





What’s the real story behind the explosive growth of data?
You may have read or heard about IDC’s recent Global DataSphere Forecast, 2021-2025, which predicts that global data creation and replication will experience a compound annual growth rate (CAGR) of 23% over the forecast period, leaping to 181 zettabytes in 2025. That’s up from 64.2 zettabytes of data in 2020 which, in turn, is a tenfold increase from the 6.5 zettabytes in 2012.
A single zettabyte, by the way, is equivalent to 1,000,000,000,000,000,000,000 (1021) bytes, or in easier terms to understand, about 250 billion DVDs, so that’s a lot of data.
But what’s causing the growth? Where will all of that extra data be stored? What will we do with it? How should we, as data professionals, prepare for it?
Let’s talk about data usage
Firstly, let’s take a closer look at data usage and see how it’s changed over time. Back in 2010, research from IDC shows that only 2 zettabytes of data was created and replicated worldwide but, as the variety and appetite for data increased, so did the speed of the growth of that data:
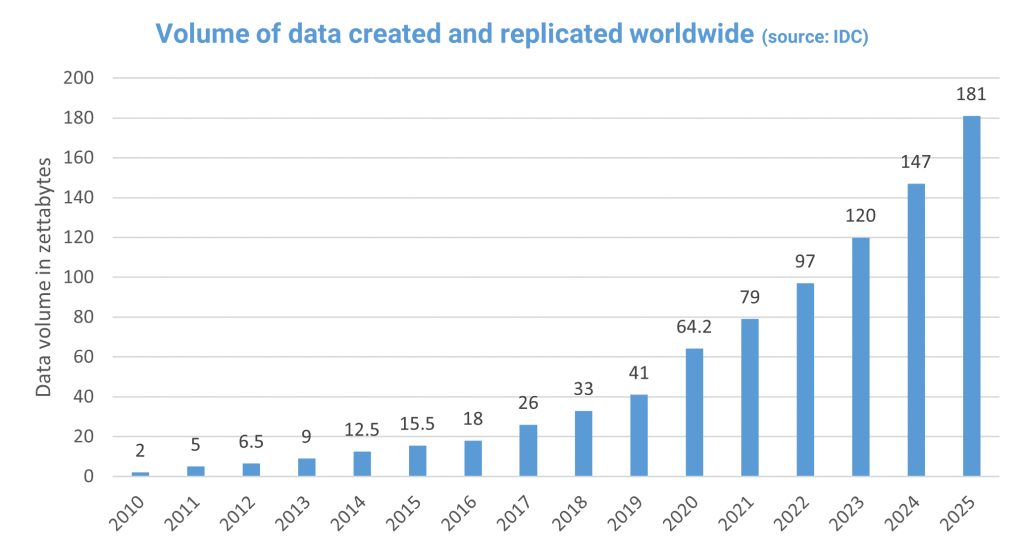
A key point to make is that while a lot of data is created and replicated, not a lot of it is actually saved. The jump that can be seen in 2020, for example, was caused by people accessing online resources from home for work, learning and entertainment, but less than 2% of the new data was saved. The remainder was created for immediate consumption and not stored for future use, or temporarily cached and then overwritten with more new data.
Let’s talk about data storage
Rather than looking solely at data usage, IDC’s DataSphere Forecast needs to be considered alongside its accompanying Global StorageSphere Forecast, 2021-25, which measures storage utilization and the amount of storage available each year. This shows that the installed base of storage capacity worldwide was 6.7 zettabytes in 2020, and IDC predicts a five-year CAGR of 19.2% over the forecast period:
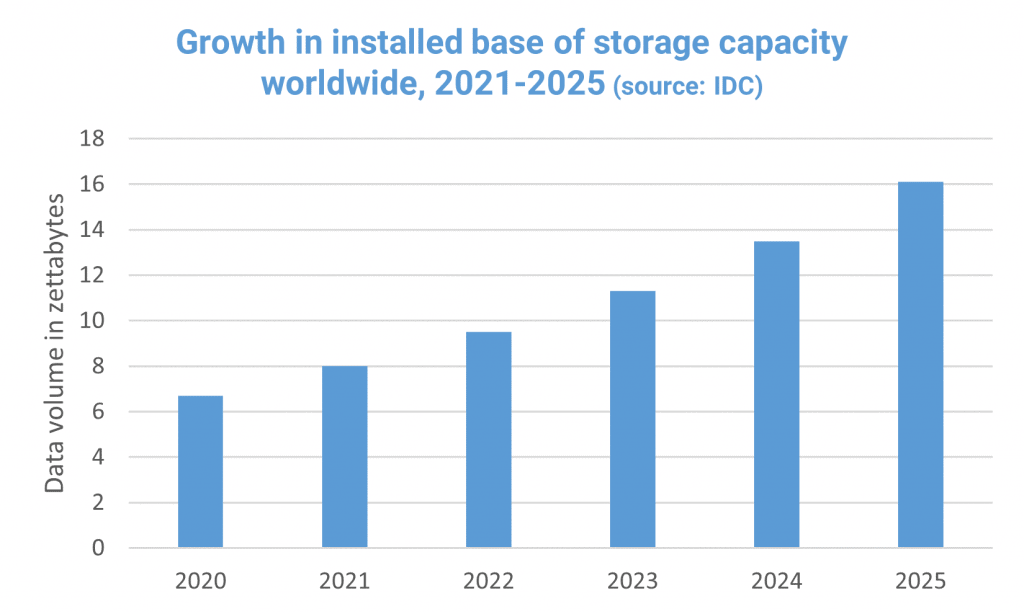
While this makes the huge growth in the amount of data being created and replicated slightly less worrying, it still means that over the next five years, storage capacity will need to increase by 240% (we’re talking about a compound annual growth rate here, remember). That’s a lot of extra infrastructure and servers to accommodate and, whether it’s on-premises or in the cloud, all of the data will need to be managed and monitored.
Let’s talk about where the data is
While data is growing in volume, the nature and location of data is also changing. Alongside structured data like relational and transactional data in SQL databases, there has been a meteoric rise in unstructured and semi-structured data, or big data, which has altered the data landscape.
IDC predicts that 80% of global data will be unstructured by 2025 because the way we use and consume data, and what we expect of it has changed. Rather than data being stored in fixed, known locations which can be controlled and managed easily, data is, literally, everywhere:
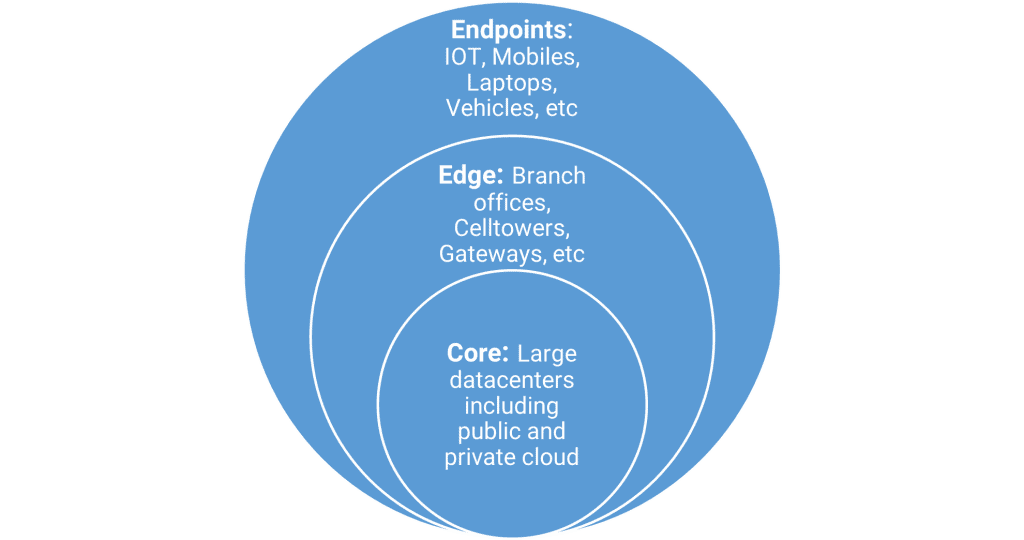
At the Endpoints are devices that sit outside the networks like mobiles, sensors, and IoT devices such as wearables. At the Edge are enterprise-hardened servers in locations like regional offices, and smaller datacenters located to maintain response times or meet local data privacy requirements. At the Core are enterprise and cloud provider datacenters where most of the processing and analytics work goes on.
There is some order to this structure, with raw data flowing from Endpoints to the Edge for analysis, before going deeper into the core for further analysis. IDC predicts data collected at the Edge through various IoT and sensing devices will grow at 33% annually and will make up 22% of the total global datasphere by 2025.
Just as enterprises already use data warehouses to analyze structured data, they are now turning to data lakes to analyze unstructured and semi-structured data. While relational databases remain the most popular category of database, scoring 72.4% in the September 2021 rankings on the database ranking website, DB-Engines, other databases are now being introduced alongside them to handle that big data.
The result of all of these changes will be a shift from consumers holding data at Endpoints to data being centralized in the Edge and Core, with enterprises responsible for its creation and storage. As Seagate reveals in its Rethink Data report, nearly 80% of data will be stored in the Edge and Core by 2025. In the same report, IDC also predicts that 12.6 zettabytes of installed capacity like HDD, flash, tape, and optical drives will be managed by enterprises, with cloud providers managing 51% of the capacity.
Summary
Data growth is coming, as is a change in the way organizations collect, analyze and store data. We’ve seen that a large part of the volume of data created and replicated isn’t saved, yet it still leaves a sizeable portion that is. Much of it will be in the cloud, but enterprises are facing a wave of data heading for them too.
