
For development and test databases that include payment-card data, using real card numbers is a compliance nightmare (PCI DSS) and a liability. The alternative is generating fake credit card numbers that look realistic – correct length for the brand, valid-looking prefix ranges, and passing the Luhn checksum that payment systems use as a first-pass validity check.
This article shows how to generate Luhn-valid fake card numbers in SQL Server: implementing the Luhn algorithm as a T-SQL function, using brand-appropriate prefix ranges (Visa starts with 4, Mastercard with 5 or 2, Amex with 34 or 37, Discover with 6011 or 65), and a BigRandomNumberView for producing batches of cards at once.
(The generated numbers are unambiguously fake (don’t match real issuing bank BINs) but will survive input validation in test scenarios that check only format and checksum.)
I haven’t seen a SQL Server table with real unencrypted credit card numbers for several years, and I don’t know of any good reasons to have them stored that way. However, I’ve needed them in the past for testing a web application that had to take credit card details. Generating credit cards in a way that conforms to a particular distribution is reasonably easy in SQL Server, though. The only difficult bit is the fact that there is a validation checksum. Otherwise it is a good example of how to solve the problem of spoofing the more specialist types of data.
Imagine that we need to create fake credit cards from a fairly large table. We don’t want, and can’t get, the real information, but our fake credit cards have to conform to the distribution of the real data.
All we need is an aggregation of the real data that tells us the distribution. Fortunately, the first six digits of a credit Card has only the details of the bank, currency and so on. We aren’t going to associate the fake data with an identifiable person. We are pretty safe. We are just generating a list of credit cards. We will draw from the list at random and not associate the randomly-generated suffix with the original person.
We start with the real data. OK, it isn’t real data, but we’ll pretend that it is. The data I used is provided with this blog so you can try it out. It conforms roughly with the proportion of providers that you’ll see in the States.
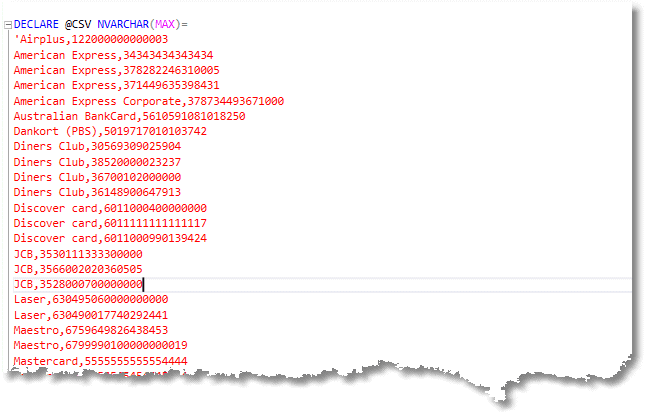
… A lot of rows omitted here …
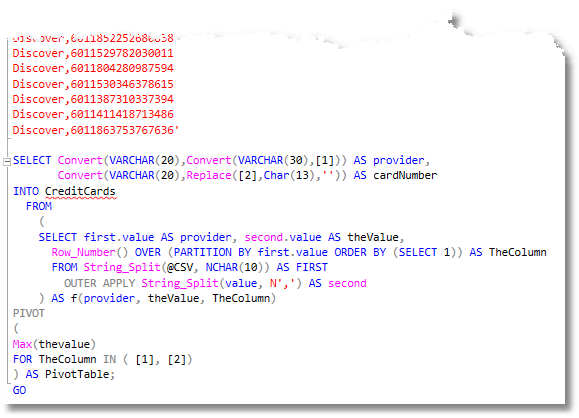
We just need to know the distribution. You must imagine that these cards are from a production system that you will never see. In reality, you would just receive from the Ops people the Generation Table #GenerationTable so you wouldn’t need access to the actual data
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
/* We create a table that gives us the distribution of the bank prefix of the number, for each length of card. This is the number of times that each 6-character Bank ID prefix occurs with a particular length It also calculates the range so as to be able to pick a random number right across the range. */ CREATE table #GenerationTable (Prefix char(6), Thelength INT, TheFrequency int, TheRange int) INSERT INTO #GenerationTable (Prefix, Thelength, TheFrequency, TheRange) SELECT f.IIN, --the prefix f.TheLength, --the length ofd the credit card f.frequency, --how often it occurs, Sum(f.frequency) OVER (ORDER BY f.IIN,TheLength)--the cumulative total (giving the range) FROM ( SELECT Count(*) AS frequency, Len(CardNumber) AS TheLength, Left(CreditCards.cardNumber, 6) AS IIN FROM CreditCards GROUP BY Left(CreditCards.cardNumber, 6),Len(CardNumber) ) AS f(frequency, TheLength, IIN); GO |
Now we can use the Generation Table to provide valid credit cards with the correct distribution. Note that, by this method, you will only get credit card numbers with the prefixes that come from the generation table.
