





Using SQL Compare and SQL Data Compare within a PowerShell Cmdlet
There are quite a few tasks you're likely to undertake in the earlier stages of database development, the main ones being:
- Saving database changes to source control
Save any alterations to the schema or the data of your dev database to a script directory, to then save it to your branch of the code - Updating a database with changes from source
Make a database identical to a source directory, scripting both the schema and, if you wish, the database data - Generating the latest change scripts
For the schema and data, for you or someone else to check - Generating a build script for the source
To do a clean build of a new database versions, such as for integration testing.
You'll need to run these tasks often, for example if you are doing a lot of testing of your development branch and you wish to run a test that affects data, which must be at a known state. Therefore, it's best to automate them.
I'll demonstrate a PowerShell cmdlet that uses SQL Compare and SQL Data Compare command line versions, with a database and a script folder, to perform all four of these tasks. As a bonus, I've added the option to export the entire data as CSV and JSON at the time you're saving the changes.
Command line licensing
The automation described in the article, using the SQL Compare and Data Compare command lines, is only available for customers of Redgate Deploy and SQL Toolbelt. For full details, see the Changes to distribution of command line page of the documentation.
What we're doing
There are many ways that you can use SQL Compare and SQL Data Compare at the command line. There are a lot of different types of source and target other than databases, such as backups, backup sets, SQL Source control projects, SQL Change Automation projects, Redgate Snapshots and scripts folders. There are also a lot options and switches that cover all sorts of edge cases and infrequent requirements. We're just going to cover the basics.
Update the contents of the "C:\Scripts\Pubs" scripts folder to reflect the database BigThink\Pubs:
sqlcompare /Server1:BigThink /Database1:Pubs /Scripts2:"C:\Scripts\Pubs"
Update the data INSERT statements in the "C:\Scripts\Pubs" scripts folder to reflect the data on database BigThink\Pubs
sqldatacompare /Server1:Pubs /Database1:Pubs /Scripts2:"C:\Scripts\Pubs"
Update the database BigThink\Pubs to make it identical to the database represented by the script in the "C:\Scripts\Pubs" folder:
sqlcompare /Scripts1:"C:\Scripts\Pubs" /Server2:BigThink /Database2:Pubs
Create the C:\Scripts\Pubs folder if necessary and place in it the Redgate database information and the scripts subdirectories, with the object-level scripts from BigThink\Pubs and include a data directory with data INSERT statements for all the tables on database BigThink\Pubs:
SQLDataCompare /server1:BigThink /database1:Pubs /force /MakeScripts:"C:\Scripts\Pubs"
There is, of course, a lot more you can do. If you compare a source with a target with SQLDataCompare.exe, you can export the data of the source as CSV files. (/export: command) (True CSV, not SQL Server Comedy-limited). This allows you to import data using a bulk import, which is a lot more satisfactory for a regular build process.
A quick spin around the block
The trouble with using PowerShell is that, by the time you've put in some error handling, reporting and security, even the minimal PowerShell example for updating the target with the latest changes in the source can start to look a bit complicated. Once you get to the switches and options, you might be forgiven for being confused. I've therefore combined several processes into one cmdlet so I've less to maintain and remember.
You can download the Run-DatabaseScriptComparison cmdlet that can automate all these tasks from my GitHub repo. See The Code section later for more details. You can compile the cmdlet in the ISE or run it from a PowerShell command line.
I'll describe broadly how it works and what you can configure a bit later but first let's take a quick tour of what it can do.

Scripting a database into source control
To do this we simply compare a database (PubsTest) as the source, with a script directory as the target. In this example, the scripts directory doesn't yet exist so will be created (with the name PubsTest, by default) and the whole database, and its data will be scripted into source control.
|
1
2
3
4
|
#if using windows security (Trusted_Connection) use this …
Run-DatabaseScriptComparison -MyServerInstance 'MyServer' -MyDatabase
#... OR if using SQL Server Security use this (with the name changed where necessary)
Run-DatabaseScriptComparison -MyServerInstance 'MyServer' -MyDatabase 'pubstest' -UserName FredBloggs
|
It whirrs away for a while, and hopefully we get this:
PS C:\WINDOWS\system32> S:\work\programs\powershell\Run-DatabaseScriptComparison.ps1 successfully Synched using Database MyServer/pubstest as source and Script Folder as target Build Script successfully generated using Database MyServer/pubstest as source and Script Folder as target updated Data successfully using Database MyServer/pubstest as source and Script Folder as target
Here is our source control folder. I'd just run a test with PubsDev, which is why that folder is already there. Our database PubsTest, however, has just appeared as a subdirectory. We're expecting it to hold all the scripts we want.
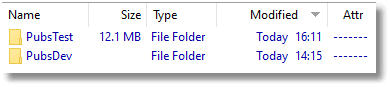
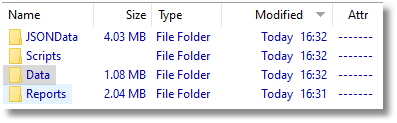
If we click on PubsTest, we see that in it are five directories.
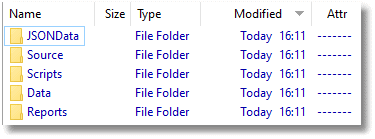
The Source directory is our Redgate Script folder and contains the object level source scripts, generated by SQL Compare and, in the Data subfolder, the data scripts generated by SQL Data Compare.
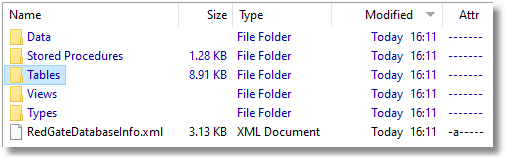
You'll normally see a lot more object folders, but this is just a simple sample database and we've just got tables, views, types, and procedures. The data scripts, stored separately for each table as INSERT statements, aren't any good for bulk insert, and we need some extra code to use them in a build. However, they are useful if you want to synchronize the data. The .sdcs files for each table contain index information that enables SQL Data Compare to compare static data. The Scripts contains build scripts, data scripts and deployment scripts. Now, the build script and the deployment scripts are essentially identical since they both create all the objects from scratch. The Data and JSONData directories contain all the data as CSV files and as JSON scripts, respectively. If you have a large amount of data, you'll lose interest in storing data this way, and can opt to avoid it, but if you use a special test dataset for development work, you'll certainly want it for running integration tests. The Reports directory tells you what happened and what the differences were between the database and the scripts directory.
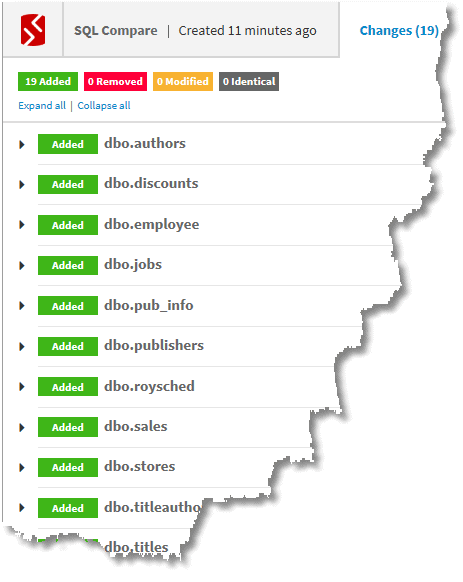
So far, so good.
Scripting database changes into source control
Now we just check that any changes that we subsequently make are replicated if we rerun the system. We alter PubsTest to remove the deprecated datatypes in PubInfo
|
1
2
|
Alter table Pub_info ALTER COLUMN pr_info nvarchar(max);
Alter table Pub_info ALTER COLUMN logo Varbinary(max);
|
We'll want to make sure that the source for our branch reflects this change
|
1
|
Run-DatabaseScriptComparison -MyServerInstance 'MyServer' -MyDatabase 'pubstest' -UserName JoeBloggs -MyVersion '_1-2-4'
|
We run the script. In the PubsTest source directory, holding the Redgate Scripts folder, just the pub_info source has changed because this is the table we altered in the database and so the system has updated the source.
