





Automating Builds from Source Control for the WideWorldImporters Database
Sample databases from Microsoft are like YouTube stars: they're quirky, popular with their fans, and always online somewhere. It makes them a common choice when it comes to creating prototypes, but their lovable quirkiness sometimes makes this tricky. Here, we'll be prototyping an automated database build from source control, for the WideWorldImporters database. Microsoft uses these databases to demonstrate every newfangled feature that they've cooked up, so to get our build process working successfully, we'll have to configure our target server to accommodate features that we may or may not be using in our own databases. Specifically, we'll cover special configuration for:
- Non-default filegroups: we'll use a pre-deployment script to handle these
- Memory optimized tables: we'll use the NoTransactions option for SQL Compare on our build task to make these work
- Case-sensitivity errors: WideWorldImporters contains a procedure with inconsistent case for a variable, which will cause an error if you run your build against a case-sensitive SQL Server Instance. We'll see how to identify the problem procedure and fix it.
In this example, I'll manage the WideWorldImporters source code using a "state-based" approach, with SQL Source Control, and then automate the build process with SQL Change Automation. If you want to see how to manage both your source code and automate builds entirely with SQL Change Automation (SCA), using a migrations-first approach, see Steve Jones' article.
Ready to follow along? Here's what you need to get started
At the time of writing, everything I'm showing in this post is either a free service or may be used as part of a free trial. Here's what you need in your environment to follow along.
A build server running SQL Server 2016 or higher, Git and the SQL Toolbelt
The version of SQL Server is important for this example because Microsoft's WideWorldImporters sample database only restores to SQL Server 2016 and higher. In my case, my 'build server' is a virtual machine on my laptop. It's where the build artifacts are stored and it's where the build agent is going to run. However, just for demo simplicity, I am also hosting my development databases on the same instance. This is not a good practice, but if you want to set up a simple prototype for learning in an isolated environment, it will work. For the demo, I used:
- SQL Server 2017 Developer Edition, installed in the VM.
- SQL Server Management Studio (SSMS) (v 17.9.1)
- Git (v 2.19) installed in the VM
- Redgate SQL Toolbelt. Installing this makes SQL Source Control available in SSMS.
An organization and project created in Azure DevOps
Azure DevOps currently provides many free options for creating repos and automating pipelines. Read more about pricing and sign up here. In your organization, you need to go to 'Organization Settings' (https://dev.azure.com/yourorganizationname/_settings/), click on Extensions, then click 'Browse Marketplace' and add two extensions:
- SQL Change Automation: Build
- SQL Change Automation: Release
I won't be using the Release extension in this demo, but if you're following along it's worth adding it now, in case you want to work with it after you get your build set up.
An Azure Pipelines self-hosted agent
I installed a self-hosted agent for Azure Pipelines into my build server using the Windows agent v2. Instructions for setting up agents for multiple operating systems are provided by Microsoft here. You need to have your organization set up in Azure DevOps before setting up the self-hosted agent, so that you can configure permissions.
Using a hosted agent is convenient, and Azure DevOps provides one, which Alex Yates demonstrates how to use in his Database CI article. However, the Hosted VS2017 agent uses SQL Server LocalDB behind the scenes, a variation of SQL Server Express Edition. It's designed to be streamlined and fast to install, and for those reasons it has some unusual settings, such as AUTO_CLOSE automatically enabled for databases. It also doesn't support In-Memory OLTP tables, and since we have those in WideWorldImporters, it's not the right choice for this build.
A copy of the WideWorldImporters sample database
We will restore the WideWorldImporters-Full.bak file to our SQL Server instance. Download it from Microsoft here.
I saved this file to the location "S:\MSSQL\Backup\WideWorldImporters-Full.bak" on my build server, and I restored it to my SQL Server with this command.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
IF DB_ID('WideWorldImportersDev') IS NOT NULL BEGIN
ALTER DATABASE WideWorldImportersDev
SET SINGLE_USER
WITH ROLLBACK IMMEDIATE;
END;
GO
/* Restore - and replace if it exists */
RESTORE DATABASE WideWorldImportersDev
FROM DISK='S:\MSSQL\Backup\WideWorldImporters-Full.bak'
WITH
REPLACE,
MOVE 'WWI_Primary'
TO 'S:\MSSQL\Data\WideWorldImportersDev.mdf',
MOVE 'WWI_UserData'
TO 'S:\MSSQL\Data\WideWorldImportersDev_UserData.ndf',
MOVE 'WWI_Log'
TO 'S:\MSSQL\Data\WideWorldImportersDev.ldf',
MOVE 'WWI_InMemory_Data_1'
TO 'S:\MSSQL\Data\WideWorldImportersDev_InMemory_Data_1';
GO
|
Step 1: Get WWI development database into source control
We have a database; now we need a place to put the source code. The remote Git repo will be hosted on Azure DevOps, and we'll have a local repo on the build server.
1.1 Create an empty repo in Azure DevOps
In Azure DevOps, you may create a new project, or use an existing project that you've already set up for non-production testing. Inside the project of your choice, create a new repository, or 'repo', using the 'Git' type. I named my repo WideWorldImportersDemo. I also selected to add a README file, which is a good practice.
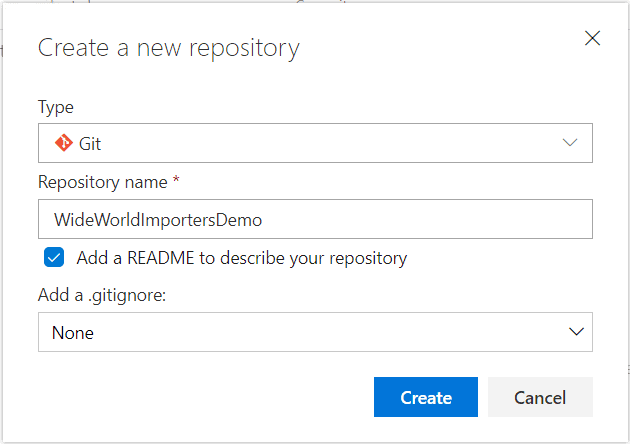
1.2 Clone the repo to your build server
We need to pull down a copy of our repo to a folder on our build server. That's because when we commit code, SQL Source Control will write the commit locally to the folder, then give us the option to push the commit up to the shared repo.
To clone, we need to know the HTTPS address for our repo. You can get this by clicking on 'Clone' in Azure DevOps and copying the address:
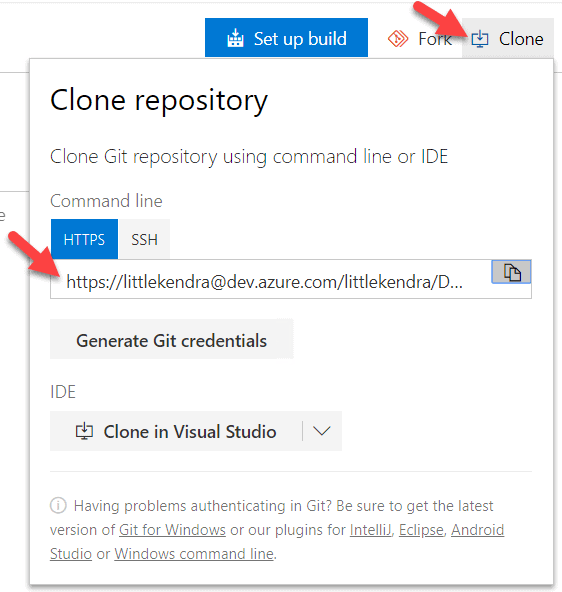
My organization is named 'littlekendra' and my project is named 'DM', so my repo address is https://littlekendra@dev.azure.com/littlekendra/DM/_git/WideWorldImportersDemo
I decide that I'd like to have my local files under C:\Users\Kendar\Source\Repos for this prototype, so I navigate to that directory and then run:
Git clone https://littlekendra@dev.azure.com/littlekendra/DM/_git/WideWorldImportersDemo
Of course, for something other than a temporary prototype, you probably don't want to store the source files on the build server in a user's profile directory. This is a private learning environment, so I'm keeping it simple.

Shazam, I've got a copy of my empty repo cloned to my build server.
At this point, I'm going to add a new directory into the repo. I do this in PowerShell by first changing to the WideWorldImportersDemo folder and then making a new directory:
cd .\WideWorldImportersDemo\ mkdir Source
You could also do this in Windows File Explorer, if you prefer. Here's what my folder looks like now:
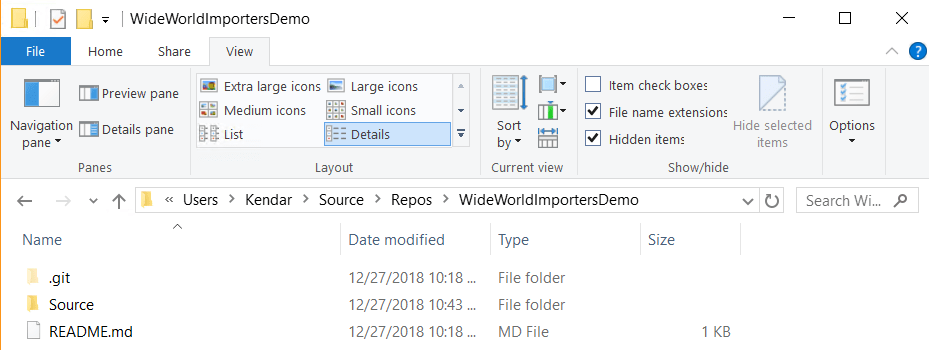
At this point, the 'Source' folder is only in my local copy of the repo, but that's OK. We'll use it in the next step.
