




Comparing Two SQL Server Databases: When, Why, and How
SQL Compare is now close to 20 years old and has been put to uses that the original developers of the tool barely imagined. After a brief recap of what it is and how it works, I'll review how to compare SQL databases with SQL Compare, and how this makes the following common development tasks easier, less error-prone and faster:
- Update a target database so it is the same as the source
- Update a subset of a database
- Create or update a scripts folder from a database
- Create or update a database build script
- Create a point-in-time "snapshot" of a database
- Generate a schema migration script for deployments
What is SQL Compare?
SQL Compare is a GUI tool to compare SQL Server databases. It will inspect the structural differences between the source and target databases, and present side-by-side differences in the SQL DDL code of each of the tables and code modules. It will generate a deployment script (a.k.a. a '1-way synchronization' script or 'migration' script) that will update the target database to make its structure the same as the source, preserving the existing data wherever possible, and issuing a warning if it's not. You can use SQL Compare's options and filters to control how it does this comparison, and what objects in ignores.
SQL Compare provides a command line interface (which may be subject to a different, automation-based license), both for Windows and Linux. It allows you to perform the comparisons and deployments as part of a scripted process. When used from the command line or script, SQL Compare can provide an HTML or Excel file as a report.
SQL Compare's comparison engine is also built into both SQL Change Automation and SQL Source Control.
How does SQL Compare work?
SQL Compare will compare schemas between databases, specifically between two different versions of the same SQL Server database. The source and target might be 'live' SQL Server databases, but they don't have to be because SQL Compare can work with any representation of a database from which it can construct a 'model' of the structure of that database. For example, it can parse a scripts folder, containing a set of DLL scripts for every database object, into a model of the database, or even a single build script. Similarly, it can work with a SQL Compare Snapshot or a SQL Source control project or a SQL Change Automaton project file.
On running the comparison, SQL Compare will generate a list of database objects that exist only in the source, or exist only in the target, or exist in both but have differences. It will display the differences in the metadata for each object, in script form, and can auto-generate the deployment (or 'schema migration') script that will, if executed, alter the target so that its metadata is the same as the source.
If the target is a database, the script will create any objects that exist only in the source, drop any objects that exist only in the target, and update any object that is in both so that its definition matches that in the source. Similarly, if the target is an existing DDL code directory, files are added, removed, or altered to reflect the source database. In each case, SQL Compare will issue a warning of any likely issues, including cases where it can't preserve existing data. You can inspect the resulting migration script, and alter it if necessary, before applying it to the target.
SQL Compare provides filters, to control which objects are included in the comparison, and various options that control how the comparison and subsequent scripting is done.
SQL Compare's auto-generated schema migration script runs within a transaction and will automatically rollback if errors occur. You will be warned if certain objects, such as full text indexes, cannot be deployed in a transaction, and they will be deployed separately.
Tricky database development tasks that SQL Compare tackles
The following diagram illustrates many of the tasks that SQL Compare can perform as part of development work, such as generating the migration script to take the target database from its current version to the source version, or creating a build script, to create the current version from scratch. Regardless of source and target, SQL Compare always offers the option to generate and save the auto-generated script that it will use to update the target, which you can then adapt to requirements.
