




SQL Clone for Unit Testing Databases
Sometimes, when you are doing unit tests or integration tests whilst developing code, you need to be able to do something extreme, such as mangling a test database or two, repeatedly, each time subsequently restoring it to its original state before running the next test. Often, especially in integration tests when you are testing processes, you will need run a 'setup' process, to establish a known database data state, then run the process, test that the final data state matches that which your business rules dictate it should be, and finally run then a 'teardown' process to restore things to how they were at the start.
The difference with a unit test is that the developer is constantly running the test and resents it if the set up or teardown processes take any delay longer than what in my misspent youth we'd call 'the time it takes to roll a cigarette'. Integration tests are generally done in a more dignified manner after the build so there is less pressure on time. In this case, it is a unit test that we need, though it can be adapted as an integration test if the component under test gets to be part of a process.
What's required?
Unit testing is performed on each routine, in isolation, to ensure that it returns a predictable result for each specific set of inputs that is used. They are required for all modules, such as procedures, functions, views and rules – Testing Databases: What's Required?
Some code we can only test by making changes to a database, either schema changes or data changes, or both. Developers will want to run the tests repeatedly, as they refine the code. What one really needs, in such cases, is a disposable database. You want to be able to create a known database version on your development server, possibly stocked with standard test data, then run the unit test, which executes your code and verifies that the outcome is exactly as expected. Once the test completes, we immediately run a teardown process that resets the test database to its original state.
The set up and tear down processes must run quickly to be useful for unit testing. Speed is especially important if, for example, we need to test that the same code produces the correct result on a series of different versions of the database, meaning that we need to recreate each different version and run the test on it. If, for example, you need to run tests on several variations of the same release version (e.g. payroll programs for different legislative areas), then you need a way of doing it quickly.
I was faced with just this problem when developing a routine that checked for objects that had been added, modified or removed, in a set of databases. I wanted to quickly set up the required version of the test database, then run the unit test for my routine.
Unlike regression or integration tests, this sort of development work isn't dependent on the data in the database, just with changes in the metadata as recorded in the sys.objects system table. The unit test first needs to make a series of schema changes to a test database, recording in a #WhatHasHappened table, for each change, the object and the action. For example, if the test drops a FOREIGN KEY constraint, it will write two entries into #WhatHasHappened, one identifying the constraint, with an action of "dropped", and one identifying the parent table, with an action of "altered". Next, the unit test runs the routine, which in this case is SQL that compares data in the system tables of the 'used' test database to that in the original database, to return a result set containing a list of the object changes. The test compares this result set to the contents of #WhatHasHappened to make sure they are identical. If they are, the test passes. By associating each test with a report to the #WhatHasHappened table, it is easier to expand the range of tests and ensure that all modifications are reported correctly.
The disposable database: 'Set up' and 'tear down'
There are plenty of ways to setup and teardown (reset) a database. If you just need an empty database (which is fine in this case) or only a modest amount of test data, then you can perhaps use a DACPAC, or run an automated build-and-fill using SQL Change Automation and JSON.
For a fully-fledged database, you can restore from a backup, each time, or you can detach the 'used' database, and then reattach the original database. The speed of these techniques will depend on the size of the database and won't be viable for unit tests beyond a certain point.
As a Friend of Redgate, I'm lucky enough to be able to use SQL Clone. Why so lucky? It takes less than ten seconds to produce or refresh a clone of, say AdventureWorks, from an existing image. It is easy to de-clutter your servers by keeping test databases and utilities only as images and cloning them just when you need them, and you can feel uninhibited about destruction-testing them.
For the type of unit test I've been describing, every time you want to run a test, you want a fresh clone created from the current image. If a clone already exists, you delete it on the assumption that it has been already defiled by your test code. You then create a new one. If you need to modify all clones, in a standard way, or modify individual clones, before running the tests, you can run scripts as part of the image or clone creation.
Listing 1 shows the code that will create a new clone, tearing down and replacing any existing clone. It will check to see if you have an existing image for the database. If not, then it creates it. If you want a fresh image, you just delete the present one, using the SQL Clone console, before you run the script. If there is an existing image, the script then checks if you already have a clone. If there is one, it deletes it and creates a new one, ready for the next test run. In the diagram, the original database is on the same instance as the clone.