1.3 Link WideWorldImportersDev to SQL Source Control
Next, open SSMS, right-click on the WideWorldImportersDev database in the Object Explorer pane and select 'Link database to source control…'.
This opens the SQL Source Control pane. I want to link to my Azure repo, which is the Git type, so I select that option in the wizard and click 'Next'. After that, I'm prompted to specify the target folder in my cloned Git Repo. I choose the 'Source' folder which I just created in my local copy of my WideWorldImportersDemo repo, and then click 'Link'.
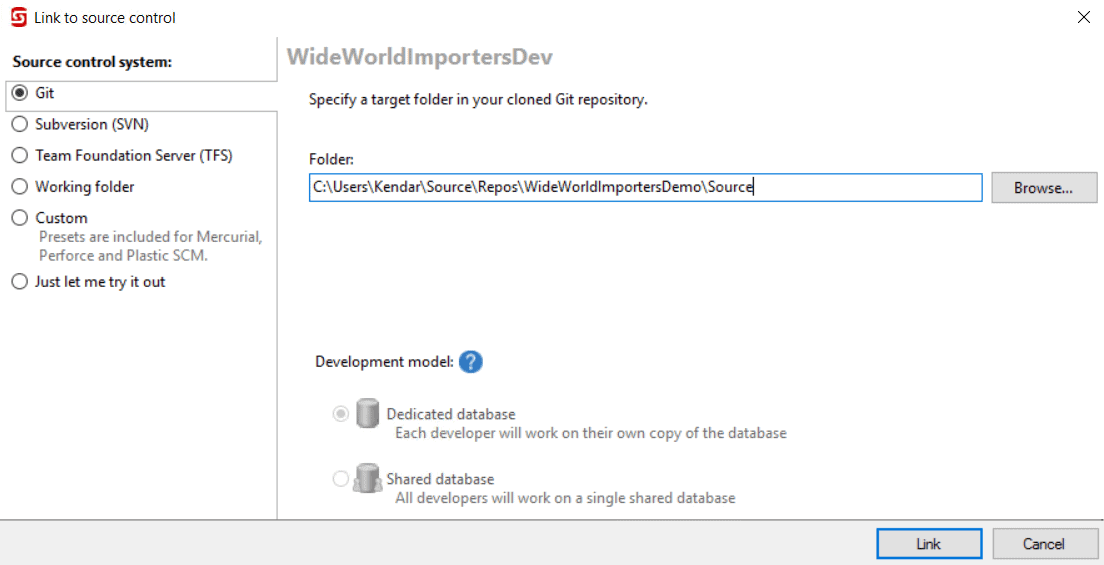
This establishes a link between the database and my local copy of the repo.
1.4 Configure comparison options for WideWorldImportersDev (optional)
Once linked, the 'Setup' tab in SQL Source Control is displayed. Note that the icon for our database also changes in Object Explorer to denote that SQL Source Control is configured for our database.
Under the covers, SQL Source Control uses the SQL Compare comparison engine. It compares the source to the target and generates a list of objects that exist only in the source or exist only in the target or exist in both but have differences. In this case, the source is the WideWorldImportersDev database and the target is simply an empty source control directory. SQL Compare then generates a deployment script to synchronize the target with the source.
We can exert some control over how SQL Compare performs these comparisons and deployments, using the 'Comparison options' under 'Options just for this database', within the Setup tab. I'm going to change some configuration items specific to WideWorldImportersDev, to try to circumvent some issues that I know might cause us problems.
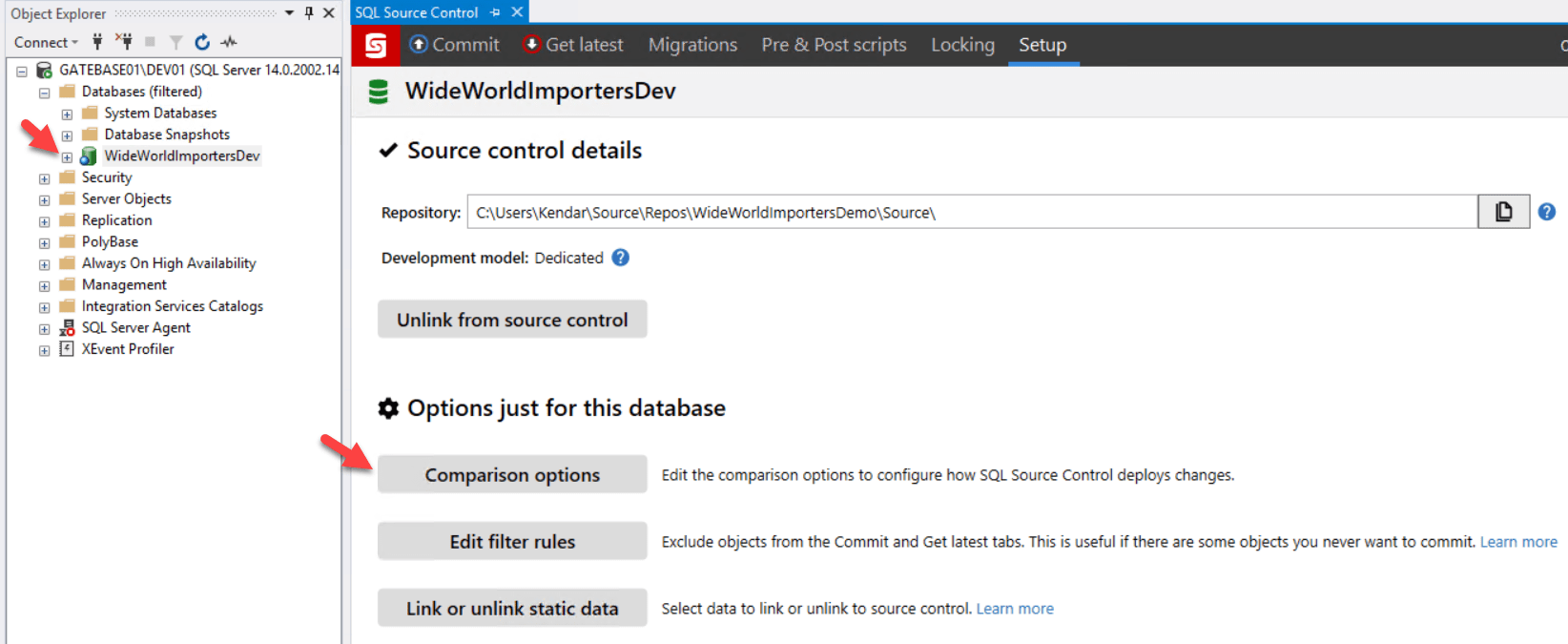
I'm going to enable two options that are not enabled by default. Firstly, I'll enable 'Don't use transactions in deployment scripts', because I know that my database contains objects (memory-optimized tables), and any changes to them can't be deployed as part of a transaction (more on this later). Secondly, I'll enable 'Use case-sensitive object definition', because my SQL Server instance is installed with a case-sensitive collation. This is a preference that I have for my personal SQL Server development instances, because I've been caught too many times writing code that worked fine on a case-insensitive instance, but broke when someone tried to use it on a case-sensitive instance
1.5 Commit and push our configuration options and database source code
I click on the 'Commit' tab at the top of SQL Source Control to review what I can commit. Here is how it looks:
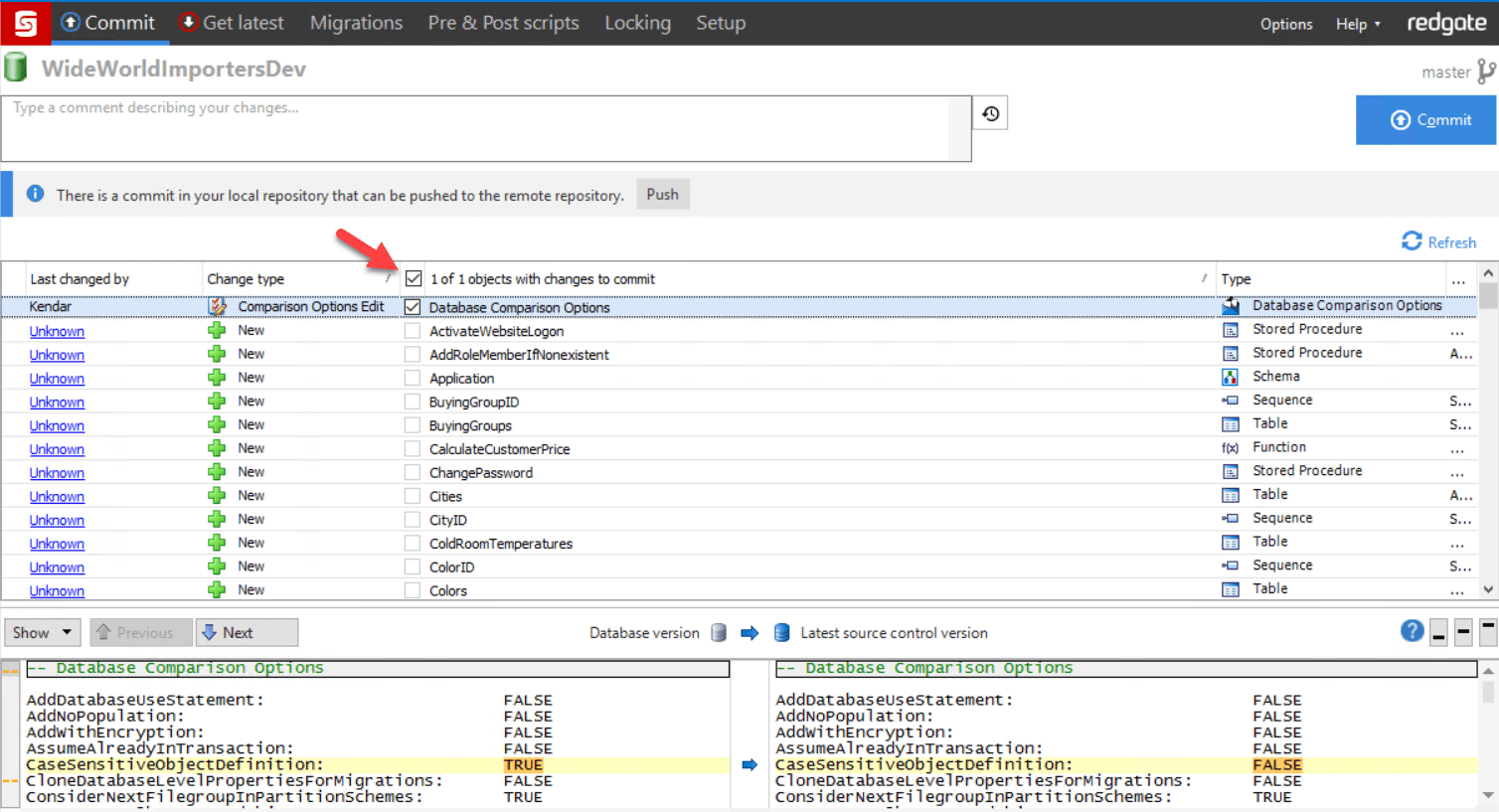
Note that I already have a commit in my local repo that can be pushed. That commit was a database project file, RedGate.scc, which was added to my Source folder when I linked to source control. I do not need to push that commit now.
Since I have changed my comparison options, there is only one object with changes that can be committed right now. SQL Source Control wants to commit those comparisons before moving forward. I check off 'Database Comparison Options' and then click 'Commit'. After this commit completes, the screen refreshes, and I can now select all 132 objects found in the WideWorldImportersDev sample database, and then click 'Commit' for those.
At this point, a warning pops up, letting me know that the WideWorldImportersDev has some custom filegroups installed:
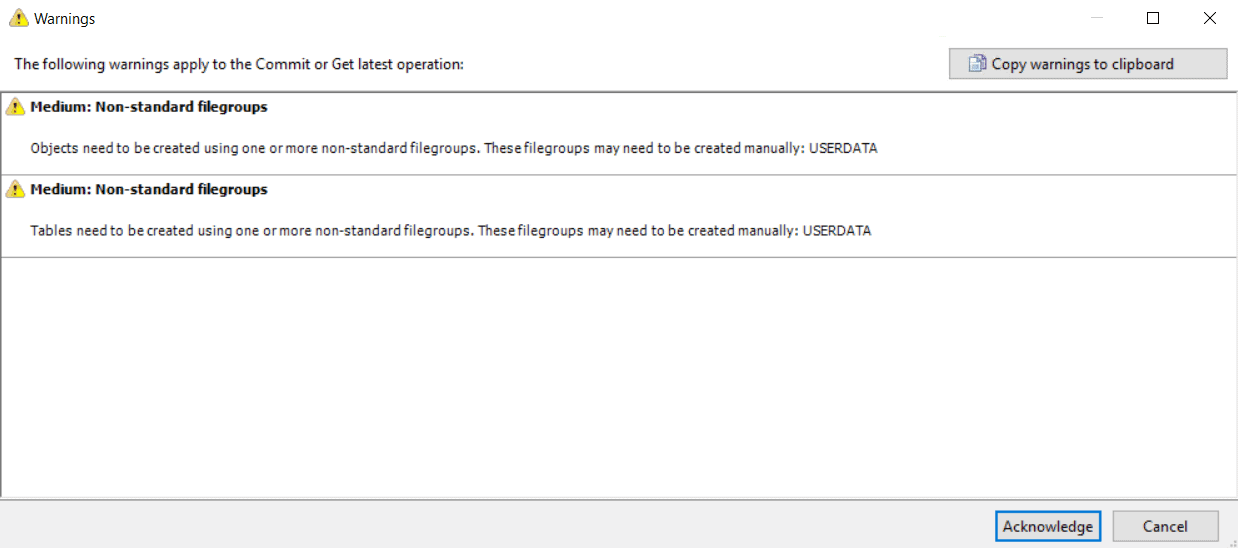
I copy this warning off and save it so that I don't forget, then click 'Acknowledge'. My commit completes successfully. Now I have no items pending commits to my local repo, and three commits ready to push to my remote repo.
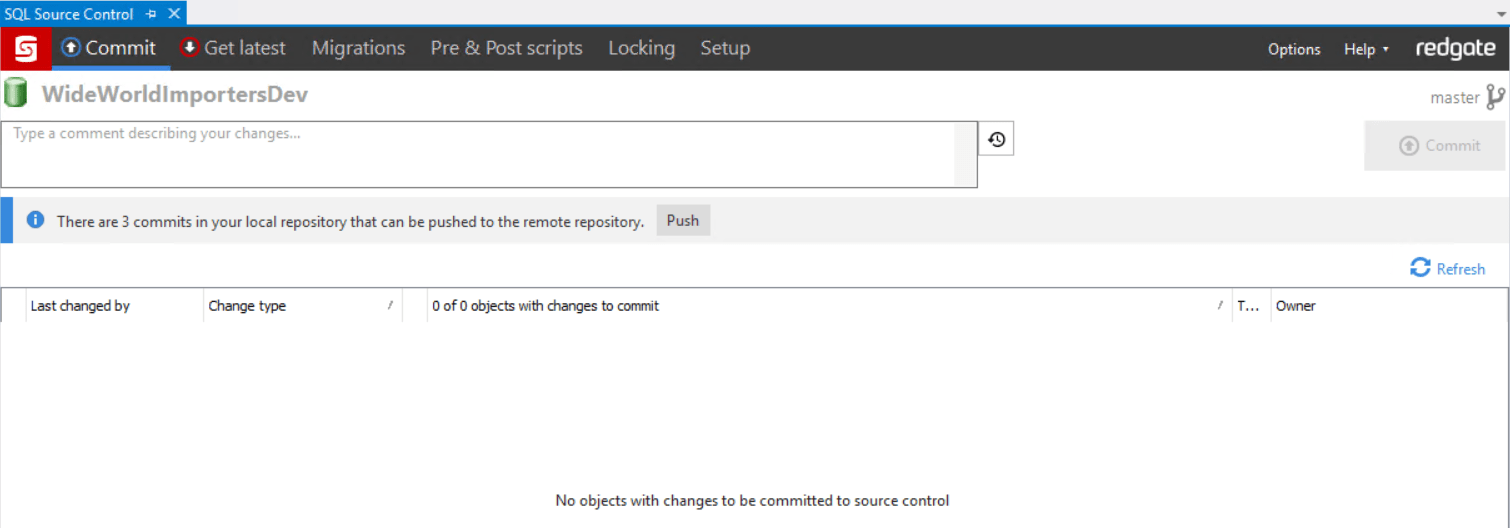
