





Staying In-sync with drift correction
Getting everyone in a team behind a process change is hard.
As a database developer, not only do you need to champion the new process within your own team, but you also need to extend the olive branch to your DBA to ensure everyone is on-board with the changes.
This is where you may encounter ‘challenges’, as SQL Change Automation is designed primarily with a developer workflow in mind:
Integrated Dev Environment → Source Control → Continuous Integration
Some DBAs may not be used to working in this way.
If your DBA currently prefers to make changes directly on Production (eg. for index additions, filegroup adjustments, permissions changes, etc), you’ll need to work together closely to ensure that his/her changes also get included in source control.
Failure to do so could result in deployment issues down the line, or even cause your DBA’s changes to be (quietly) undone.
To help you keep the change management loop closed, SQL Change Automation supports drift correction: a feature that allows you to keep track of changes made outside of your established process.
What is “drift”?
Drift occurs when a target database deviates from the baseline that was used to originally deploy it (eg. the database project within your repository’s trunk).

In this example, modifications were made to the live database after Version 1.2 was released, eg. using SQL Management Studio. This effectively created a new version of the schema outside of source control.
This could cause a problem when Version 1.3 is deployed, because the deployment package (migrations) will expect the target database to be in the state defined by the canonical (Version 1.2) baseline.
How it works
During a Continuous Integration build, a comparison is performed between the target database and the appropriate source control baseline. This process generates:
- A drift report, eg.
AdventureWorks_ReSync.html
Containing details of objects that have drifted from the source control baseline - A drift correction script, eg.
AdventureWorks_ReSync.sql
If executed, will re-synchronize the target db with source control, undoing changes made directly to Production
These artifacts are created within the bin\Release\ sub-folder of your database project.
Viewing the drift report
In the following example, an index has been added to an existing table in Production:
|
1
2
3
4
|
USE [AdventureWorks_PRODUCTION]
CREATE NONCLUSTERED INDEX IX_Person_ModifiedDate ON Person.Person
( ModifiedDate DESC ) ON [PRIMARY]
GO
|
During build, a drift report is generated because one or more object changes have been detected:
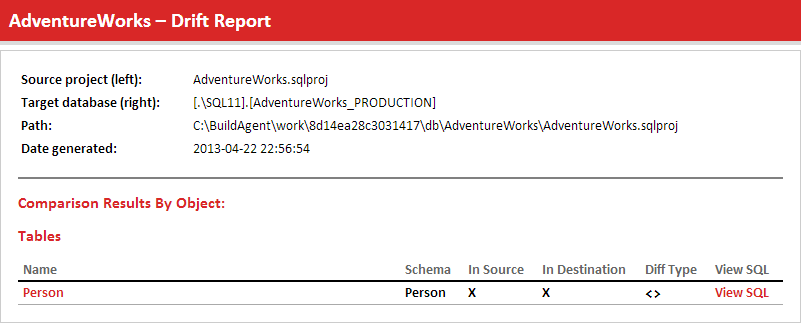
Further down, we can see that the index is missing from source control:

Note that this report is distinct from the deployment preview report, which shows changes that originate from source control only.
Viewing the drift correction script
The drift correction script reflects what is displayed in the report: that the object was not found in source control, therefore it should be removed from the target database:
|
1
2
3
4
5
6
7
8
9
|
-------------------------- BEGIN DRIFT CORRECTION (GENERATED) SCRIPT --------------------------
GO
Print 'Drop Index IX_Person_ModifiedDate from [Person].[Person]'
GO
DROP INDEX [IX_Person_ModifiedDate] ON [Person].[Person]
GO
-------------------------- END DRIFT CORRECTION (GENERATED) SCRIPT ----------------------------
|
This is the default behaviour of drift correction. However, another option is available.
Further down in the script is a (commented out) query batch that performs the opposite change of the above:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
----------------------------------------------------------------------------------------
-------------------------- NEW DEPLOY-ONCE SCRIPT --------------------------
----------------------------------------------------------------------------------------
/*
-- <Migration ID="e5910f2f-c691-44bd-828b-205e4481ac34" />
Print 'Create Index IX_Person_ModifiedDate on [Person].[Person]'
GO
IF (EXISTS(SELECT * FROM sys.objects WHERE [object_id] = OBJECT_ID(N'[Person].[Person]')
AND [type]='U')) AND NOT (EXISTS (SELECT * FROM sys.indexes WHERE [name]=N'IX_Person_ModifiedDate'
AND [object_id]=OBJECT_ID(N'[Person].[Person]')))
CREATE NONCLUSTERED INDEX [IX_Person_ModifiedDate]
ON [Person].[Person] ([ModifiedDate] DESC)
ON [PRIMARY]
GO
*/
|
Instead of dropping the index, this batch can be used to preserve the changes.
This is done by pasting the code into a new migration within your database project and committing the change to source control.
After the above script is deployed to Production, a further build should indicate that the drift has been resolved.
Set up
Configuring of drift correction happens within the build parameters section of your Continuous Integration server.

Specify these MSBuild properties in your build configuration to enable drift analysis:
- TargetServer & TargetDatabase: the SQL Server instance name & database name of the target environment (typically Production). Read-only and view-definition access is required.
- ShadowServer: a test SQL Server instance name. This will be used by SQL Change Automation to create a version of your database used as the basis of drift analysis. Sysadmin (database create/backup/drop) level access is required.
There is one other (optional) property that you can specify:
- DBReSyncOnBuild: If True, the drift-correction script will be executed after a successful build is performed, undoing any changes made in your target database. However, unless performing drift correction against a test environment, we strongly recommend specifying False (default) to give you an opportunity to review the script before executing it.
Other uses: branch resynchronization
Drift correction can also be used to help switch between branches in your source control system, eg. to assist with rolling-back changes made during a deployment.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
SQL Change Automation 4.0: Collaborative Database Development Across Visual Studio and SQL Server Management Studio
SQL Change Automation's Development component for developing new databases and modifying existing databases, using migrations, now integrates directly into SQL Server Management Studio as well Visual Studio. It allows teams to collaborate effectively during development, regardless of their preferred IDE, and in a way that integrates easily with common build/integration servers and release management tools.
Article
Solving Visual Studio database delivery problems with SQL Change Automation
For .NET developers working with Visual Studio (VS), the introduction of Database Projects with SQL Server Data Tools (SSDT) brought to VS the ability to manage changes to the database schema and code objects, just like any other type of application code. An added advantage is that the declarative style of SSDT’s project files lends itself to effective version control practices, such as being able to view an audit trail of database changes at the object level. However, at the point where you need to deploy your changes and preserve existing data in the target database, certain modifications to database tables
Article
Integrating SQL Server Tools into SQL Change Automation Deployments
Phil Factor shows how to integrate use of SQL Change Automation, SSMS registered servers, SMO, and BCP to automatically build or update a database on all servers in a group.

Article
Simple Steps in SQL Change Automation Scripting
Phil Factor demonstrates the bare essentials of SCA PowerShell scripts that can form the basis for an automated process for database delivery or help improve your current process.

Article
Resolving Cross Database Dependencies in SQL Change Automation using Local Databases or Clones
How to avoid database build failures, caused by circular cross-database object references, by restoring or provisioning copies of all required databases to the development, build, or test SQL Server instance.
Article
Integrating Redgate SQL Code Guard with SonarQube
Greta Rudžionienė provides a step-by-step guide to running SQL code analysis checks, as defined by SQL Code Guard, in SonarQube, a general-purpose code quality tool that can perform continuous code analysis on a variety of languages.
Loading comments...