





Database Continuous Integration with the Redgate SQL Toolbelt and Azure DevOps
This article explains how to set up a SQL Server source control and database continuous integration (CI) process from scratch, using Azure DevOps, Git, PowerShell and Redgate tools, in three steps:
- Database CI in theory and practice
- What you need to get started
- Step 1: Create a new Azure DevOps project and clone the repository
- Step 2: Linking a database to source control
- Step 2.1 (optional): Writing a build script using SCA and PowerShell
- Step 3: Automating your build using Azure DevOps
- Further extensions
In a Database Continuous Integration (CI) process, we establish a working version of the database quickly, integrate subsequent changes as frequently as possible, and run tests each time to prove that the database still works. CI makes it easier to spot mistakes. Bugs, introduced by coding errors or by new versions of third party components, become much easier to find and remove, because we know that the problem was caused by a change made since the last successful integration. Over time, database changes become easier, and the database build and deployment processes get more predictable, and far less likely to introduce problems into the production systems.
Database CI in theory and practice
The theory behind CI is that if we integrate code into a shared repository several times a day, and then verify each commit by running an automated build, and subsequent tests, then we detect and eradicate problems early, and improve the quality of our software.
More on CI theory
For extensive background on CI, check out ThoughtWorks, as well as Martin Fowler's book. For a detailed description of what's required for Database CI, and its benefits, see Grant Fritchey's Database Continuous Integration article.
This article is all about setting up the plumbing that will allow you to put CI theory into practice, for databases. When I posted my original article on this topic, in 2013, it used SVN and Jenkins, and proved very popular. That's still a viable route, but half a decade is an eternity in our industry and other technologies and tools have risen in popularity. PowerShell has become the primary scripting language for the Microsoft stack, and Git the prevalent source control tool for everyone. Jenkins, or indeed TeamCity, could easily still be used for the CI server, but with Azure DevOps replacing Visual Studio Team Services (VSTS) last month it felt like the right time to write a new version of the original 2013 post. Azure DevOps has a free tier that is available to anyone who wants to follow this tutorial.
As such, this article will use:
- Git – as the source control system.
- Azure DevOps – to host the remote Git repo and to automate database builds
- Redgate SQL Source Control (SoC) – to commit database changes locally. We clone the remote repo then link it to SoC, so we can commit database changes directly from SSMS
- PowerShell – to push commits to the remote repository, hosted on Azure DevOps
- Redgate SQL Change Automation (SCA) – to automate local database builds, using its PowerShell cmdlets (an optional step)
- SCA plug-in for Azure DevOps – to automate database build and deployment processes
Of course, saying you are a CI practitioner just because you now have some CI tools is a bit like claiming to be an astronomer as soon as you buy your first telescope. The tools are merely a necessary first step. The team still need to adopt good CI practices. Developers will need to write the unit tests that prove that each small change works. As frequently as possible, many times a day, they must commit changes to a shared source control repository. Each commit should trigger an automated database build, to ensure the team always has a working database build process. Each night the team should run integration tests (not covered in this article) to prove that all the individual units work together to implement the required processes. These CI practices will lead naturally to automated deployments, as well as to more frequent and more reliable releases.
Of course, you can practice CI without these tools, but the better the tools, the easier and more rewarding you'll find CI, much like with telescopes and astronomy.
What you need to get started
This post assumes a basic understanding of SQL Server, Git and PowerShell. To reproduce this proof of concept, I used the following software versions:
- A Windows Server 2016 VM, with Admin access. You should also be able to get this all working on Windows 10 with similar results.
- SQL Server 2017 Developer edition. You can download it here.
- The Redgate SQL Toolbelt (Oct 2018 version). You can download it here and it comes with a 14-day free trial. Specially, you'll need to install on your local workstation SQL Source Control and SQL Change Automation.
- Git 2.19. You can download it here.
- An Azure DevOps account, you can create one here for free.
You can probably use older or newer versions of the software, but since Azure DevOps is a hosted service, and time is a complicated problem, I'm not making any promises about compatibility. Similarly, if you are reading this post several months or years in the future, you may find that the Azure DevOps UI has changed:
You will also need a database to play with. I'm going to use the StackOverflow database because it has a straightforward schema and I know it works. For your first build, try to use something simple that can be built in isolation on localDB. This excludes AdventureWorks, because localDB does not support Full-Text Search. Also, try to avoid databases with dependencies on other databases, for now.