I click 'Push', and SQL Source control syncs the changes from my local copy of the repo up to my Git repo in Azure DevOps. Going back to Azure DevOps in my browser, I navigate into my repo and I can see my source code organized into folders:
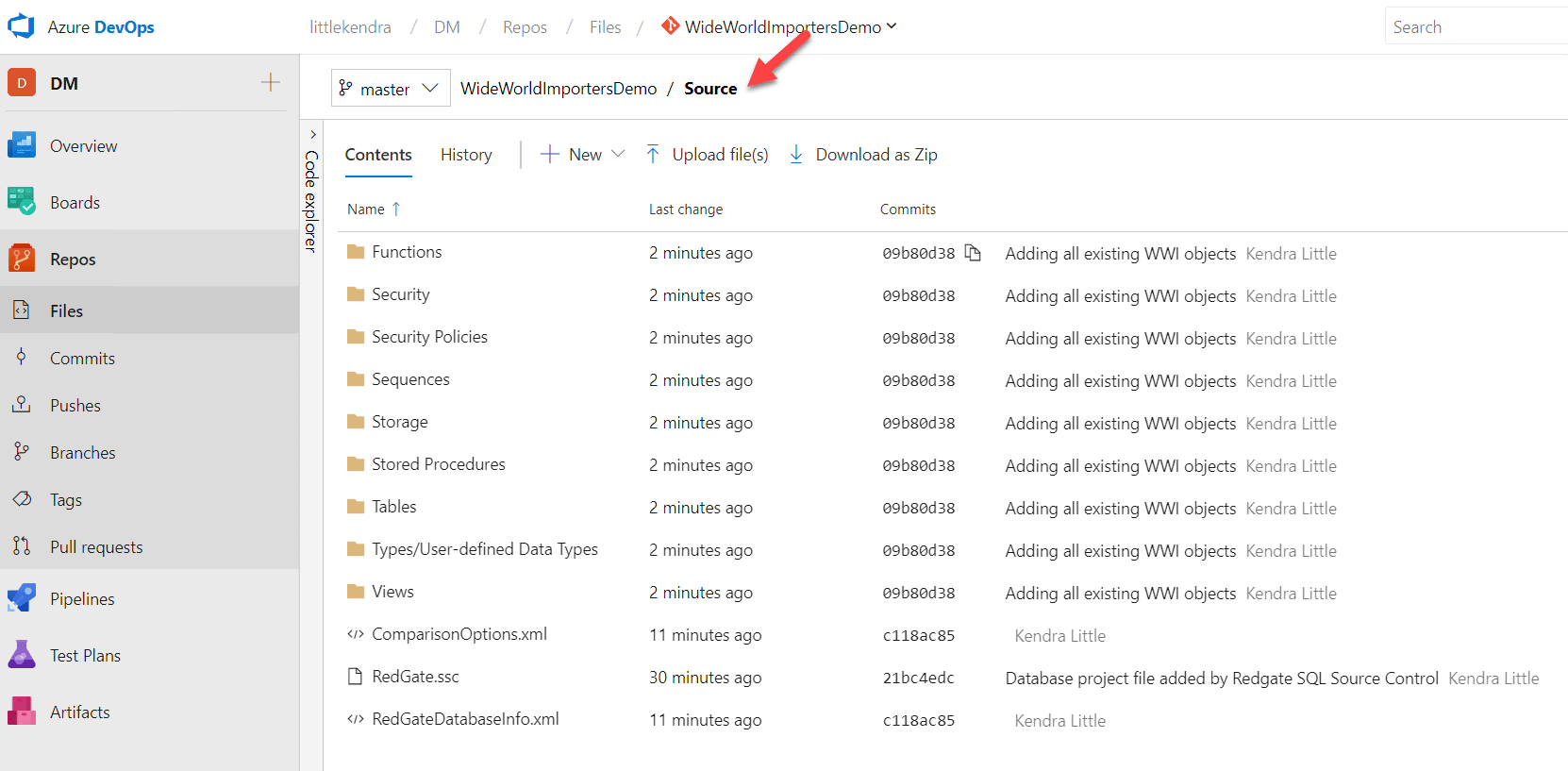
The code for my objects is stored in individual .sql files inside these folders. I can click around and review the contents of each file anytime (or review them on my local cloned copy with File Explorer, SSMS, or PowerShell, too).
Step 2: Set up a build with SQL Change Automation in Azure DevOps
Now that we've set up our source control processes, we want to trigger a new database build every time a change is pushed to the team repository, on Azure DevOps. To do that, we're going to set up a new build pipeline.
2.1 Configuring the Build pipeline
In Azure DevOps, click on Pipelines, then Builds, and then 'New', followed by 'New build pipeline'. Select 'Azure Repos Git' as the source, and the project and repo that you set up, in my case named WideWorldImportersDemo.
On the 'Select a template' screen, I select 'start with an Empty job'.

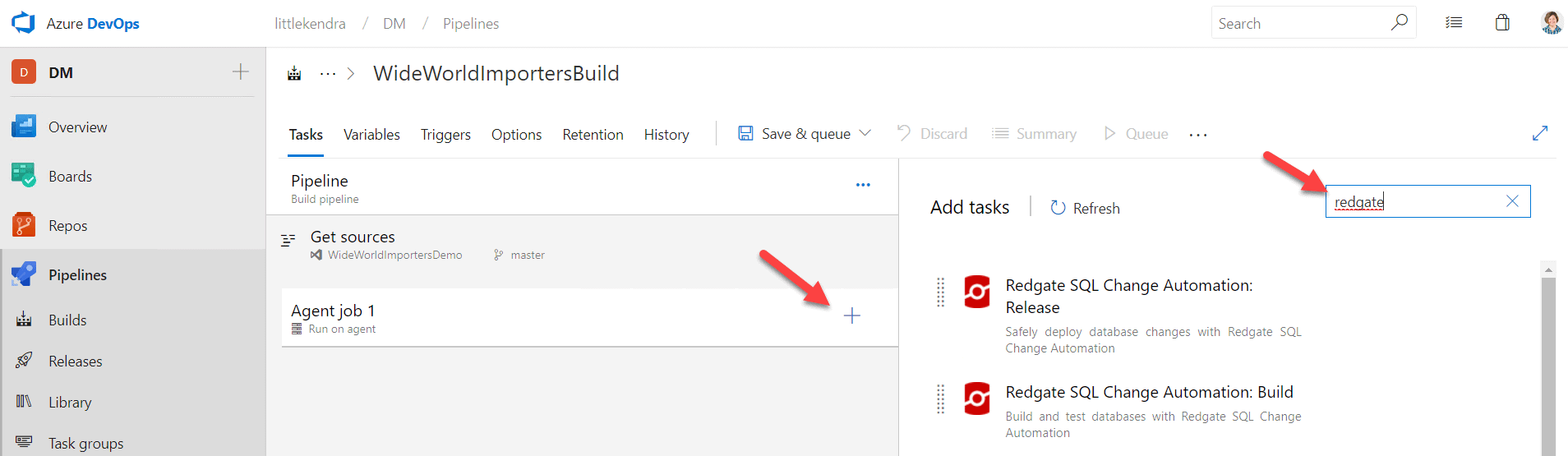
I name my job 'WideWorldImportersBuild'.
I set my agent pool to a 'Private' agent (that's a self-hosted agent), which I left named 'Default' when I configured my self-hosted agent. Next, I click on the plus sign under Agent job 1, to add a task. I type 'redgate' into the search bar to find my SQL Change Automation tasks, and I add the 'Build' task.
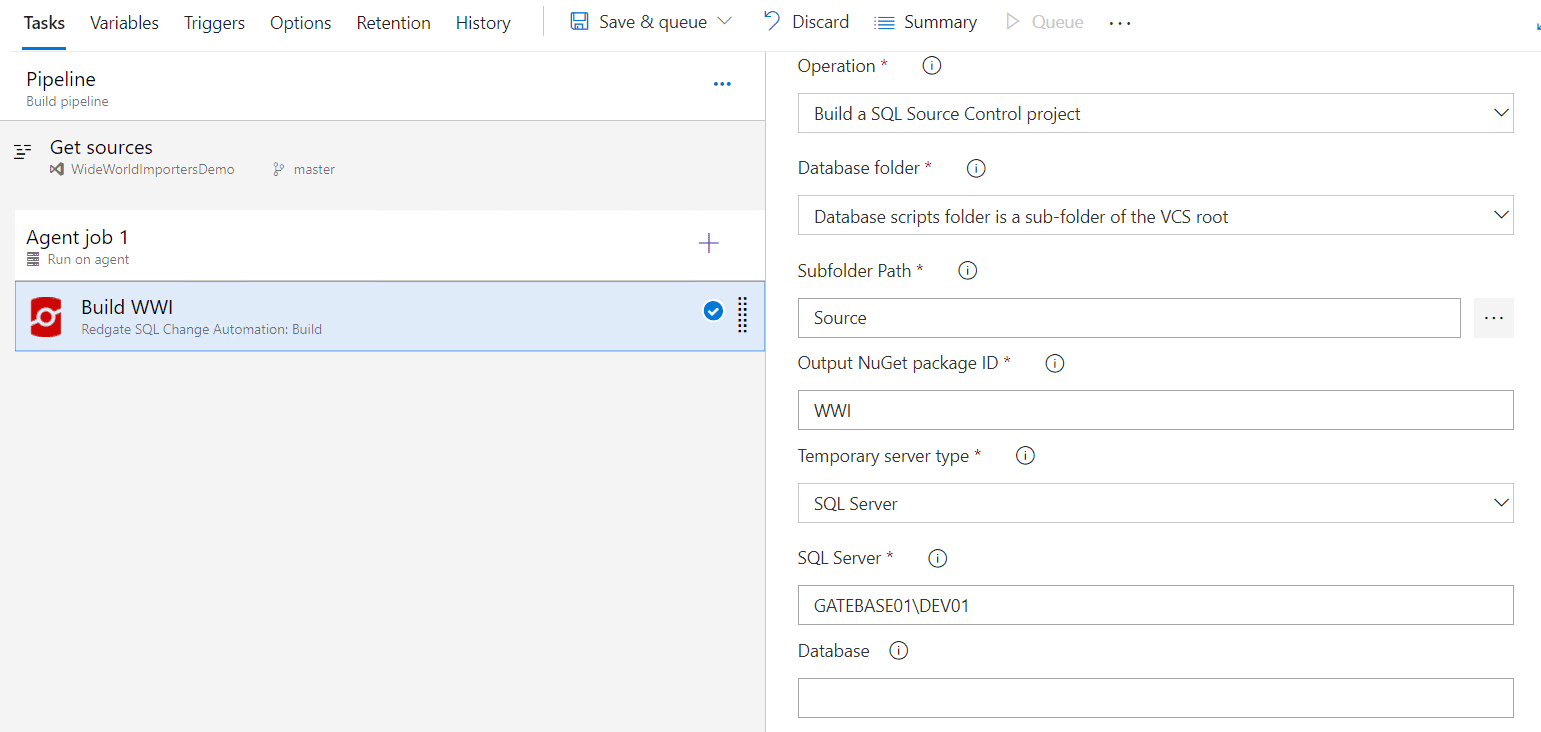
Now I need to configure settings for my build:
- Under 'Operation' I select, 'Build a SQL Source Control project' because I used SQL Source Control to script out the definition for all my objects. SQL Source control uses a state-first approach. If you used SQL Change Automation to add your database code to source control with a migrations-first approach, you would select 'Build a SQL Change Automation project' from the dropdown.