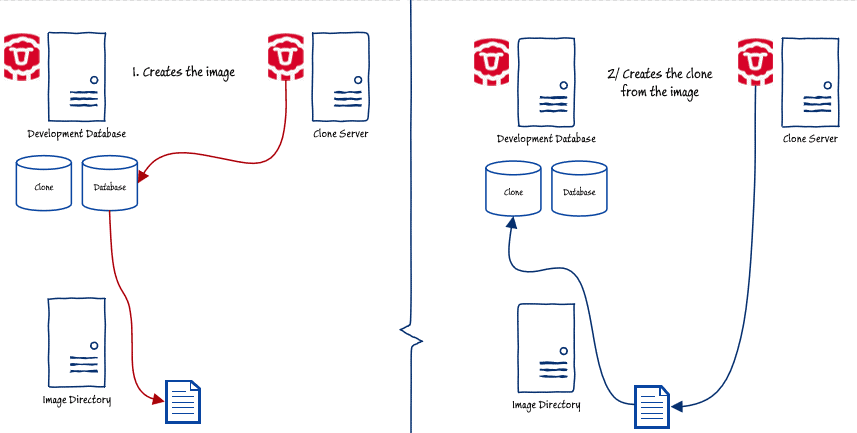
In this code, I've kept the configuration data with the script just to keep things simpler. It is possible to use the code from the previous SQL Clone articles, with an appropriate config file, but it would be overkill for a busy development session, particularly as you are unlikely to need an image or clone modification and would never need to retain the code from the clone before the teardown. Here, everything is in one easily-modified script.
Listing 1: CloneForUnitTesting.ps1
A practical use for the disposable database
Now we have our disposable database, how would we use it? Here, I'm going to show how to use it to run a unit test on a database, repeatedly, when the test, by necessity, messes up the database each time. In this case we're testing a query that finds all the differences between two databases, one called MyTestDatabase, the clone, and the other called MyReferenceDatabase, the original database from which we take the image. At the beginning of the test they are identical.
I started developing this code while writing Reporting on the Status of Clones During Database Development, where I was using it to check activity on a whole series of development clones. I've explained how the code works in a Simple-Talk blog post, so I won't repeat those details here. The version of the code I show in the blog, for general use, compares the system data in a live test database to a copy of that data from the original database, held in a JSON file. It also wraps everything up neatly in a versatile table-valued function. with the end user in mind.
During development, it's better to use a CTE, as shown in Listing 2, but the 'guts' of the routine are the same in each case. I used a CTE query during development work because it is so much easier to debug than a function.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
WITH
Cloned
AS (SELECT --the data you need from the test database's system views
Coalesce(--if it is a parent, then add the schema name
CASE WHEN parent_object_id=0 THEN Object_Schema_Name(object_id)+'.'
......ELSE Object_Name(parent_Object_id)+'.' END
......+ name,name --otherwise add the parent object name
......) AS [name], object_id, modify_date, parent_object_id
FROM MyTestDatabase.sys.objects
WHERE is_ms_shipped = 0),
Original
AS (SELECT --the data you need from the original database's system views
Coalesce(--if it is a parent, then add the schema name
... CASE WHEN parent_object_id=0 THEN Object_Schema_Name(object_id)+'.'
... ELSE Object_Name(parent_Object_id)+'.' END
... + name,name --otherwise add the parent object name
... ) AS [name], object_id, modify_date, parent_object_id
FROM MyReferenceDatabase.sys.objects
WHERE is_ms_shipped = 0)
SELECT Cloned.name, 'Added' AS action --all added base objects
FROM Cloned --get the modified
LEFT OUTER JOIN Original-- check if they are in the original
ON Cloned.object_id = Original.object_id
WHERE Original.object_id IS NULL AND cloned.parent_Object_id =0
--if they are base objects and they aren't in the original
UNION ALL --OK but what if just child objects were added ...
SELECT Clonedchildren.name, 'Added' -- to existing objects?
FROM Original-- check if they are in both the original
INNER join Cloned -- and also they are in the clone
ON Cloned.name = Original.name --not renamed
... AND Cloned.object_id = Original.object_id
......--for ALL surviving objects
...inner JOIN cloned Clonedchildren--get all the chil objects
...ON Clonedchildren.parent_object_id =cloned.object_id
...LEFT OUTER JOIN -- and compare what child objects there were
Original OriginalChildren
...ON Originalchildren.object_id=ClonedChildren.object_id
...WHERE OriginalChildren.object_id IS NULL
UNION ALL
--all deleted objects but not their children
SELECT Original.name, 'deleted'
FROM Original --all the objects in the original
LEFT OUTER JOIN Cloned --all the objects in the clone
ON Cloned.name = Original.name
... AND Cloned.object_id = Original.object_id
WHERE Cloned.object_id IS NULL AND original.parent_Object_id =0
--the original base objects that aren't in the clone
UNION ALL
--all child objects that were deleted where parents survive
SELECT children.name, 'deleted'
FROM Original
INNER join Cloned
ON Cloned.name = Original.name
... AND Cloned.object_id = Original.object_id
......--for ALL surviving objects
...inner JOIN Original children
...ON children.parent_object_id =original.object_id
...LEFT OUTER JOIN
cloned ClonedChildren ON children.object_id=ClonedChildren.object_id
...WHERE ClonedChildren.object_id IS NULL
UNION ALL
SELECT Original.name,
CASE WHEN Cloned.name <> Original.name THEN 'renamed'
WHEN Cloned.modify_date <> Original.modify_date THEN 'modified' ELSE '' END
FROM Original
INNER JOIN Cloned
ON Cloned.object_id = Original.object_id
WHERE Cloned.modify_date <> Original.modify_date
OR Cloned.name <> Original.name
ORDER BY name;
|
Listing 2: DifferencesBetweenObjects.sql
So, what do we need to do to test this code? Well, to see if it seems to be working, let's make a bunch of changes to the test database. (I'm using AdventureWorks here).
