
We’ll be looking at a typical database ‘migration’ script which uses an unusual technique to migrate existing ‘de-normalised’ data into a more correct form.
So, the book-distribution business that uses the PUBS database has gradually grown organically, and has slipped into ‘de-normalisation’ habits. What’s this? A new column with a list of tags or ‘types’ assigned to books. Because books aren’t really in just one category, someone has ‘cured’ the mismatch between the database and the business requirements. This is fine, but it is now proving difficult for their new website that allows searches by tags. Any request for history book really has to look in the entire list of associated tags rather than the ‘Type’ field that only keeps the primary tag.
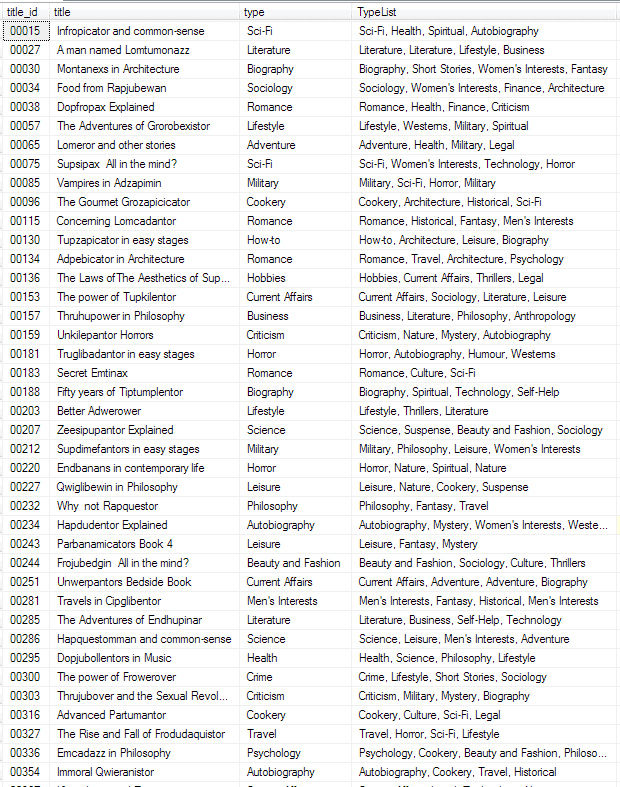
We have other problems. The TypleList column has duplicates in there which will be affecting the reporting, and there is the danger of mis-spellings getting there.
The reporting system can’t be persuaded to do reports based on the tags and the Database developers are complaining about the unCoddly things going on in their database.
In your version of PUBS, this extra column doesn’t exist, so we’ve added it and put in 10,000 titles using SQL Data Generator.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
/* So how do we refactor this database? firstly, we create a table of all the tags. */ IF OBJECT_ID('TagName') IS NULL OR OBJECT_ID('TagTitle') IS NULL BEGIN CREATE TABLE TagName (TagName_ID INT IDENTITY(1,1) PRIMARY KEY , Tag VARCHAR(20) NOT NULL UNIQUE) /* ...and we insert into it all the tags from the list (remembering to take out any leading spaces */ INSERT INTO TagName (Tag) SELECT DISTINCT LTRIM(x.y.value('.', 'Varchar(80)')) AS [Tag] FROM (SELECT Title_ID, CONVERT(XML, '<list><i>' + REPLACE(TypeList, ',', '</i><i>') + '</i></list>') AS XMLkeywords FROM dbo.titles)g CROSS APPLY XMLkeywords.nodes('/list/i/text()') AS x ( y ) /* we can then use this table to provide a table that relates tags to articles */ CREATE TABLE TagTitle (TagTitle_ID INT IDENTITY(1, 1), [title_id] [dbo].[tid] NOT NULL REFERENCES titles (Title_ID), TagName_ID INT NOT NULL REFERENCES TagName (Tagname_ID) CONSTRAINT [PK_TagTitle] PRIMARY KEY CLUSTERED ([title_id] ASC, TagName_ID) ON [PRIMARY]) CREATE NONCLUSTERED INDEX idxTagName_ID ON TagTitle (TagName_ID) INCLUDE (TagTitle_ID,title_id) /* ...and it is easy to fill this with the tags for each title ... */ INSERT INTO TagTitle (Title_ID, TagName_ID) SELECT DISTINCT Title_ID, TagName_ID FROM (SELECT Title_ID, CONVERT(XML, '<list><i>' + REPLACE(TypeList, ',', '</i><i>') + '</i></list>') AS XMLkeywords FROM dbo.titles)g CROSS APPLY XMLkeywords.nodes('/list/i/text()') AS x ( y ) INNER JOIN TagName ON TagName.Tag=LTRIM(x.y.value('.', 'Varchar(80)')) END /* That's all there was to it. Now we can select all titles that have the military tag, just to try things out */ SELECT Title FROM titles INNER JOIN TagTitle ON titles.title_ID=TagTitle.Title_ID INNER JOIN Tagname ON Tagname.TagName_ID=TagTitle.TagName_ID WHERE tagname.tag='Military' /* and see the top ten most popular tags for titles */ SELECT Tag, COUNT(*) FROM titles INNER JOIN TagTitle ON titles.title_ID=TagTitle.Title_ID INNER JOIN Tagname ON Tagname.TagName_ID=TagTitle.TagName_ID GROUP BY Tag ORDER BY COUNT(*) DESC /* and if you still want your list of tags for each title, then here they are */ SELECT title_ID, title, STUFF( (SELECT ','+tagname.tag FROM titles thisTitle INNER JOIN TagTitle ON titles.title_ID=TagTitle.Title_ID INNER JOIN Tagname ON Tagname.TagName_ID=TagTitle.TagName_ID WHERE ThisTitle.title_id=titles.title_ID FOR XML PATH(''), TYPE).value('.', 'varchar(max)') ,1,1,'') FROM titles ORDER BY title_ID |
So we’ve refactored our PUBS database without pain. We’ve even put in a check to prevent it being re-run once the new tables are created. Here is the diagram of the new tag relationship
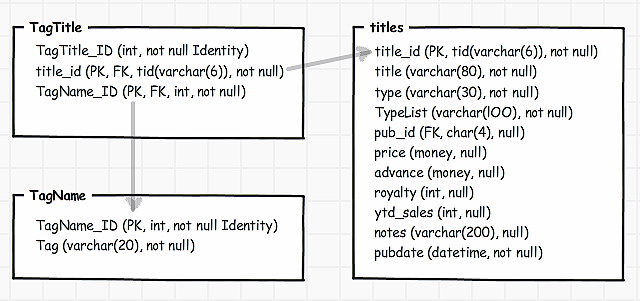