- Under 'Database folder' I select, 'Database scripts folder is a sub-folder of the VCS root'.
- Under 'Subfolder path' I browse to the 'Source' folder I created
- I set 'Output NuGet package ID' to 'WWI'
- For Temporary server type, I select 'SQL Server'
- For SQL Server, I enter the name of the SQL Server instance on my build server, where my self-hosted agent also runs
- I leave the 'Database' field blank. This means that it will be automatically assigned.
- I use Windows authentication
I want the build to run each time changes are pushed to the repo, so I click on the 'Triggers' tab and check 'Enable continuous integration' (CI).
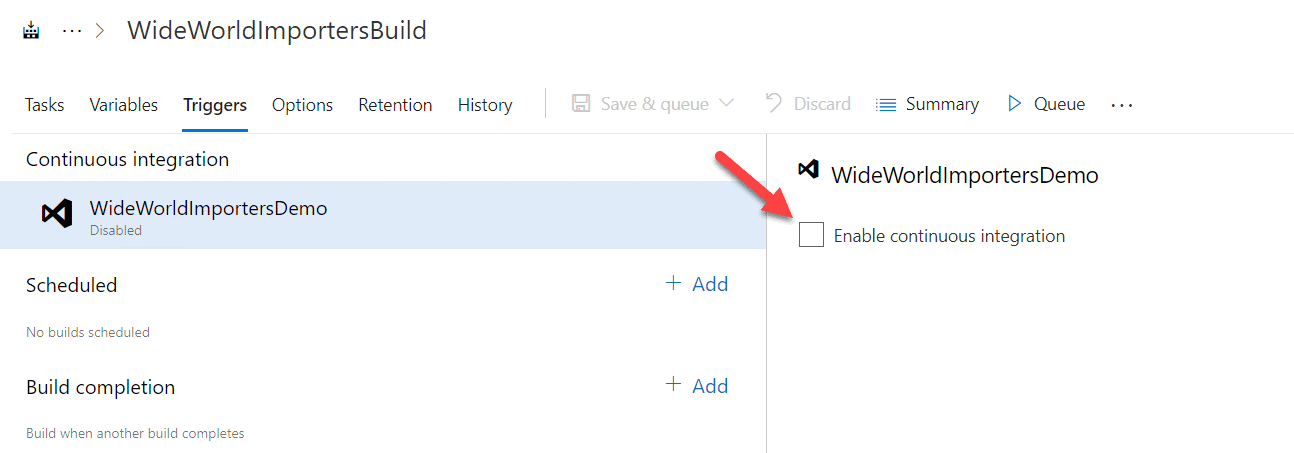
After setting these options, I click 'Save & queue' at the top of the screen, which kicks off a build.
2.2 Dealing with the build errors
My build fails. You knew something was coming, right? In fact, it fails for several reasons, and we'll just tackle each problem in turn.
2.2.1 Using pre-deployment scripts to handle non-default filegroups
Here is what the first error looks like: 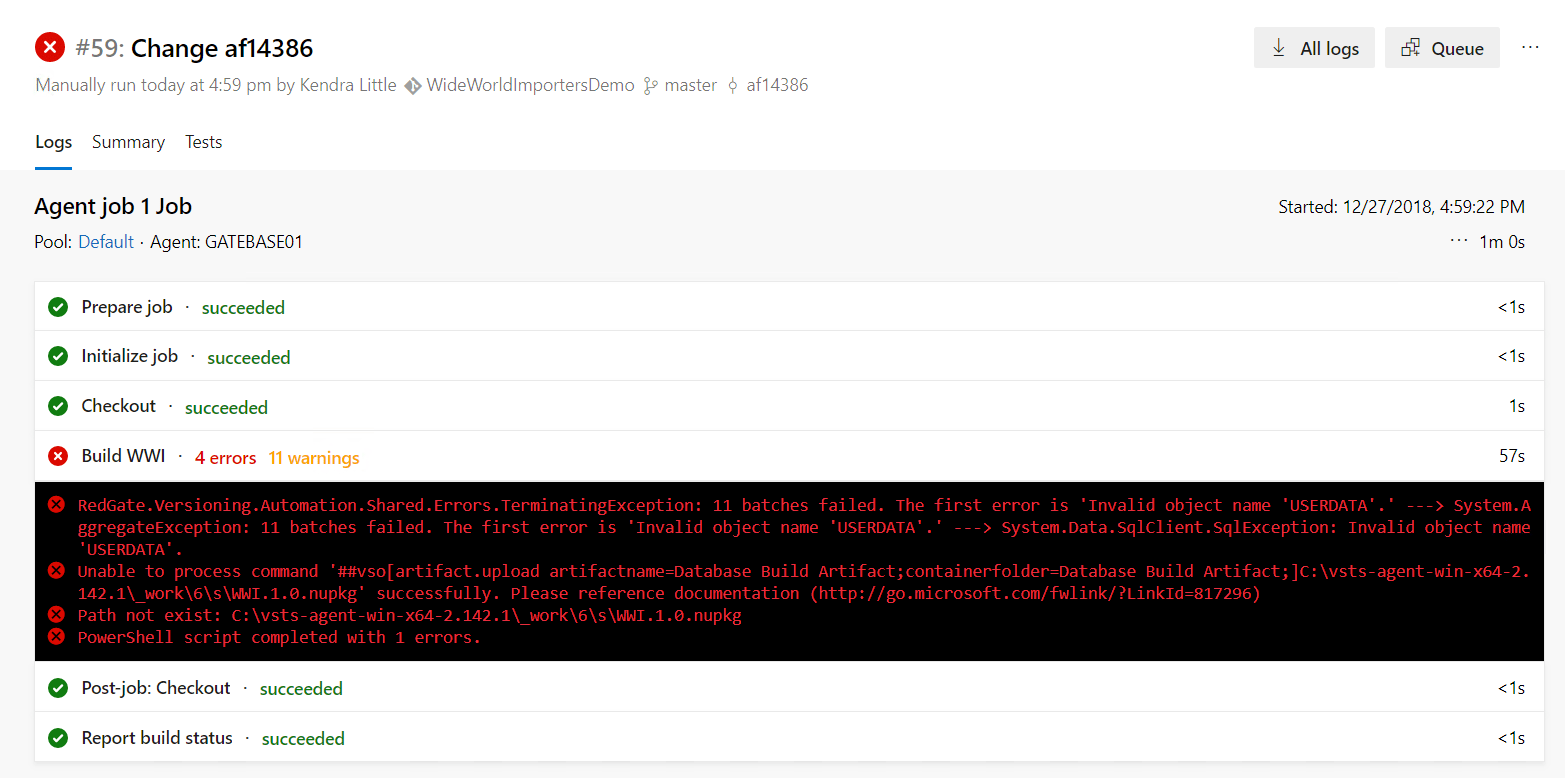
I can click on the error in that window and get detailed output, but everything we need to know appears in the summary, in this case.
The first error that occurred is related to USERDATA, which is a non-standard filegroup that SQL Source Control warned me about. SQL Source Control scripted out the source for our objects, committed the scripts, and pushed them to a repo. This only presents a problem when it comes time to use the scripts to build the database. At that point, under the covers, SQL Compare will need to devise a deployment scrip that creates the objects from source and validates that they will create successfully.
Filegroups are not an object in the database, and filegroup configuration is not scripted as part of the contents of a database. When we instruct SQL Change Automation build component to build the WideWorldImportersDev database, and it doesn't exist on the target, then it simply uses CREATE DATABASE WideWorldImportersDev to create an empty database on the target server, and the standard mdf and ldf files will be created in the default location for them on that server.
In this case, our database has non-default filegroups, and the definitions for some of our objects reference these filegroups. This means that we'll need to use a pre-deployment script to ensure that the target database is configured correctly.
SQL Source Control's pre-deployment and post-deployment scripts are a convenient way to handle database properties, such as filegroup configuration. Pre and post deployment scripts will be automatically run by SQL Change Automation when we execute a build, and they're also automatically run when you use SQL Compare from the command line or GUI, as well).
In this case, our pre-deployment script will alter the target database to make sure the filegroups exist before the build. Return to SSMS and, go to the 'Pre & Post scripts' tab in SQL Source Control, and click 'Add Pre-Deployment script'.
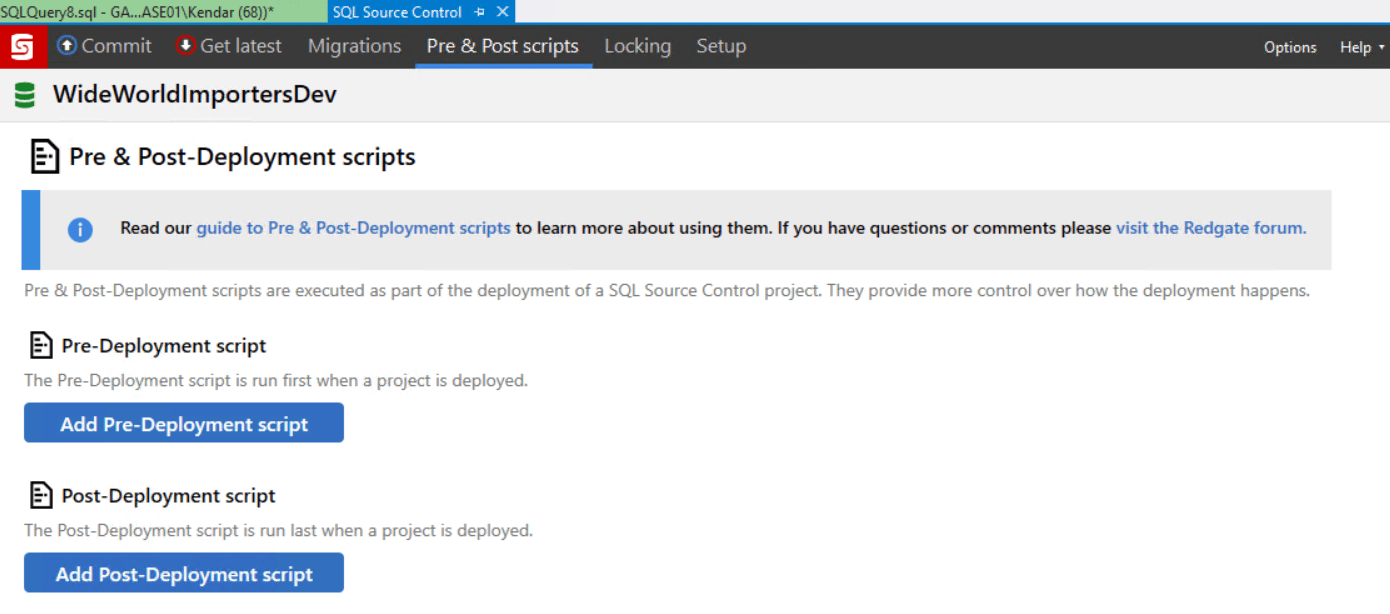
This opens and editor window where I enter the following code, and it is automatically saved as PreScript.sql:
https://gist.github.com/LitKnd/fd088af1087f742b5a83673092fa3aa5
This script will need modifications for your environment:
- I have a hardcoded server name set in two places ('GATEBASE01\DEV01') so that datafiles are only created by this script when run against a particular instance. This is done as an example of things you might want to do in a script like this to ensure that some of the script is only run against specific environments, but you probably don't have the same build instance I have, so you will need to change this.
- I want the script to generate unique filenames for each database on the instance to avoid conflicts, and I do this very simply by using the database name as part of the file path. Databases with special characters in the name will cause the script to fail. If you restored your WideWorldImporters with a name with characters which won't work in a file path, you'll need to customize.
I save the pre-deployment script, and this now shows as a change ready to commit.
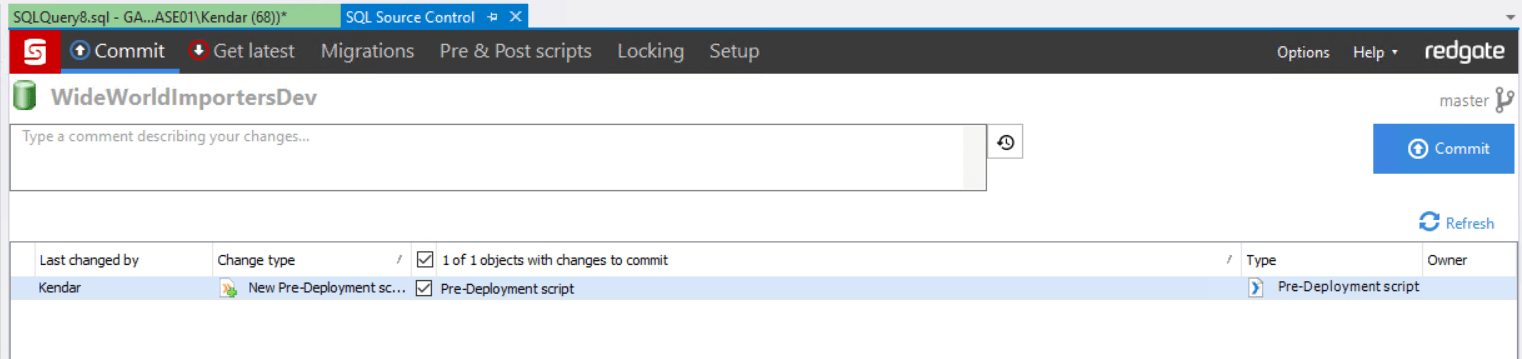
I commit the change and push it to the remote repository. Pushing this change to the repository triggers a build, because I configured a CI trigger on the build earlier.
2.2.2 Running the build script without a transaction
Our new build fails. But this time it fails with a different error:
|
1
|
DDL statements ALTER, DROP and CREATE inside user transactions are not supported with memory optimized tables
|
The error references something we mentioned earlier: we cannot deploy schema changes for memory optimized tables within a transaction.
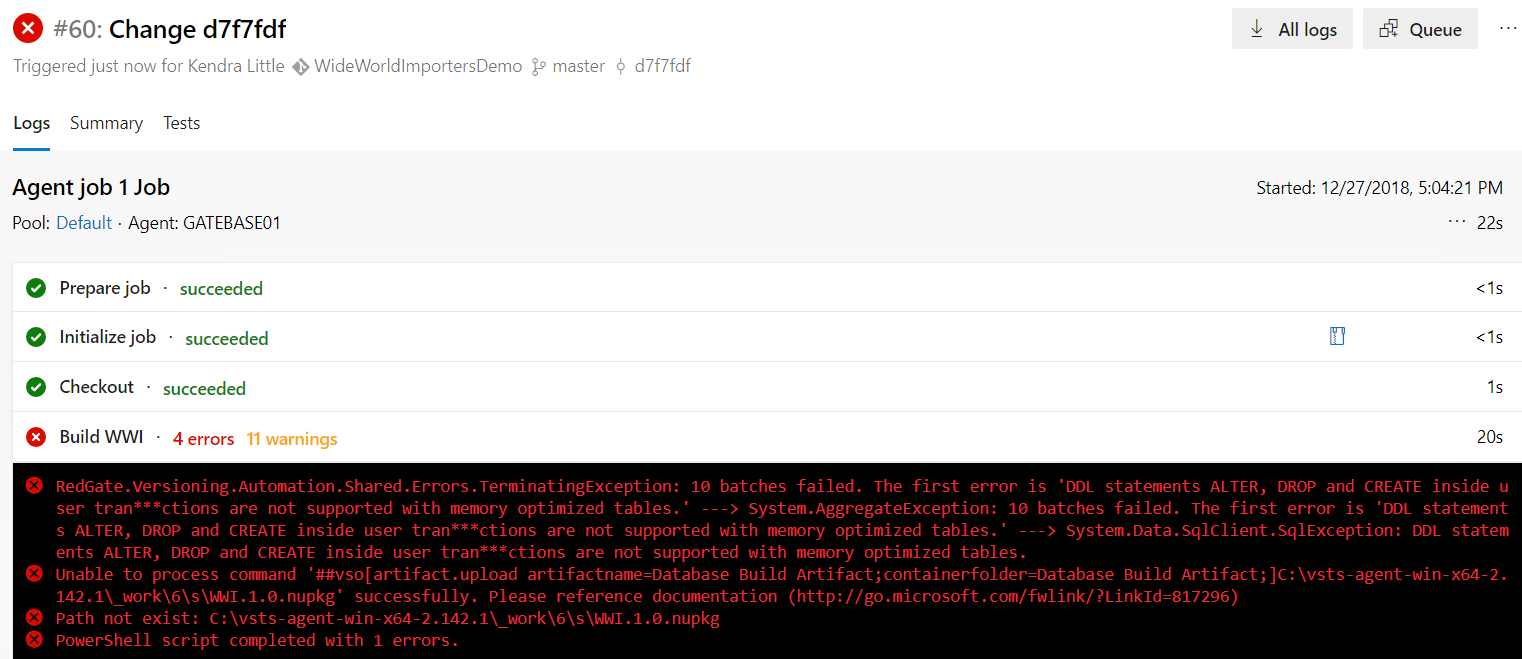
By default, Redgate tools run deployments within an explicit transaction. That way, if something goes wrong, it can perform a clean rollback of all the changes. If you have memory-optimized tables, which don't support modifications run in transactions, we need to avoid use of transactions when deploying changes to those objects.
You'll recall that earlier, we changed a setting in SQL Source control regarding transaction handling for deployment scripts. However, that setting is not picked up by SQL Change Automation. We need to edit the build task directly, and let it know that it shouldn't use transactions. This is done by checking 'Show advanced options', then entering 'NoTransactions' under SQL Compare options. A list of more SQL Compare options that can be used are in the documentation. Note that this need to specify NoTransactions in the compare options also applies to other tasks you may run in Azure DevOps for releases.
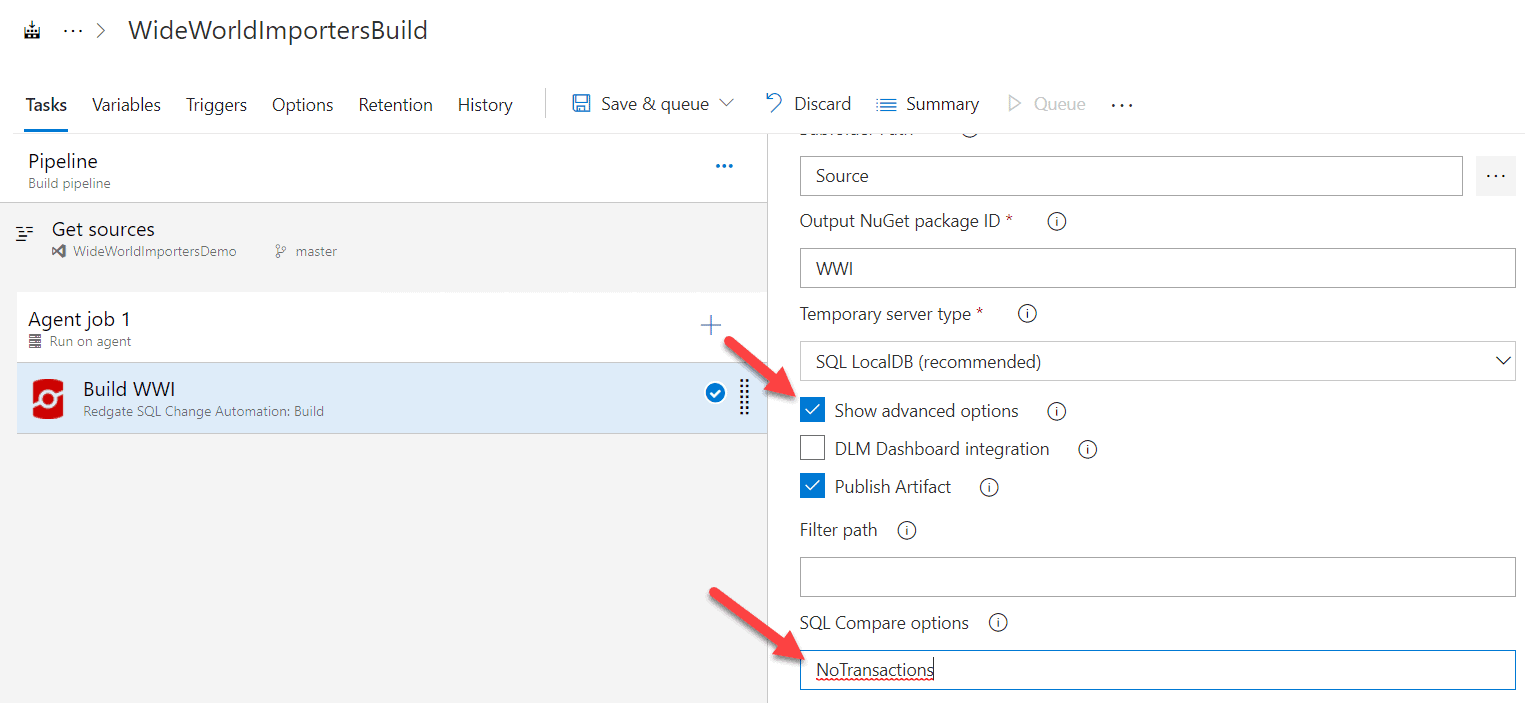
I make this change and save and queue the build.
Note that, for good reason, SQL Change Automation will issue a general warning when you generate a release artifact without transactions, as it can make updating existing databases dangerous:
This deployment will run without transactions. This could leave your database in an inconsistent state if it fails. We recommend backing up the database as part of the deployment or enabling transactions.
Don't turn transactions off silently, because it's something you should know about. Potentially you want to change your procedures to capture a backup or create a database snapshot before the deployment begins.
2.2.3 Dealing with deployments to a case-sensitive SQL Server instance
Once again, my build fails, but this time it's with a different error. This error occurs because I installed the SQL Server instance on my build machine using a case sensitive collation. This error will occur even if I uncheck the SQL Source Control setting 'Use case-sensitive object definitions', which I enabled earlier. The developers who work at WideWorldImporters aren't so good about case sensitivity, and one of their objects has a variable with inconsistent case.
Here's what the error looks like in the build:
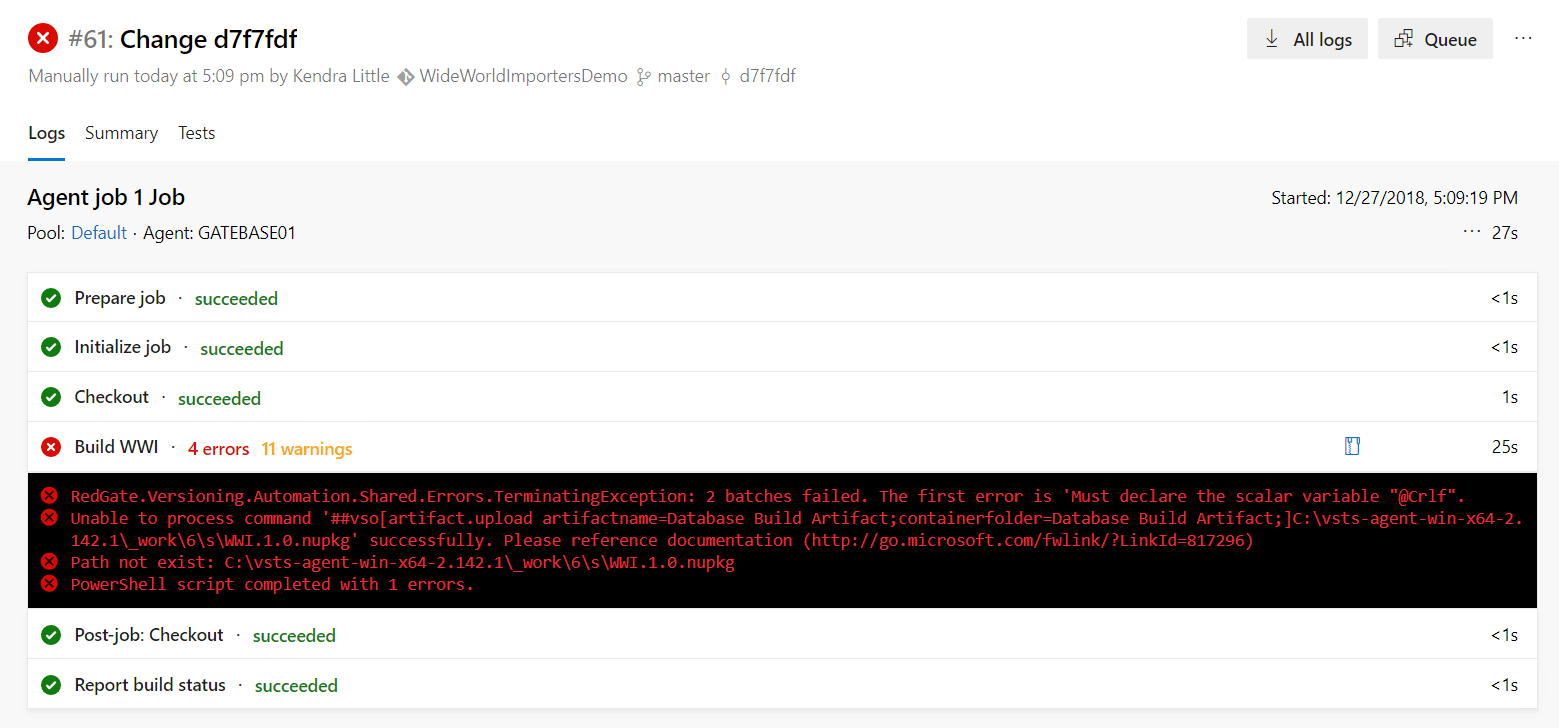
I want more information this time, so I click on the error and scroll to where the warnings began in the build.
