





Integrating SQL Server Tools into SQL Change Automation Deployments
When doing repetitive database work with SQL Change Automation (SCA) or SQL Compare, we often need to use other tools at the same time such as the registered servers in SQL Server Management Studio (SSMS), SQLCMD and BCP. I also tend to use the SQL Server PowerShell module, sqlserver (formerly known as sqlps). This uses Server Management Objects (SMO), which is Nature's Way of interacting with SQL Server and uses the same .NET library that underlies SSMS.
If you do so, you'll want to integrate all these tools as much as possible and, when you're scripting with PowerShell, to use the same database connections as you are using with SCA. This article is all about how you do that. We'll show how you can start integrating SCA scripts with SSMS into a single process. We'll also learn to stop fearing the connection string and view it as an ally. We will use one to create a SMO connection, via a serverConnection object, and borrow that same connection to execute BCP and execute a SQL Command.
The project
We have carefully saved any work we need to in Source Control, using whatever tool we prefer, and now want to deploy the latest version to all our development servers. This means we need to build a new database at that version, if one doesn't exist, or else update the existing copy to the new version.
Establishing the database source
In this article, I don't assume use of the Development component of SCA, where the resulting database source will essentially be a set of migration scripts. I use only SCA Deployment, specifically the PowerShell cmdlets, with the source in this case being a set of object-level build scripts that represent the current state of the database version we want to build.
In SSMS, we create a new Local Server Group called Development and register within it any development servers that need a copy.
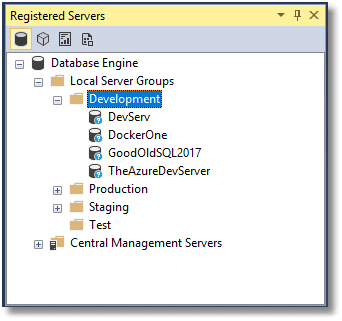
We can now run a script that builds our database and then 'releases' it to all our development servers. We'll add data as well because we then need to be able to run unit tests and integration tests. We don't just take production data because we need to compare performance figures from previous runs and check results against ones that we know are correct. This is just part of our daily integration run to ensure that the dev servers are all up to date with the latest changes.
When all this is set up, we can simply right click on Development (or Test) and run a PowerShell script in the resulting PowerShell window that either creates or updates a database on each server in that server group.
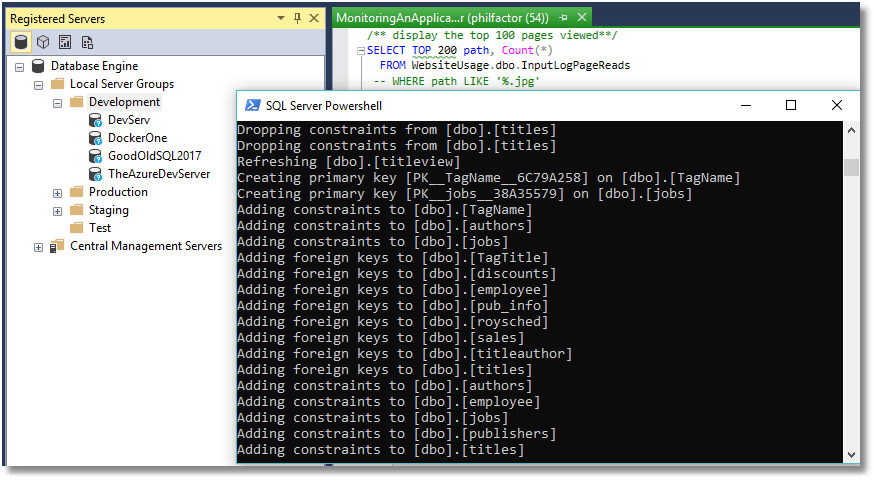
All the SQL Server instances in the group have now been updated with the version in source control. We have done it without having any IDs and passwords in the script itself or having to encrypt them in files within the user area. Also, it has taken the list of servers from our development group of servers which we can easily change.
Why do we need to use other tools in a script?
Surely, SCA gives you everything you could possibly need? Well, no, it is not a general interface into SQL Server, such as SSMS or VS. It merely provides add-ins to these tools, and several others, to assist with database development and deployment.
When I'm working on a database, I create SQL scripts in SSMS, save them to a Scripts directory that represents the build, run my unit tests and then run the script that will then build the database on all the development and test servers. This requires PowerShell or DOS scripting with a toolchain, choosing the best tools for each job. I'm likely to use SMO to create the database if required, SCA to build it, BCP to blast in the data, and so on. Routine tasks always get scripted away to save me time for the interesting aspects of work.
In this example, I want to keep the list of servers and, where necessary their credentials, in SSMS so that I don't then need to change the build script whenever I change the target instance. The Registered Server feature is ideal for this, but you do need to close SSMS before any changes become visible to PowerShell/SMO!
The script needs to create the database on the server if the database doesn't exist already. If I'm using PowerShell, then the sqlserver module does all that. I need to run a whole lot of checks that are outside the remit of SCA. Sometimes, I even need to stock the data in a built database using a command-line tool such as BCP. I don't want IDs or passwords in scripts as literals, certainly nothing stored anywhere in plain sight.
The Connection String
Connection strings are extraordinarily clever and contain everything you need to make a connection to a data source. They are in a structured format, so you can create, access and manipulate them as easily as you can a JSON string. They can pass on a lot of parameters that influence the way that a connection is made. A connection string specifies the server and database as well as the authentication methods and credentials. It also allows you to specify a lot more besides, such as the type of security used, the timeout, packet size encryption, language and so on.
You might shrug and say that connection strings are a thing of the past now that you use Windows Authentication. However, even now the ability to specify the user and password is handy, even if you generally only access SQL Servers within the domain. If you haven't the problem of mixed methods of authentication, then lucky you. At the time of writing, it is impossible to use Windows Authentication with SQL Server instances hosted in Docker in a Linux VM. It is possible to use Azure Active Directory to connect to Azure but not all of us are using that.
The easiest way to create a connection string is to use an online tool or to look it up in a library site. You can do it in PowerShell too, using the DbConnectionStringBuilder or SqlConnectionStringBuilder classes. The joy of using the .NET classes is that it makes it easy to change an existing string. We'll show an example in the script where we must add a database to an existing connection string. You can also extract any value from them too, which is useful for a tool that doesn't understand connection strings such as BCP.exe or SQLCMD.exe.
In short, if you can use a connection string for any server or database, then it makes scripting far easier because all the relevant details of a database connection are held together in what amounts to a structured document.
Deploy the latest versions of a database to all servers in an SSMS group
In the routine that follows, we have two pipelines. Most of the work is done by a pipeline that processes each SQL Server instance in turn, either building or updating the database that you specify. If a new database is created, it is remembered and in the second pipeline, we fill it with data. In other words, the second pipeline fills just the databases that you create, rather than any you update.
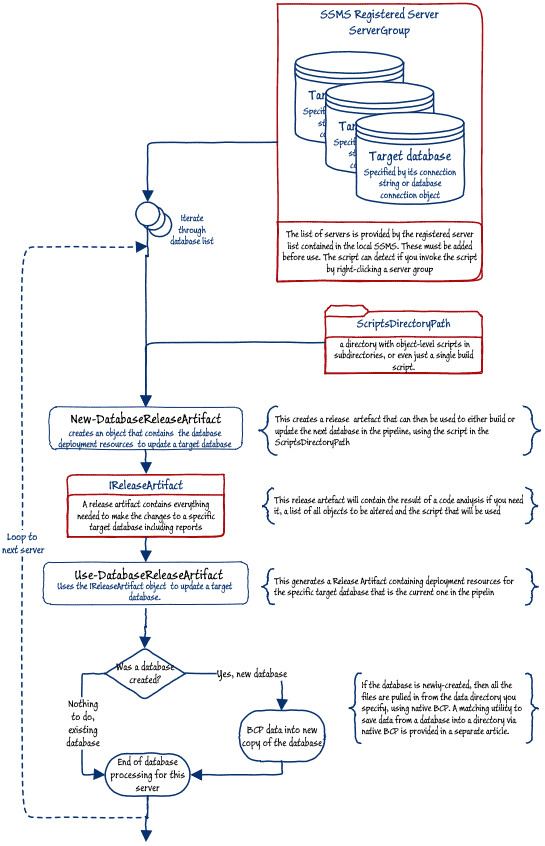
The list of servers, along with their connection strings, is provided by the local registered servers. This script is designed to be usable either from within SSMS or, if you wish, from Powershell IDE, or Windows Scheduler.
I've configured the script, so it detects whether you are running it from the Server Group in SSMS and changes to that location as default. So, when launching a deployment from within SSMS, it will simply use the server group from which the PowerShell session is invoked. You can, for example, deploy the new version to all the servers in your Test group, simply by right-clicking on that folder and selecting Start PowerShell. When the PowerShell window appears, you invoke the script within it like this:
|
1
|
& MyFilePath\NameOfFile.ps1
|
If you run the script outside SSMS, then it uses the location of the Development group, by default, but you can change that to whatever is appropriate.
All you need t do before running it is specify the full location of the source control directory (I've provided the source for the pubs database to get you started), as well as the full name of the database you are building. Listing 1 shows the PowerShell for the first pipeline.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
Import-Module SqlChangeAutomation
import-Module sqlserver #
$VerbosePreference = 'continue'
$ErrorActionPreference = 'stop'
$SourceDirectory = 'C:\MyPathToTheDatabase\scripts'
$ReleaseArtefacts = @()
$DatabaseName = 'MyHotDatabase'
$blacklist = @('MyDudServer')
$ServerGroupPath='SQLSERVER:\sqlregistration\Database Engine Server Group\Development'
#is this being started in SSMS in the registered server window?
if ((get-item .).GetType().name -eq 'ServerGroup') {$ServerGroupPath=(get-item .).PSpath}
<# fetch the list of all our registered servers.
for this to work, and this is not being started in SSMS, as when scheduled
you need a 'development' group in the base of your development servers in SSMS
So we gather all the servers in, including any in subgroups and just get each
server (we assume that one server may have two roles) #>
$serverList = dir -path $ServerGroupPath `
-recurse | where { $_.GetType() -notlike '*ServerGroup*' } |
Select servername, connectionstring | sort-object -property servername -unique
<# for each unique server in the group, or any subgroup, install the database #>
$DataBasesNeedingData=@()
$serverlist | where { $blacklist -notcontains $_.servername } | foreach-object {
<# we now install the database on every server in the registered server group #>
write-verbose "connecting to server $($_.ServerName)"
$mySrvConn = new-object Microsoft.SqlServer.Management.Common.ServerConnection
$mySrvConn.ConnectionString = $_.connectionString
$WhatImCoonectedTo = $mySrvConn.ExecuteScalar('Select @@Servername')
if ($mySrvConn.InUse -eq $true)
{
$srvr = new-object ('Microsoft.SqlServer.Management.Smo.Server') $mySrvConn
if ($srvr.status -ne 'online')
{ throw "could not connect to server $($_.ServerName)" }
<# ------- if the database doesn't exist ... --------#>
If ((($srvr.Databases |
select Name | where { $_.Name -ieq $DatabaseName }) |
measure).count -eq 0)
{
<# ------- ...then create a new version of the database --------#>
write-verbose "creating database $DatabaseName"
$DatabaseObject = `
New-Object ('Microsoft.SqlServer.Management.Smo.database') `
($srvr, $DatabaseName)
$DatabaseObject.Create()
$DataBasesNeedingData+=$DatabaseObject #add it to our collection
}
# add the database to the connection string
$sb = New-Object System.Data.Common.DbConnectionStringBuilder
$sb.set_ConnectionString($_.connectionstring)
$sb.Add('Database', $DatabaseName)
write-verbose `
"creating release artifact for $DatabaseName on $($sb.'data source')"
$iReleaseArtifact = new-DatabaseReleaseArtifact `
-Source $SourceDirectory `
-Target $sb.ConnectionString `
-AbortOnWarningLevel None
try
{
Use-DatabaseReleaseArtifact `
-ErrorAction Continue -InputObject $iReleaseArtifact `
-DeployTo $sb.ConnectionString `
-AbortOnWarningLevel None >"$($env:TMP)\Log.txt"
}
catch
{
$errorCaught = $_;
<# catch the error (should be warning) from post build check #>
if ($errorCaught.CategoryInfo.Category -eq 'InvalidResult')
{ write-verbose "Exception Message: $($_.Exception.Message)" }
else { throw $errorCaught }
}
}
else
{
write-verbose "Could not connect to $($_.ServerName)"
}
}
|
We can, of course, now stock the database with data as part of the routine, though this makes sense only if we are creating it from scratch. We therefore check whether we created the database and save the server object if we did so. That allows us to then stock the database with data.