 At Redgate, we’ve been following this growth and the subsequent increase in the size and complexity of database estates over the last four years with our regular State of Database Monitoring survey.
At Redgate, we’ve been following this growth and the subsequent increase in the size and complexity of database estates over the last four years with our regular State of Database Monitoring survey.
We recently took a deep dive into the latest survey data and produced an insights report, ‘The real-world challenges of growing server estates’. It goes behind the headlines and looks at the issues the constant growth is causing, how organizations can deal with them, and offers inspiration from companies that are already managing growing estates and thriving.
Download your free report to find out more.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Read next
Blog post
The importance of monitoring your SQL Servers
Without a proper SQL Server monitoring system in place, DBAs can find they never have the time to implement new processes because they’re bogged down with too many daily checks, and other painstaking investigatory tasks. On top of this, they’re continually firefighting problems that are surfacing instead of being able to spend time finding and fixing the root causes, and they don’t readily have the answers available when something goes wrong. What are the red flags you should look out for? You’re short of time SQL Server monitoring with custom scripts is very time-consuming. For a large estate it can

Product learning article
Scaling Redgate Monitor to Large SQL Server Estates
Tony Davis describes the features and capabilities of Redgate Monitor that allow it to scale smoothly to monitor a growing estate of servers and databases, while still providing a single, simple dashboard that gives the team all of the essential SQL Server metrics and alerts, establishes baselines, and detects trends in behavior.
The real-world challenges of growing server estates
The State of Database Monitoring Survey, Insights Report
Now in its fourth year, Redgate’s 2021 survey on The State of Database Monitoring received more responses than ever. We’re publishing four insight reports on the common themes that emerged in the results.

Tools in this post
Redgate Monitor
Real-time multi-platform performance monitoring, with alerts and diagnostics
You may also like

Blog
To learn and improve, we cannot be afraid to fail

Blog
Loading comments...