How to build multiple database versions from the same source: post-deploy scripts
In Part 2 of his series, Alex Yates shows how to use a combination of post-deployment scripts to handle cases where a code object exists in multiple production instances, but in different states.
This is the second post in a three-part series that explains how to use SQL Compare to maintain a single source of truth in version control for a SQL Server database which can be deployed to multiple production instances, despite the fact that some production instances have customizations.
My previous article explained how to use SQL Compare object filters to restrict deployments to a certain set of database objects. This piece explains how to use a combination of post-deploy scripts to handle deployments in cases where a code object (anything that isn’t a table) exists in multiple production instances, but in different states. Tables add an extra layer of complication, and we’ll deal with those in part 3, using pre-deploy scripts.
Set up
To help demonstrate the concepts, I’ll continue to use my sample databases, Twilight Sparkle and Fluttershy, which represent two customized production instances of the same database (Ponies). We’ll also continue to use the ‘master development database’, Ponies_dev, and the SQL Compare filters that we created in part 1.
You can create the Twilight Sparkle and Fluttershy databases by executing this script. You can create the Ponies_dev database, source control repository and filter files by following the instructions in part 1.
You’ll need a SQL Server instance and a copy of the Redgate SQL Toolbelt. which you can download with a fully functional 14-day free trial.
Handling objects that exist in both environments, but are different
By the end of part 1, we’d created in source control our ‘canonical source’, namely a master development database called Ponies_dev, by deploying to it all the objects in the Twilight Sparkle database, followed by the objects that existed in Fluttershy only. We then used SQL Compare filters to ensure that when deploying from Ponies_dev, we selected only the appropriate objects.
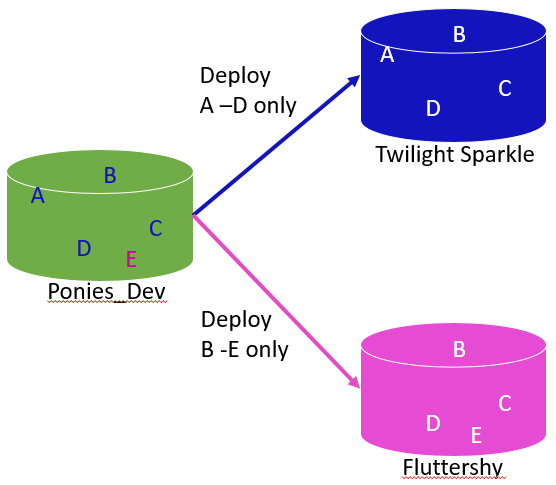
Figure 1
However, where objects existed on both Twilight Sparkle and Fluttershy (objects B, C and D in Figure 1), we were effectively deploying the Twilight Sparkle version, so relied on the fact that these objects were identical in Fluttershy.
However, let’s say Fluttershy has been customized to support local functionality, and one or more of the objects in Fluttershy are different from the version that exists in Twilight Sparkle (and therefore in Ponies_dev)? We risk deploying the wrong version of these objects. In Figure 2, we’d overwrite object Bf with object B.
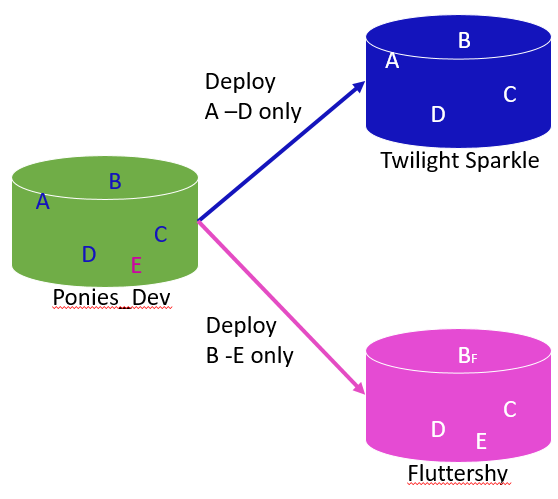
Figure 2
In this article, we’re going to do the ‘easy’ bit, dealing with any object that is not a table, then in the final part of this series, we’ll deal with the knottier issue of trying to deploy a change made to a table in the ‘canonical source’ when the same object in the target database is deliberately different.
Dealing with differences in code objects with post-deploy scripts in SQL Compare
To solve this problem for code objects only (assuming all tables are in-sync), we are going to create a post-deployment script that we run only when deploying to Fluttershy.
- Open Redgate SQL Compare.
- From the options tab select Use DROP and CREATE instead of ALTER.
- Set
Fluttershyas the source andPonies_devas the target, and compare. - Select all the in both, but different objects except tables. In this case, that leaves just one object,
spOnBothButDifferent, but in a real world example you’ll likely have more.
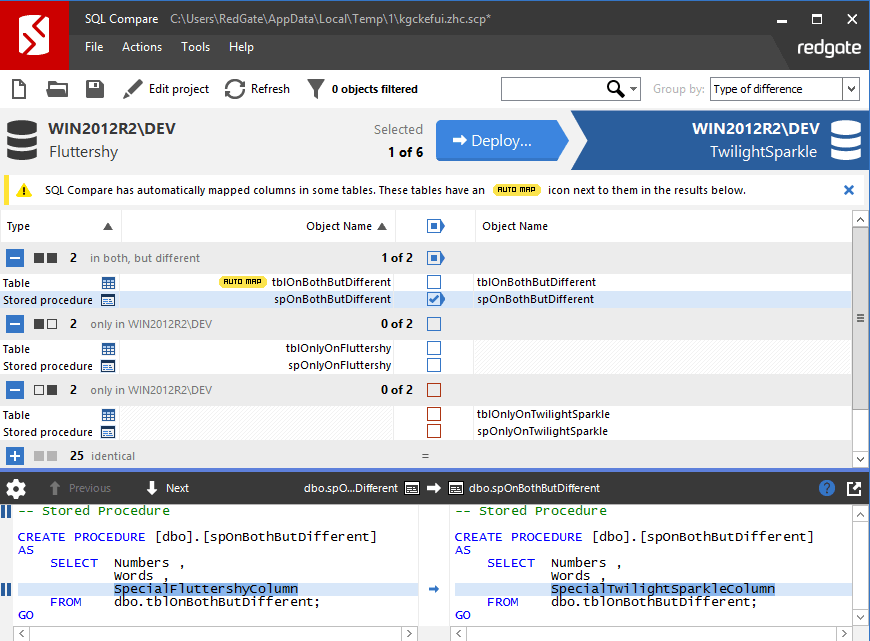
Figure 3
- Click Deploy… and in the wizard choose the option to Create a deployment script.
- You should be able to create a script that drops and recreates all the in both, but different objects (except tables) in the
Fluttershystate. All the drop and creates should be neatly wrapped into a single transaction. This will be your post-deploy script for theFluttershydatabase. - Create a new directory in source control and save your post-deploy script as FluttershyPostDeploy.sql. I saved mine to the directory: Documents\Ponies_dev\postDdeploys.
From now on, if developers wish to modify the Fluttershy version of these objects, they must do so by editing the FluttershyPostDeploy.sql, instead of the actual database.
Since these objects are now handled by the post-deploy script, we can revisit the Fluttershy filter we created in part 1 and filter out all the objects that we are now managing with the upgrade script.
Now, assuming your tables are in sync, you can run a single script, shown in Listing 1, to deploy your source code to Twilight Sparkle and Fluttershy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# This script assumes the user has followed the instructions listed in part 1 and part 2 # of this blog post: # http://www.red-gate.com/blog/database-lifecycle-management/how-to-build-multiple-database-versions-from-the-same-source-using-sql-compare-filters $ErrorActionPreference = "stop" # Required variables $user = "YOUR_USERNAME" $password = "YOUR_PASSWORD" $serverinstance = "YOUR_SERVER\YOUR_INSTANCE" # Derived variables $myDocuments = [Environment]::GetFolderPath("MyDocuments") $masterSourceCode = "$myDocuments/Ponies_dev/state" # Regular SQL Compare deployment step (using filters) $fluttershyDb = New-DlmDatabaseConnection -ServerInstance $serverInstance -Database Fluttershy | Test-DlmDatabaseConnection $filterPath = "$myDocuments\Ponies_dev\filters\fluttershy.scpf" Sync-DlmDatabaseSchema -Source $masterSourceCode -Target $fluttershyDb -filterPath $filterPath # Post-deploy script invoke-sqlcmd -inputfile "$myDocuments\Ponies_dev\postDeploys\fluttershyPostDeploy.sql" -ServerInstance $serverInstance -Database Fluttershy -Username $user -Password $password |
Listing 1: DeployFluttershy-NoTables.ps1
We only have one object covered in our post-deploy script, but if you had many objects you might prefer to create a post-deploy script for each object and run each script in sequence. This would be easier to manage in development, because you’ll get fewer merge conflicts and it will be more obvious which objects are managed by post-deploys and which are not. However, you’ll want to run all these scripts within a single transaction, as demonstrated in this example on Stack Overflow.
Summary
This article demonstrated how we can deal with non-standard changes to database code objects, in various target environments, while maintaining a single, master source copy of the database, and automating our deployments to each environment from a single script.
That was the easy part; once we start introduce non-standard changes to tables, the solution grows in complexity, as we’ll see in Part 3, where I’ll describe the solution and discuss its shortcomings.
As I’ve stated before, the best way to solve this problem is to fix the root cause and get our databases in sync. However, when that is not possible or practical in the short term, employing strategies such as those discussed in this series can allow us to apply some sort of version control, and gain some measure of control over our deployments.
If you’d like to know how to use SQL Compare object filters to restrict deployments to a certain set of database objects, read my first article in this three-part series.
Read part 3 of the series if you want to maintain a specific table, or set of tables, with different structures in different production versions of the database, using a combination of a migrations tool and a pre-deploy script.
Tools in this post
You may also like
-

Article
How to cope with Database Drift during Deployment using SQL Compare
Phil Factor on how to cope with any database drift that results from various checks and tests and fixes made during deployment.
-

Article
Problems Caused by Use of the SQL_VARIANT Datatype
Phil Factor illustrates the 'quirks' of the SQL_VARIANT datatype and why it's best to investigate when SQL Prompt alerts you to its use. It is only safe to store data as a SQL_VARIANT, if you explicitly convert it to its true type before you use it.
-

Article
How to create and refresh development and test databases automatically using SQL Clone and SQL Toolbelt
A PowerShell automation script to build a SQL Server database from source control, seed it with dummy data, document it, and then deploy copies to any number of test and development servers.
-

Article
Database Development in Visual Studio using SQL Change Automation: Getting Started
Steve Jones shows how to set up a SQL Change Automation (SCA) project in Visual Studio, and import an existing database. As the team make database changes, either in SSMS or VS, they import them into the SCA project, which saves each change as a migration script that is then committed to source control.
-
Article
Introducing the updated HTML comparison report in SQL Compare 13.1
SQL Compare 13.1 brings improvements to the interactive HTML comparison report type, providing simpler cleaner reports that focus on the differences between the compared databases.