
One of the common problems when you are developing databases is knowing what’s changed and when. You want to detect changes and to work out what has changed in a particular build. You’d have thought it would be an easy problem, when you consider that every database object in SQL Server’s system views has a date when the object was last modified. If you want to know what’s been changed since a particular date you would need to just list all those objects that have a ‘last-modified’ date greater than that date.
This actually works fine if you just want to be know whether objects have changed, but you are likely to want more than that. It is nice to know what’s been deleted too. While were about it, it is nice to see if something has been renamed or added.
This can all be achieved reasonably easy by querying the metadata, but unlike a database comparison tool, it can do little more than tell you what has changed rather than the way it has changed. It has a different objective. It gives you just the overview to track changes in a particular build. If you want to compare different builds, you can ‘t use it because the object_ids will be different. You’ll need to use a database comparison tool because the information you want to use is lost.
The problems with this technique come from the fact that some database components such as indexes, columns, parameters and distribution statistics aren’t considered to be objects, because they are parts of other objects, tables or routines in this case. When, for example, a column changes, the whole table changes and its last-modified date is changed to the time that the column was modified. However, some objects that are parts of other objects such as primary keys and constraints are considered to be objects in their own right. Sometimes they roll their updated modification date back to the parent object. Sometimes, rarely, they don’t. When a foreign key constraint is changed, both participating tables are flagged as being modified, which isn’t entirely intuitive.
Nowadays it is easier to use Extended Events to track database changes, but this requires a session to be running at the time to capture the event. If this isn’t possible, then the default trace may have the information. On the other hand, this may have been switched off, or the data may have got lost. This happens if the background noise of maintenance tasks drowns out the database modifications you want to track by pushing them out of the current default trace log. It is useless if you want to study the history of changes in a build.
In order to track database changes, you need to understand the thinking behind the way that the various database components are recorded in the system views. Objects that don’t have parents are typically views, table valued functions, stored procedures, service queues, inline table valued functions, tables and scalar functions. On the other hand, check constraints, default constraints, foreign key constraints, primary key constraints, sql triggers, and unique constraints have parents, and have no independent existence beyond their parent object. When the parent is deleted, so are the children. However Columns, parameters and indexes aren’t considered to be objects, just attributes of objects, so can only be tracked by their ids together with the object IDs of their associated objects.
Why bother with all this? If you maintain a single build, merely making changes to it for every internal release, then you can preserve just the values of the objects name, object_id, modify_date and parent_object_id in a database somewhere. If you do that for every integration, then you have the means to list out all the changes between any two releases. Hmm. I wonder what has changed since the beginning of May? (click click click.) Hmm. OK, it doesn’t tell you how it has changed, but it narrows it down! Another use: At the beginning of a day’s work, you save those four columns from the sys.objects table. At the end of the day, you run the query which identifies the changes. This allows you to script out all the changed objects into source control. With SMO (sqlserver), you can do it all automatically once you’ve devised a script to do it.
I started on this routine in order to monitor changes being made to clones, using SQL Clone. In this case, it is easy to save a json file with the required columns to disk when creating the image and use that to check on what has changed with each clone. One could even report on when the changes were made.
The table value you need in order to do comparisons is easily illustrated by using Adventureworks, but any database will do, obviously.
You can create a table to store these in, or maybe store them on disk. We’ll show the former method. Here is an example of such a table
|
1 2 3 4 5 |
CREATE TABLE DatabaseObjectReadings( Reading_id int IDENTITY, DatabaseName sysname NOT NULL, TheDateAndTime datetime NULL default GETDATE(), TheJSON NVARCHAR(MAX)) |
… then you can take an ‘insta-record’ of the state of a database (Adventureworks2016 in this case)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
INSERT INTO DatabaseObjectReadings (DatabaseName, TheJSON) SELECT 'Adventureworks2016' AS DatabaseName, (SELECT --the data you need from the test database's system views Coalesce(--if it is a parent, then add the schema name CASE WHEN parent_object_id=0 THEN Object_Schema_Name(object_id,Db_Id('AdventureWorks2016'))+'.' ELSE Object_Schema_Name(parent_object_id,Db_Id('AdventureWorks2016'))+'.'+ Object_Name(parent_Object_id,Db_Id('AdventureWorks2016'))+'.' END + name,'!'+name+'!' --otherwise add the parent object name ) AS [name], object_id, modify_date, parent_object_id FROM AdventureWorks2016.sys.objects WHERE is_ms_shipped = 0 FOR JSON AUTO) AS TheJSON |
… and reference them later. You could, if you want, just get a count of just the modifications
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT Count(*) FROM AdventureWorkstest.sys.objects new LEFT OUTER JOIN OPENJSON(( SELECT TOP 1 theJSON FROM DatabaseObjectReadings WHERE DatabaseName='AdventureWorks2016' ORDER BY TheDateAndTime desc )) WITH([object_id] int, modify_date datetime) AS original ON original.Object_ID = new.object_id AND original.Modify_Date = new.modify_date WHERE new.is_ms_shipped = 0 AND original.Object_ID IS NULL; |
This will tell you the number of database objects that have changed. However, I guess you’d want more than that. This involves several comparisons between the two table values of objects so you either need a CTE or some table variables.
I’ve given a CTE version of the code in an article I’ve written elsewhere that describes how I went about the chore of testing the development of the code for this. However, that is only capable of comparing two databases on the same server. It is more useful if could compare with a JSON string, or file-based data. The best performance and versatility comes from an inline table-valued function. Here we first create the table type and table-valued function before preparing the data and passing it to the function. OK, it may look slightly cumbersome, but it is quick.
I’ve taken the original from a version stored in a DatabaseObjectReadings table. I made a copy of AdventureWorks 2016, and ran a few deletions and modifications on it to test it out. Naturally, you can compare two versions of the same build of a database when you have neither of them, just a record of relevant columns in sys.objects.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
IF Object_Id('dbo.DatabaseChanges') IS NOT NULL DROP FUNCTION [dbo].[DatabaseChanges] IF EXISTS (SELECT * FROM sys.types WHERE name LIKE 'DatabaseUserObjects') DROP TYPE [dbo].[DatabaseUserObjects] CREATE TYPE [dbo].[DatabaseUserObjects] AS TABLE ( [name] sysname, object_id int, modify_date Datetime, parent_object_id int ) go CREATE FUNCTION [dbo].[DatabaseChanges] ( @Original DatabaseUserObjects READONLY , @Comparison DatabaseUserObjects READONLY ) RETURNS TABLE AS RETURN ( SELECT Cloned.name, 'Added' AS action --all added base objects FROM @Comparison AS Cloned --get the modified LEFT OUTER JOIN @Original AS Original-- check if they are in the original ON Cloned.object_id = Original.object_id WHERE Original.object_id IS NULL AND cloned.parent_Object_id =0 --if they are base objects and they aren't in the original UNION ALL --OK but what if just child objects were added ... SELECT Clonedchildren.name, 'Added' -- to existing objects? FROM @Original AS Original-- check if they are in both the original INNER join @Comparison AS Cloned -- and also they are in the clone ON Cloned.name = Original.name --not renamed AND Cloned.object_id = Original.object_id --for ALL surviving objects inner JOIN @Comparison AS Clonedchildren--get all the chil objects ON Clonedchildren.parent_object_id =cloned.object_id LEFT OUTER JOIN -- and compare what child objects there were @Original OriginalChildren ON Originalchildren.object_id=ClonedChildren.object_id WHERE OriginalChildren.object_id IS NULL UNION ALL --all deleted objects but not their children SELECT Original.name, 'deleted' FROM @Original AS Original --all the objects in the original LEFT OUTER JOIN @Comparison AS Cloned --all the objects in the clone ON Cloned.name = Original.name AND Cloned.object_id = Original.object_id WHERE Cloned.object_id IS NULL AND original.parent_Object_id =0 --the original base objects that aren't in the clone UNION ALL --all child objects that were deleted where parents survive SELECT children.name, 'deleted' FROM @Original AS Original INNER join @Comparison AS Cloned ON Cloned.name = Original.name AND Cloned.object_id = Original.object_id --for ALL surviving objects inner JOIN @Original AS children ON children.parent_object_id =original.object_id LEFT OUTER JOIN @Comparison AS ClonedChildren ON children.object_id=ClonedChildren.object_id WHERE ClonedChildren.object_id IS NULL UNION ALL SELECT Original.name, CASE WHEN Cloned.name <> Original.name THEN 'renamed' WHEN Cloned.modify_date <> Original.modify_date THEN 'modified' ELSE '' END FROM @Original AS Original INNER JOIN @Comparison AS Cloned ON Cloned.object_id = Original.object_id WHERE Cloned.modify_date <> Original.modify_date OR Cloned.name <> Original.name ) GO |
Now we can use this function do check on the difference between any two saved versions of the database or the current state of the database.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
DECLARE @original AS DatabaseUserObjects DECLARE @Changed AS DatabaseUserObjects INSERT INTO @Changed SELECT --the data you need from the test database's system views Coalesce(--if it is a parent, then add the schema name CASE WHEN parent_object_id=0 THEN Object_Schema_Name(object_id,Db_Id('AdventureWorksTest'))+'.' ELSE Object_Schema_Name(parent_object_id,Db_Id('AdventureWorksTest'))+'.'+ Object_Name(parent_Object_id,Db_Id('AdventureWorksTest'))+'.' END + name,'!'+name+'!' --otherwise add the parent object name ) AS [name], object_id, modify_date, parent_object_id FROM AdventureWorksTest.sys.objects WHERE is_ms_shipped = 0 INSERT INTO @Original SELECT [name], object_id, modify_date, parent_object_id --the data you need from the original database's system views FROM OpenJson(( SELECT TOP 1 theJSON FROM DatabaseObjectReadings WHERE DatabaseName='AdventureWorks2016' ORDER BY TheDateAndTime desc )) WITH(name NVARCHAR(4000),[object_id] int, modify_date DATETIME, [parent_object_id] int) AS original SELECT * FROM DatabaseChanges(@Original,@Changed) ORDER BY name |
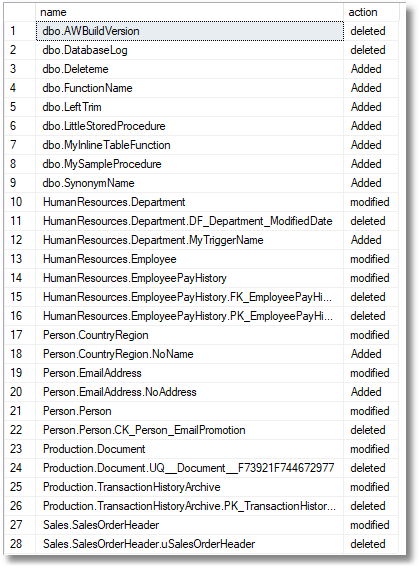
We can sort this another way, but this is the most obvious way because it groups the members of each schema together, and lists each object together with the child object that has changed, the parent first followed by the children.
You could, conceivably, do better by adding the details of the columns, indexes and so on that are related to these. However, that’s not the objective here because I just want to know what object is affected by the modification and I already know that. If you want all that stuff, you can buy a SQL Comparison tool!
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments