





Questions about SQL Change Automation that you were Too Shy to Ask
- What is SQL Change Automation?
- Do I have to use a migration-based approach to use SCA?
- We've just started using the SSMS SCA add-in. How is it different from the old "DLM-A" tool?
- I'm getting errors when trying to create a "baseline" for my deployment project. What's causing this?
- Why does SCA do so much checking of databases during a deployment?
- Do I need to wrap the deployment artifacts up into a NuGet Build package?
- Can SCA release a new version of just one schema of a large database?
- When I deploy a new version of a stored procedure, SCA drops and recreates it, which means I need to reset permissions. How can I avoid this?
- I'm getting a puzzling 'String_Split is an invalid object' error when deploying to a SQL Server 2017 instance. What's going on?
- I'm getting a weird error that talks about ReadPast Lock. What should I do?
- SCA is altering all the user permissions in staging and production and deleting the replication users. What should I do?
- The production database contains attributes related to replication that we can't include in the development project. How do I omit them?
What is SQL Change Automation?
SQL Change Automation (SCA) automates the database change process for SQL Server, focusing on the database build, release, and deployment processes. It encourages practices such as Continuous Integration by providing a build process that can test and validate the source code and deliver a working deployment package. The release process deploys the build package to the target database servers.
It is designed to be used primarily by a PowerShell module, but also provides a set of add-ons for continuous integration and continuous deployment servers, such as Team Foundation Server, Azure DevOps (formerly VSTS, Visual Studio Team Services), Octopus Deploy, TeamCity, Bamboo and Jenkins.
Under the covers, it provides static SQL code analysis that is compatible with that in SQL Prompt, as well as database documentation and automated testing using TSQL-t. For more details, see the docs: About SQL Change Automation.
Do I have to use a migration-based approach to use SCA?
Not necessarily. SCA aims to be able to support the database development methodology you use and doesn't presume that there is a single obvious 'royal road' to database development.
To provide better support for an enterprise-scale migration approach in the database industry, SQL Change Automation's development add-ins for Visual Studio or SQL Server Management Studio support automated build, release, and deployment of migrations projects.
However, the SCA PowerShell module supports both automated deployment of migration projects, created using the add-ins, and state-based (a.k.a. static, or object-based) scripts folders, that will be familiar to users of SQL Compare or SQL Source Control.
We've just started using the SSMS SCA add-in. How is it different from the old "DLM-A" tool?
DLM-A supported the static approach, using SQL Source Control for version control and PowerShell for deployments. The SSMS add-in, conversely, supports the migration approach, primarily, but also a 'hybrid' approach where the team use SQL Source Control to maintain the current state of the database in version control, during development, and then use the add-in to generate and test the migration scripts that will deploy the changes to the target database.
When automating deployments, you'll find that the cmdlets have been renamed. Two new cmdlets have been added to provide support for migration-based projects. The 'package' has become a 'build artifact' and a 'release' has become a 'release artifact'. Converting old DLM-A scripts is generally straightforward, but check on each cmdlet for details of any changes
| DLM-Automation Cmdlets | Equivalent SCA Cmdlets |
| Export-DlmDatabasePackage | Export-DatabaseBuildArtifact |
| Export-DlmDatabaseRelease | Export-DatabaseReleaseArtifact |
| Export-DlmDatabaseTestResults | Export-DatabaseTestResults |
| Import-DlmDatabasePackage | Import-DatabaseBuildArtifact |
| Import-DlmDatabaseRelease | Import-DatabaseReleaseArtifact |
| Invoke-DlmDatabaseSchemaValidation | Invoke-DatabaseBuild |
| Invoke-DlmDatabaseTests | Invoke-DatabaseTests |
| New-DlmDatabaseConnection | New-DatabaseConnection |
| New-DlmDatabaseDocumentation | New-DatabaseDocumentation |
| New-DatabaseProjectObject | |
| New-DlmDatabasePackage | New-DatabaseBuildArtifact |
| New-DlmDatabaseRelease | New-DatabaseReleaseArtifact |
| Publish-DlmDatabasePackage | Publish-DatabaseBuildArtifact |
| Register-DlmSerialNumber | Register-SqlChangeAutomation |
| Sync-DlmDatabaseSchema | Sync-DatabaseSchema |
| Test-DlmDatabaseConnection | Test-DatabaseConnection |
| Use-DlmDatabaseRelease | Use-DatabaseReleaseArtifact |
| Unregister-DlmSerialNumber | Unregister-SqlChangeAutomation |
| New-DlmManualDatabaseSchemaValidation | |
| Get-DependentProjectPaths |
I'm getting errors when trying to create a "baseline" for my deployment project. What's causing this?
When working with the SCA add-ins, the baseline represents the current, released version of the schema as a script directory. When you commit a change, SCA verifies the database by building the current version from the 'baseline script' and then running the migration scripts on it.
A common reason why this might fail is if the baseline script contains cross-database dependencies. SQL Server checks each referenced object when it executes the CREATE or ALTER statement, and this will cause an error if it doesn't exist. Other issues can cause this problem too, such as the presence of invalid objects. One way round this specific problem, often an issue with large, legacy databases, is to use a SQL Clone image as a baseline. This simply bypasses the need to build the 'baseline' database, and instead just verifies the new migration scripts by running them on the clone.
More generally, you can resolve "build blockers", such as mutual dependencies between databases in two possible ways. You can ensure that all dependent databases exist, either as clones or by restoring backups, or you can create 'stub' objects, in SQL Change Automation pre-deployment scripts, to represent the 'missing references'. The advantage of the latter solution is that it allows SCA or SQL Compare to work, whereas the former solution requires preliminary setup to establish the correct versions of a Clone images or database backups.
Why does SCA do so much checking of databases during a deployment?
Databases are unlike any other software system in that you can alter them just as easily as building them. An unnoticeable modification can radically change the way that data is processed with potentially catastrophic results. With the static approach, when you are simply updating a target database to have the same schema as the source, not a lot can go wrong; neither the source nor target database is likely to change its metadata during the update process, so the script is unlikely to fail for that reason. If SCA can't make the changes whilst preserving the existing data in the target, it will stop with an error and inform you.
Generally, however, SCA deployment involves using the migration script from the same release object on all the target databases of the same version. Before it can apply the script, it must, of course, check that the target is at the correct version (i.e. the version used to test the migration scripts).
A production system must also have checks to ensure that the version of the database that is delivered has the same code as the one that was tested, validated, and signed off for release. Therefore, after deployment, the whole database must be compared with the release to make sure they are identical.
Do I need to wrap the deployment artifacts up into a NuGet Build package?
Not necessarily. SCA is designed to fit in easily with a range of releasing systems and many of them use NuGet, particularly where the database is just a component within a broader application. The advantage of NuGet is that the contents are encrypted and can't be changed. Parts can't be lost or altered. It is used by several automated deployment and release management tools, such as Octopus Deploy, which can update databases to a specific version, remotely. However, it is also very easy to do deployments without having to write out the release object to file as a NuGet package.
Can SCA release a new version of just one schema of a large database?
If you're working on only one schema of a database, you need to tell SCA what the boundaries of your interest are. Unless you do so, it just guesses that you want the whole database released. To define the boundaries, you should use filters and options. Filters define the objects, or the types of object, to be included, whereas options can specify how they are used or scripted.
If you are interested in all objects within a schema, you need to set up a filter that just names the schema or schemas in which you are interested. Filters are defined in an XML file with a filetype of .scpf. They represent the full collection of database object types. You'll need SQL Compare to generate a filter. Here, in SQL Compare, I've opened the 'filter' pane and specified just the entire contents of the Person Schema in AdventureWorks. I could have just specified stored procedures, functions, views, and tables if I'd needed to do that.
