





Loading data into SQL Data Warehouse
In this step-by-step guide, we’ll be walking through the process of moving data from an on-premises SQL Server to Azure SQL Data Warehouse using the Copy Data feature in Azure Data Factory. The use case we’ll focus on is the first-time loading of data.
A note to Data Platform Studio users
| Data Platform Studio is no longer available as a service. We’ve prepared a step-by-step guide to loading data into Azure SQL Data Warehouse. Read on if you’d like to find out more about this decision.
In 2016 we released Data Platform Studio (DPS) to help people shift data into an Azure SQL Data Warehouse from an on-premises SQL Server database. DPS did this in the Ingeniously Simple fashion that you’ve come to expect from Redgate. Prior to DPS, moving large volumes of data from on-premises SQL Servers into Azure SQL Data Warehouses was a significant undertaking. It required an in-depth understanding of BCP, PolyBase and data type differences between two quite different database technologies. With DPS, your first data load could be completed within a few clicks and – depending on the volume of data you were moving – you could quickly get a feel for what Azure Data Warehouse could mean for you, using your data. In those three years we’ve significantly accelerated thousands of those SQL Data Warehouse proof-of-concept projects. It’s a piece of software we’re proud to have worked on. Today, we’ve taken the decision to close down the Data Platform Studio service. Within the past three years the native capability of Azure has grown to encompass this activity. While the process isn’t as neat as DPS, it is more powerful and, moreover, sets you up for more operational activities beyond your first data load. Any meta data DPS stored will be available for 1 month from the date that this article was posted and then dealt with according to our policy on data privacy and protection. If you have any questions, you can contact the team directly via dps@red-gate.com. To everyone who used DPS, thank you. We enjoyed working with you to build and improve the service. The DPS team. |
Approach
Pre-requisites:
- A Microsoft account and an Azure subscription
- An Azure SQL Data Warehouse. Example uses a Gen1 set at DW100.
- An existing Storage account. Example uses Storage (general purpose v1)
- An on-premises SQL Server database. Example uses AdventureWorks2014 on SQL Server 2014
Process
- Log into https://portal.azure.com and create a Data Factory; click + Create a resource, search Data Factory, click Create and follow the instructions.
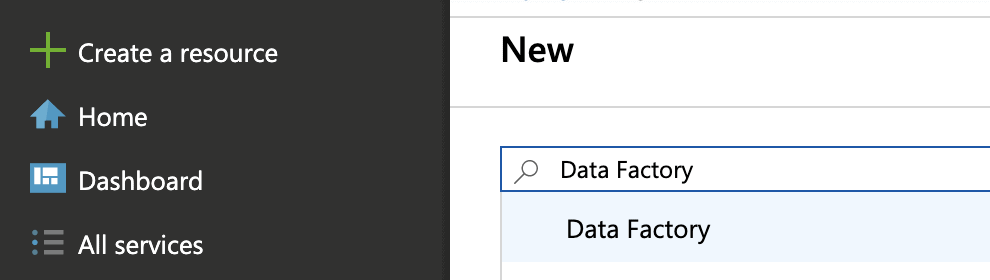
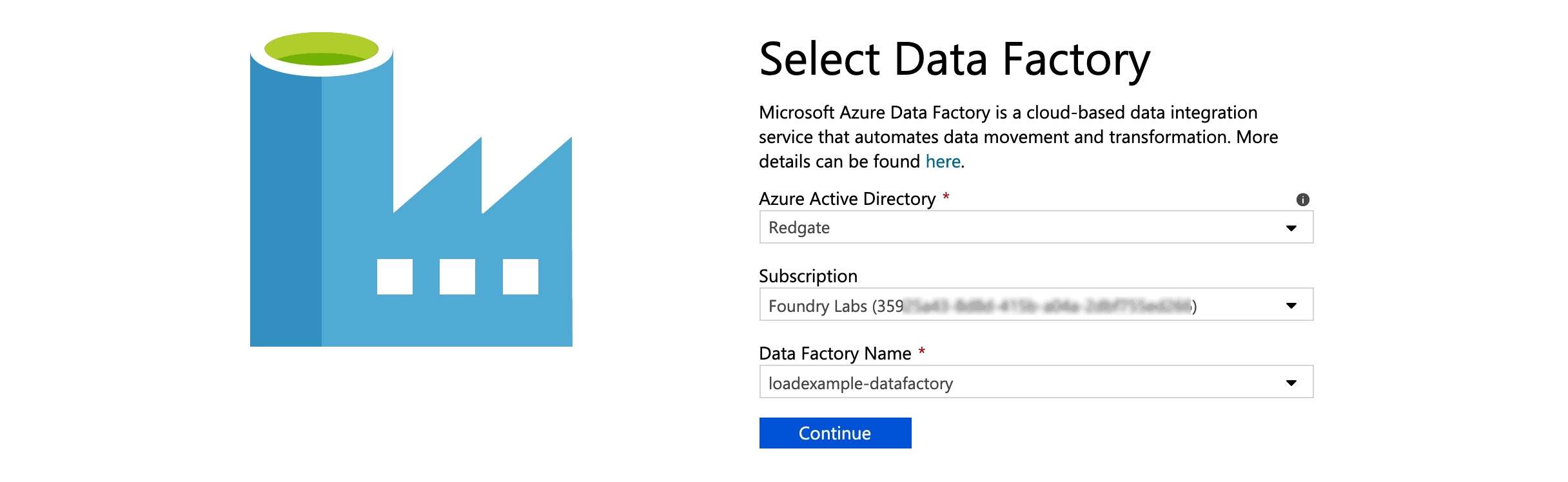
- Log in to Azure Data Factory at https://adf.azure.com and select the Data Factory you created.
- Navigate to Overview in the left hand menu and click Copy Data.