For the attached BigPubsData.zip, I used SQL Data Generator to fill the pubs database with lots of development data then outputted it to create a set of BCP native-format data files, as demonstrated in Scripting out SQL Server Data as Insert statements via PowerShell.
We saved the server object, so we can borrow its connection to pass the credentials to BCP. However, BCP can't use a connection string, sadly, which is no problem if you are using Windows security, but otherwise we must use SQL Server credentials, which we extract from the username and password.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
<# -------Fill the new database with data if required --------#>
<# Now we BCP all the table data in. As we are using native mode the utility
disables constraints for the table before doing the import #>
$dDataSyncPath = ' C:\MyPathToTheDatabase\Data'
$DataBasesNeedingData | foreach{
$Buildserver = $_.Parent
$csb = New-Object System.Data.Common.DbConnectionStringBuilder
$csb.set_ConnectionString($_.Parent.ConnectionContext.connectionString)
$DatabaseName = $_.Name
$_.Tables | #for every table
foreach {
$filename = "$($_.schema)_$($_.Name)" -replace '[\\\/\:\.]', '-';
$TheScriptPath = "$($dDataSyncPath)\$($filename).bcp";
if ($csb.'user id' -ne '')
{
$whatHappened = "`"$DatabaseName`".`"$($_.Schema)`".`"$($_.Name)`""
$WhatHappened +=
BCP "`"$($DatabaseName)`".`"$($_.Schema)`".`"$($_.Name)`"" `
in "`"$TheScriptPath`"" -q -n -E "-U$($csb.'user id')" `
"-P$($csb.'password')" "-S$($csb.'data source')";
}
else
{
$WhatHappened =
BCP "`"$($DatabaseName)`".`"$($_.Schema)`".`"$($_.Name)`"" `
in "`"$TheScriptPath`"" -q -n -T -E "-S$($csb.'data source')";
}
if (“$WhatHappened” -like '*Error *')
{ throw ("$whatHappened BCPing data into $DatabaseName from $TheScriptPath") };
}
$result = $BuildServer.ConnectionContext.ExecuteNonQuery(
"EXEC sp_msforeachtable 'ALTER TABLE ? WITH CHECK CHECK CONSTRAINT all'");
"$($csb.'data source') $DatabaseName has been stocked with data"
}
|
Conclusions
In this article, I've illustrated how to integrate other tools with SQL Change Automation. We've taken SMO (in the form of the sqlserver module), BCP and SSMS as examples. I hope I've demonstrated that, because SCA uses connection strings, it makes it very easy to integrate SCA scripting with any other process running in Windows Servers. The same goes for any command-line tool, ODBC connection or PowerShell tool: it is easy. This means that integration with other tools, reporting and so on aren't likely to pose problems.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Questions about SQL Change Automation that you were Too Shy to Ask
Phil Factor takes on tricky SQL Change Automation questions about database builds, migrations, deployments and releases.

Article
Using Filters to Fine-tune Redgate Database Deployments
Filters are used by Redgate's SQL Compare, SQL Source Control, DLM Dashboard, and SQL Change Automation. A typical use for a filter is to work on just one schema within a database or just a limited set of tables and routines. You would also want to use a filter to exclude certain object, such as database users, from comparisons. Phil Factor explains how they work, and how to create, edit and then use them within the various Redgate tools.
Article
SQL Server Database Deployment: What Could Go Wrong?
Phil Factor tackles the tricky questions you will need to answer when deciding how to automate your SQL Server database builds and deployments with Redgate's development, version control and deployment tools.
Article
Deploying Multiple Databases from Source Control using SQL Change Automation
How to automatically build multiple test databases, from source control, and then fill them with standard test data sets, using SQL Change Automation, BCP and some PowerShell magic.
Article
SQL Code Analysis from a PowerShell Deployment Script
This article shows how to define SQL code analysis rules using SQL Prompt and them run them automatically from a PowerShell script, displaying the detected code issues in a handy HTML report.
Article
Dealing with production database drift
For the SQL Change Automation team, it’s important that we take time out from development, occasionally, to explore some of the issues our customers face when automating database deployment. Following on from previous posts about cross-database and cross-server dependencies, this article shares some of our thoughts about how to deal with production database drift. If you’re using automated deployment for your databases, direct changes to your production environment can cause a headache. These unmanaged changes are known as database drift. To better understand the issues this can cause, our team created a test application we could work with; this was a
Loading comments...