|
1 2 3 4 5 6 7 |
CREATE TABLE SpoofedCreditCards(Card CHAR(20)) DECLARE @topOfRange INT = (SELECT Sum(Thefrequency) FROM #GenerationTable) INSERT INTO SpoofedCreditCards(Card) SELECT dbo.ValidCardNumber(Prefix,TheLength) FROM #GenerationTable cross JOIN Random WHERE Convert(INT,Number*@topOfRange)+1 BETWEEN (TheRange-TheFrequency)+1 AND TheRange |
With this table we can quickly throw together a routine that provides our friends in AdventureWorks (or your spoof customer names) with credit cards. We use the ‘zip’technique.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT TheName.Fullname, TheCard.card FROM ( SELECT Coalesce(Person.Title + ' ', '') + Person.FirstName + Coalesce(' ' + Person.MiddleName + ' ', ' ') + Person.LastName + Coalesce(' ' + Person.Suffix, ''), Row_Number() OVER (ORDER BY NewId() ASC) FROM AdventureWorks2016.Person.Person ) AS TheName(Fullname, TheKey) INNER JOIN ( SELECT SpoofedCreditCards.Card, Row_Number() OVER (ORDER BY NewId()) FROM SpoofedCreditCards ) AS TheCard(card, TheKEY) ON TheName.TheKey = TheCard.TheKEY; |
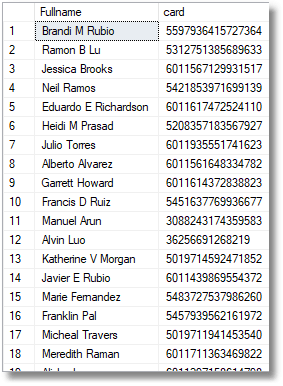
To do this, you would need to start with a view that gives you a twenty digit number when combined with the six-digit prefix
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE VIEW TwentyDigitNumber /* fourteen digit strings are returned */ AS SELECT Char(Ascii('0') + (Rand() * 9 + 1)) + Char(Ascii('0') + (Rand() * 9 + 1)) + Char(Ascii('0') + (Rand() * 9 + 1)) + Char(Ascii('0') + (Rand() * 9 + 1)) + Char(Ascii('0') + (Rand() * 9 + 1)) + Char(Ascii('0') + (Rand() * 9 + 1)) + Char(Ascii('0') + (Rand() * 9 + 1)) + Char(Ascii('0') + (Rand() * 9 + 1)) + Char(Ascii('0') + (Rand() * 9 + 1)) + Char(Ascii('0') + (Rand() * 9 + 1)) + Char(Ascii('0') + (Rand() * 9 + 1)) + Char(Ascii('0') + (Rand() * 9 + 1)) + Char(Ascii('0') + (Rand() * 9 + 1)) + Char(Ascii('0') + (Rand() * 9 + 1)) AS numbers; GO |
Now, we need the function that produces the spoof credit card that is correct according to Luhn’s algorithm
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 |
CREATE OR ALTER FUNCTION dbo.ValidCardNumber (@ProviderPrefix CHAR(6),--the six characters that denote the provider @length INT --between 13 and 19 digits including the provider /** Summary: > This function returns a valid credit card number, including the provider string or ANSI prefix supplied as a parameter. It is valid only in the sense that the card will past the Luhn Checksum test. It is generated by random numbers so is unlikely to be a genuine credit card number! The Luhn Algorithm (Modulus 10 Algorithm) is only a checksum formula (ISO/IEC 7812-1) that is an extra verification for human errors. The ANSI prefix (AKA the BIN, IIN,or BAN and PAN prefix) is the “primary account number” for credit card processing. Except for the first digit, the contents varies from provider to provider. The information cannot be used to identify a personal account but reveals the bank identity and country of issue and could indicate the currency being used. This information is company confidential. A very obscure prefix could potentially identify an individual when joined with other data but this is unlikely e.g. 540221 = ANZ National Bank ANZ Low Interest MasterCard Credit Card 490603 = BC VISA Credit Card issued by Industrial Bank of Korea 374671 = Blue American Express Card 630490 = Bank of Ireland Laser/Maestro debit card Author: Phil Factor Date: 06/08/2018 Database: PhilFactor Examples: - Select * from stuff - Select top 100 percent stuff Returns: > nothing **/ ) RETURNS VARCHAR(20) --between 13 and 19 digits AS BEGIN DECLARE @wideNumber CHAR(20), @checksum INT, @lastdigit INT, @AlteredDigit INT; IF @length > 20 OR @length < 0 SELECT @length = 16; IF @ProviderPrefix LIKE '%[^0-9]%' SELECT @ProviderPrefix = numbers FROM TwentyDigitNumber; SELECT @wideNumber = CASE WHEN @length % 2 = 1 THEN '0' ELSE '' END + @ProviderPrefix + Left(numbers, @length - Len(@ProviderPrefix)) + '00000000000000000000' FROM TwentyDigitNumber; SELECT @checksum = CASE WHEN @wideNumber LIKE '%[^0-9]%' THEN -2 WHEN @wideNumber IS NULL THEN -1 ELSE + 2 * cast(substring(@wideNumber, 1, 1) AS TINYINT) / 10 + 2 * cast(substring(@wideNumber, 1, 1) AS TINYINT) % 10 + cast(substring(@wideNumber, 2, 1) AS TINYINT) + 2 * cast(substring(@wideNumber, 3, 1) AS TINYINT) / 10 + 2 * cast(substring(@wideNumber, 3, 1) AS TINYINT) % 10 + cast(substring(@wideNumber, 4, 1) AS TINYINT) + 2 * cast(substring(@wideNumber, 5, 1) AS TINYINT) / 10 + 2 * cast(substring(@wideNumber, 5, 1) AS TINYINT) % 10 + cast(substring(@wideNumber, 6, 1) AS TINYINT) + 2 * cast(substring(@wideNumber, 7, 1) AS TINYINT) / 10 + 2 * cast(substring(@wideNumber, 7, 1) AS TINYINT) % 10 + cast(substring(@wideNumber, 8, 1) AS TINYINT) + 2 * cast(substring(@wideNumber, 9, 1) AS TINYINT) / 10 + 2 * cast(substring(@wideNumber, 9, 1) AS TINYINT) % 10 + cast(substring(@wideNumber, 10, 1) AS TINYINT) + 2 * cast(substring(@wideNumber, 11, 1) AS TINYINT) / 10 + 2 * cast(substring(@wideNumber, 11, 1) AS TINYINT) % 10 + cast(substring(@wideNumber, 12, 1) AS TINYINT) + 2 * cast(substring(@wideNumber, 13, 1) AS TINYINT) / 10 + 2 * cast(substring(@wideNumber, 13, 1) AS TINYINT) % 10 + cast(substring(@wideNumber, 14, 1) AS TINYINT) + 2 * cast(substring(@wideNumber, 15, 1) AS TINYINT) / 10 + 2 * cast(substring(@wideNumber, 15, 1) AS TINYINT) % 10 + cast(substring(@wideNumber, 16, 1) AS TINYINT) + 2 * cast(substring(@wideNumber, 17, 1) AS TINYINT) / 10 + 2 * cast(substring(@wideNumber, 17, 