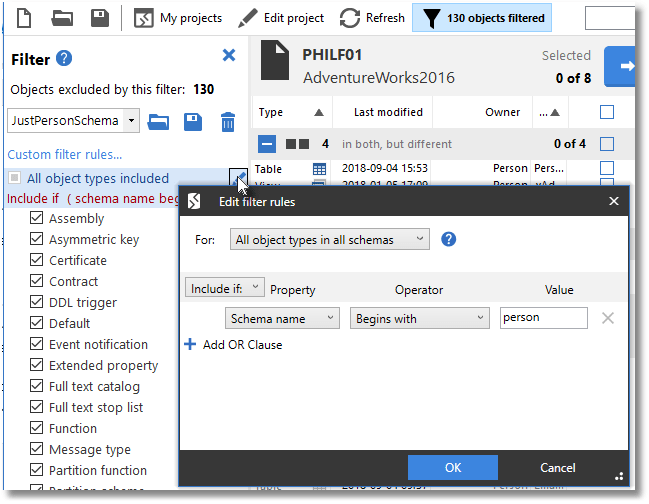
To create or edit a filter, open the Filter pane, and click the Edit Filter Rules button. In the 'For' box, make sure that 'All object types in all schemas' is selected. Make sure that 'include if:' is selected in the drop-down box. Under the 'Property' title, select 'Schema name'. under 'Operator' select 'Begins with' and under 'Value' enter the name of the schema you wish to include. See Using Filters to Fine-tune Redgate Database Deployments for more details.
If you deploy just one or more schema, but not the whole database, SCA will assume that all the dependencies are already in the target at the right version, and you just want to update the schema.
You specify the filter file in Invoke-DatabaseBuild to create a build artifact
When you specify the filter file in the New-DatabaseReleaseArtifact, this puts the filter into the release artifact so that only the schema is released. This will also tell SCA to use the filters for the pre-deployment and post-deployment schema checks; only differences between objects included by the filter will cause the check to fail.
If you specify the filter in the Sync-DatabaseSchema cmdlet, (-FilterPath <path to the filter file> it will be used in the sync operation. This will override any Filter.scpf file in the source project.
When I deploy a new version of a stored procedure, SCA drops and recreates it, which means I need to reset permissions. What can I avoid this?
This isn't SCA's default behavior, which is to use the ALTER command. It looks as if you have set the option DropAndCreateInsteadofAlter (Alias: dac) which tells SCA to replace ALTER statements in the deployment script with DROP and CREATE statements for views, stored procedures, functions, extended properties, DDL triggers, and DML triggers. You'll need to find out why this has been done and remove this from the script.
I'm getting a puzzling 'String_Split is an invalid object' error when deploying to a SQL Server 2017 instance. What's going on?
If you're using Invoke-DatabaseBuild as part of a deployment, then SCA uses the -temporaryDatabase that you specify as a parameter to verify the build, so it must also be at the correct SQL Server version, either the same or higher than the target. In this case, it must be at SQL Server 2016 or higher.
You probably haven't provided a parameter to the -temporaryDatabase parameter, so SCA is using your LocalDB. It is this database that is at the wrong level. You only need to use this cmdlet as part of a deployment if you haven't already tested the build by actually building the database.
I'm getting a weird error that talks about Readpast Lock. What should I do?
Aha, you've been trying to release a change to a replication object. The error for this looks a bit like this
WARNING: Error 'You can only specify the READPAST lock in the READ COMMITTED or
REPEATABLE READ isolation levels.' occurred when executing the following SQL:
ALTER TABLE [dbo].[Transactions] ADD [TransactionDate] [datetime2] NULL
It occurs because SQL Server specifies that, when you make changes to replicated objects, you must use either the Read Committed or Repeatable Read transaction isolation level.
In SCA, the default transaction isolation level is Serializable. To fix the issue, you must pass the value RepeatableRead to the -TransactionIsolationLevel parameter of the SCA cmdlet. This will tell SCA to alter the isolation level for the transactions used in the update script.
SCA is altering all the user permissions in staging and production and deleting the replication users. What should I do?
Why are your users in source control? Users are usually the responsibility of operations. You should be implementing role-based security, and preferably schema-based security. It is far better to have a clear split in responsibilities here. Basically, you can design the security system and allow the ops team to assign roles to groups. If you do this, all the assigning people to roles can be done in the Active Directory.
This means, in practical terms, that you exclude users from your deployment scripts by means of a filter that excludes the user objects from SCA's remit.
In the SCA PowerShell script that does the deployment, you'll also need to set the IgnoreUsersPermissionsAndRoleMemberships (alias -iu) flag in the New-DatabaseReleaseArtifact cmdlet. This cmdlet has a parameter called -SQLCompareOptions, and you just add that to the list of options. The IgnoreUsersPermissionsAndRoleMemberships flag ensures that user permissions and role memberships, are ignored in comparisons of roles.
The production database contains attributes related to replication that we can't include in the development project. How do I omit them?
Any DML triggers on replicated tables might need to have the NOT FOR REPLICATION attribute set on them. The same can apply to identity columns, and it is occasionally true of constraints in the replicated table. Ideally, these attributes should be set in staging, but there is no harm in having them in the development scripts if the reason is explained in the documentation. If these are set in staging and don't exist in development, then there is a danger that SCA will see the NOT FOR REPLICATION attribute on the replication objects within the target and over-write them. That is likely to break replication. To get around this, you'll need to use the IgnoreNotForReplication option but if you have check constraints and foreign keys that contain the NOT FOR REPLICATION statement in their definition, they will automatically be flagged by SQL Server as WITH NOCHECK. If this happens, you'll also need to use the IgnoreWithNocheck option to allow SCA to identify these objects as being the same.
Tools in this post
You may also like

Article
Database Delivery with Docker and SQL Change Automation
Phil Factor demonstrates how to integrate SQL Change Automation into containerized workflows, such as are typical of a microservices architecture. He shows how to automate database builds into a Linux SQL Server container running on Windows, and then backup the containerized database and restore it into dedicated containerized development copies for each developer and tester.

Article
What is SQL Change Automation?
This article describes the basic principles of SQL Change Automation, and how it works to provide a consistent and repeatable way of automating as much as possible of the database build, test, and deployment processes.
Article
Unearthing Bad Deployments with Redgate Monitor and Redgate's Database DevOps Tools
Sudden performance issues in SQL Server can have many causes, ranging all the way from malfunctioning hardware, through to simple misconfiguration, or perhaps just end users doing things they shouldn't. But one particularly common culprit is when deployments go wrong: I don't know a single DBA who hasn't been burned by a bad release.
Article
Simple Database Development with SQL Change Automation
SQL Change Automation makes automation simple enough that it can adapt to suit many different approaches to SQL Server database development. Phil Factor describes a project to update the Pubs database, using it in combination with a PowerShell function and to maintain in source control the build scripts, migration scripts and object-level scripts, for every version of the database.
Article
We don't need no documentation - automating schema docs in SQL Change Automation
“Understanding the existing product consumes roughly 30 percent of the total maintenance time.” Facts and Fallacies of Software Engineering by Robert L. Glass. You should be documenting your database schema. I know it, you know it. Having current, accurate documentation available accelerates time-to-resolution for faults, aids tech-to-business conversations, and is a regulatory requirement for a great number of firms. Yet a majority of 214 respondent to our survey admitted that while they didn’t always have up-to-date docs, they knew they should. Do you work in a US-listed organization? Sarbanes-Oxley (SOX) clearly requires up-to-date documentation on where the financial data resides within your firm and how it’s
Article
Simple SQL Change Automation Scripting: Connections, iProjects and Builds
Phil Factor delves into some of SQL Change Automation's data objects, or artifacts, covering the DatabaseConnection, iProject and iBuildArtifact objects. He explains the useful information they contain and how to use them in a PowerShell-automated database delivery process.
Loading comments...