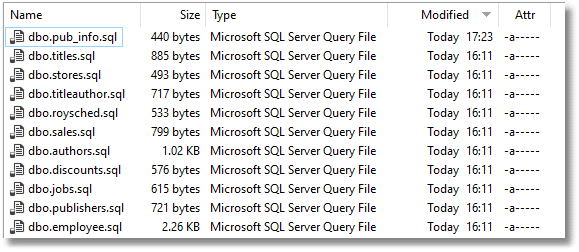
The three scripts have been added to the Scripts directory. The Synch script basically has the two ALTER TABLE statements.
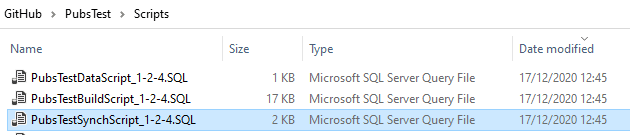
You may not want build scripts and Synch scripts, depending on how you do your updates to your development databases. With the script, you can opt whether you have these SQL scripts merely by putting a null in the variable that specifies where you want them stored instead of the path.
Updating a database with changes from source
OK. We can now test it out by creating a new database called PubsTwo and deploying our Scripts directory to it so that it has both the metadata and data and is identical to PubsTest. Fortunately, PubsTwo is on the same server, so we don't need to change the value of the -MyServerInstance parameter. We just change the -MyDatabase parameter.
More importantly, the target is now the PubsTwo database, and the source is the PubsTest script folder, so we add the -sourcetype 'script' parameter. When we run the cmdlet, not only will it synchronize PubsTwo so that it matches the source but will also generate build and synch scripts for the PubsTwo deployment We'll give these scripts the version number 1-2-4, using -MyVersion '_1-2-4', which is the version with the altered pub_info table currently in the PubsTest folder. If you are using a trusted connection you shouldn’t use the -UserName parameter:
|
1
|
Run-DatabaseScriptComparison -MyServerInstance 'MyServer' -MyDatabase 'pubsTwo' -UserName JoeBloggs -sourcetype 'script' -MyVersion '_1-2-4' -MyScripts 'PubsTest'
|
We then run it ….
successfully Synched using Script Folder as source and Database MyServer/pubsTwo as target Build Script successfully generated using Script Folder as source and Database MyServer/pubsTwo as target updated Data successfully using Script Folder as source and Database MyServer/pubsTwo as target
…and we get a new directory where the build, synch, data scripts and report scripts for the PubsTwo deployment are held. By default, it saves them in a PubsTwo subfolder within the Git directory to which the -SourceFolder parameter points. I'll discuss how to alter that behavior in the Where things get saved to section, below.
If you opted just to generate the script rather than go straight ahead to do the synchronization, this gives you a chance of checking the script, making any necessary changes and executing it. If you provide appropriate version numbers, a complete record of build scripts and change scripts is maintained, otherwise only the current one is kept so you can check the process. Basically, enough ‘paperwork’ is done for a typical deployment, but it is always done in the folder for the Target database.
We can now run SQL Compare and SQL Data compare to confirm that the two are identical.

The Run-DatabaseScriptComparison Cmdlet
To allow as much configurability as possible, the code of the cmdlet seems kinda complicated in places. The most obvious complication is that I use the Password Vault here for storing any credentials. It is wrong to assume that all SQL Servers can be assumed to use Windows Security. If you specify a username, then the code assumes you want to store any password in your Password Vault. If there is nothing there, it asks you for it and stores it there.
Building the Cmdlet
There is one detail that you may need to change and that is in the two lines that describe where the actual SQL Compare and SQL Data Compare tools are stored on your machine. They'll vary according you your machine configuration, install options and version number.
|
1
2
|
$SQLCompare = "${env:ProgramFiles(x86)}\Red Gate\SQL Compare 14\sqlcompare.exe" # full path
$SQLDataCompare = "${env:ProgramFiles(x86)}\Red Gate\SQL Data Compare 14\sqlDatacompare.exe" # full path
|
Configurability
I've also made anything configurable anything that you're likely to want to configure. Obviously, there are certain things you really need to specify, such as the name of the server and database, but not much else. The rest gets what I think are sensible defaults. If this isn't enough you just change the code in the cmdlet. My own version, for example, uses the version number for other purposes as well, such as saving to the source directory when it is the target, or otherwise to the database when you opt to allow SQL Compare to do the Synch.
IWantTheDataPlease
For example, you just set -IWantTheDataPlease to $False (no) if you don't want the data included with the save or synch process. It is an obvious $True (yes) if you have a small database dataset, but as data size gets big, you'll wand a separate native-BCP process.
IWantToSynchPlease
If you are doing things that aren't likely to stop the cmdlet in its tracks, then you'll want to leave -IWantToSynchPlease to $true so that the source and target that you specify gets immediately synched. If you set the variable to $false then the script that would do the synch is produced. If there is likely to be a problem, you get a warning.
SourceType
SQL Compare thinks in terms of 'Source' and 'target'. The default for the cmdlet is -SourceType='database', because a lot of the time you'll be using it to save changes to the current branch, so that the source code is being updated to reflect the changes in the database.
If you set it to 'script' then it will change the database to reflect the source's version of the state of the database. This is sometimes very handy, but if you get it wrong, you can overwrite the state of the database. You can tweak the code of the cmdlet to allow you to routinely save the source code before a change to the database.
MyVersion
If you opt for the default of not putting the version number in the build and migration scripts generated by the cmdlet, then leave -MyVersion to the default. If you would like to keep each version, then set the parameter to a string representing a version number. I like to start with a '_' character to separate the version number clearly from the database name in the filename.
Where things get saved to
If you specify the -SourceFolder parameter, which is the location of your source control directory (e.g. Git) then that affects where everything else is stored. You can specify any one of these locations, of course. If you don't for example want your reports to go into your source control directory, you just say where with -MyReportPath. You might want your data, either CSV (MyExportPath) or JSON (MyJSONExportPath) to go elsewhere as well, if maybe you share development datasets across the team. All the other places where scripts are written (e.g. -MyScriptsPath and -MybuildScriptPath) can be altered.
The Code
As this code is a bit bulky, and I’ve included the sample database that I used, it is held here at Phil-Factor/Database_Comparison_And_Sync. The code is Run-DatabaseScriptComparison.ps1 and I’ve also included the PubsTest. To demonstrate a way of running it, I’ve included some code here RunComparison.ps1.
Summary
When you're working on a database, working with SQL Compare and SQL Data compare User Interface can be a distraction, especially if you are asking it to do the same task repeatedly. When you start automating this by using the Command-Line Interface (CLI), you'll find that it is much easier, but still needs occasional changes are your requirements evolve. A Cmdlet is ideal for this, because you can fix it to do what you want but allow for different varieties of tasks by parameterizing a lot of the variables such as the locations where you store 'artifacts' and what you want to store.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Adding Test Data to Databases During Flyway Migrations
How to generate "realistic but fake" SQL Server test data, using SQL Data Generator, and then use SQL Data Compare to produce an INSERT script that Flyway can run to load the data into the database. The technique is useful for managing small volumes of test data or for "topping up" existing data when you create new entities.

Article
Exploring the SQL Compare Options
You need to compare database schema objects in two SQL Server databases, and then automatically generate a SQL deployment script that when executed will remove these differences, either making the schema of the target database match the source, or vice-versa. It sounds easy, but the problems lie in the details of the schema comparison options.

Article
Maintaining a Database Build Script with SQL Compare
Phil Factor explores a lesser-known capability of SQL Compare, which is to help you maintain a 'traditional', well-documented, single file build script, for creating the current version of the database during development.
Article
Automating Flyway Undos
How to auto-generate first-cut undo scripts for every Flyway migration. For every new version of a database created by a Flyway versioned migration, we compare it to a 'source' directory containing object-level build scripts for the previous version. The SQL Compare engine does the rest, producing the associated undo script that will revert the database to the previous version, if required.
Article
Reverse-Engineering the Production Database into Source Control
Starting out a new database development with source control is relatively easy. To introduce source control into an existing database application can be more challenging. Phil Factor explains some of the fundamental steps.

Article
You just Build It don't you? 12 Common Database Build Blockers
Database deployments, like the sheep of exasperated hill-farmers, often find strange and unexpected ways to self-destruct. Phil Factor describes the most common things that can go wrong, and how a reliable automated database build process can prevent messy accidents.
Loading comments...