Using Custom Deployment Scripts with SQL Compare or SQL Change Automation
Phil Factor describes how custom pre- and post-deployment scripts work, when doing state-based database deployments with SQL Compare or SQL Change Automation, and how you might use them to, for example, add a version number to the target database, specify its database settings, or stuff data into some tables.
When you are using the so-called ‘state-based’ method of database deployment, you’ll need to devise some additional custom scripts to get around some of the trickier deployment problems. For example, if you’re using SQL Compare or SQL Change Automation (SCA) to synchronize a script folder containing object-level scripts with a target database that holds data, you might need some custom scripts to control movement of data between the current and new version of a table.
Both SQL Compare and SCA place these scripts either at the beginning or the end of the synchronization script that it generates, before it is executed.
What are custom deployment scripts good for?
Most often, you’ll turn to a custom deployment script when you need to introduce code to deal with an awkward change from one version of a database to another. If, for example, you are changing tables in a version of a database that is already stocked with data, you will occasionally need to ‘snatch the reigns’ from SQL Compare to ensure that the old data all moves to the correct place in the improved design. It will often happen with a table rename or table split. Sometimes a single column that contains data that isn’t ‘atomic’, such as a comma-delimited list, XML or JSON, will need to be distributed into normalized columns.
You may also have a problem with dependencies, changing database properties, adding scheduled tasks, adding database version numbers and so on. At other times, you might also need to change database-level settings, manage role memberships, check for the existence of the correct static data, or create or alter SQL Server Agent jobs. All these matters can be dealt with by a custom deployment script
Deploying from a script directory
SQL Compare compares two databases, the source and the target, and automatically generates a single synchronization script that will modify the target schema so that it matches the source schema. When you are using a scripts directory as a source, SQL Compare allows you to attach extra SQL Scripts onto the beginning or the end of the synchronization script that it generates.
If your source is a scripts directory taken from your version control system, then SQL Compare allows pre- and post-deployment scripts, but you can have just one of each. SQL Compare, both UI and command line, allow them from version 13.4.7, or SQL Change Automation from version 3.0.4.
The scripts must be contained in a directory called Custom Scripts, within subdirectories called Post-Deployment or Pre-Deployment.
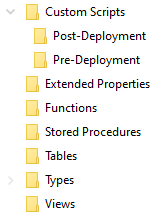
Both post-deployment scripts and pre-deployment scripts are outside the transaction within which the auto-generated portion of the script runs, so you need to add your own transaction handling, and manage any rollback, within these custom deployment scripts.
Each script must follow certain simple conventions. The script will not abort execution on error, so it must catch every error and report it, while also setting NOEXEC to ON, if it is a ‘fatal’ error. If an error occurs before the post-deployment script, NOEXEC will be ON. Therefore, it will not execute. Never use the NOEXEC OFF command in your post-deployment script, because the synchronization script uses the NOEXEC ON switch to abort processing after any error. Bad things will happen if you unintentionally re-enable execution after an error
Each section of the script should have a PRINT statement at the start describing what it does, so that if there is an error then it is obvious what has caused the rollback.
Each script must be re-runnable and idempotent. It must be able to run in all intended target environments and must support any possible differences in database collation across your database environments.
How pre- and post-deployment scripts work
The contents of these custom scripts aren’t part of the build because they aren’t executed until after the comparison is done, and so they have no effect on the synchronization script that SQL Compare auto-generates. A pre-deployment script is used to alter the target database after the synchronization script is generated but before it is executed. A post-deployment script is used to alter the target after the synchronization script has been executed.
If, for example, you place in the Pre-Deployment subdirectory a custom script that includes the creation of a table, then this table will not be included in the comparison. SQL Compare runs the comparison, generates the synchronization script, executes the pre-deployment script on the target, creating the new table, then executes the synchronization script. If, on the other hand, you placed the same script in the Post-Deployment subdirectory of your Custom Scripts directory, then SQL Compare will create the new table after running its synchronization script.
There is no other way within SQL Compare to add migration logic. If you need to alter the target before the comparison is done, you must do it in a separate script before you run SQL Compare.
Pre-deployment scripts can be useful, for example, if you need to copy data out of a table in the target database that will be altered and save it in a temporary table. The table can then be changed in the synchronization script and, finally, the data can be re-inserted into the new table in a post-deployment script. You might also need to use a post-deployment script to ensure that certain reference or static data exists in a table.
SQL Compare does not consider server-scoped objects in its comparisons, so if you need to synchronize agent jobs between a source and target then you can do so in either a pre- or post- deployment script. Other tasks, such as checking that database settings are correct, must use the pre-deployment script because they can easily change the way that the subsequent scripts are executed. If, for example, collation is case-insensitive and the database is case-sensitive, the synchronization won’t work.
Post-deployment scripts can be used to apply the changes required to create specific variants of the database version. If, for example, you have different variants of a payroll database according to legislative area, they can be switched according to the required legislative area.
You may need to keep several variants of the same version of the database in trunk, using conditional switches to produce the correct variant (any accounting package, for example, is likely to have variants for each tax region). Although it is possible to run CREATE scripts, or ALTER scripts, conditionally, this makes source control over-complex, and makes synchronization from a script directory a minefield.
The best practice for this, I suggest, is to include all code in the version and use a feature toggle or feature switch, such as a value in a table or extended property, to implement the correct logic. This can be set in the post-deployment script merely by simple logic such as checking the name of the target database and switching accordingly. A ‘soft’ database switch or toggle held in a function or extended property allows all variants to be tested using the same deployment.
Quirks
There are some limitations to consider when using Pre & Post-Deployment scripts.
The do not support use of SQLCMD syntax and variables, unless you execute the synchronization script separately, outside SQL Compare, using SQLCMD or by using SSMS in SQLCMD mode.
If you opt to modify existing objects as part of these custom scripts, you will need to make sure that the SQL Compare engine leaves them alone. You will need to have the new version of the object source code in the main script directory, not the ‘Custom scripts’ directory, so you will need to tell SQL Compare not to create or change them as well, using SQL Compare filters or /Exclude switches to prevent the inclusion of those objects in the comparison.
If SQL Compare runs a comparison between source and target and finds they are identical, then it will not run the Post- and Pre- scripts because there will be no synchronization script to which to attach them.
Unless these scripts are thoroughly tested, errors will only be discovered once the deployment script is executed and then they will break the build which can cause problems. Allow time to test them thoroughly before use.
Source control and custom scripts
Post-deployment and pre-deployment scripts should almost always be kept in source control. Whatever objects they create or change, the state must be in source control. Normally, for a change such as a table-split, you need only add a SQL Compare Filter or /exclude switch to tell SQL Compare not to include the affected object in the comparison, because it is done in the accompanying post-deployment script. This means that source control can have the SQL DDL code for the changed objects without their presence interfering with a complicated data split. As described earlier, it is perfectly possible to use a pre-deployment script to save existing data in the target database from a table about to be altered into a temporary table before allowing the Synchronization script to make the rest of the changes except for the objects you specify for exclusion; and then a matching post-deployment script can read the temporary table and place the data in the correct location.
Both types of custom scripts, pre- and post-deployment, should be specific to a version. However, because they are idempotent, they should not normally hurt anything even if they are accidentally re-run. The script folder will reflect just one version so it should be easy to provide the correct custom scripts for the version.
The target of a database deployment cannot necessarily be guaranteed. If you don’t maintain a version number of the live database, then you will need to ensure that the custom scripts will work with all possible target versions that are ‘out in the wild’.
Examples
These shouldn’t be run as-is; you need, for example, to fill in the name of the database and version number, or else tweak the information as required. The database settings example could have subtle but wide-ranging effects on the hapless database on which you run it. They also don’t amount to a general recommendation on how to perform these tasks because your circumstances could well be different For example, the “stocking a table with data” example will be fine until you have thousands of rows, at which point you would be better off with a BULK INSERT. These examples are just intended to be illustrative, to show you the possibilities
Stocking a table with data
Imagine that you need to build a version of the antiquated PUBS database, including all the data. This script must be in the Post-deployment directory. Here is an example that ensured that the dbo.publishers table had nothing but the original data in it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
PRINT 'Ensuring that the original PUBS test data is there' BEGIN TRY MERGE INTO dbo.publishers AS target USING (VALUES ( '0736', 'New Moon Books', 'Boston', 'MA', 'USA' ), ( '0877', 'Binnet & Hardley', 'Washington', 'DC', 'USA' ), ( '1389', 'Algodata Infosystems', 'Berkeley', 'CA', 'USA' ), ( '1622', 'Five Lakes Publishing', 'Chicago', 'IL', 'USA' ), ( '1756', 'Ramona Publishers', 'Dallas', 'TX', 'USA' ), ( '9901', 'GGG&G', 'Mnchen', NULL, 'Germany' ), ( '9952', 'Scootney Books', 'New York', 'NY', 'USA' ), ( '9999', 'Lucerne Publishing', 'Paris', NULL, 'France' ) )source(pub_id,pub_name,city,[state],country) ON target.pub_id = source.pub_id WHEN NOT MATCHED BY TARGET THEN INSERT ( pub_id,pub_name,city,[state],country ) VALUES ( pub_id,pub_name,city,[state],country ) WHEN NOT MATCHED BY SOURCE THEN DELETE; END try BEGIN CATCH DECLARE @msg nvarchar(max)=Error_Message(), @severity int = ERROR_SEVERITY(), @State int = ERROR_State() RAISERROR(@msg, @severity, @state); SET NOEXEC ON END CATCH |
Database settings
These must be performed in the pre-deployment script. For a database to perform as you expect there are certain database property settings that are required. It is usually a good idea to check these settings on deployment as they can sometimes produce subtle errors. Collation, recovery model and compatibility level are obvious ones, but several others, such as auto-update statistics and auto-create statistics need to be checked. You’ll, of course, need to determine the correct settings for your databases; these are just examples of settings that a DBA might recommend.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
/* To run this Requires having ALTER permission on the target database. */ PRINT 'Ensuring that the settings are right for this particular database. DECLARE @AutoCreateStatistics INT,@AutoUpdateStatistics INT, @ReadCommittedSnapshot INT,@AutoUpdateStatisticsAsynchronously INT, @recovery_model_desc nvarchar(120),@compatibility_level int SELECT @AutoCreateStatistics=is_auto_create_stats_on, @AutoUpdateStatistics=is_auto_update_stats_on, @AutoUpdateStatisticsAsynchronously=is_auto_update_stats_async_on, @ReadCommittedSnapshot=is_read_committed_snapshot_on, @recovery_model_desc=recovery_model_desc, @compatibility_level=[compatibility_level] FROM sys.databases WHERE name='pubs' IF @AutoCreateStatistics=0 ALTER DATABASE current SET AUTO_CREATE_STATISTICS ON DECLARE @AnyErrors INT =@@error IF @AutoUpdateStatistics=0 ALTER DATABASE current SET AUTO_UPDATE_STATISTICS ON SELECT @AnyErrors=@AnyErrors+@@Error IF @AutoUpdateStatisticsAsynchronously=1 ALTER DATABASE current SET AUTO_UPDATE_STATISTICS_ASYNC OFF SELECT @AnyErrors=@AnyErrors+@@Error if @ReadCommittedSnapshot=0 ALTER DATABASE current SET READ_COMMITTED_SNAPSHOT ON WITH rollback immediate SELECT @AnyErrors=@AnyErrors+@@Error if @recovery_model_desc<>'SIMPLE' ALTER DATABASE CURRENT SET RECOVERY SIMPLE SELECT @AnyErrors=@AnyErrors+@@Error /* normally you'd want it at your current product version but you might, as in this case, need something different check product version with SELECT SERVERPROPERTY('ProductVersion'); */ IF @compatibility_level<>100 --Warning this is specially for old PUBS! ALTER DATABASE PUBS --a bad idea anywhere else SET COMPATIBILITY_LEVEL = 100 SELECT @AnyErrors=@AnyErrors+@@Error --See https://docs.microsoft.com/en-us/sql/t-sql/statements/alter-database-transact-sql?view=sql-server-ver15 before doing this IF NOT EXISTS ( SELECT 1 FROM sys.databases WHERE name= Db_Name() AND collation_name='SQL_Latin1_General_CP1_CI_AI') ALTER DATABASE CURRENT COLLATE SQL_Latin1_General_CP1_CI_AI SELECT @AnyErrors=@AnyErrors+@@Error IF @AnyErrors>0 SET NOEXEC ON |
Add version information
This can be done either as a pre- or post-deployment script. This example script merely inserts the version number and description as a JSON string. A much more extended version of this code that tracks versions and when they were applied is contained in this article Associating Data Directly with SQL Server Database Objects.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
PRINT N'Adding a version number' GO DECLARE @DatabaseInfo NVARCHAR(3750) SELECT @DatabaseInfo = ( SELECT Db_Name() AS "Name", '2.4.01 (Change This to your version)' AS "Version", 'You will need to edit this string' AS "Description", GetDate() AS "Modified", SUser_Name() AS "by" FOR JSON PATH ); BEGIN TRY IF not EXISTS (SELECT name, value FROM fn_listextendedproperty( N'Database_Info',default, default, default, default, default, default) ) EXEC sys.sp_addextendedproperty @name=N'Database_Info', @value=@DatabaseInfo ELSE EXEC sys.sp_Updateextendedproperty @name=N'Database_Info', @value=@DatabaseInfo END TRY BEGIN CATCH DECLARE @msg nvarchar(max)=Error_Message(), @severity int = ERROR_SEVERITY(), @State int = ERROR_State() RAISERROR(@msg, @severity, @state); SET NOEXEC ON END CATCH |
Conclusions
Pre- or Post-deployment scripts allow us to get over most problems faced by development teams who are deploying database code in a scripts directory via SQL Compare, while maintaining a single source of truth of the source code in version control.
Tools in this post
You may also like
-

Article
Moving from application automation to true DevOps by including the database
This article explains the challenges of DevOps automation for databases, starting with how to manage the database, as a set of SQL scripts, in the version control system, and then how to start building an integrated and automated script pipeline for continuously testing and deploying database schema changes, alongside the application code.
-
Article
How to Add a Filter to an Existing SQL Change Automation Project
Kendra Little demonstrates how to create a SQL Compare filter file and save it to a SQL Change Automation project folder, so that it will be used automatically during development.
-
Article
Deploying Multiple Databases from Source Control using SQL Change Automation
How to automatically build multiple test databases, from source control, and then fill them with standard test data sets, using SQL Change Automation, BCP and some PowerShell magic.
-
Article
Simple Steps in SQL Change Automation Scripting
Phil Factor demonstrates the bare essentials of SCA PowerShell scripts that can form the basis for an automated process for database delivery or help improve your current process.
-

Article
SQL Compare Snapshots: a lightweight database version control and rollback mechanism
During the proof-of-concept phase of development work, SQL Compare Snapshots offer an easy way to work out what broke, if a change causes some tests to fail, as well as a simple ‘roll back’ technique to return quickly to the last working copy.