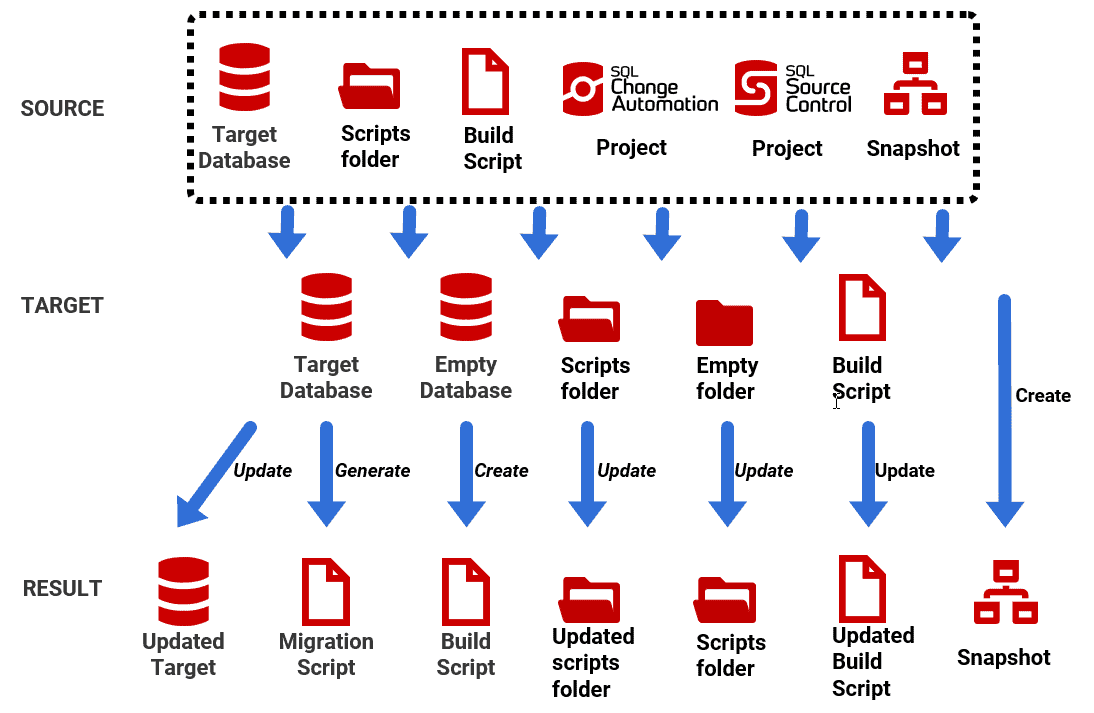
1 Update a target database so it is the same as the source
With any of the database sources indicated previously, and shown in the above diagram, SQL Compare will construct a 'model' of that database, compare it to a target database, and generate a migration script to update the metadata of the target so that it is the same as the source. This has obvious uses during development; for example, you can upgrade the current version of any databases on the test server, to the release candidate.
SQL compare's auto-generated migration script will preserve existing data in the target, wherever possible, when deploying changes to it. However, if the extent of the differences between source and target is such that SQL Compare can't work out what happened, or where data should move, then you'll need to intervene. If you use a scripts folder to represent the source database, you can write custom scripts that deal with these migrations issues, and SQL Compare will append them automatically to the beginning or end of its auto-generated script. See Generating a migration script for deployments.
If the target is an empty database, the comparison is essentially between the source and SQL Compare's internal representation of the model database, in SQL Server, and the result is a build script for the source database. See Creating or updating a build script.
2. Update a subset of a database
You can also compare only parts of a database. For example, you can compare schemas between databases (or a group of schema), or can compare tables between databases, or other types of object, such stored procedures. You can even compare just one named object, such as one view (plus the tables on which it depends).
SQL Compare's numerous comparison options control how SQL Compare does this comparison, the way it compares database objects, and the type of script it generates. You can also use its filters to exclude certain classes of object, such as database users, or specific database objects or groups of objects, such as all objects in a schema, from the comparison.
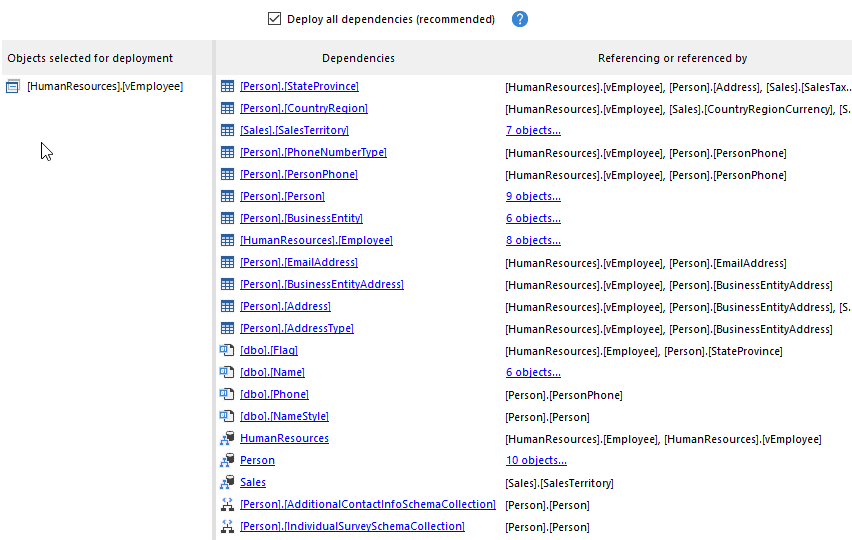
For example, perhaps you just need to modify and then test one view, in the database, but it depends on 20 tables. With SQL Compare, you select just the required view in the source, with the target being an empty database. As long you remember to select the "Deploy all dependencies" option (called IncludeDependencies, if you are using the command line), then it will script out the view and all dependencies, so you can build, modify and test just that portion of the database.
3. Create or update a scripts folder from a database
It the target of a comparison is an empty file system directory, and you choose to allow SQL Compare to update the scripts folder directly, the result will be an orderly set of CREATE scripts, one for each object in the source database. So, you will have the source of each table and routine as a separate script file, with the scripts organized into sub-directories by type of database object.
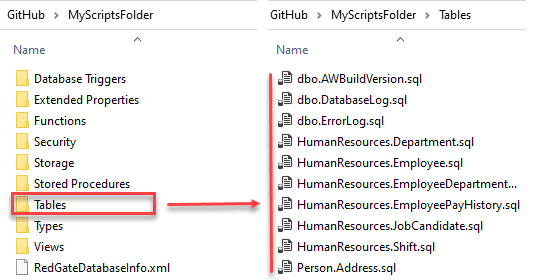
As you make subsequent changes to the source database, you can rerun the comparison to the target scripts directory, quickly see the differences between the new version and the source scripts and update the latter to reflect the changes. This is handy if you need to keep track of your database changes outside of version control, such as in the early 'proof of concept' phase of a project.
If you use a source-controlled scripts directory as the target, then you have quick way to get a database into source control:
- Get a 'reference' copy of a database into the development system, such as a refence copy of the current version of the Staging or Production database.
See Reverse-Engineering the Production Database into Source Control - Get a legacy database, for which no or limited source exists, into source control.
See Retrospective Database Source Control with SQL Compare - Detect database 'drift' between different versions or releases of a database. For example, you can detect any drift between the current production database, and what's in source control, just by comparing to the scripts directory.
See How to cope with Database Drift during Deployment using SQL Compare
SQL Compare can create or update a script directory even if the source is just a single build script, such as generated in SSMS. For example, let's say you want to get a working build of the Staging database into source control. The following scheme would do the trick:
- Use SSMS to generate a database build script (e.g. Tasks > Generate Scripts)
- Test it to verify that you can build the database.
- Save a copy of the verified build script in an empty directory on your development server
- Use SQL Compare to compare the build script folder, as the source, to an empty folder in your local version control repository
You might see warnings that a "non-schema statement was ignored", but if you persevere and click "Continue without resolving errors", SQL Compare should generate the usual DDL code directory, containing all the object in the Staging database, with the different types of objects placed in subdirectories.
If the target is an existing scripts folder, SQL Compare will generate its list of objects in the source that are different from those in the target, from which you can generate the script to deploy those differences.
Finally, the source can be a chaotic scripts folder for a legacy database if you put all the files in one directory. SQL Compare can compare it to an empty script folder (or database), or you can use the /empty2 switch in SQL Compare command line. You should end up with neatly organized object scripts.
4 Create or update a database build script
If the target of a comparison is an empty file system directory, and you choose to generate a deployment script, instead of or alongside allowing SQL Compare to update the scripts folder directly, the result will be a single build script. SQL Compare can also produce a single document build script from a 'chaotically-organized' source, as described in the previous section.
The build script will create all the database objects, in the correct dependency order, taking the database from 'zero', to the required version. If you must create this build script by hand, instead, it is a harder task than it sounds. The build will fail if you don't build the objects in the right order. User-defined data types, for example, need to be in place before the tables; functions and procedures can't be created until the objects that they reference exist; tables must be built in a certain order, according to the existing references and constraints. Using SQL Compare will save you a lot of time.
It the target of a comparison is a script directory containing a single build script, and the source is a build script then you can simply update the existing build script to match the source. See Maintaining a Database Build Script with SQL Compare for an example.
5. Create a 'point-in-time' snapshot of a database
A SQL Compare Snapshot is just a point-in-time copy of the metadata of a database. It is a file containing a machine representation of the metadata, as produced by a parser. It does not contain any data.
A snapshot cannot be modified, and so represents a stable view of the database structure, as it existed when it was created. The source for the new snapshot can be a database, another snapshot, a source control directory, or a simple scripts folder.
You can use it in comparisons in the same way as a normal database. For example, with a snapshot as a source, SQL Compare will compare it to the target and auto-generate a deployment script to make the state of the target match that of the snapshot.
They have many possible uses. For example:
- Compare live databases with snapshots to find out what's changed then save the changes
- Compare two databases if you don't have direct access to either, or compare different, older versions of a database to see what has changed.
- Capture the database state before and after refactoring, and then run a comparison to work out what broke, if the change has caused some tests to fail
- Use a snapshot as a simple rollback technique to return quickly to the last working copy. See SQL Compare Snapshots: a lightweight database version control and rollback mechanism
6. Generate a migration script for deployments
Database migrations, rather than simple builds, become necessary when a production database system must be upgraded, in situ, in a way that guarantees to preserve the data and doesn't disrupt the service. When testing a release candidate, therefore, before it enters the deployment pipeline (UAT, Staging, and so on), the team must create and thoroughly test the migration script that will change the current production version to the new version.
SQL compare's auto-generated schema migration script will preserve data where possible, when deploying changes to the target, and will often succeed, especially if the databases are structurally similar. It will only fail when confronted with schema re-engineering that means it has no way that it can match tables and columns in source and target, and so cannot preserve the data. This can happen if tables or their components are renamed, or if tables are split, datatypes changed, constraints are added or amended, and so on.
Teams that avoid tackling these migration problems or hope that SQL Compare tool will 'just do it', will find that 'breaking changes' accumulate, deployments become daunting, and releases are delayed. Instead, you need to 'flag' those schema changes that might affect existing data in unpredictable ways, as early in development as possible. For those cases, you provide SQL Compare with some help.
For simple adjustments, you can amend the auto-generated script directly, but in others you will need to add custom scripts to deal with the migration issues. When using a scripts folder as a source, SQL Compare can automatically run one pre-deployment custom script (which must be placed in a Custom Scripts/Pre-Deployment subdirectory), used to alter the target database after the auto-generated portion of the migration script is generated but before it is executed, and one post-deployment custom script (Custom Scripts/Post-Deployment subdirectory), to alter the target after the auto-migration script has been executed:
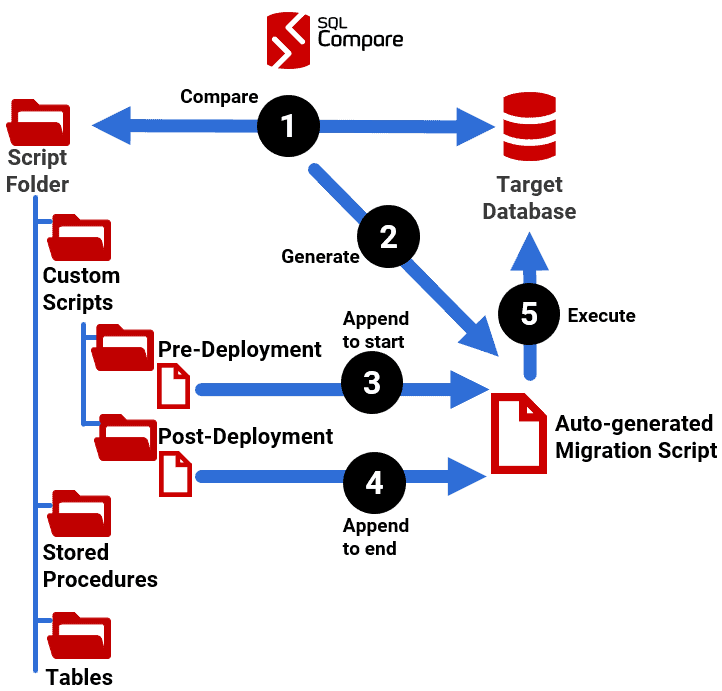
You can deal with quite a few migrations in this way. For example, if you're refactoring tables, it may be possible to write a pre-deployment script to extract the data from a column that's about to be dropped, save it into a temporary table, and then use a post-deployment script in to distribute the existing data into the new table design. Or, if you've amended constraint definitions and have existing data that violates the new rules, you might deploy the new constraints in a 'disabled' state, initially, and then use a post-deployment script to fix the data and then enable them. For other examples, see Using Custom Deployment Scripts with SQL Compare or SQL Change Automation.
However, care is required when amending SQL Compare's auto-deployment process. You'll have to "obey the rules", when writing the custom scripts, making sure they are idempotent, and doing all transaction handling yourself, so you have a means to roll them back safely if things go wrong. If you need to make changes to the target to get it into the required state before SQL Compare runs the comparison, then the only way to do it is to execute the required migration scripts beforehand, as a separate process.
Overall, it can be hard to ensure that this sort of partly customized, partly auto-generated deployment is always safe, even if accidentally run on the wrong version of the target database. If you frequently encounter deployment blockages because of problems with SQL Compare's auto-generated deployment process, then it is probably wiser to use a migrations-based deployment tool like SQL Change Automation to develop a script specifically designed to upgrade a target database, at a specific version, to the new version (see A Hybrid Approach to Database DevOps for more details).
References:
Documentation:
Redgate University training videos:
Related Redgate Product Learning articles (not referenced in the body of this article):
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
How to build multiple database versions from the same source: pre-deploy migration scripts
The final part of Alex Yates's three-part series tackles the complicated issue of automating deployments when the same table might have a different structure, in different production versions of the database.

Article
SQL Server Database Deployment: What Could Go Wrong?
Phil Factor tackles the tricky questions you will need to answer when deciding how to automate your SQL Server database builds and deployments with Redgate's development, version control and deployment tools.

Article
Unearthing Bad Deployments with Redgate Monitor and Redgate's Database DevOps Tools
Sudden performance issues in SQL Server can have many causes, ranging all the way from malfunctioning hardware, through to simple misconfiguration, or perhaps just end users doing things they shouldn't. But one particularly common culprit is when deployments go wrong: I don't know a single DBA who hasn't been burned by a bad release.
Article
Keeping track of history: SQL Compare and Temporal Tables
Asha Patel introduces SQL Compare 13's support for deploying changes to temporal tables,

Article
Using Custom Deployment Scripts with SQL Compare or SQL Change Automation
Phil Factor describes how custom pre- and post-deployment scripts work, when doing state-based database deployments with SQL Compare or SQL Change Automation, and how you might use them to, for example, add a version number to the target database, specify its database settings, or stuff data into some tables.

Article
Designing an automated database deployment process: case study
In my previous article, How to design an automated database deployment process, I wrote about the steps companies and organizations should take to introduce automation to their database deployments. In this article, I’m going talk about the challenges I faced when I embarked on my own automation journey. Prior to joining Octopus Deploy, I was the lead developer on a pilot team that automated database deployments and reduced the time required from two to four hours per deployment down to ten minutes. Why automate? One of the DBAs in the company summed it up best when they said, “Our database
Loading comments...