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
--DROP existing tables
DROP TABLE [dbo].[DatabaseLog]
DROP table [dbo].[AWBuildVersion]
--ADD tables
CREATE TABLE Dbo.Deleteme (theKey INT IDENTITY PRIMARY KEY)
--Add a Procedure
go
CREATE PROCEDURE [dbo].[LittleStoredProcedure] AS
BEGIN
SET NOCOUNT on
SELECT Count(*) FROM sys.indexes AS I
END
GO
Create FUNCTION [dbo].[MyInlineTableFunction]
( @param1 INT, @param2 CHAR(5) )
RETURNS TABLE
AS
RETURN
(
SELECT @param1 AS c1, @param2 AS c2
)
--add a scalar function
go
CREATE function [dbo].[LeftTrim] (@String varchar(max)) returns varchar(max)
as
begin
...return stuff(' '+@string,1,Patindex('%[^'+CHAR(0)+'- '+CHAR(160)+']%',' '+@string+'!'
... COLLATE SQL_Latin1_General_CP850_Bin)-1,'')
end
GO
--drop child objects
--drop a primary key constraint
ALTER TABLE Production.TransactionHistoryArchive
DROP CONSTRAINT PK_TransactionHistoryArchive_TransactionID
--drop a default constraint
ALTER TABLE [HumanResources].[Department]
DROP CONSTRAINT [DF_Department_ModifiedDate]
--drop a foreign key constraint
ALTER TABLE [HumanResources].[EmployeePayHistory]
DROP CONSTRAINT [FK_EmployeePayHistory_Employee_BusinessEntityID]
--drop a primary key constraint
ALTER TABLE [HumanResources].[EmployeePayHistory]
DROP CONSTRAINT [PK_EmployeePayHistory_BusinessEntityID_RateChangeDate]
--drop a check constraint
ALTER TABLE [Person].[person]
DROP CONSTRAINT [CK_Person_EmailPromotion]
--drop a trigger
--IF OBJECT_ID ('sales.uSalesOrderHeader', 'TR') IS NOT NULL
DROP trigger sales.uSalesOrderHeader
--drop a unique constraint
ALTER TABLE [production].[document]
DROP CONSTRAINT UQ__Document__F73921F744672977
--add a default constraint
ALTER TABLE [Person].[EmailAddress]
ADD CONSTRAINT NoAddress
DEFAULT '--' FOR EmailAddress ;
--add a default constraint
ALTER TABLE [Person].[CountryRegion] WITH NOCHECK
ADD CONSTRAINT NoName CHECK (Len(name) > 1)
|
Listing 3: Making a range of different schema changes
Then you would run the query in Listing 2, and the results is as follows:
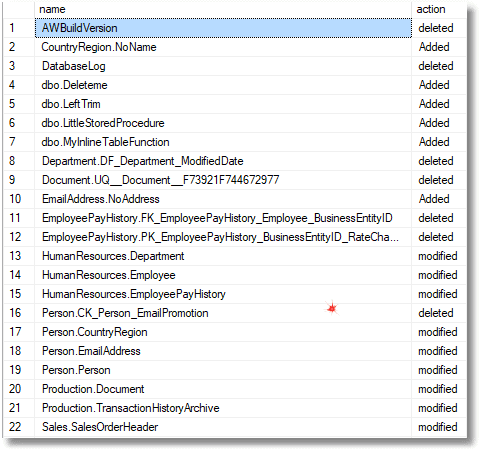
Fine so far, but I can tell you that testing this sort of query properly isn't quite plain sailing. Listing 3 shows just a small sample of the sorts of changes we'd want to make in order to test that Listing 2 catches all possible types of changes correctly. There are a lot of test runs before you can feel confident that the routine works, and for each one you'll need to check that the actual outcome meets the expected outcome. This is something you'll need to automate because checking the results by eye is too error-prone.
The trick to automating the test run is to create a temporary table as you execute the test database modifications. After each modification, there is some extra code that inserts into a temporary table all the results you expect to be reported by the test query, for each DDL statement. By keeping each test together with the expected result, then you are likely to be able to keep everything in sync so that each test has one corresponding record of what should happen.
Listing 4 shows just a section of the test code. You can download the full test code, DifferencesBetweenObjects.sql (this script includes the code from listing 2), from my SQLCloneFamily GitHub repository.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
--drop a default constraint
ALTER TABLE HumanResources.Department DROP CONSTRAINT DF_Department_ModifiedDate;
INSERT INTO #WhatHasHappened (object, action)
SELECT N'Department.DF_Department_ModifiedDate', 'deleted';
--drop a foreign key constraint
ALTER TABLE HumanResources.EmployeePayHistory
DROP CONSTRAINT FK_EmployeePayHistory_Employee_BusinessEntityID;
INSERT INTO #WhatHasHappened (object, action)
Values
(N'EmployeePayHistory.FK_EmployeePayHistory_Employee_BusinessEntityID',
'deleted'),-- When a FK constraint is changed, both ends are modified
(N'HumanResources.Employee', 'modified');
ALTER TABLE HumanResources.EmployeePayHistory
DROP CONSTRAINT PK_EmployeePayHistory_BusinessEntityID_RateChangeDate;
INSERT INTO #WhatHasHappened (object, action)
VALUES
(N'EmployeePayHistory.PK_EmployeePayHistory_BusinessEntityID_RateChangeDate',
'deleted'),
(N'HumanResources.EmployeePayHistory', 'modified');
|
Listing 4: Saving the expected outcome of each DDL change to #WhatHasHappened
Then, you just compare the result of running Listing 2 with what you expect it to be, stored in #WhatHasHappened, by comparing the two tables. I use EXCEPT for this.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
--CHECK the differences BETWEEN the two tables. It should be none
SELECT object COLLATE DATABASE_DEFAULT, action COLLATE DATABASE_DEFAULT
AS 'changes that were reported but not announced'
FROM @differences
EXCEPT
SELECT object COLLATE DATABASE_DEFAULT, action COLLATE DATABASE_DEFAULT
FROM #WhatHasHappened
SELECT object COLLATE DATABASE_DEFAULT, action COLLATE DATABASE_DEFAULT
AS 'changes that were announced but not reported'
FROM #WhatHasHappened
EXCEPT
SELECT object COLLATE DATABASE_DEFAULT, action COLLATE DATABASE_DEFAULT
FROM @differences
|
Listing 5: Checking the result matches expectations
Hopefully this will be an empty result. You can trigger an error on an IF EXISTS, but I generally don't bother. The result can be fed into whatever system you are using for your builds.
The whole process can be scripted in PowerShell. The only caveat I have is that once you've destroyed an existing clone and replaced it for a fresh one, it pays to refresh your query window in SSMS, otherwise the connection will get slightly confused about what is going on. If you make the connection afresh after the cloning process, then it is fine.
I've placed all the code for this project on GitHub, with the full source code.
Conclusions
Once you have SQL Clone, it can creep up on you and suggest all sorts of uses that aren't immediately obvious. This is because it causes a cultural change. Development Databases cease to be precious and fragile things that must be preserved at all costs. Instead, you get a lot more freedom to keep databases around in different forms and versions for the various purposes that crop up in the database development trade. Now, the creation of a fresh copy of a working database is so quick that there is hardly time to roll a cigarette.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
SQL Provision
Provision virtualized clones of databases in seconds, with sensitive data shielded
You may also like

Article
How to automatically provision sanitized data using SQL Clone, Data Masker and PowerShell
Chris Unwin describes a strategy, using data masking, cloned databases and PowerShell, which will allow you to sanitize data before provisioning test or development environments.

Article
How Redgate use SQL Clone internally to provision databases
An Interview with the Redgate IT Manager to discover how SQL Provision is being used to implement a new database provisioning process.
Article
Deploying and Reverting Clones for Database Development and Testing
Demonstrating how to use PowerShell automation to create a suite of clones, for testing or development work, with the ability to revert a clone to its original state, instantly, ready for the next set of tests to begin.
Article
New permissions features brings access control to SQL Clone
SQL Clone permissions give you simple control over who can access SQL Clone, and what they can do with it.

Article
Create, protect and manage non-production databases with SQL Provision
SQL Provision allows users to create copies of SQL Server databases in seconds, using a fraction of disk space, and mask any sensitive data to help address data privacy and protection concerns. It serves as a gateway between production and non-production environments, to ensure the safe distribution of database copies from one central location, without blocking the team's development and release processes.

Article
Basic data masking for development work using SQL Clone and SQL Data Generator
Richard Macaskill describes a lightweight copy-and-generate approach for making a sanitized database build available to development teams, using SQL Clone, SQL Change Automation and SQL Data Generator.
Loading comments...