1) AS TINYINT) % 10 + cast(substring(@wideNumber, 18, 1) AS TINYINT) + 2 * cast(substring(@wideNumber, 19, 1) AS TINYINT) / 10 + 2 * cast(substring(@wideNumber, 19, 1) AS TINYINT) % 10 + cast(substring(@wideNumber, 20, 1) AS TINYINT) END; SELECT @AlteredDigit = CASE WHEN @length % 2 = 1 THEN @length + 1 ELSE @length END; SELECT @lastdigit = Cast(Substring(@wideNumber, @AlteredDigit, 1) AS TINYINT); IF (@checksum % 10 <= @lastdigit) SELECT @lastdigit = @lastdigit - (@checksum % 10); ELSE SELECT @lastdigit = @lastdigit + (10 - (@checksum % 10)); IF @checksum % 10 <> 0 SELECT @wideNumber = Stuff(@wideNumber, @AlteredDigit, 1, Char(Ascii('0') + @lastdigit)); RETURN Substring(@wideNumber, 1 + (@length % 2), @length); END; GO |
And finally, you have a view that contains just the number of random numbers that you need. I’ve bulked this up to 4000 just to test out and make sure the routine performed well. The source is with the blog.
… and so on down to the end … (it avoids iteration and is fast)

We can now compare the distribution of the old and new data, using the routine published here in ‘Visual Checks on How Data is Distributed in SQL Server’
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
DECLARE @FirstVariable IndependentVariable; --a simple table of numbers INSERT INTO @FirstVariable (number) SELECT Convert(FLOAT,(Left(CreditCards.cardnumber,6))) FROM CreditCards SELECT ColumnHistogram.line AS 'Original Modified date' FROM dbo.ColumnHistogram(@FirstVariable) ORDER BY ColumnHistogram.y DESC; GO DECLARE @SecondVariable IndependentVariable; --a simple table of numbers INSERT INTO @SecondVariable (number) SELECT Convert(FLOAT,Left(Card,6)) FROM SpoofedCreditCards; SELECT ColumnHistogram.line AS 'Spoofed Modified date' FROM dbo.ColumnHistogram(@SecondVariable) ORDER BY ColumnHistogram.y DESC; GO |
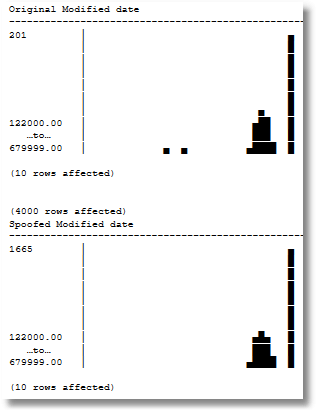
Can we improve on this in order to get a smoother distribution of provider strings? At the moment we can’t create a six-digit provider string that isn’t in the original data. To do so isn’t easy, because each provider uses the string in a different way, and not every combination of digit is used even for the individual provider. It would require maintenance as well because provider strings can come and so, or change.
This following routine is designed for generating lists. You can check the routine that creates the card by using an existing routine, dbo.fnIsValidCard, that I wrote a while back in The Luhn Algorithm in SQL .
|
1 2 3 4 5 |
SELECT CreditCards.provider, CreditCards.cardNumber FROM creditcards WHERE dbo.fnIsValidCard( dbo.ValidCardNumber(CreditCards.cardNumber, Len(CreditCards.cardNumber)) ) = 0; |
Downloads
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments