




How to cope with Database Drift during Deployment using SQL Compare
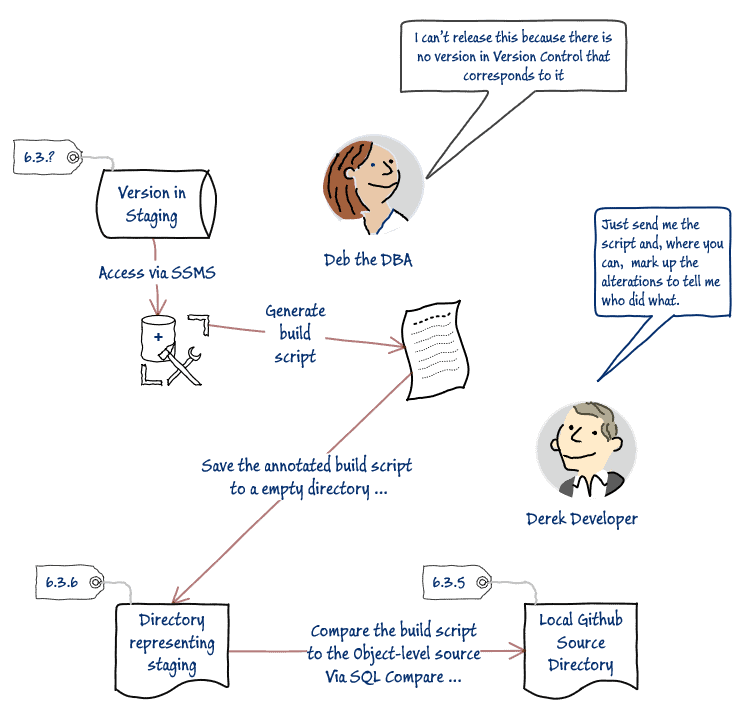
Imagine this. Deb the DBA has just finished checking out a new version of a database in staging. She has suddenly discovered that the version has ‘drifted’. It was version 6.3.5 that was deployed from version control, but it seems that the migration script has had some minor but essential changes since then. There was that NVARCHAR datatype that had to be increased in size to avoid truncation. There was that silly glitch in performance testing because someone got the index wrong. The security team also spotted a problem with some executed code, based on user input, which wasn't using a parameter. They fixed the stored procedure because it was easier to do that than explain how. There was that pesky CHECK constraint that fired on perfectly good data. The test team dealt with that. They all altered the migration script in turn as the release passed through the pipeline.
Deb the DBA has been told to release this version because there is pressure from the business for the new functionality it contained, and all the participants in the pipeline have agreed that, after a shaky start, it is now OK. What does she do? Those changes were nicely documented in the script. They ought to be in source control. She doesn't have direct access to the source control system, and only Derek in development has access to SQL Compare.
Deb's conundrum is this. The database in staging is the release candidate, and her migration script is ready, tested, and checks out fine, but that database is no longer v6.3.5. She needs it to become a new version, 6.3.6, in source control before she can responsibly release to production from staging.
The first and most important thing to do is to create a point-in-time build script representing the version in Staging. SSMS does this well, and the default settings are fine.
Getting a build script from SSMS
On the object explorer pane of SSMS, click on the 'databases' item of the server, and then right-click on the name of the database. You'll see a context menu. Find the item 'tasks' which leads to a sub-menu. This has an item 'Generate Scripts….'. Click on this and, you reach the scripting wizard. After an introductory page, you will see this.
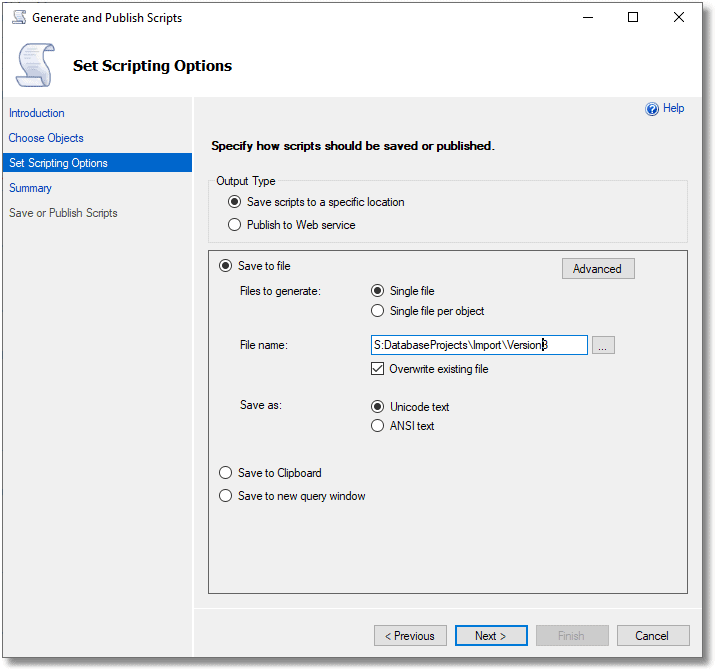
You'll see that I've typed in the name and location for the file I want as the destination of the script. There is an 'Advanced' button that allows you to specify exactly how you'd like the script. It is rather like ordering coffee from an over-eager artisan coffee barista. Fortunately, you can ignore the button as the defaults will do us fine. Click 'Next' and you'll see this:
You, or rather Deb the DBA, is now almost done. All that Deb must do now is to annotate the script to describe who did what and where (she includes a hashtag in each of the comments to make them easier to find). Then she sends the script to Derek in development.
Updating source control: adding the changes to the object source
The next stage is to get the changes into source control, and for this we'll use SQL Compare.
You, or rather Derek, should create a directory and place the build script in it. This script should be the only file in the directory. The target is the source code directory for version 6.3.5, in the local GitHub directory. A small word of caution: SQL Compare does not officially support using an SSMS build script as a source. You'll see several warnings that a "non-schema statement was ignored", but persevere and click "Continue without resolving errors" and SQL Compare should generate its usual list of objects in the source that are different from those in the target.
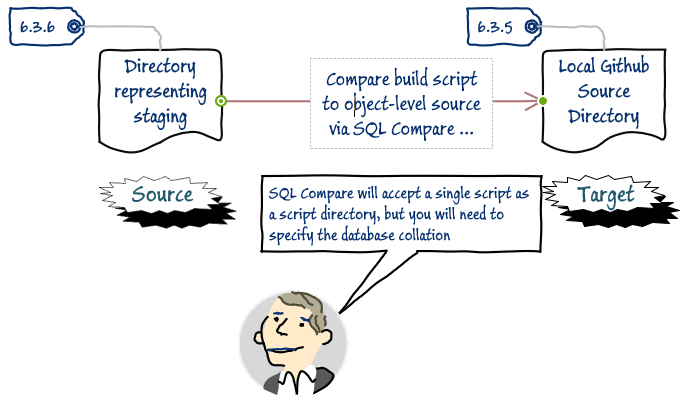
Derek can now deploy the detected changes to the local GitHub directory, to update the object-level source so that it is at version 6.3.6. He can also save off an initial cut of the 6.3.5-to-6.3.6 migration script, which SQL Compare will also obligingly generate.
In different circumstances, the target might be an empty source directory, in which case Derek would have on the development system a 'reference build' for the current version of the Staging database (see The Database Development Stage for more details).
Committing the changed files to GitHub
We'll assume that you are using Github or Git. Although it is possible for Derek in Development to commit the changes under his own name, it isn't safe because people will one day have forgotten the whole messy detail of this interlude and blame Derek. The aim here is to create a new version, with the people who did the work listed in Git as co-authors. For this to happen, their emails should be in the configuration settings.
If Derek knows who did what, it is possible to commit as the person who changed the release. For example, Timothy Tester might have added an index. That change could be committed under Timothy's name.
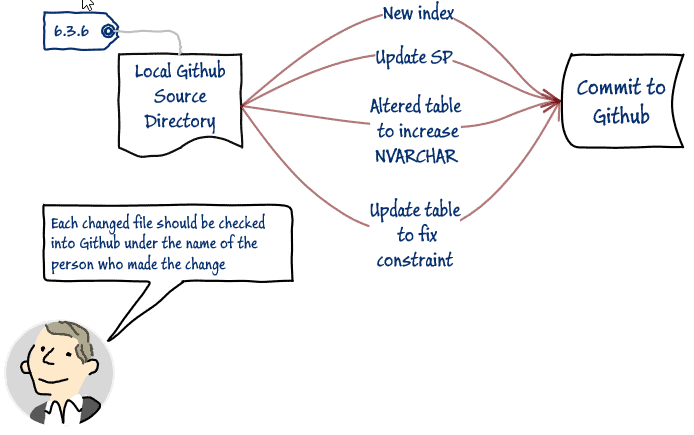
Derek Developer now gives the go-ahead to Deb. Now because the various changes to the migration script were effectively already tested in staging before the drift became apparent, Deb the DBA has just one final task before release. She changes the version number in the migration script to 6.3.6.
Conclusions
It is nice to pretend that we all invariably practice the methods extolled in the various manuals on Continuous Delivery. The problem is that so many factors must be examined in the deployment of a database application. We can encourage everyone to 'shift-left' to try to make sure that a release candidate is perfect, but sometimes we must react to pragmatic decisions. SQL Compare is flexible; it can cope with occasional problems that would otherwise stop a deployment dead in its tracks.
Collaboration in any database-driven application ought to encompass the entire release chain, including QA and operations, to ensure that individual releases are far less complex and come out much more frequently. If a team decides to reduce the incidence of triage of release candidates, by dealing with minor problems rather than delay release, then it is surely up to us as team members to ensure that the team processes can be sufficiently flexible to allow this to happen.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
SQL Compare Snapshots: a lightweight database version control and rollback mechanism
During the proof-of-concept phase of development work, SQL Compare Snapshots offer an easy way to work out what broke, if a change causes some tests to fail, as well as a simple ‘roll back’ technique to return quickly to the last working copy.

Article
Database Branching and Merging without the Tears
Armed with a schema comparison engine and an object-level directory of the source for every recent version of the database, you'll be able to remove a lot of the uncertainty around merging database changes back into development.
Article
Building a Database Directly from Object-level Source Scripts
Table manifests, and object manifests, which are just ordered lists, are a very useful output from and development database build. This article show how to generate a table manifest in SQL, and once you have it, you'll start to find several uses for it, besides the build process.

Article
Using Filters to Fine-tune Redgate Database Deployments
Filters are used by Redgate's SQL Compare, SQL Source Control, DLM Dashboard, and SQL Change Automation. A typical use for a filter is to work on just one schema within a database or just a limited set of tables and routines. You would also want to use a filter to exclude certain object, such as database users, from comparisons. Phil Factor explains how they work, and how to create, edit and then use them within the various Redgate tools.
Article
Keeping track of history: SQL Compare and Temporal Tables
Asha Patel introduces SQL Compare 13's support for deploying changes to temporal tables,
Article
How to build multiple database versions from the same source: pre-deploy migration scripts
The final part of Alex Yates's three-part series tackles the complicated issue of automating deployments when the same table might have a different structure, in different production versions of the database.
Loading comments...