We’ve done both the DDL to create the tables and their associated components, and the DML to put the data in them. I could have also included the script to remove the de-normalised TypeList column, but I’d do a whole lot of tests first before doing that. Yes, I’ve left out the assertion tests too, which should check the edge cases and make sure the result is what you’d expect.
One thing I can’t quite figure out is how to deal with an ordered list using this simple XML-based technique. We can ensure that, if we have to produce a list of tags, we can get the primary ‘type’ to be first in the list, but what if the entire order is significant? Thank goodness it isn’t in this case. If it were, we might have to revisit a string-splitter function that returns the ordinal position of each component in the sequence.
You’ll see immediately that we can create a synchronisation script for deployment from a comparison tool such as SQL Compare, to change the schema (DDL). On the other hand, no tool could do the DML to stuff the data into the new table, since there is no way that any tool will be able to work out where the data should go. We used some pretty hairy code to deal with a slightly untypical problem. We would have to do this migration by hand, and it has to go into source control as a batch. If most of your database changes are to be deployed by an automated process, then there must be a way of
- over-riding this part of the data synchronisation process to do this part of the process
- taking the part of the script that fills the tables, Checking that the tables have not already been filled, and executing it as part of the transaction.
Of course, you might prefer the approach I’ve taken with the script of creating the tables in the same batch as the data conversion process, and then using the presence of the tables to prevent the script from being re-run.
The problem with scripting a refactoring change to a database is that it has to work both ways. If we install the new system and then have to rollback the changes, several books may have been added, or had their tags changed, in the meantime. Yes, you have to script any rollback! These have to be mercilessly tested, and put in source control just in case of the rollback of a deployment after it has been in place for any length of time.
I’ve shown you how to do this with the part of the script ..
|
1 2 3 4 5 6 7 8 9 10 |
/* and if you still want your list of tags for each title, then here they are */ SELECT title_ID, title, STUFF( (SELECT ','+tagname.tag FROM titles thisTitle INNER JOIN TagTitle ON titles.title_ID=TagTitle.Title_ID INNER JOIN Tagname ON Tagname.TagName_ID=TagTitle.TagName_ID WHERE ThisTitle.title_id=titles.title_ID FOR XML PATH(''), TYPE).value('.', 'varchar(max)') ,1,1,'') FROM titles ORDER BY title_ID |
…which would be turned into an UPDATE … FROM script.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
UPDATE titles SET typelist= ThisTaglist FROM (SELECT title_ID, title, STUFF( (SELECT ','+tagname.tag FROM titles thisTitle INNER JOIN TagTitle ON titles.title_ID=TagTitle.Title_ID INNER JOIN Tagname ON Tagname.TagName_ID=TagTitle.TagName_ID WHERE ThisTitle.title_id=titles.title_ID ORDER BY CASE WHEN tagname.tag=titles.[type] THEN 1 ELSE 0 END DESC FOR XML PATH(''), TYPE).value('.', 'varchar(max)') ,1,1,'') AS ThisTagList FROM titles)f INNER JOIN Titles ON f.title_ID=Titles.title_ID |
You’ll notice that it isn’t quite a round trip because the tags are in a different order, though we’ve managed to make sure that the primary tag is the first one as originally.
So, we’ve improved the database for the poor book distributors using PUBS. It is not a major deal but you’ve got to be prepared to provide a migration script that will go both forwards and backwards. Ideally, database refactoring scripts should be able to go from any version to any other. Schema synchronization scripts can do this pretty easily, but no data synchronisation scripts can deal with serious refactoring jobs without the developers being able to specify how to deal with cases like this.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments