, by adding a comma-delimited list of publication types as an extra column, TypeList, in the Titles table. The full details are here: Database Migration Scripts: Getting from place A to place B.
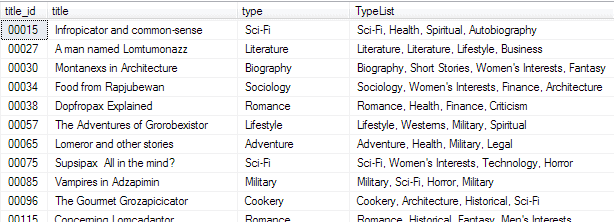
Searches on this column are taking far too long and it is doomed, so we decide to split out the tags into a many-to-many arrangement as shown below. We then stock the two new tables. TagTitle and TagName, appropriately with the data in the TypeList before tidying up by removing the TypeList column.
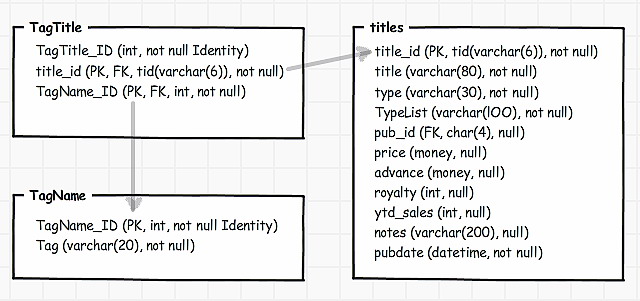
We need to write a migration script to create the two new tables and migrate the data into them from the TypeList column. A subsequent synchronization will apply all other required changes (and can now safely drop the TypeList column, which no longer exists in the source).
The migration script will need to use guard clauses to ensure that it can be run more than once without causing damage. Before making any change, each guard clause first checks to make sure it is necessary and does nothing otherwise. This technique, where we don’t assume anything about the state of the target and instead check with guard clauses before executing any DDL statement, is explained in Idempotent DDL Scripts That Always Achieve The Same Result – Making Changes Only Once: Stairway to Exploring Database Metadata Level. It is necessary because we must assume that the script will somehow get executed in all sorts of inappropriate times and places.
Here is our code. The XML is used purely to shred the TypeList into a relational table. The String_Split() function now does the same thing and makes the code a lot less impressive but I wanted to keep this so everyone could play along.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
/* make sure that we are on the right database */ IF NOT EXISTS (SELECT * FROM sys.types WHERE name LIKE 'tid') OR Object_Id('Titles') IS NULL BEGIN RAISERROR('Error. this migration script needs a version of the PUBS Database', 16, 1); END; /* we check to see whether the TagName table is already created, meaning this script is being accidentally re-run. No bother, we simply do nothing rather than scream and trigger an error */ IF Object_Id('TagName') IS NULL BEGIN PRINT 'creating the tagname table' CREATE TABLE TagName ( TagName_ID INT IDENTITY(1, 1) PRIMARY KEY, Tag VARCHAR(20) NOT NULL UNIQUE); END ELSE --do nothing besides sending a message PRINT 'The TagName table already exists. Nothing to do.' /* now we stock the TagName table, if it hasn't already been stocked. It could be that the process crashed at this stage during a previous attempt. */ IF NOT EXISTS (SELECT * FROM TagName) --if there is nothing in the table /* ...and we insert into it all the tags from the TypeList column (remembering to take out any leading spaces) */ INSERT INTO TagName (Tag) SELECT DISTINCT LTrim(x.y.value('.', 'Varchar(80)')) AS Tag FROM ( SELECT Title_ID, Convert( XML, '<list><i>' + Replace(TypeList, ',', '</i><i>') + '</i></list>' ) AS XMLkeywords FROM dbo.titles ) AS g CROSS APPLY XMLkeywords.nodes('/list/i/text()') AS x(y); ELSE PRINT 'TagName table already filled. To replace the data, truncate it first' /* Now we create the TagTitle table that provides the many-to-many relationship between the Title table and the Tag table. */ IF Object_Id('TagTitle') IS NULL BEGIN PRINT 'creating the tagTitle table and index' CREATE TABLE TagTitle ( TagTitle_ID INT IDENTITY(1, 1), title_id dbo.tid NOT NULL REFERENCES titles (Title_ID), TagName_ID INT NOT NULL REFERENCES TagName (TagName_ID) CONSTRAINT PK_TagNameTitle PRIMARY KEY CLUSTERED (title_id ASC,TagName_ID) ON [PRIMARY] ); CREATE NONCLUSTERED INDEX idxTagName_ID ON TagTitle (TagName_ID) INCLUDE (TagTitle_ID, title_id); END; ELSE PRINT 'TagTitle table is created already' /* ...and we now fill this with the tags for each title. Firstly we check to see if the data is already in the table ... */ IF NOT EXISTS (SELECT * FROM TagTitle) /* only do the insertion if it hasn't already been done.*/ INSERT INTO TagTitle (title_id, TagName_ID) SELECT DISTINCT title_id, TagName_ID FROM ( SELECT title_id, Convert(XML , '<list><i>' + Replace(TypeList, ',', '</i><i>') + '</i></list>' ) AS XMLkeywords FROM dbo.titles ) AS g CROSS APPLY XMLkeywords.nodes('/list/i/text()') AS x(y) INNER JOIN TagName ON TagName.Tag = LTrim(x.y.value('.', 'Varchar(80)')); ELSE PRINT 'TagTitle table already filled. To replace the data, truncate it first' /* all done. The original TypeList table will be removed in the synchronization */ |
Automating synchronization-based deployments that require data migration
We need to incorporate this sort of migration script into an automated deployment process, which uses synchronization. SQL Compare always does deployment using synchronization, and SQL Change Automation does too in cases such as this, where the source is simply a set of object-level build scripts (or even a single build script).
Some migration scripts can be run after the synchronization, if the synchronization runs error-free. This is easy to manage because we simply place the migration script in a folder within the scripts directory called \Custom Scripts\Post-Deployment. SQL Compare or SCA will simply attach it to the end of the synchronization script automatically.
However, in this case we need the migration script to take care of the awkward preliminaries before the synchronization process runs. However, we can’t try running it as a pre-deployment script either, by putting it in scripts directory called \Custom Scripts\Pre-Deployment. If we do this, Compare or SCA will still run the synchronization first, and then simply append the migration script to the start of it.
Instead, we need to execute it on the target, as a separate step, before running the synchronization. This prepares the target so that the subsequent comparison and synchronization will work without a hitch. It doesn’t subvert the work of the synchronization at all.
If your guard clauses work well, it can stay there over subsequent deployments since nothing will be executed. It would cause havoc if you wanted to resurrect a previous build so you might need a check on version number. I usually specify in the filename of the migration script the versions for which it is appropriate.
…With SQL Compare
If you are using SQL Compare, all you then need to do is:
- execute the migration script on the target
- Do a SQL Compare synchronization between the source code files as the source and the target, as usual.
…With SQL Change Automation
Here, you’ll want the whole process scripted. Again, don’t try using the migration script as a pre- or post-deployment script, as it won’t work, and don’t put it in your scripts directory either, because SCA will then attempt to include it in the build, with unpleasant results. Storing it in a parallel directory will be fine.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
cls $ReleaseArtifact = @{ 'target' = 'Server=MyServer;Database=Pubs;User Id=MyID;Password=MyPassword;Persist Security Info=False'; 'source' = 'MyScriptsDirectory; 'Migrations' = 'MyPathToScripts\AddTags.sql' } | foreach { $csb = New-Object System.Data.Common.DbConnectionStringBuilder $csb.set_ConnectionString($_.target) Write-Output "executing the migration script on $($csb.'Server').$($csb.'Database') " if ($csb.'user id' -ne '') { sqlcmd -S $csb.'Server' -d $csb.'Database' -j -P $csb.'Password' -U $csb.'User ID' ` -i "$($_.migrations)" } else { sqlcmd -S $csb.'Server' -d $csb.'Database' -j -E -i "$($_.PreliminaryCheck)" } Write-Output "Now synchronising the target ( $($csb.'Server').$($csb.'Database')) with the source " <# first we build an empty database. #> $iReleaseArtifact = new-DatabaseReleaseArtifact ` -Source $_.source ` -Target $_.target ` -AbortOnWarningLevel None -SQLCompareOptions IgnoreSystemNamedConstraintNames Use-DatabaseReleaseArtifact -InputObject $iReleaseArtifact -DeployTo $_.target $ReleaseArtifacts = $iReleaseArtifact } |
Doing a rollback
What if something goes wrong and we need to roll back to the original database version, in other words with the original version (where the TypeList column contains a list of tags) as the source. We’ll need to run a ‘reverse migration’ to safely migrate the data back into TypeList and we must run it before any synchronization because it relies on the data in the tables that the synchronization will remove.
