Managing Datasets for Database Development Work using Flyway
A cross-RDBMS way of exporting, deleting and inserting data, for database development work. It is a PowerShell automation technique for Flyway that uses JSON files for data storage. It should help a team maintain datasets between database versions, as well as to switch between the datasets required to support different types of testing.
This article is part of a series on managing test data in a Flyway development:
- Better Database Development: The Role of Test Data Management
- A Test Data Management Strategy for Database Migrations
- Dealing with Database Data and Metadata in Flyway Developments
- Adding Test Data to Databases During Flyway Migrations
- Getting Data In and Out of SQL Server Flyway Builds
- Bulk Loading of Data via a PowerShell Script in Flyway
- Managing Test Datasets for a Database: What’s Required?
- Managing Datasets for Database Development Work using Flyway
Also relevant are the series of related articles on Database testing with Flyway.
No database developer should feel any apprehension about the task of generating development datasets, loading them into a database and using them for tests, or for providing the test data necessary for adding new features or functionality. Previous articles in this series provide the various ways of doing parts of the job, but I’ve never pulled it together into one article, or shown how Flyway can help with this for a range of RDBMSs. Here, I’d like to avoid diving too much into the fine detail, and instead illustrate the end-to-end process, creating, exporting, loading and deleting data, using a database being developed in Flyway. Flyway is handy because you know the version that you’re importing into and if you use the Flyway Teamwork framework, you’ll already have some useful information about the database; enough to do the job.
The technique I demonstrate stores the data in JSON files and generates a table manifest that we can use to define the correct order of dependency for each task. Data export tasks can either use JSON queries or the native bulk import/export tool for each RDBMS. To import the data from JSON, I provide a PowerShell cmdlet that reads in the contents of the JSON data files and converts it into multi-row INSERT statements.
Creating a dataset
I like to use SQL Server to create datasets, mainly because I like using SQL Data Generator. For me, using SQL Data Generator, with all its quirks, is second nature, because you can easily export data into a format suitable for other database systems. I’ve used it even for creating data for NoSQL Databases such as MongoDB. However, if you don’t have a special tool to generate data, there are other ways: not so convenient but sometimes you haven’t got the choice.
SQL itself is pretty useful for generating data. As well as the obvious linear, reverse-exponential and normally-distributed random numbers, almost any special types of number can be generated. (See Spoofing Data Convincingly: Credit Cards, Spoofing Data Convincingly: Masking Continuous Variables)
I’ve provided a project that generates random text, though it is also possible to use Markov chains to generate text from existing examples (see Spoofing Data Convincingly: Altering Table Data). It is easy to convert SQL results into JSON files (see JSONSQLServerRoutines). It’s also straightforward to export INSERT statements via PowerShell (see Scripting out SQL Server Data as Insert statements via PowerShell) and even export to non-SQL databases such as MongoDB (see Using Batch Scripts and SQLCMD to Write Out a Database’s Data.).
JSON has the useful adjunct of JSON Schema. This allows you to convey more precise information about the intended data type of the data such as whether data is binary information coded as a string. See Transferring Data with JSON in SQL Server and How to validate JSON Data before you import it into a database.
PowerShell provides a good way of creating a generic dataset, by which I mean a dataset that can be loaded into other database systems. You can use it to create all sorts of text that looks believable (see GenerateRandomText.Ps1). I use JSON for storing this data, though it is easy to do so in CSV. A PowerShell array of psCustomObjects, as is created by the ‘ConvertFrom-…‘ built-in PowerShell cmdlets, can be easily converted into SQL Multi-row insert statements (see ConvertTo-InsertStatements).
Working with a dataset: the table manifest
To do any work with data within a database, we need a list of the tables that are in the database. This is just a list of tables in the order of dependency, with the tables with no dependencies first, and the most dependent ones last. We read it in and use it to export the data as JSON. We don’t actually have to do it in any particular order.
This table manifest is derived from the full database manifest, which will list all the objects in dependency order. You can even use this full manifest, if needed, to create a build script from an object-level source (‘schema model’ in Flyway Desktop jargon). It isn’t its main purpose though: it is a good quick way of seeing how far deep any object is in dependency.
The table manifest is easy for us because it is provided by Flyway Teamwork. I’ve adapted the $SaveDatabaseModelIfNecessary script task so that it now generates the table manifest from the database JSON model, by examining the foreign keys. In this article, its role is occasionally just as a useful list of all the database tables, as when we export all the data currently in the tables, or report on the number of rows in all the tables. However, because the tables are in dependency order, we can also use it for more powerful magic: to insert data into all the tables or, with order reversed delete all the data in the tables. This code can be adapted to all sorts of routine tasks that have to be done for every table, such as disabling constraints, but is particularly useful where the order of operation is important.
The following preliminary routine defines a path for the data, based on the version of the database then looks for the table manifest for that version. If it’s not there, it generates the JSON model and then the manifest, using $SaveDatabaseModelIfNecessary. If then uses the manifest to establish the dependency list for the tables. If a JSON model already exists, you’ll need to delete it before running this code.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
cd <My Path to>\FlywayTeamwork\PubsPG\Branches\Develop . '.\preliminary.ps1' Write-Output @" $($Env:USERNAME) processing the $($dbDetails.variant) variant of $($dbDetails.branch) branch of the $($dbDetails.RDBMS) $($dbDetails.project) project using $($dbDetails.database) database on $($dbDetails.server) server with user $($dbDetails.installedBy)" "@ if ([string]::IsNullOrEmpty($dbDetails.Version)) { Process-FlywayTasks $DBDetails $GetCurrentVersion } $WhereToPutIt = "$($dbDetails.reportLocation)\$($dbDetails.Version)\Data" if (-not (Test-Path "$WhereToPutIt")) { $null =New-Item -ItemType Directory -Path "$WhereToPutIt" -Force } #now read in the manifest as an array of lines #It is in version V1.2.144 of the DatabaseBuildAndMigrateTasks.ps1 onwards. $currentManifest = "$($dbDetails.reportLocation)\$($dbDetails.Version)\Reports\TableManifest.txt" if (-not (Test-Path "$currentManifest" -PathType Leaf)) { Process-FlywayTasks $DBDetails $SaveDatabaseModelIfNecessary if (-not (Test-Path "$currentManifest" -PathType Leaf)) { throw @" could not access the manifest. Are you are using V1.2.144 or higher of the DatabaseBuildAndMigrateTasks.ps1? "@ } } $TablesInDependencyOrder = get-content -Path $currentManifest #Now we can read the current rowcount and then write out the data |
Each of the following data tasks assumes you’ve first run this part of the routine, so I won’t repeat it in any of the subsequent listings.
Exporting a data set
For many of the examples in this article, you’ll need the order of tables but when exporting data, the order isn’t that important. However, it will allow the files to be sorted by the creation dates of each file, to ensure they are loaded in the correct order.
Exporting data in JSON
Having established the list of tables in dependency order, the next part of the PowerShell routine exports the dataset, as JSON files, to the specified location. It will work with all the RDBMSs that the Flyway Teamwork currently supports.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
$TablesInDependencyOrder | foreach{ $tableName=$_; switch -Regex ($dbDetails.RDBMS) { 'sqlserver' { $expression = @" SELECT * from $tableName FOR JSON PATH "@ } 'postgresql' { # Do it the PostgreSQL way $expression = @" SELECT json_agg(e) FROM (SELECT * from $tableName)e; "@ } 'sqlite|mysql|mariadb' { ## OK, lets do it the conventional way. $expression = @" select * from $tableName; "@ } Default { $problems += "$($dbDetails.RDBMS) is not supported yet. " } } $filename = "$($_)".Split([IO.Path]::GetInvalidFileNameChars()) -join '_'; Execute-SQL $dbDetails $expression > "$WhereToPutIt\$filename.json" } |
We’ve specified a location that is version-specific, which is handy for a lot of the tasks you’ll do, but, generally, it needs to be in a location where it can be used for a range of database versions within the branch.
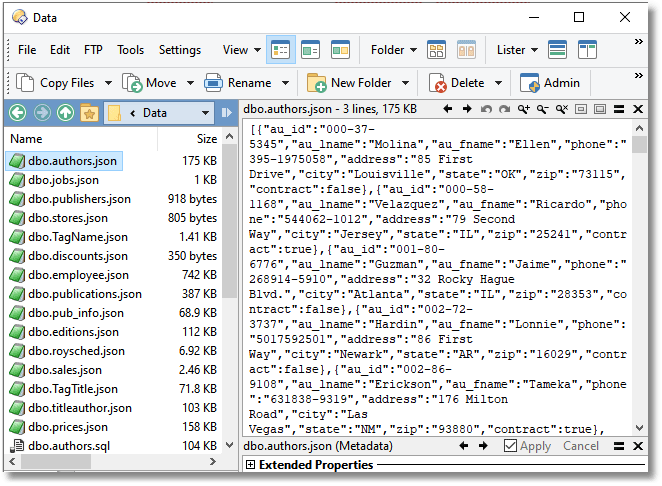
Note that, if there is an error at the database end, the error will go into the JSON output file instead of the JSON. Of course, you might not like JSON data. That’s no problem, because we can, and will, convert this to the data-import format best-suited to the input routines of the SQL dialect you’re using. It could be CSV, tab-delimited or SQL INSERT Statements. In our example we’ll be converting to multi-row INSERT statements. JSON is merely a useful intermediate form for storing datasets.
RDBMS-specific approaches
You can always use an RDBMS-specific approach instead. SQL Server’s ‘native BCP’ is one of the few very fast ways of importing data, and the Framework already has a way of importing and exporting this format (see Getting Data In and Out of SQL Server Flyway Builds). For most work, though, JSON does just fine.
Here is the PostgreSQL way to export data, using psql. In this case, we’ll use CSV format.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
$env:PGPASSWORD = "$($dbDetails.pwd)" $TablesInDependencyOrder| foreach{ $filename = "$($_)".Split([IO.Path]::GetInvalidFileNameChars()) -join '_'; Try { $Params = @( "--command=\copy $($_) to c:/temp/$filename.csv delimiter ',' csv header;", "--dbname=$($dbDetails.database)", "--host=$($dbDetails.server)", "--username=$($dbDetails.user)", "--password=$($dbDetails.pwd)", "--port=$($dbDetails.Port -replace '[^\d]', '')", "--no-password") psql @params } catch { throw "$psql query failed because $($_)" } } |
MySQL and MariaDB both can use MySQLDump. In this example, it is writing out the data as multi-row INSERT statements.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
$WhereToPutIt = "$($dbDetails.reportLocation)\$($dbDetails.Version)\Data" $TablesInDependencyOrder | foreach{ $filename = "$($_)".Split([IO.Path]::GetInvalidFileNameChars()) -join '_'; $Schema=($_.split('.'))[0] $Table=($_.split('.'))[1] Try { mysqldump ` "--host=$($dbDetails.server)" ` "--port=$($dbDetails.Port -replace '[^\d]', '')" ` "--password=$($dbDetails.pwd)" ` "--user=$($dbDetails.uid)" ` --no-create-info --skip-set-charset --skip-add-drop-table --skip-set-charset --compact ` $schema $table >"$WhereToPutIt\$filename.sql" } catch { throw "mysqlDump query failed because $($_)" } } |
Converting datasets from JSON to other formats
Despite the availability of RDBMS-specific tools, I’d store the data as JSON, especially if you’re working with more than one RDBMS, unless you find a performance hit that I haven’t noticed. If, on the other hand, you need CSV as your route to generic data-transfer, you can do this, using the variables set up in the code sample in ‘Exporting data in JSON’ …
|
1 2 3 4 5 |
$TablesInDependencyOrder| foreach { $filename = "$($_)".Split([IO.Path]::GetInvalidFileNameChars()) -join '_'; $Data=[IO.File]::ReadAllText("$WhereToPutIt\$filename.json") | ConvertFrom-json $Data| ConvertTo-Csv > "$WhereToPutIt\$filename.csv" } |
Likewise, you can even store this as insert statements, using the ConvertTo-InsertStatements cmdlet from Flyway Teamwork, but this approach isn’t entirely free of RDBMS-specific quirks.
Deleting a data set
It is fairly easy to delete a dataset. You can always do it by temporarily disabling or deleting foreign key constraints, but a more generic and unintrusive way is to do it is in reverse-dependency order. This means that you start by deleting the data from tables that may have foreign key references to other tables but have no tables with existing data referring to them via foreign keys. It is the reverse to the order in which you build tables, where you never CREATE a table that has foreign key references to tables that you haven’t yet created.
To do this, we’ll use the table manifest I demonstrated in the previous section, which is no more than a list of tables in dependency order. We simply reverse its order, as I show in the following code. When you do it like this, it is in fact scarily easy to delete all the current data in your database! The following code works with PostgreSQL, SQL Server and MySQL and SQLite, but it is very similar in the other SQL dialects.
We have already got everything we need! To keep things simple, I’ll use the same Flyway configuration and settings, so all the details in the $DBDetails array will be the same as we used in the data export. We need a reverse-order manifest for deleting the data in all the tables, so we’ll read in another copy of the manifest afresh as an array of lines and then reverse it.
Before and after we delete the data, we’ll find out how many rows there are in each table just to be certain that it has worked.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
<#----- Delete the data ------ #> $TablesInReverseDependencyOrder = get-content -Path $currentManifest [array]::Reverse($TablesInReverseDependencyOrder) # Now we can read the current rowcount and then delete the data $SQLStatements = $TablesInDependencyOrder | foreach{ "SELECT '$_' as `"TheTable`", count(*) as `"Rows`" from $($_)"; } Execute-SQLStatement $dbDetails ($SQLStatements -join "`r`nUNION ALL`r`n") $TablesInReverseDependencyOrder | foreach{ $SQLStatement = "Delete from $($_)"; Write-Output "Executing $SQLStatement ..." Execute-SQLStatement $dbDetails $SQLStatement } Execute-SQLStatement $dbDetails ($SQLStatements -join "`r`nUNION ALL`r`n"); |
TheTable Rows -------- ---- dbo.titleauthor 1499 dbo.tagtitle 1000 dbo.sales 21 dbo.roysched 86 dbo.pub_info 8 dbo.employee 5000 dbo.discounts 3 dbo.tagname 35 dbo.stores 6 dbo.publishers 8 dbo.publications 1000 dbo.prices 1000 dbo.jobs 14 dbo.editions 1000 dbo.authors 999 TheTable Rows -------- ---- dbo.titleauthor 0 dbo.tagtitle 0 dbo.sales 0 dbo.roysched 0 dbo.pub_info 0 dbo.employee 0 dbo.discounts 0 dbo.tagname 0 dbo.stores 0 dbo.publishers 0 dbo.publications 0 dbo.prices 0 dbo.jobs 0 dbo.editions 0 dbo.authors 0
Flyway is happy for you to delete all the data in this version without subsequent reproach because data isn’t part of a version, so the database is, in this case, still at version 1.1.7. If you need to have data in your database that is essential for it to work and must be part of a version, such as enumerations, then it’s best to use the multi-row VALUES clause within views, because the code to produce these is DDL code and therefore part of the database held within a migration script.
Inserting a data set
Every RDBMS has an optimal way of loading and dumping data. SQL Server uses bulk copy (BCP) for example, PostgreSQL uses the COPY command. MySQL has the LOAD DATA INFILE statement that loads CSV files. However, the general way of doing the job, using the syntax they all have in common, is to use multi-row INSERT statements.
The biggest problem with importing and exporting data in a generic way is that the database’s connection to its local file system is limited and the database rarely is allowed network access for reasons of security. These methods usually write to directories local to the database server. You really need a data directory on the network. In other words, your script, when exporting, will more simply pull the data out rather than request that the database pushes it out. Likewise, inserting is best done from a network-based file, unless performance is a big issue.
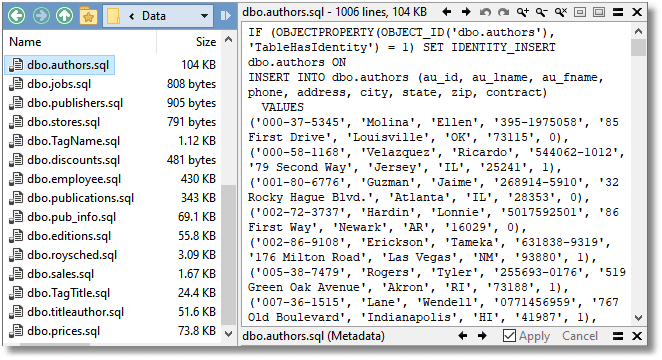
Here, I’m using a home-made cmdlet (ConvertTo-InsertStatements) to convert an object derived from JSON into a set of INSERT statements. This works well with most RDBMSs, even though there really aren’t enough datatypes in JSON to deal with the more complex datatypes that you find in databases.
However, RDBMSs have a different degree of tolerance towards data in INSERT statements. Whereas MySQL will do its best with the very spartan range of data types in JSON, SQL Server will quite often rear up and demand a conversion of JSON’s string into a datatype such as an image. To produce something that works with any data and RDBMS isn’t particularly practical, and I’ve opted for providing rules that can be provided for particular columns in specific tables. There is a good example here which concerns the logo column in the pub_info table.
Another issue is the number of rows that you insert at a time in a multi-row INSERT statement. It depends on the memory resources on the server that is hosting the database, and the CPU. Whereas multi-row INSERTs save on the overhead of processing each statement, a large batch can cause problems with managing memory resources on the sever. A typical compromise is to import data by running a series of multi-valued INSERTs with each statement having values for 1000 rows. However, a few experiments will give you the optimal figure which the home-grown cmdlet will use.
Here is the code to insert into the Pubs database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
<# the import #> if ([string]::IsNullOrEmpty($dbDetails.Version)) { Process-FlywayTasks $DBDetails $GetCurrentVersion } $WhereToGetIt = "$($dbDetails.reportLocation)\$($dbDetails.Version)\Data" #We can now read in the table manifest. It is in version V1.2.144 of the DatabaseBuildAndMigrateTasks.ps1 onwards. $currentManifest = "$($dbDetails.reportLocation)\$($dbDetails.Version)\Reports\TableManifest.txt" if (-not (Test-Path "$currentManifest" -PathType Leaf)) { Process-FlywayTasks $DBDetails $SaveDatabaseModelIfNecessary if (-not (Test-Path "$currentManifest" -PathType Leaf)) { throw @" could not access the manifest. Are you are using V1.2.144 or higher of the DatabaseBuildAndMigrateTasks.ps1? "@ } } get-content -Path $currentManifest| foreach { $filename = "$($_)".Split([IO.Path]::GetInvalidFileNameChars()) -join '_'; $ThePath="$WhereToGetIt\$filename.json" if (-not (Test-Path "$ThePath" -PathType Leaf)) {Throw "I'm sorry, but there was no data file called '$ThePath' to fill $($_)" } $Data=[IO.File]::ReadAllText("$ThePath") | ConvertFrom-json $Prequel=$null; $sequel=$null;$MyRules=@{};$clause='' if ($dbDetails.RDBMS -eq 'postgresql') {$Clause= 'OVERRIDING SYSTEM VALUE'}; if ($dbDetails.RDBMS -eq 'sqlserver') {$Prequel="IF (OBJECTPROPERTY(OBJECT_ID('$($_)'), 'TableHasIdentity') = 1) SET IDENTITY_INSERT $($_) ON"; $Sequel="IF (OBJECTPROPERTY(OBJECT_ID('$($_)'), 'TableHasIdentity') = 1) SET IDENTITY_INSERT $($_) OFF";} if ($dbDetails.RDBMS -eq 'sqlserver' -and $dbDetails.project -eq 'Pubs'){$MyRules=@{'logo-column'='CONVERT(VARBINARY(MAX),xxx)'}} "filling $filename" $PSDefaultParameterValues['Out-File:Encoding'] = 'utf8' ConvertTo-InsertStatements -TheObject $Data ` -TheTableName $_ -Batch 500 -Prequel $prequel -Sequel ` $sequel -Rules $MyRules -Clause $clause > "$WhereToGetIt\$filename.sql" Execute-SQLStatement -DatabaseDetails $dbDetails -Statement '-' -fileBasedQuery "$WhereToGetIt\$filename.sql" } |
filling dbo.authors (500 rows affected) (499 rows affected) filling dbo.jobs (14 rows affected) filling dbo.publishers (8 rows affected) filling dbo.stores (6 rows affected) filling dbo.TagName (35 rows affected) filling dbo.discounts (3 rows affected) filling dbo.employee (500 rows affected) (500 rows affected) (500 rows affected) (500 rows affected) (500 rows affected) (500 rows affected) (500 rows affected) (500 rows affected) (500 rows affected) (500 rows affected) filling dbo.publications (500 rows affected) (500 rows affected)
…and so on…
Summary
Data isn’t really part of a database version. It is best applied to the database in a separate process. Flyway provides several callbacks that can be used to do this. This gives the developer a lot more freedom to create, modify and use datasets that can be loaded into the database, when working in a branch, to test or experiment.
I’ve demonstrated a generic way of storing, exporting and loading data, using JSON files for storage and using Flyway together with the Flyway Teamwork framework to do the tricky bits. I’ve designed this to be as widely usable as possible, and with the least-possible pain. If this can be made easy enough, it should be possible to take a much more relaxed attitude to testing databases and to experimenting with a mix of development data sets that can best assist the work you’re doing. Make it as easy as possible to do, and it is more likely to get done.
Tools in this post
You may also like
-

Article
10 Mistakes I’ve Made When Migrating Databases to the Cloud
John Q Martin, Technology & Alliances Partner Manager at Redgate, covers 10 mistakes he's made when migrating databases to the cloud - and the strategies he now implements to avoid them happening again. But first, John explains exactly why databases are the hardest part of cloud migration.
-

Article
Redgate’s roadmap for cross-database DevOps
At Redgate, we strongly believe that all databases should be managed and orchestrated in the same way, with the same standards of security and quality in releases. For the past few years, we’ve been leading the adoption of database DevOps by focusing on the most challenging parts of the process like version control, continuous integration
-

Article
Flyway Alerting and Notifications
Once a scripted Flyway task is tested and bedded-in, it should rarely cause errors, so when one happens the team need to be notified immediately, especially if it is part of an automated deployment process. This article provides a PowerShell cmdlet that will execute any Flyway command, process and filter the Flyway output and send any errors to the chosen notification system. You can receive the Flyway error alerts on your mobile phone, if required!
-
Article
New Redgate Flyway GitHub Actions: Faster setup, safer deployments
If your team uses GitHub Actions to ship application code, you’ve probably wished your database changes could move through the same pipeline just as smoothly. Today, that’s easier than ever. We’ve launched verified Redgate Flyway GitHub Actions on the GitHub Marketplace, giving you a simple, reliable way to integrate database deployments into your existing GitHub
-
Article
Pipelining Configuration Information Securely to Flyway
This article demonstrates two techniques for allowing Flyway to read extra configuration information from a secure location, possibly encrypted. The first technique pipes the contents of the config file to flyway via STDIN, and the second uses PowerShell splatting. This makes it much simpler to use Flyway to manage multiple development copies of a database using role-base security.
-

Article
Rollbacks, Undos and Undonts
Rollback scripts are designed to allow us to recover safely from a failed deployment that leaves the database in an indeterminate state. They must check exactly what needs to be reverted before doing so. If you work with an RDBMS that cannot support transaction DDL rollback they are vital. This article proposes a strategy where you create and test a rollback file, at the same time as the forward migration, and reuse it as a Flyway undo script.