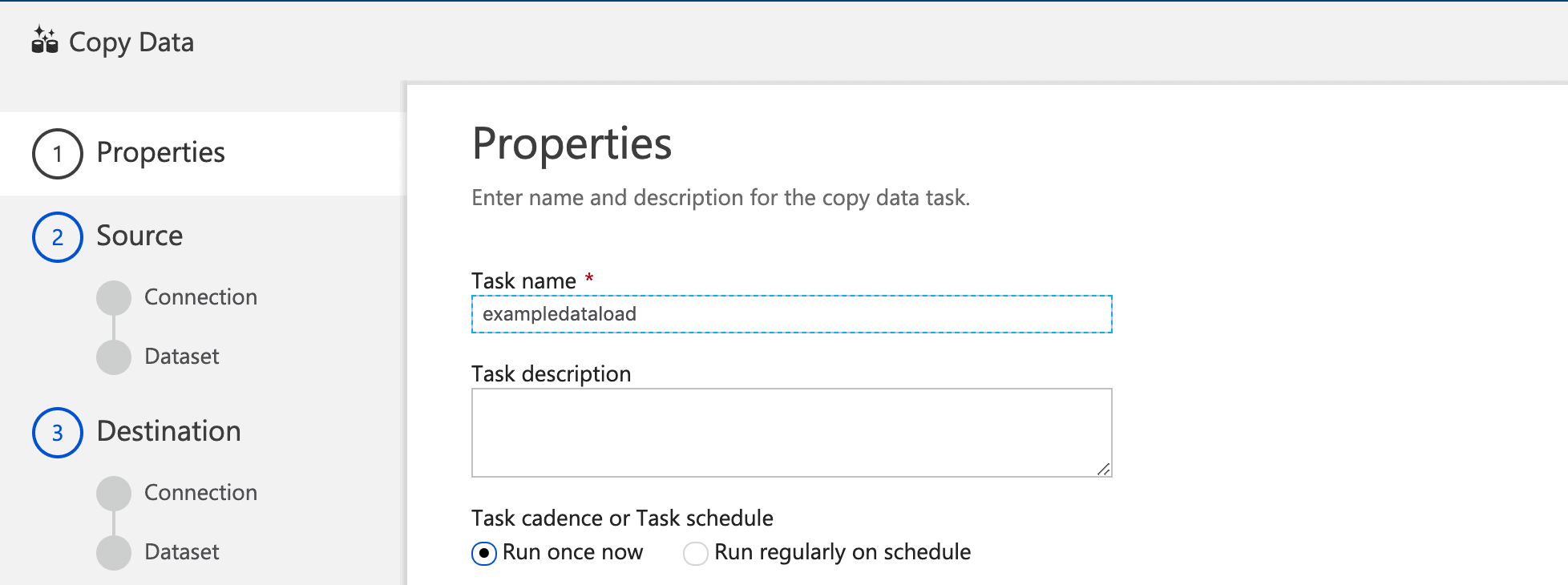
- Enter a name and a description, select the Run once now option and click Next.
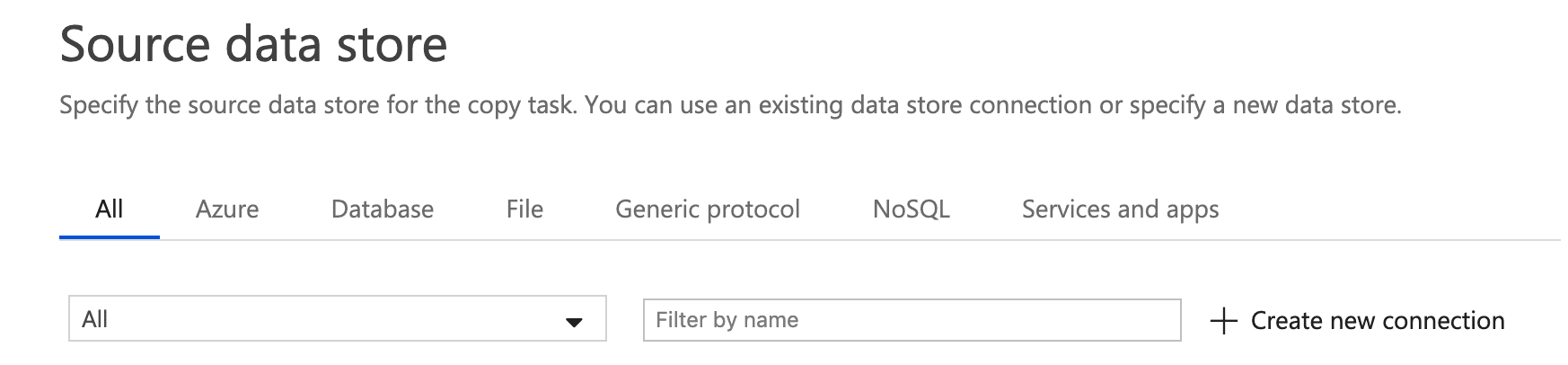
- In Source Data Store, click Create new connection.
- Select Database and type down to find SQL Server. Select it and click Continue.
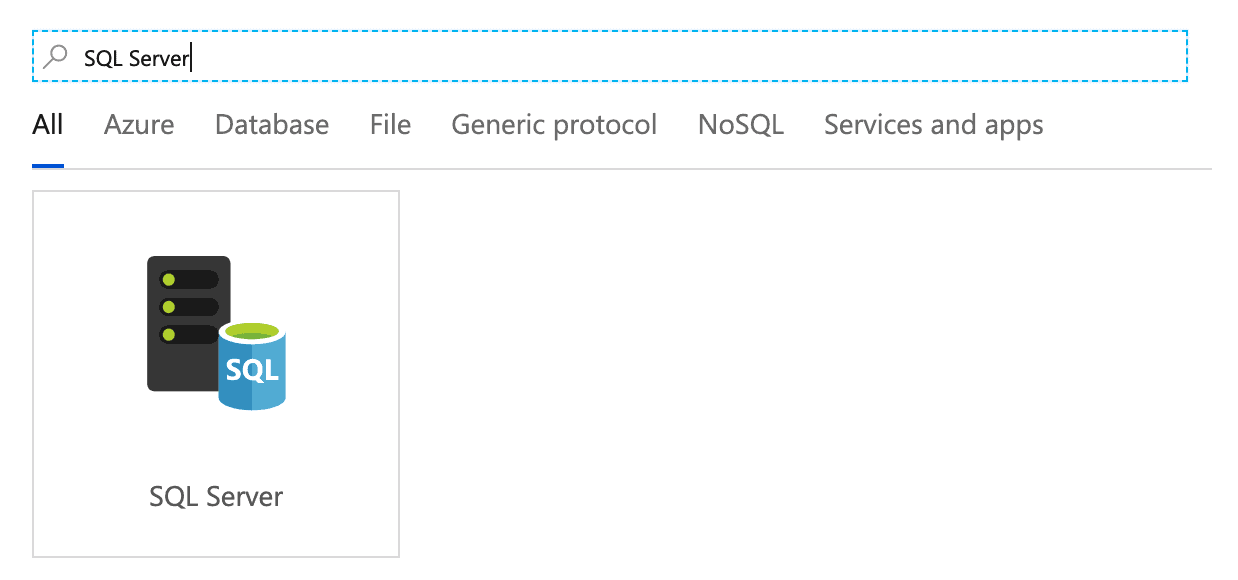
- Give the Linked Service a name and select + New from the Connect via integration runtime drop-down.

- Select Self-Hosted, then click Next.

- Give the Integration Runtime a name and click Next.

- Choose Option 1: Express setup and click the link to launch express setup.

Note: here we’ve made the assumption the machine on which you have created the runtime has network access to the SQL Server you wish to upload to SQL Data Warehouse. - Run the .exe file and follow the install process. Confirm installation was successful by double-clicking the integration runtime in your system tray.
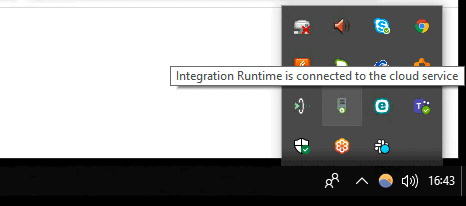
- Back in ADF, click Finish to exit the Integration Runtime panel.
- In the New Link Service (SQL Server) panel, type the name of the server and database you want to load into Azure SQL Data Warehouse, followed by the username and password (selecting your preferred authentication type), then hit Test connection to check everything is fine, followed by Finish.
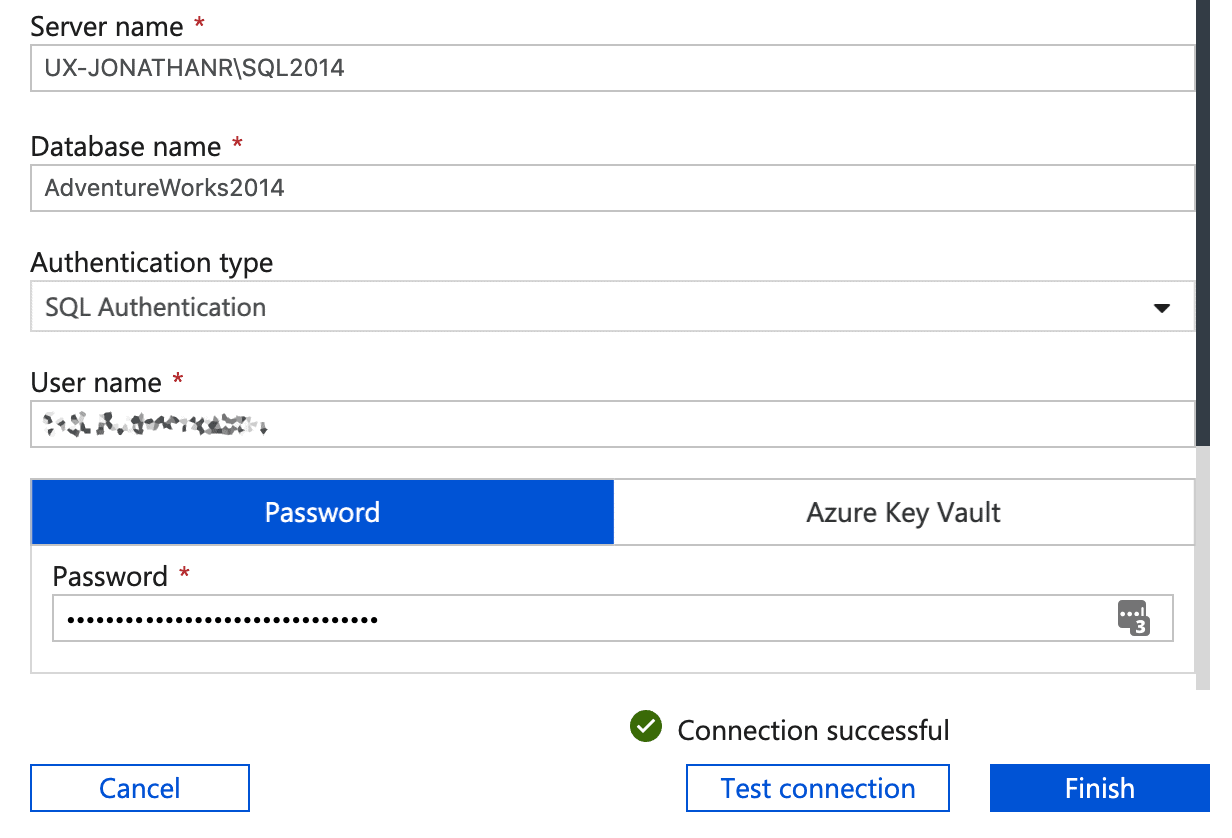
- Your on-premises SQL Server is now available as a Source data store. Select it and click Next.

- Select the tables you wish to upload and click Next.
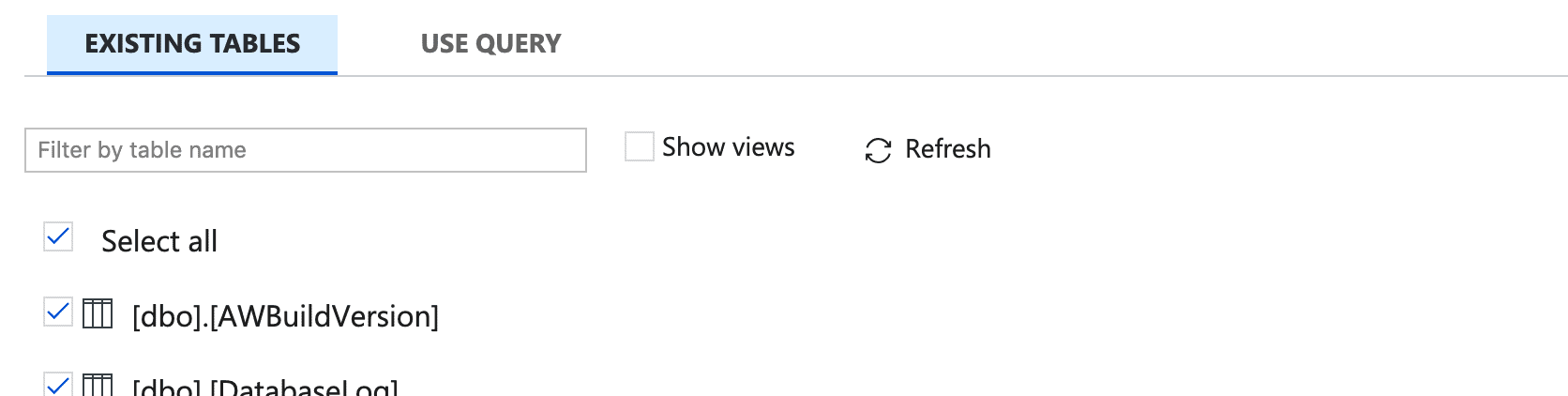
Note: the following steps assume you have already created a SQL Data Warehouse in Azure and that you have added your machine’s IP to the whitelist under ‘Firewalls and virtual networks’. - In the Destination data store panel, click + Create new connection.

- In New Linked Service type down to find Azure SQL Data Warehouse, select it and click Continue.
- Give the Linked Service a name and, in Connect via integration runtime, ensure AutoResolvingIntegrationRuntime is selected.

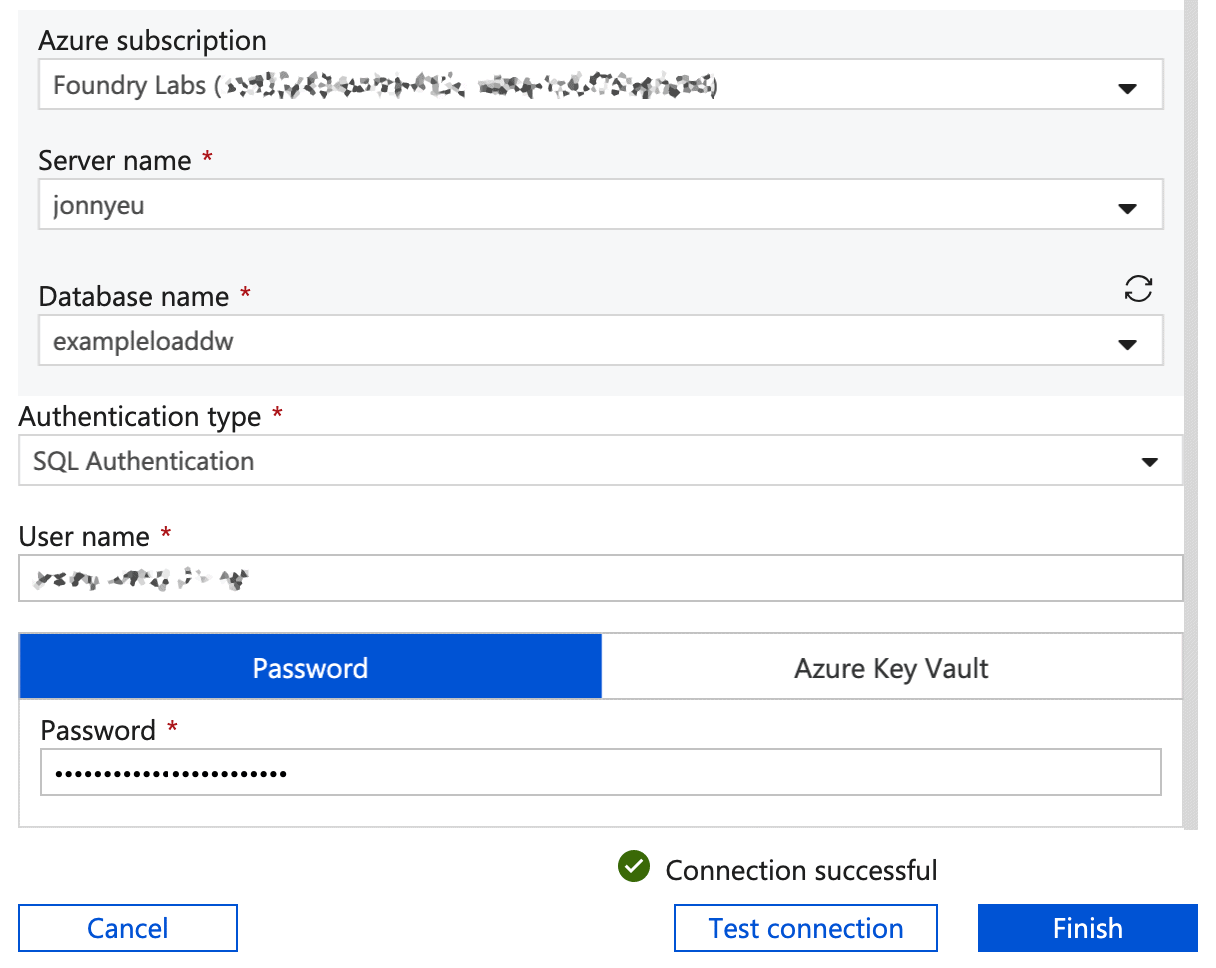
- Select your ‘Azure Subscription’, ‘Server name’ and ‘Database name’. Under authentication type, select SQL Authentication, entering the username and password for the server on which your SQL Data Warehouse lives. Click Test connection to check everything is fine, then Finish.
- Back in Destination data store’, ensure the Azure SQL Data Warehouse you just connected to is selected and click Next.

- In the ‘Table mapping’ panel, click ‘Next’.

- In the Column mapping panel, review any warnings. In this example we leave problematic columns (eg.unsupported types) selected. Once you’ve done this, click Next and wait.
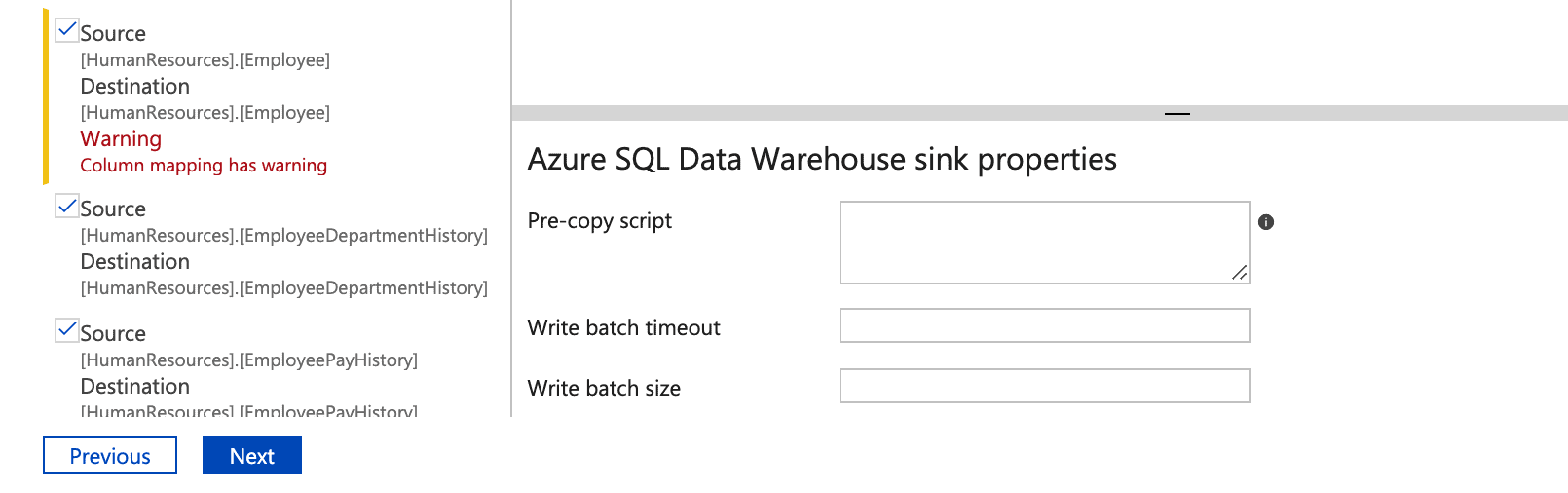
- In the settings panel, under fault tolerance select Skip incompatible rows.

Note: In this example, the import will succeed with the exception of incompatible rows. How to make incompatible rows compatible isn’t in the scope of this guide. - Under Performance Settings, for Staging account linked service choose + New next to the Staging account linked service option.

Note: the following steps assume you have already created a Blob Storage Account - In the New Linked Service panel, give the linked service a name, and make sure the integration runtime you created earlier (and installed on your local machine) is selected in the Connect via integration runtime dropdown. Select your Azure subscription and Storage account.
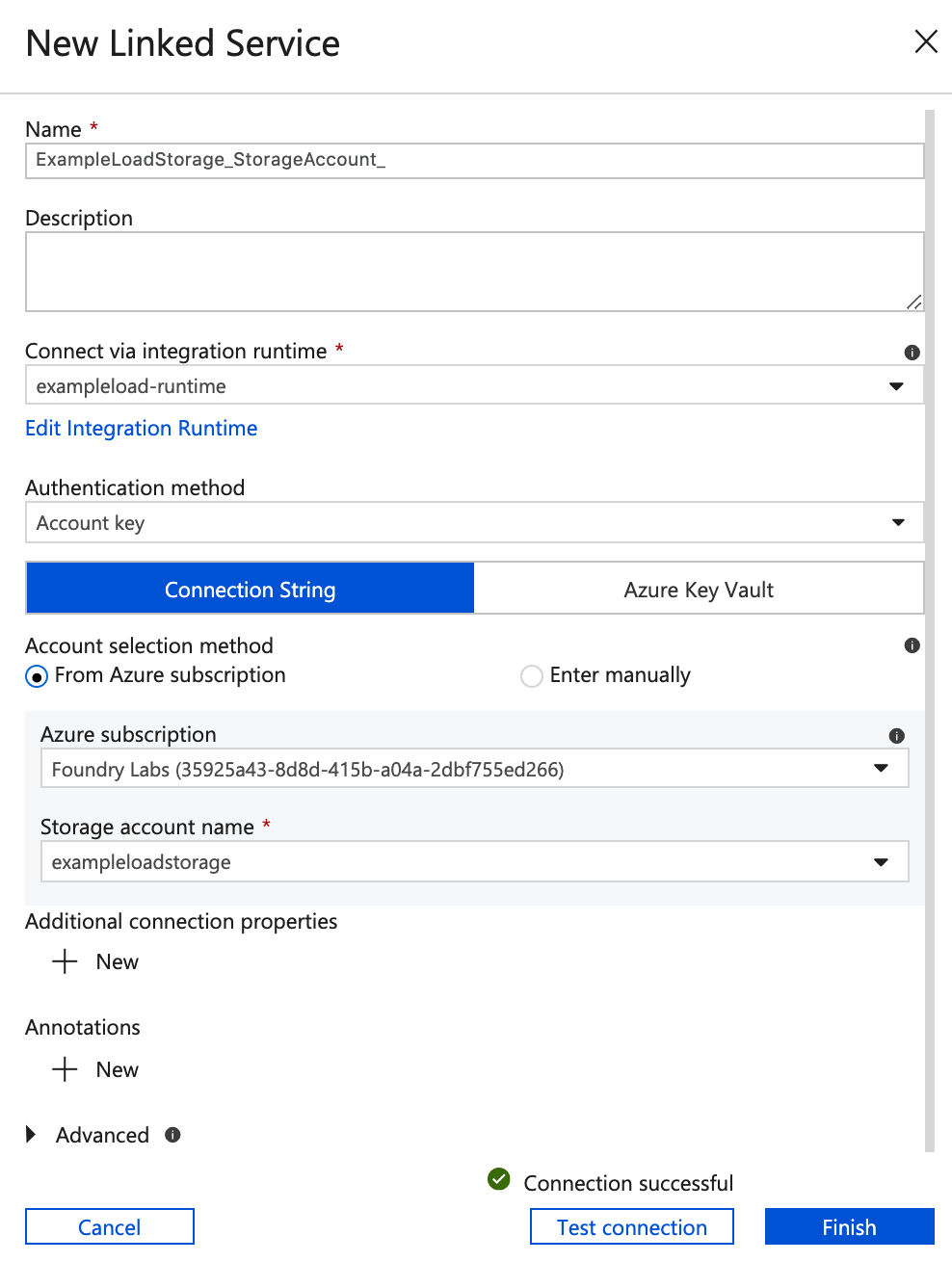
- Click Test connection and if everything is fine, click Finish.
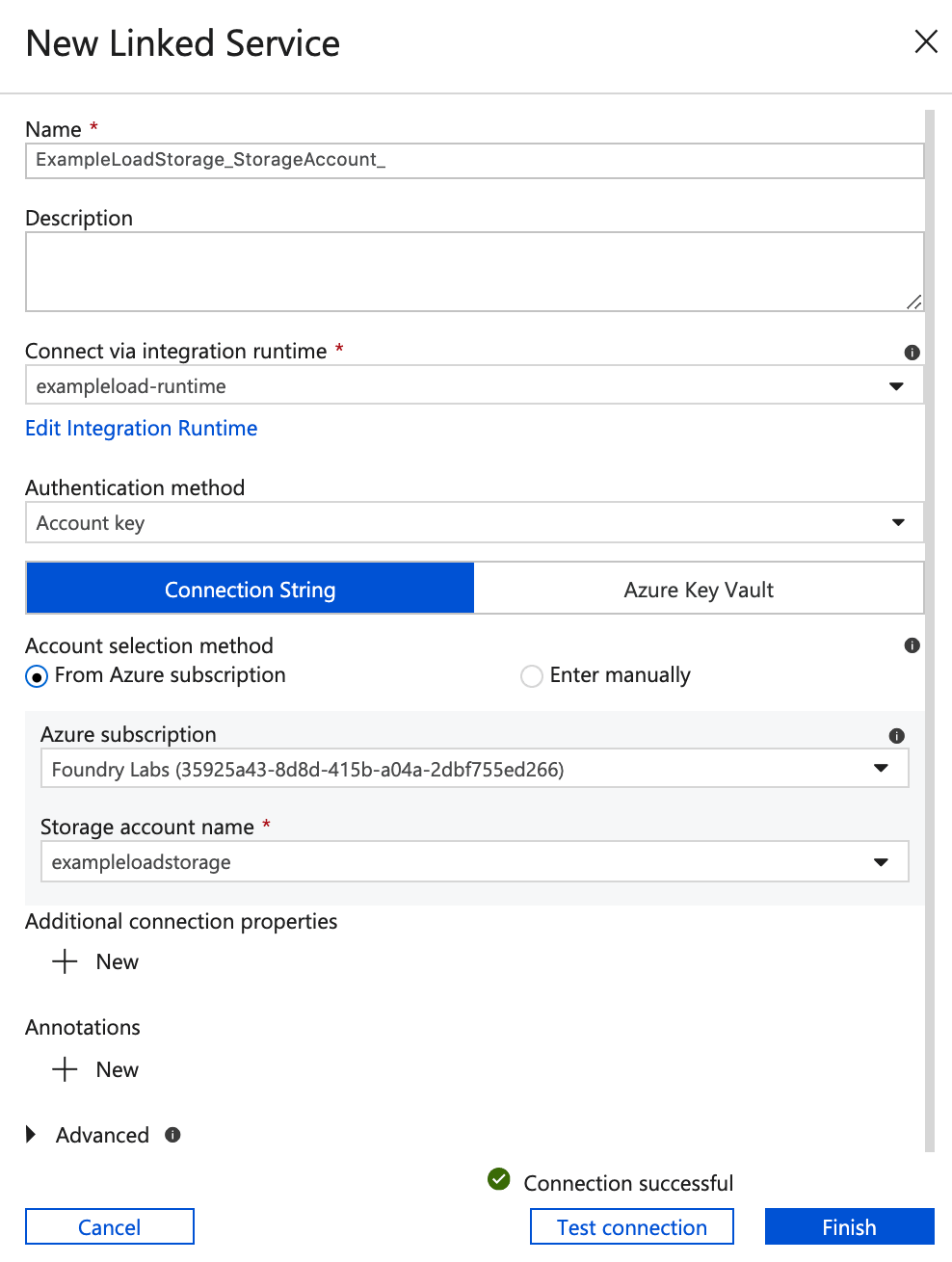
- Review the Summary and click Next to begin the upload.
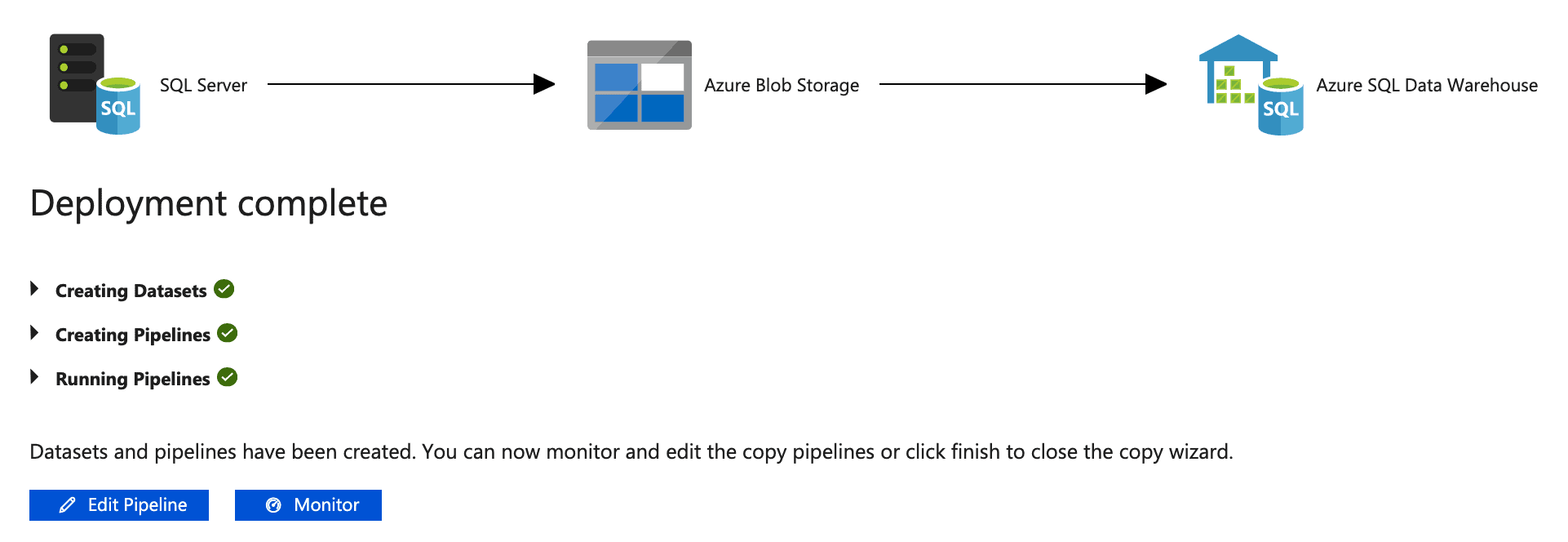
- You can monitor your upload by clicking the Monitor button, which will give an overview.

- You can choose to view more detail by selecting ‘View Activity Runs’ under in the ‘Actions’ column
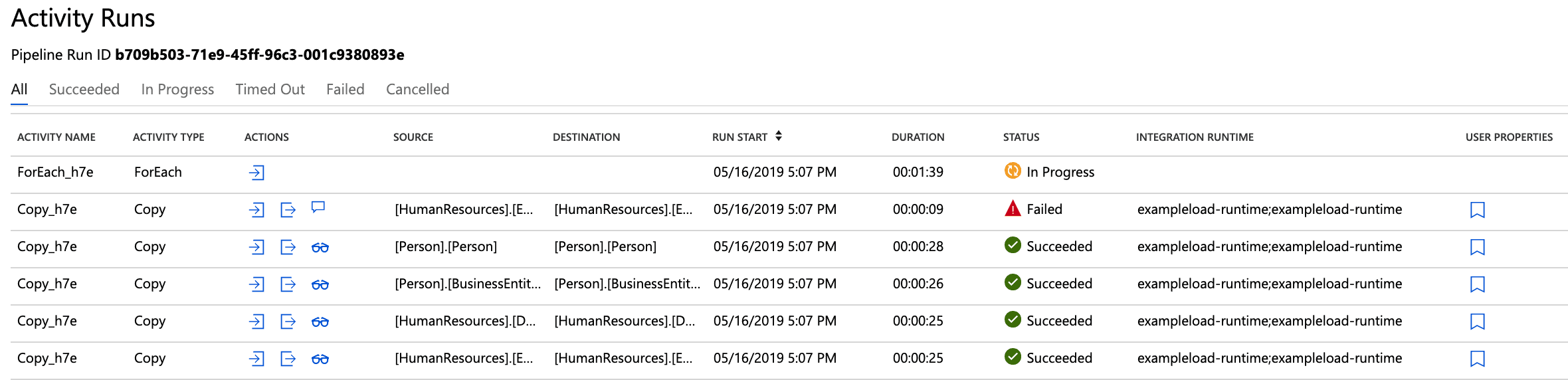
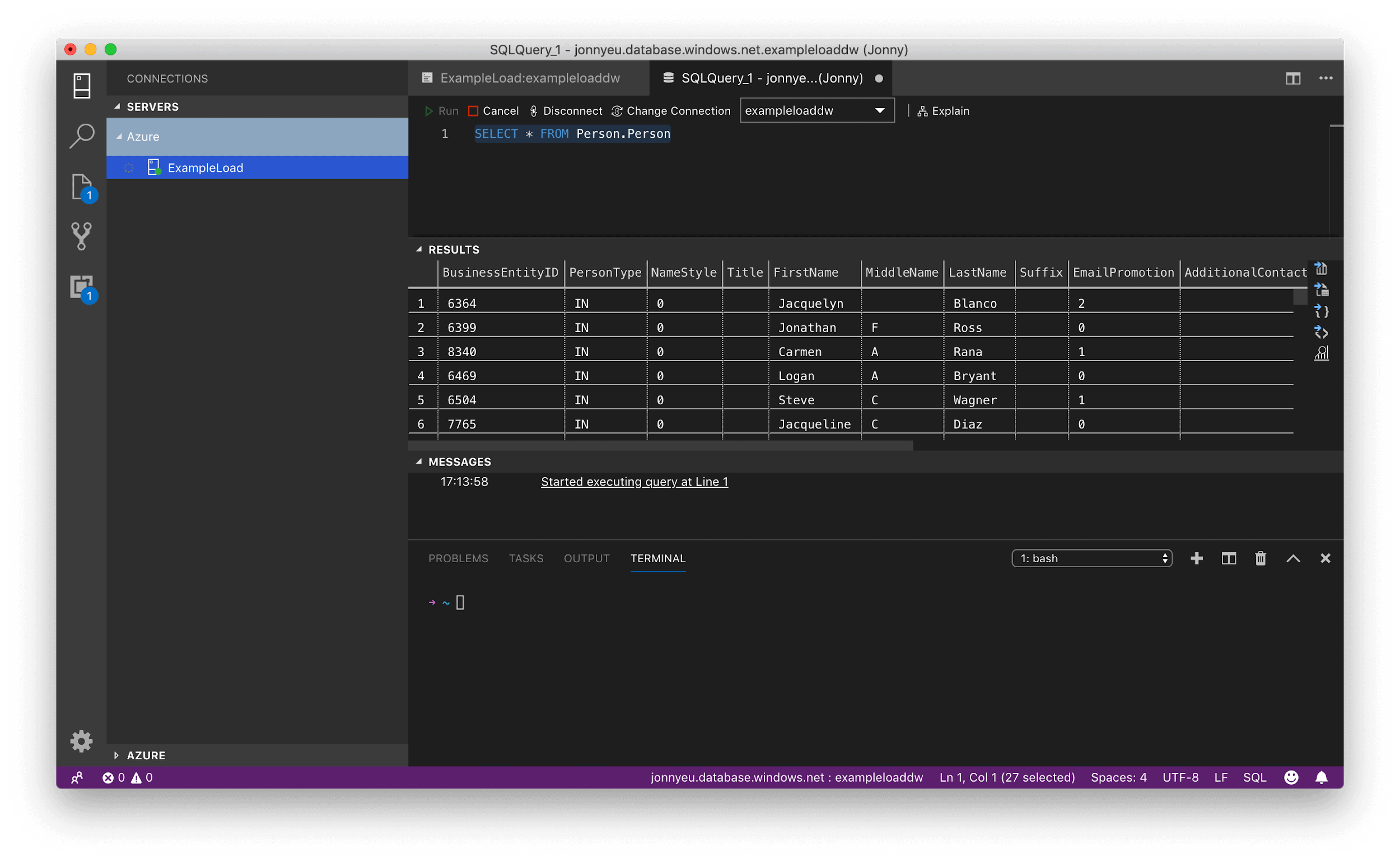
- Once complete, connect to your Azure SQL Data Warehouse and run a query.
You may also like

Blog
Why database ownership is so fragmented in 2026 - and what you can do about it

Blog
SQL Prompt Product Updates – May 2026
Blog
Loading comments...