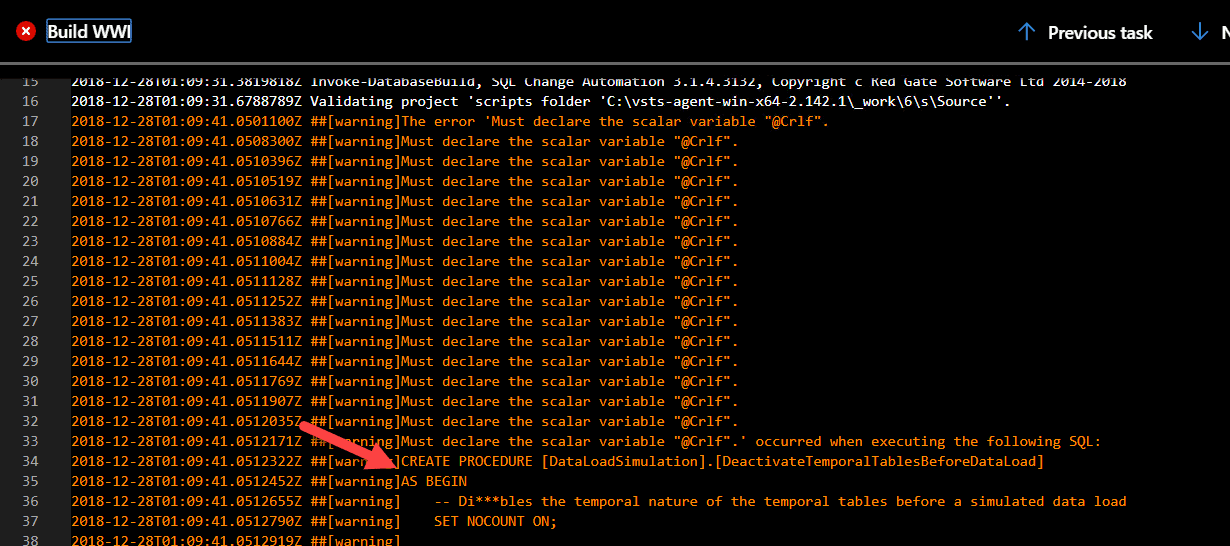
Either I need to run my build against a case-insensitive SQL Server instance, or change that procedure to make it use consistent case for @CRLF. I choose to change the procedure.
In SSMS, I modify the DataLoadSimulation.DeactivateTemporalTablesBeforeDataLoad procedure and replace all instances of @Crlf with @CRLF, using a non-case-sensitive search. This is detected as a change by SQL Source Control, because I've configured it to use case sensitive comparisons. I commit and push the change. In a real-world situation, even this small change is important, and would need to be released like any other change to avoid drift between my development environment and other environments.
As usual, pushing this change triggers my build since I have the continuous integration trigger set on my build pipeline.
2.3 We have a successful build!
Woo hoo! We've built the quirky WideWorldImporters database, even against my picky build SQL Server instance with its case-sensitive collation. Here's the detailed history of the build run:
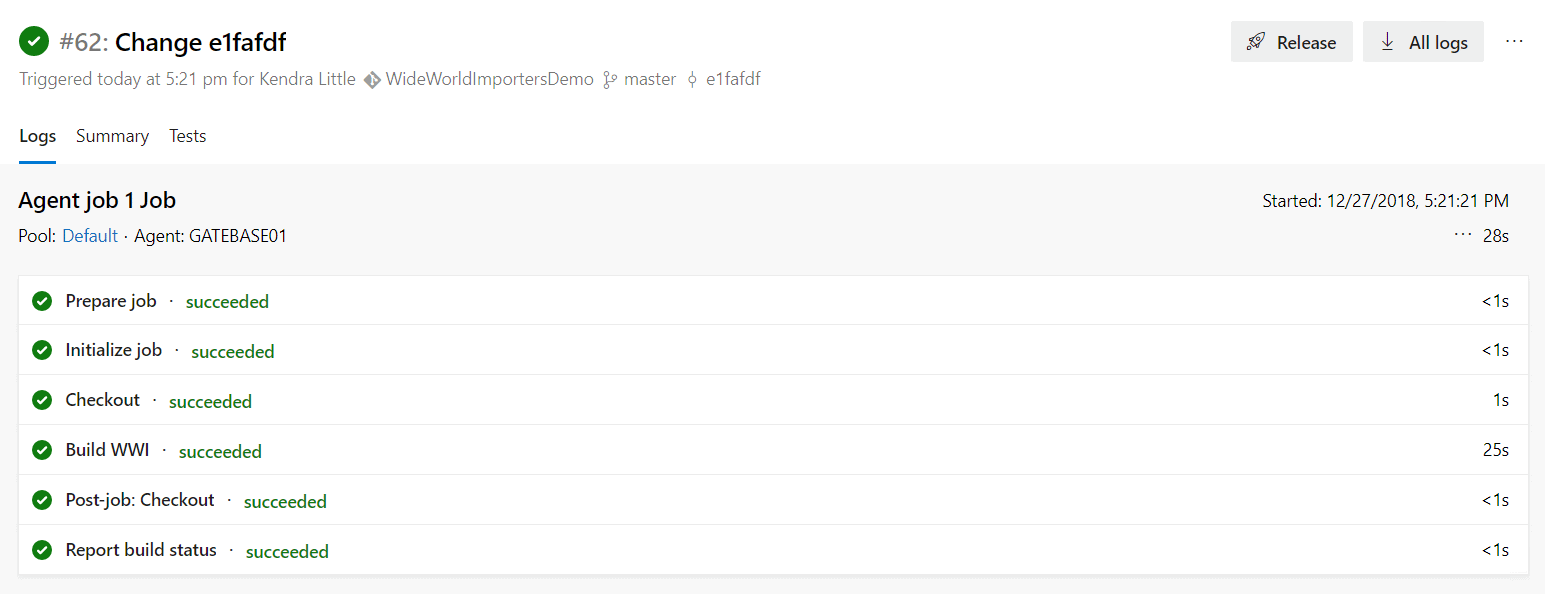
Now I have proven that all the code in my repository can be executed successfully against my build server, recreating the schema which I have stored in my Git repository.
Next steps
Now that I've set up a prototype with WideWorldImporters and configured a continuous integration build, I can test adding and modifying objects, and observing the build process. I can also configure a release pipeline in Azure DevOps using the SQL Change Automation: Release extension and set up automated tests and deployments for my code.
But those tasks are for another article.
A quick recap
When setting up Microsoft's free WideWorldImporters sample database, we were able to quickly add our code to a Git repo housed in Azure DevOps, but we hit a few issues that we needed to fix to get our build running properly:
- Non-default filegroups: when SQL Source Control shows you a warning about these, it's letting you know that you probably have some work to do to configure your build. The option we used to fix this is a pre-deployment script in SQL Source control that checks for the filegroups and files, and creates them if they don't exist. Pre and post deployment scripts are automatically run by SQL Change Automation, so we didn't need to configure our build task specifically to run this script.
- Memory optimized tables: WideWorldImporters contain memory optimized tables. Modifications to these types of objects can't be done within a transaction. To handle this, we added the 'NoTransactions' option for SQL Compare to the advanced options of our SQL Change Automation Build task.
- Case-sensitivity errors: These occurred only because WideWorldImporters contains a procedure using inconsistent case for a variable name and I ran my build against a case-sensitive SQL Server instance which refuses to compile that code. The build task in SQL Change Automation showed me the name of the problematic procedure so I could fix it (but I could also build against a non-case-sensitive instance if I had a lot of code like this and couldn't fix it immediately).
Tools in this post
You may also like

Article
How to examine differences with SQL Compare Summary View and SQL View
Jamie Wallis introduces the new Summary View, which is a tab that sits alongside SQL View and provides a more concise breakdown of the differences between two objects.
Article
Avoid running out of Disk Space ever again using Redgate Monitor
Redgate Monitor not only collects all the disk and database growth tracking data you need, automatically, but also analyses trends in this data to predict accurately when either a disk volume will run out of free space, or a database file will need to grow.

Article
Reverse-Engineering the Production Database into Source Control
Starting out a new database development with source control is relatively easy. To introduce source control into an existing database application can be more challenging. Phil Factor explains some of the fundamental steps.

Article
Getting Started with Automatic Database Branch Switching
Alexander Diab demonstrates how a team of developers can work on and test features in different branches of a SQL Server database development project, while their local development database automatically remains 'synchronized' with the current branch in version control.
Article
Effective Database Testing with SQL Test and SQL Cover
Julia Hayward describes the basics of how SQL Test’s code coverage can help uncover the darker, untested paths in your database code.
Article
Generating test data with localized addresses using SQL Data Generator
With basic grasp of regex expressions, a tool like SQL Data Generator can generate test data with addresses that are realistic for your part of the world.
Loading comments...