





The Data Catalog comes of Age
Nowadays, it isn't just banks and multinational corporations who have to be rigorous about data. Even modest organisations who would previously been unable to afford the storage, tooling and processing power required, now have sophisticated data processing capabilities within their reach. Like the superhero of the comics, with such power comes responsibility; companies soon reach the point where discipline, rigorous practices and good tools are required to support their data ambitions. However, not all organisations are quick enough in picking up the mantle of responsible data curation.
The better a business understands and trusts its data, the more it can use it, and the more opportunities there are for it to generate revenue. You cannot use a data source you know nothing about, and if you know it exists you need a detailed knowledge of what it contains. This, of course, is the role of a data catalog. This article will review what's required of a data catalog, and what needs to be in place, within the organization, for it to succeed and evolve in a way that will fully support their business.
The Data Governance Debt
An aggressive start-up company entering an immature market gains market share by favoring informality and ad-hoc processes over disciplines and governance. The company is energetic. The individuals and structures, which will eventually grow into departments, have great freedom to pursue their own path, and that freedom is resulting in rapid progress. However, if the 'Governance Debt' isn't paid off, it is ultimately self-limiting. This is the most insidious of debts and can lead to spectacular and expensive corporate disgrace.
This is the time to catch up with issues of security, auditing, compliance, resilience, change control and data integrity. Unfortunately, you can't do this rapidly or effectively if you don't know where your data is, what it is, or what transformations happen on that data.
Many companies reach late adolescence but fail to realize how important it is to then make the cultural shift from an adhocracy to a more mature and responsible way of working with their data. Few who make this mistake survive the transition.
This potentially dangerous state of data agnosticism is not just a problem with the start-up. A more traditional company in a mature market can also lose track of their data, but for different reasons. It may seem that the company is mature, has processes and disciplines even if they are a little bureaucratic. An outsider will see 'fiefdoms' where decisions are taken for the serendipitous but uncoordinated benefit of the individual departments. What causes this? It may be the effect of mergers or take-overs, or of wild-west management. You will recognize such a company from its IT. Different systems and applications will be bought to suit the individual departments with scant thought to the needs of how such systems should or even could talk to applications used by others.
For either company to grow beyond such limitations they must embark on a journey of self-discovery about the way data is kept, used and processed within their organisation.
Discovering and understanding your data
To begin this journey, an organisation must start by investigating and capturing a deep understanding of its own processes, core data entities and its internal language and terminology for the organisation's activities. This can clear up some bewildering misunderstandings. It is common, at this stage, to discover that the description of a fundamental entity such as "Customer" is not as clear-cut as might be supposed. For example, a customer might be any of the following:
- A person who has accepted a quotation for an order
- A person who has placed an order
- A person who has received an order
- A person who has paid for an order
Because pay and bonuses may be determined by the successful recruitment of "Customers", one must expect intense and lengthy debate to thrash out an agreed definition for this and other terms. This process, and the value of its output, must be championed at the highest levels of the organisation and must become the lexicon of that organisation. Senior management plays a crucial and ongoing role in ensuring that this ontological bridgehead is not surrendered and becomes the core of the business glossary.
The organisation must establish and agree on a business glossary before any attempt is made to build a conceptual business model of the enterprise. The purpose of any model is to communicate an understanding of the thing it is supposed to represent. As those understandings coalesce, and agreement is reached the model will change to incorporate those understandings. A measure of the success is when the organisation routinely uses the language of the model and in the correct context. An example might be the recognition that there is a distinction between a "product" which is a thing that is stocked and a "proposition" which is the price at which a product or collection of products is offered. A model that does not communicate a shared understanding is a failed model.
The business model will evolve as a shared understanding of the business processes develops. In this way, the model enables growth of the organisation, from which will come change, which will drive evolution of the model.
In turn, the conceptual business model provides the basis for more detailed logical models and down further into the physical models, implemented on whatever technology is chosen to hold the data. Both the conceptual and logical models should be technology-agnostic and should model a thing as it is, rather than the purpose to which it is to be put. In the data warehouse world, Kimball warns explicitly against modelling for a desired report, and instead modelling the business process. Failure to do this has two outcomes:
- The resulting model will most likely be fit only for a limited purpose. It will be a "stovepipe" solution.
- The model will tend to accumulate attributes that are too specific to the output of a limited purpose, and the mechanics of producing that output.
The business glossary, conceptual and logical models are the cornerstones on which a data model can be derived. From this model, a data catalog is built.
Building the data catalog
A data catalog makes data sources easily discoverable; it provides the metadata that describes exactly what data they store. It allows for classification and labeling of any sensitive data in your databases. It must be fast, contend with the classification and inventory metadata of many different data types, and support the increasing sophistication of data processing requirements within an organisation, which are being driven by, for example:
- Adoption of more varied data technologies into the corporate portfolio
- Cheap storage and pay-as-you-go processing from cloud vendors
- Collaboration and data sharing between partnering organisations
- The adoption of NOSQL solutions
The data catalog must support both existing business processes and provide a useful resource in designing new processes.
Data Catalog Business Benefits
The data catalog is an information resource whose benefit lies in increasing certainty for a business initiative; making it easier to cost out accurately, and reducing the perception of risk
By communicating an agreed understanding of its data, it builds trust in the corporate data asset, and draws attention to opportunities for that data that have the potential for use to generate revenue. Having such information at the fingertips of a business user represents an opportunity, whereas a painfully slow 'data archaeology' and data discovery process represents a threat.
Stakeholders, data stewards and curators
Experience tells us that organisations descend to the lowest level of adherence to existing policies and standards that management will tolerate. Like any other standards, a data catalog must have champions and stakeholders who are in senior positions within the different organisational areas. The champions and stakeholders must do what Patrick Lencioni describes as overcommunicate clarity. Their task is to emphasize the way in which the data catalog can, will and does help the organisation.
The data stewards and curators should be subject-matter experts in the various data sources and systems within their area. Their responsibilities include:
- Documenting data lineage
- Implementing data quality rules
- Compiling any additional information that, in handling the data, can increase the return on investment
- Ensuring the integrity of the data
- Clarifying the rules under which the data can be legally held, shared and used.
A curator also ensures that content curation, structure, tagging, and classification all adheres to disciplines and an agreed format. Content must have a review date and a mechanism for it being retired. This function is librarianship, or that of a content gardener to ensure accuracy and relevance of the information.
Without data stewards and curators, a knowledge repository such as a data catalog is doomed to failure and the descent follows a cyclic pattern.
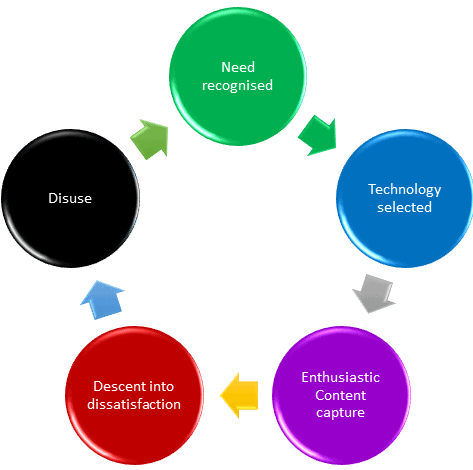
Where curation is ineffective, and stewardship is flaccid, contradictory information will begin to appear in the knowledge repository. Other signs include the poor maintenance of a tagging and classification system and sometimes even unchecked content that doesn't correspond with the business reality. This leads to a corrosion of trust in the content from the users of the repository.
Much can be achieved with a carefully designed system but there is only so much that can be realistically catered for by mechanical means. It requires the expert eye.
Audience for the data catalog
The needs that a business or technical user may have of a data catalog can vary from simple to extremely complex but can be summarized as follows:
- What data do we have?
- Where does it come from?
- Where do we store it?
- What do we do with it?
- How long to we retain it?
Within this, however, each distinct audience will have their own needs and require various levels of detail. A Business Intelligence Developer will need detailed technical information about the data sources they use.
A manager will be best served by summarized information written in the language of the business and terms from the business glossary. Doing so reinforces the use and value of the business glossary and is an example of overcommunicating clarity. Ideally, when a business glossary term is used, the data catalog should provide automatic highlighting and hyperlinking of business glossary terms. This feature exists in modelling tools such as Sparx Enterprise Architect. Some users of the catalog, such as business analysts, will need to zoom in to greater levels of detail in some instances and zoom out to a summarized view.
If a business is to maximize the benefit its users gain from a data catalog, it must be published where it is readily available, such as at an easily remembered URL. For example, I would expect Redgate's data catalog to have a URL such as https://data-catalog.red-gate.com.
We should also consider the point of view of people who cannot use a mouse, who rely on screen readers or who face similar physical challenges. A facility that is designed with disabled access in mind can be simpler and faster to operate for all audiences.
Harvesting metadata
A data catalog must be capable of harvesting metadata from its source systems. It must also allow data and data flows to be tagged to make information on those subjects easier to find and for those artifacts to be assigned a category or categories.
RDBMS's support Codd's 4th rule that the structure of the entire database must be stored in an online catalog, meaning that we can extract metadata using standard SQL queries. Many tools use the different vendors' online catalogs.
Newer systems such as Google BigQuery and Apache Presto/AWS Athena also hold descriptive metadata against data structures, though these are specific to each solution.
Some modelling tools will export their contents in XMI (XML Metadata Interchange) format. However, I have seen some tools lean rather heavily on using XMI extensions to represent their objects. Webservices provide WSDL (Web Services Description Language) and oData sources may implement the $metadata capability.
Data sources such as flat files, JSON documents and many NOSQL sources have no intrinsic metadata within the data source itself. For this reason, a data catalog must also allow us to define the structure of a data source manually.
The knowledge about all these different data sources is likely to be spread throughout the organisation, so it's important that as many people as possible contribute their expertise. For each of these data sources, the catalog must present its information in a way that support the characteristics of data and information quality:
- Accuracy
- Accessibility
- Coherence
- Completeness
- Timeliness
- Relevance
- Validity
These characteristics dovetail, overlap and support each other. The need for accuracy and validity means that there must be a distinction between a feedback mechanism, open to all, and a content maintenance mechanism, available to information gate keepers. The data catalog should support both.
No matter where information within the catalog came from, the date on which it was captured and the process or person that captured must also be recorded.
Easy Navigation through the data catalog
In addition to robust and accessible user interface design, the users of a data catalog must find it quick and easy to access the information they require. This should include a full-text search capability and that full-text search should provide the following capabilities:
- Search of descriptive content
- Search by categories of data
- Search by tags annotated to the data
A thesaurus capability is also useful, although such a facility runs the risk of circumventing the benefits offered by adhering to an agreed business glossary (see later).
When data originates in an RDBMS, or graph database, the linkages between the different data objects should be harvested to provide a mechanism to link information in the data catalog. Where there is an absence of relationships in the source database it may be useful to infer such relationships through a rules based system.
Data lineage, transformation and data quality rules
External systems, or even internal operational systems, may not produce data that is in a suitable form for downstream consumers. Therefore, data lineage within a data catalog needs to capture the actions taken against data as it flows through the organisation.
- Data is copied directly from the source
- Data is combined, aggregated or concatenated
- Data has a mathematical operation carried out against it, such as currency or temperature conversion
- Data is used to indicate the need to generate a surrogate key
- Data is re-coded, such as for the different possible ways of representing gender
- Data has a specific action when encountering unknown or missing values.
Data, and the conclusions drawn from data, will occasionally be questioned. When this happens, sort of information can reduce doubt and uncertainty and ensure that the correct conclusions and decision are reached.
Non-technical information in the data catalog
Non-technical information includes owners, stewards and, in a GDPR world, the data controllers and processors. Where dealing with 3rd party data sources and targets it is useful to hold the contact details of those 3rd parties.
With the GDPR, anyone, such as a customer, about whom you hold personal data can make a subject-access request When this happens, it must be easy to explain to the subject where that personal data was sourced from. This does not compel an organisation to act as a central coordinating point but does require it to pass on suitable contact details for the 3rd party data controller.
Notification and subscriptions
If someone fulfills the role of a data owner, steward or subject matter expert then they must be notified of any feedback or content added on their area of expertise. This enables them to fulfil their stewardship role.
Similarly, if a team is building a system that requires data of a particular subject, then they may wish to have a "watch" facility so that they are notified of new or amended content.
Threats to the adoption of a data catalog
No significant IT project is likely to succeed without a suitably placed and enthusiastic stakeholder.
The absence of a data glossary, conceptual and logical data model suggests that there is no clear idea about what is being captured in a data catalog and for whose benefit. Without the data glossary, the data catalog will use ambiguous terms, spreading doubt where certainty is required. Without a central data model, the catalog will describe isolated satellites of data rather than the integration of data across the enterprise.
Even with both the business glossary and data models in place, there is still a significant amount of work required before a data catalog can be adopted. If the benefit is seen as being long term or indirect, then few organisations will see the value in the investment and may feel that there is no pressing need for such a commitment in time, money and other resources.
New Regulatory drivers
A data catalog is one of the requirements for 'privacy by design' and underlies the privacy-enhancing technologies which make GDPR compliance easier. It also makes the PIR (Personal Information Review) and 'Data Protection Impact Assessment' (DPIA) much easier to do because these build on the information in the catalog, and the catalog itself, if properly versioned and audited, can constitute evidence. An organization that can show that it has followed best practice on doing this is likely to attract fewer penalties if an unfortunate data breach happens. In other words, a data catalog can save financial penalty and loss of reputation. Additionally, a data catalog can help with the following GDPR articles.
- Article 13, 14 and 15 of GDPR are explicit in stating that a data subject (you and I) can demand and receive within 30 days the information above regarding our personal data and how long data is retained for, how it is categorized.
- Article 30 states that an organisation must maintain a record of its processing activities and make such records available to the "Supervisory Authority" on request.
- Article 35 requires that there be a data protection impact assessment be carried out.
Earlier in this article slow 'data archaeology' and data discovery processes were described as a threat. In the context of GDPR they also represent a severe risk because they are read by the information commissioner as a cover-up for negligence.
A well-maintained data catalog represents the fact that the organisation is following best practice in data curation. It also makes the mechanics of complying with the Articles of the GDPR far simpler. The size of the fines stipulated in article 83 provide a compelling business case for tooling to aid compliance.
Conclusion
Since the early days of the use of information technologies by businesses, Organisations have maintained data models and data catalogs. This was done because it saved time and argument in any organisation that was rapidly changing. It ensured a common understanding of the specialized language or 'jargon' of the organisation, and it enabled everyone to determine how, where, why and what data was being held.
Now, with IT being intrinsic to many businesses, these original reasons for modelling and cataloging data are even more relevant. On top of that, legislation is increasingly recommending or, in some cases, demanding privacy by design and data security by design. Such things require you to answer the same questions of data: how, where, why and what.
An organisation that maintains data models and a working data catalog will meet these changing and increasing demands far more easily than the ones that rely on panic data-archaeology in response to the next crisis. If these are of a standard that allows their use as evidence, an organisation is then well-defended against any litigation concerning personal data that might happen. A data catalog is no longer a luxury and is becoming a necessity.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Live training session
Cataloging and Masking AdventureWorks
AdventureWorks is a database we all know and love so there’s no place better to tackle one of the most challenging aspects of protecting data in non-Production environments. Join Chris Unwin in this session as they walk you step-by-step through getting AdventureWorks classified and masked for non-Production use in just 30 minutes. With the help of SQL Data Catalog and Data Masker for SQL Server, data masking need never be a daunting task again! If you are interested in more sessions on SQL Data Catalog then check out ‘Loading Existing Classifications into SQL Data Catalog’ where Chris will take you through some

Article
Using Data Scanning to Identify and Classify Sensitive Columns
SQL Data Catalog's new data scanning feature uses regular expressions and data dictionaries to identify where sensitive and personal data is stored in your databases.
Article
Effective Data Governance: Being Grown Up About Data
William Brewer explains how to make data governance a continuous organizational activity, based on well-established standards and practices, rather than a knee-jerk response, and which skills and tools will help you achieve compliance, including SQL Data Catalog for discovery and classification of data held in SQL Server.
Article
What is a Data Catalog?
A data catalog allows an organization to discover and record the facts about its data, where that data is held and how it used. William Brewer explains the details.

Article
Continuous Data Protection with SQL Data Catalog 2.0 and Data Masking
SQL Data Catalog 2.0 provides a simple, policy-driven approach to data protection, through data masking. It can now automatically generate the static masking sets that Data Masker will use to protect your entire database, directly from the data classification metadata held within the catalog.
Article
How to Classify and Protect your Development Data Automatically using SQL Data Catalog and Data Masker Command Line
Chris Unwin describes a classification-driven static data masking process, using SQL Data Catalog to classify all the different types of data, its purpose and sensitivity, and then command line automation to generate the masking set that Data Masker for SQL Server can use to protect this data.
Loading comments...