In restoring the list of types or tags in the Titles table, we will have duplicates removed and the tags in alphabetic order, so the data can’t be said to have been exactly restored (the data generation wasn’t perfect in that it had duplicates and the tags weren’t in alphabetic order).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
/* this is a script for reversing out of a migration change where we re-engineer a list of types of a publication. */ /* make sure that we are on the right database */ IF NOT EXISTS (SELECT * FROM sys.types WHERE name LIKE 'tid') OR Object_Id('Titles') IS NULL BEGIN RAISERROR('Error. this migration script needs a version of the PUBS Database', 16, 1); END; IF NOT EXISTS -- only run if the column does not exist ( SELECT * FROM sys.columns WHERE name LIKE 'typelist' AND object_id = Object_Id('dbo.titles') ) BEGIN PRINT 'Adding TypeList column as a NULLable column and adding data' ALTER TABLE titles ADD TypeList varchar(100) NULL end ELSE SET NOexec On GO --now we fill the typelist from the tagTitle and Tag columns --this will only be executed if we've just created the column -- because otherwise we've set NOEXEC on for the spid. UPDATE titles SET typelist = Coalesce(Stuff(( SELECT ', '+tag FROM tagname INNER JOIN Tagtitle ON TagTitle.TagName_ID = TagName.TagName_ID WHERE Titles.title_id = TagTitle.title_id ORDER BY tag FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'Nvarchar(1000)'),1,2,''),'') IF @@RowCount >= 10000 --we assume every title has at least one type category BEGIN ALTER TABLE Titles ALTER COLUMN TypeList VARCHAR(100) NOT NULL; IF Object_Id('TagTitle') IS NOT NULL DROP TABLE TagTitle; --only executed if we've just created the Typelist column IF Object_Id('TagName') IS not NULL DROP TABLE TagName; --only executed if we've just created the Typelist column END; SET NOEXEC OFF; |
I would keep this rollback script in source control but well away from the source code. I assume you are using a database versioning mechanism. If you are using SCA, there will be a version number stored in the extended property of the database with the name ‘DeploymentManager Deployed Package Version’. It stores the PackageVersion that you assign to the source, when you use it with the New-DatabaseBuildArtifact cmdlet, to create the build artefact.
|
1 2 3 4 |
SELECT Convert(VARCHAR(20), value) AS Version FROM sys.extended_properties AS EP WHERE class_desc = 'DATABASE' AND name LIKE 'DeploymentManager Deployed Package Version'; |
In PowerShell, you can implement the logic ‘Execute this particular reverse migration before the synchronization, only when the source version is less than when the table redesign happened, and the target is at the same or higher version.‘ As you may well have a different way of managing versioning, I won’t spell out the code.
Conclusion
The problem of data migration only becomes apparent when database deployments need to preserve the existing data in the target databases. If you have a good synchronization tool that can cope with all the common problems that have only a single possible data migration path, you will rarely need an extra migration script. If you do, then it is crucially important to develop and test it while the DDL code changes that cause the problem are being made and checked in.
The migration of data is the most important aspect to releasing a new version of an existing database to production. Therefore, to avoid unpleasant surprises at release time, the development team needs to get into practice, by doing automated synchronization from source regularly to a target with plenty of data in it, to iron out any such problems as early on as possible.
You might think that a complex logic would be required to know when to apply the migration script, but in fact a script can follow the logic easily if the version of the source and target database is known. The migration is only required when the source database is at the same or higher version than the table redesign, and the target isn’t. The ‘reverse migration’, for a safe rollback, is required only when the source version is less than when the table redesign happened, and the target is at the same or higher version.
When the deployment is scripted, the logic is easy to insert. Because the migration script can be re-run without effect, one can afford to be relaxed about re-running it unnecessarily, but one wouldn’t want to execute the wrong one!
Tools in this post
You may also like
-

Article
Recreating Databases from Scratch with SQL Change Automation
Phil Factor starts with the basics how to rebuild a set of development database from scratch, using SQL Change Automation, and then demonstrates how to check for any active sessions before rebuilding, import test data using BCP, and secure passwords if connecting to the target with SQL Server credentials.
-
Article
Using database replication with automated deployments
For the SQL Change Automation team, it’s important that we take time out from development, occasionally, to explore some of the issues our customers face when automating database deployment. Following on from previous posts about cross-database and cross-server dependencies and production database drift, this article shares some of our thoughts about how to deal with database replication.
-

Article
How to examine differences with SQL Compare Summary View and SQL View
Jamie Wallis introduces the new Summary View, which is a tab that sits alongside SQL View and provides a more concise breakdown of the differences between two objects.
-
Article
Exploring the SQL Compare Options
You need to compare database schema objects in two SQL Server databases, and then automatically generate a SQL deployment script that when executed will remove these differences, either making the schema of the target database match the source, or vice-versa. It sounds easy, but the problems lie in the details of the schema comparison options.
-
Article
How to build multiple database versions from the same source: pre-deploy migration scripts
The final part of Alex Yates's three-part series tackles the complicated issue of automating deployments when the same table might have a different structure, in different production versions of the database.





