Create, protect and manage non-production databases with SQL Provision
SQL Provision allows users to create copies of SQL Server databases in seconds, using a fraction of disk space, and mask any sensitive data to help address data privacy and protection concerns. It serves as a gateway between production and non-production environments, to ensure the safe distribution of database copies from one central location, without blocking the team's development and release processes.
Updated November 2018
DevOps practices, applied to the database, aim to allow an organization to deploy databases at the frequency they need, without introducing an unrealistic administration burden, and without compromising that organization’s compliance with data privacy or security regulations. By incorporating SQL Provision into your Database DevOps toolchain, you’ll have a lightweight, centrally managed, automated and secure way to provide database copies, and the right data, to all parts of the organization that need it. It will:
- Automate the whole database provisioning process – making it easily auditable
- Manage provisioning from a single central location – giving transparent control over what data goes where and who can access it
- Replace sensitive data with realistic, anonymized, test data – an important part of your strategy in making sure database provisioning complies with relevant regulations regarding the use of sensitive or personal data.
- Create sanitized database copies (clones) in seconds using MB of storage – allowing teams to develop, test and fix code faster
Governance of sensitive and personal data
Adopting DevOps processes, for the database, should allow organizations to make better use of their data, when engaged in development, testing and training. For example, developers and testers will want ‘representative’ copies of production data for integration and acceptance testing, or to reproduce a production bug, and so develop and deliver a rapid fix. The BI team will want to export data for downstream reporting and analysis.
These are legitimate uses for this data, but only if the process used to distribute copies, outside the secure environment of production, complies with rules governing the protection of sensitive and personal information.
With the GDPR having been introduced on 25 May 2018, organizations…
These data protection and privacy concerns restrict the free movement of at least part of the data to the business activities that need it. Highly sensitive data must be removed prior to distribution, and replaced with generated data. All other sensitive and personal data needs to be obfuscated, and ‘pseudonymized’ such that it can no longer be directly attributed to a specific data subject. The whole process must be automated, and auditable so that it complies with national and industry regulations.
SQL Provision is comprised of SQL Clone and Data Masker for SQL Server. Data Masker allows you to predefine a set of data masking rules (such as substitution or shuffle), which define how each column and row should be obfuscated and anonymized. These rules form your masking set, which SQL Clone will apply as an integral step in a PowerShell-automated provisioning process.
Data masker can handle terabyte-scale databases, and can mask data while still preserving the relationships between the columns and tables in the database. Alongside encryption and data generation techniques, this ensures that data is sanitized and secure, when outside the production environment.
Central management of data movement
Centralized management of data movement is essential if you wish to pass an audit of compliance for GDPR. You must be able to prove that you know what data exists in the databases you wish to copy, to which ‘sensitivity’ category it belongs and therefore how it is protected, and then where that data goes, who has access to it, and how you dispose of it.
The central management server maintains a central record of what data copies (clones) exist on what servers, and who created them, and scripts can be run to remove clones automatically. Even the sanitized database copies should only be accessible to those people within the business who really need them. SQL Provision allows control over who can create and manage the cloned database copies.
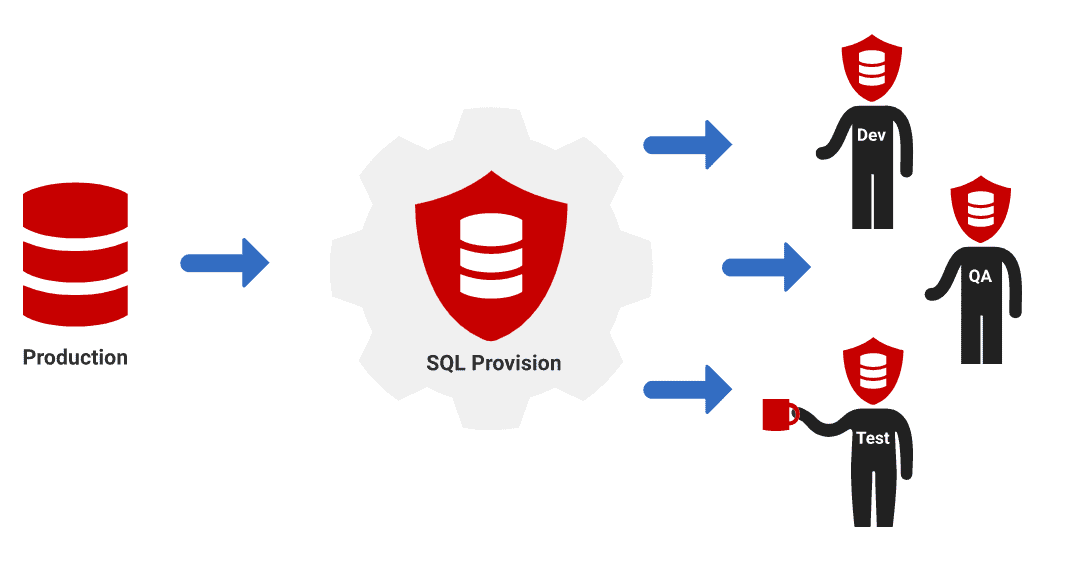
Fast database copying with a light storage footprint
A traditional, manual process for distributing sanitized database copies is no longer ‘fit for purpose’. The process is not auditable, as discussed above, and it does not scale. When databases run into hundreds of gigabytes, or terabytes, in size, storage administrators must manage the file systems and prepare sufficient space on local servers, or on the SAN. With the backup-and-restore method, the process of copying each database is often too slow to support the team’s requirements, since making a single copy of a 500 GB database can take about 5 hours.
If the business requires multiple, sanitized copies of large databases to be delivered to various parts of the business that need them, then a different approach is required. SQL Provision’s database copying component is SQL Clone, which exploits the existing virtualization technology within Windows to solve this DevOps problem.
SQL Clone creates just one full database copy, called an ‘image’, and then we can create multiple clones from that image. Each clone has access to the data in the image, which is immutable, and only the changes made to a clone are stored locally. This means that even for databases that are TB’s in size, each copy, or clone, requires only tens of MB of local disk space, and creating one takes seconds, not hours.
With appropriate permissions set up, developers and testers can even ‘self-serve’ clones. This is a big cultural shift, because it enables DevOps practices such as isolated development, and parallel test cycles. Use of realistic data during integration tests will help the team find data compatibility issues earlier in the release pipeline, as well as reproduce a ‘production bug’ in other environments, and develop a fix quickly.
Summary
SQL Provision allows a team to create a secure, scalable, and repeatable process for managing data as it moves through your SQL Server estate, without causing a significant administration burden. It supports fully the requirements of a software delivery process that relies on fast, frequent delivery of valuable functionality to end users.
SQL Provision has been priced so that small and medium sized enterprises can take advantage of it alongside large corporations. The tiered pricing model is based on the total size of the databases organizations need to provision, rather than the number of users. The development teams behind Data Masker and SQL Clone which comprise the SQL Provision solution are continuing to refine the tools to streamline data masking and database provisioning yet further.
Find out more about SQL Provision and grab your 14-day fully functional free trial.
Tools in this post
Data Masker
Shield sensitive information in development and test environments, without compromising data quality
SQL Provision
Provision virtualized clones of databases in seconds, with sensitive data shielded
You may also like
-

Article
SQL Server deployments: Which Redgate tools should you use?
Since 1999, we’ve been developing tools at Redgate to support database deployments for SQL Server. In the past couple of years, we’ve increased our effort in this space by further developing our proprietary technologies based on SQL Compare, and acquiring others like Flyway, the most popular database migration engine. As a result, we now offer
-

Article
Masking Dates in a Non-Production Database
Gerry Leith explores what’s required for the effective masking of dates and times in your data.
-

Article
SQL Clone and databases protected with TDE - part 1
Steve Jones proves that SQL Clone can create a clone from a SQL Server database that is protected by Transparent Data Encryption (TDE).
-

Article
Creating Multiple Masked Databases with SQL Provision
Chris Unwin explains how SQL Provision can create copies of multiple databases, each masked consistently, and deliver them as a group. This is useful when, for example, you are working with a Data Warehouse that contains several cross-database relationships.
-

Webinar
POPIA- Key challenges





