





Welcome to the new world of curating data, not owning it
Faced with the new challenges of data protection – and increased levels of oversight – many of us working with SQL Server have come to the same conclusion. Quite simply, the column names and free text descriptions available to us to describe the data in our care (or data-containing artefacts like columns, tables and databases) are no longer sufficient.
We need to more accurately classify, map, tag or catalog data in order to support automated behaviors, simplify decisions, and – most importantly – tell others how we are handling precious assets. They can then be confident we’re doing the right things, and our actions are aligned with their priorities.
But how? What is the simplest slice of tagging, etc, that we can apply to data to achieve the desired outcome? Is it a label or tag on a column? Or is it a catalog of information that can be tied to that column, wherever it may be?
Museums and art galleries have been using both catalogs and labels for some time and there are numerous guides that show how they have solved common problems around record keeping and context, some of them quite charming.
As I read the simplest guides I could come across, I felt the parallels with the challenges faced by data professionals were ever more striking. So much so that in this new era of regulatory scrutiny, we would be wise to think of ourselves as the curators of data rather than the owners. We would be well advised to develop the same kind of curatorial mindset the fourth edition of The Small Museums Cataloguing Manual advises:

Truly, there is nothing new under the sun.
That said, however, what’s in a catalog that isn’t in a label?
The location and history of the object, perhaps, possibly including labels used previously. The catalog for a vase in a museum, for example, might contain an entry along the lines of: Previously described as an Etruscan vase in the 1918 exhibition at The Royal Academy.
The policy on how the object is handled should also be included. For our vase, that might be: Must not be exposed to direct sunlight. Further clarification could also be required, like: Direct sunlight is defined as an excess of 10,000 lumens per square foot.
A description of the lineage or provenance of the object would add more value to the catalog, as would any other information that would help understand it, like a map showing where the Etruscan vase was made in ancient Italy.
If you’re wondering how this talk of a museum vase relates to the way organizations handle their data stores, this second quote from the cataloguing manual will explain:

So the more detail we append to the data we store, the better we are able to protect it. Just like museum curators, however, we data professionals can’t spend all of our budget on protecting items that are of only trivial importance and easily replaced.
A Victorian clay pipe (my garden in London is full of them) might be worth exhibiting, but it’s not worth surrounding by high-tech defenses like those used for the Crown Jewels. Likewise, many organizations are reluctant to buy enterprise software for advanced encryption handling to enable developers to test database changes.
A sensible approach to making these decisions upfront is simply good use of time and budget. I might, for example, use coarse-grained labelling rather than fine-grained when I want to perform bulk operations in the name of efficiency.
Take a museum collection being packed in a shipping container to exhibit in another country. It needs to be labelled to determine the delicate transportation and handling it requires, based on a knowledge of the content, but that labelling is at the higher level of the shipping container, not the individual items in the collection.
Similarly for a database, my backup and retention policy should be guided by specific data requirements, but applied at the database level (see the principle of minimization in the GDPR).
So what does all this mean for applying appropriate protection policies for databases? What goes in the catalog, and what in the label? How do they interact with each other? What are the challenges?
A common problem we’re hearing about with databases, for example, is that labels can’t be applied to the extended properties of a column, because the schema is not under the control of the DBA.
The data is still her responsibility, but adding an extended property is changing the schema, which is either specifically prohibited as part of a support agreement, or vulnerable to conflicting schema changes when the vendor applies the next update.
Considering the analogous requirements for which the techniques of cataloguing were developed for museums, they really can help us to resolve issues like this and protect our data while controlling costs and implementation effort.
All of which makes the case for having both a catalog and labels for data compelling.
A catalog helps us form a rich view of the whole. That might include visualizations, tools for search, plain English explanations of complex concepts.
Policy should live in or near the catalog, stated with enough detail to resolve ambiguities like what ‘full daily backup’ actually means to our own organization. We should also be able to evaluate the impact of policy changes on the whole, like how many databases are running on availability groups, and how many have legacy versions nearing the end of support. History, lineage, and change over time properly belong at this level as well.
Labels have a special role to play as well. They travel with the object and provide a quick reference to inform the consumer (or user, or handler).
Here’s a sketch of a possible breakdown between labels and catalog entries for relational database concerns:
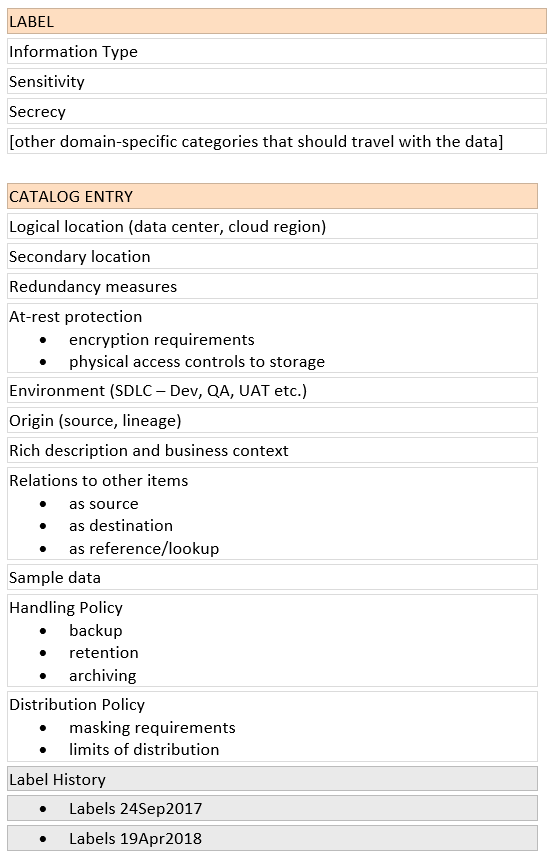
And finally, a word on lost or orphaned records from University College London’s museums and collections blog:

Apply the same thinking to data and suddenly the value of catalogs and labels becomes even more apparent.
You can find out more about keeping sensitive data secure on Redgate's Data Privacy and Protection pages.
If you'd like to gain a deeper understanding of the GDPR, you can also read Richard's four-part series on the topic:
Part 1: So what is GDPR, and why should Database Administrators care?
Part 2: So what is GDPR, and why should your customers care?
Part 3: So what is a Data Protection Impact Assessment and why should organizations care?
Part 4: So what is data mapping and why is it the key to GDPR compliance?
This article was originally published on Dataversity on 8 June 2018.
You may also like

Blog
Test Data Management and SOC 2 Compliance

Blog
The Complexity Rebound

Blog
A quick guide to the New Zealand Privacy Act 2020 for DBAs

Blog