Step 1: Create a new Azure DevOps project and clone the repository
Navigate to the Projects tab in Azure DevOps (in my case, https://dev.azure.com/DLMConsultants/_projects)
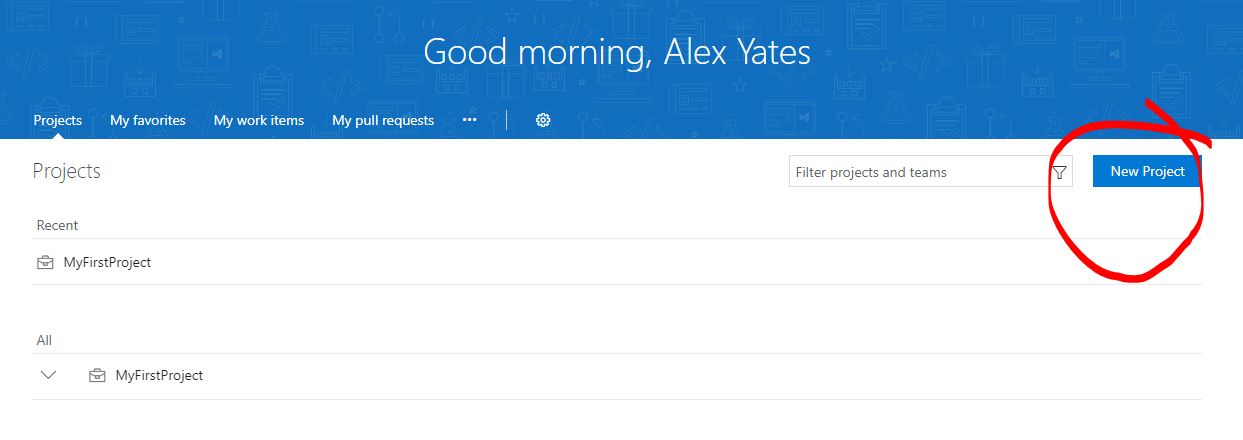
Give the project a name, such as the name of your database. Under Version control select Git, and your preferred Work Item process. If in doubt the default Work Item process (Agile) is fine, because it makes no difference to this tutorial.
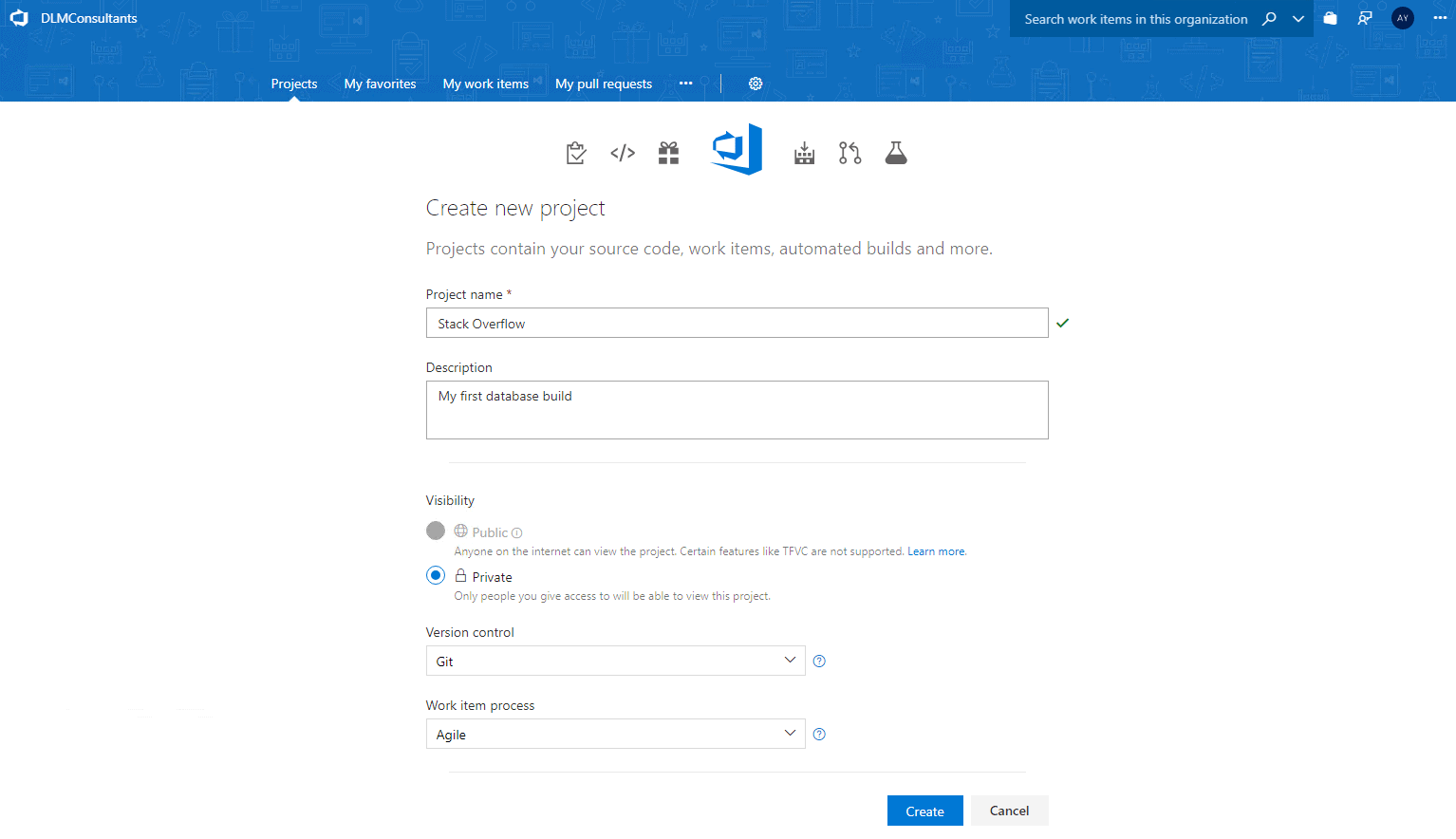
Clone the repo to your local workstation. To do this copy the HTTPS link in Azure DevOps:
Now, open a PowerShell window, navigate to the directory where you would like to store your source code and clone the repo. The basic command looks like this:
git clone https://yourcompany@dev.azure.com/etc
Here's my full command window:

You should now have a local repository on your machine, with a hidden .git directory, where you can add your database source code.

Step 2: Linking a database to source
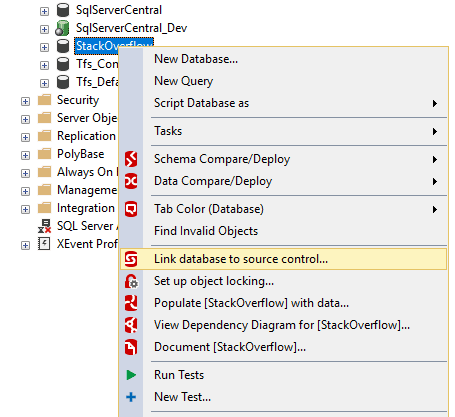
We'll use Redgate SQL Source Control, so make sure it's installed and that you can access your database in SSMS. Open SSMS and right-click on the development or test database that you want to link to source control. Select "Link database to source control…"
Redgate SQL Source Control will open in a query window. Select "Link to my source control system", choose "Git" from the supported source control systems, and paste in the path to your local source control repository. Then click "Browse" and "Make New Folder" and add a "state" directory to the root of your source control repository and link your database to the state directory. The reason for this will become clear in step 2.1.
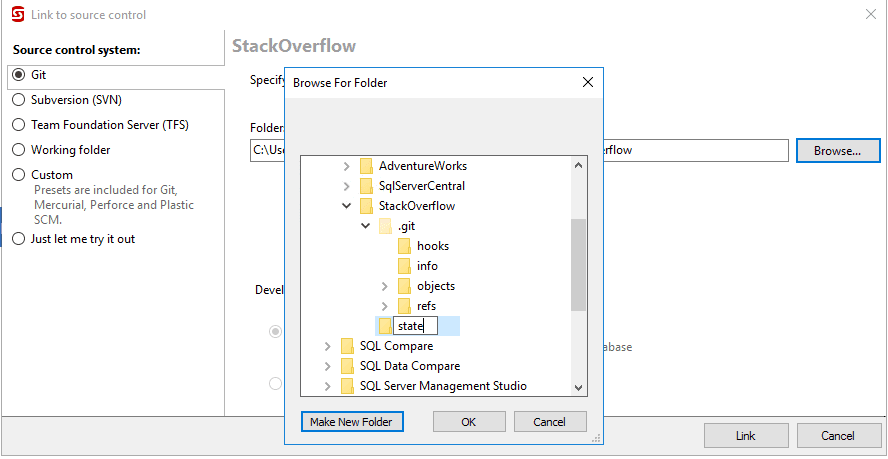
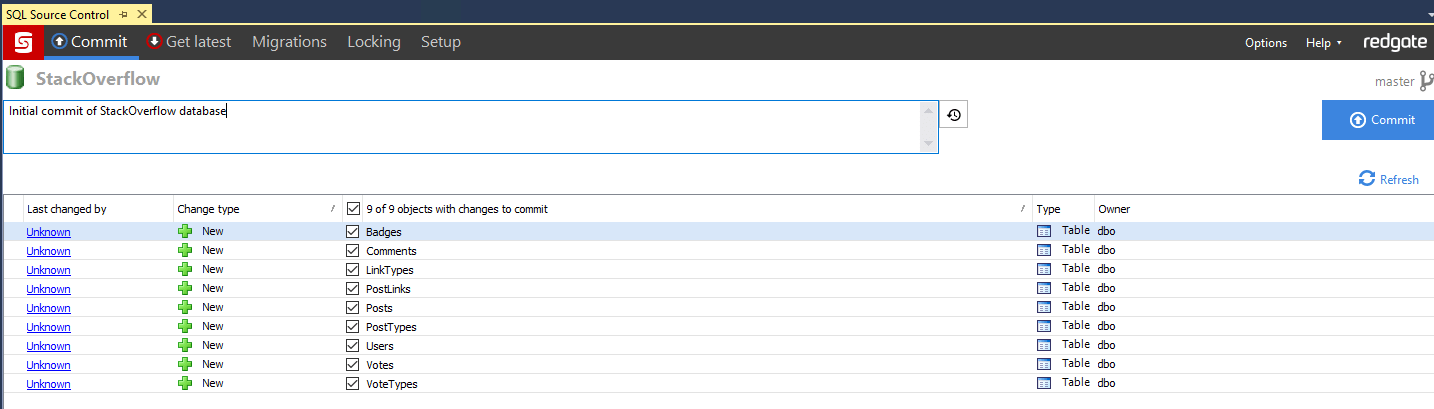
Once linked successfully, observe that a RedGate.ssc file has been added to the "state" directory in your Git repo. Then go to the "Commit" tab in Redgate SQL Source Control and you'll see a list of all your database objects, ready to be committed to source control. Ensure all the objects are selected, type in a commit message and click commit:
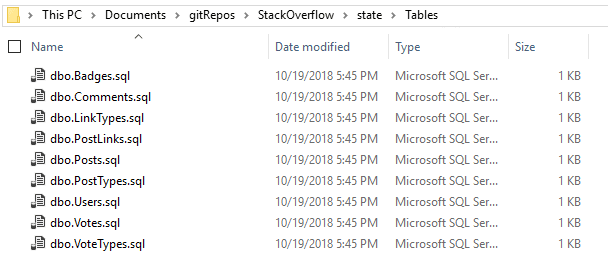
When SQL Source Control says all the changes have been committed, take another look in your git repo. You should see all your database objects scripted out into various directories.
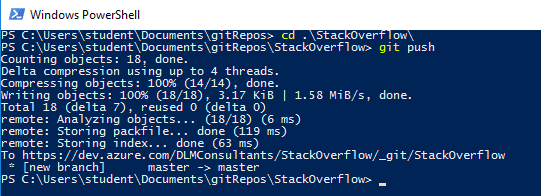
Since Git is a distributed source control system, you have only committed these changes to your local repo. You have not yet pushed these files to the remote repo hosted in Azure DevOps. If you're using the SQL Source Control v7 or later, you can use the "Push" button in the SQL Source Control commit tab. You may see the button in earlier versions too, but it does not work with Git repos hosted in Azure DevOps, so you'll need to open a PowerShell terminal , navigate to the root of your git repo and run the command: git push.
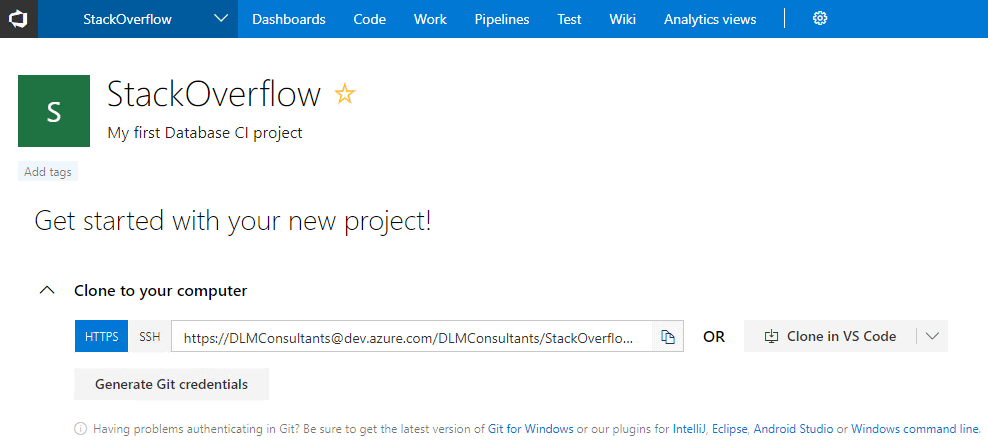
Once you have pushed your source code to Azure DevOps you should be able to see it under the "Code" tab on the Azure DevOps website:
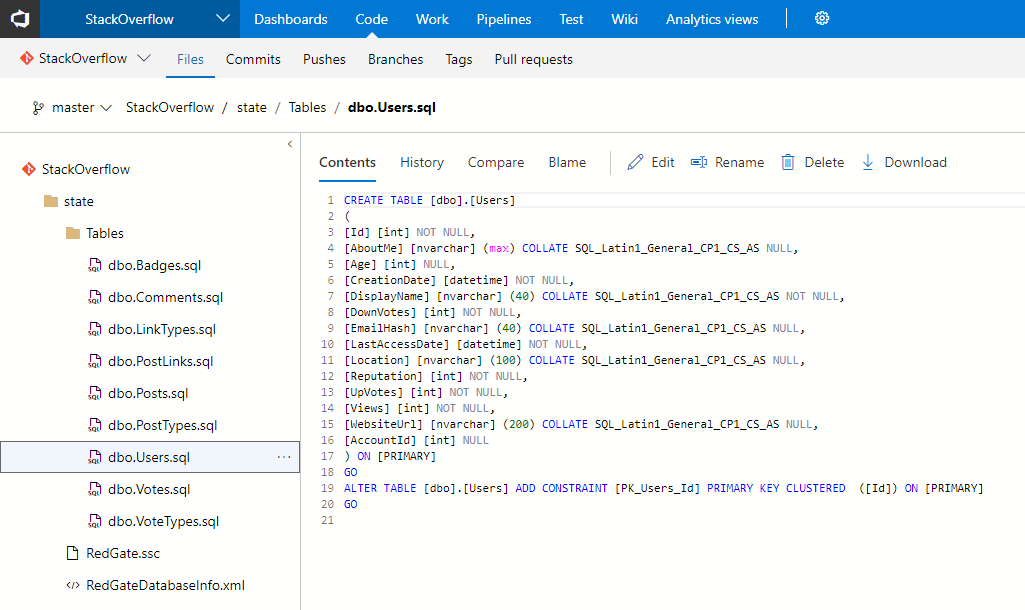
Step 2.1: Writing a database build script using SCA and PowerShell (optional step)
We now have our database in source control, so the next step is to set up a build process to check that our source code "compiles". By that I mean that it is deployable. For example, if there was some illegal T-SQL syntax in the source files, 'or if there were some views with missing dependencies, perhaps because I had refactored some tables, but forgotten to update my views, then SQL Server would not be able to execute my source code and my database build would fail.
This step is optional, or at least running it locally, using PowerShell, is optional. The alternative is to' skip this step and jump straight to Step 3 to start configuring your database builds on Azure DevOps. However, I like to run my builds locally first. It's helps me to understand what is happening under the hood. It also helps me to understand whether my first builds are failing because of my source code or my Azure DevOps configuration.
In the root of your source control, create a new directory called "build", right next to your "state" directory. This explains why I didn't link my database to the root of my Git repo in Step 2. It's useful to put other associated files in source control but you don't want to be putting them in your Redgate folder.
Validating the build using localdb
Create a new file in the build directory called "build.ps1" and copy the following PowerShell code into it. You may wish to change the default value for the parameter $packageID to reflect the name of your database. For now, you should leave the other parameters as they are. I'll explain the $packageVersion, $packagePath and $testPath parameters shortly and I'll explain the others under Further extensions.
This PowerShell code uses SQL Change Automation to create a new database in localDB and deploy all your source code to it. As soon as the database is deployed, SQL Change Automation will immediately delete it, since it has already served its purpose. If you run a build 10 times a day for a week you don't want 50 test databases hanging around.
You should be able to run the script from PowerShell, overriding the default parameters if you wish.
cd the root of your source control\build .\build.ps1 -packageVersion '0.1' -packageID 'MyDatabase'
Here's the full command window, from my example:
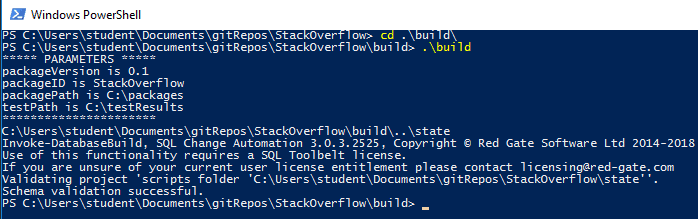
If your build script works, great! If not, you've potentially discovered some broken code, also great! Typically, these are the result of broken code, missing dependencies, localDB not being installed or SQL Server credentials being incorrect. The PowerShell output is your friend here.
Validating the build using a temporary database
You may encounter cases where you can't deploy your database on localDB because, for example, it's missing a dependency on some other database, or using a SQL Server feature that localDB doesn't support. For example, AdventureWorks uses Full-Text Search, which won't deploy to localDB. Instead, you can deploy to a database on a 'temproary' SQL Serve instance, which is set up with all the features, dependencies, filegroups, and so on, that your database needs. (See example's 3 and 4 in the Invoke-DatabaseBuild cmdlet documentation.)
You can download a PowerShell build script (DBBuildTempServer.ps1), written in a slightly different style to showcase the possible approaches, to see how it works.
You should be able to run the script from PowerShell, overriding the default parameters if you wish.
cd the root of your source control\build .\build.ps1 -packageVersion '0.1' -packageID 'MyDatabase' -TempServer 'MyServerInstance' -User_id '' -Password ''
If you don't have a SQL Server instance that you can use for this process, simply remove the -TemporaryDatabaseServer $TempconnectionString from the SCA Invoke-DatabaseBuild command, and it will use localDB, as described previously. Phil Factor's article also provides a lot of extra information about working with PowerShell and SCA.
Creating a NuGet package
At this stage all we've done is validate the build; in other words, proved that the database will build successfully. This done, we can start to explore other SCA cmdlets that will generate and export a database build artifact from the validated build, run our suite of tests on it, and then deploy the tested changes, to synchronize a target database with the validated and tested source.
I'll cover the testing and synchronization cmdlets later, in the Further extensions section, but for now you might like to generate a NuGet package. NuGet packages can be used as a build artifact, representing a significant milestone on the road to package-based deployment and continuous delivery. You can generate your NuGet package simply by uncommenting a couple of lines of code in your build script.
Simply uncomment the two lines immediately under # Export NuGet package in the comment block at the bottom (for example by moving the <# a few lines lower) and ensure that the default value for $packagePath is an existing directory that is not in your git repo. If you just leave it blank it will create a NuGet package in the build directory in your git repo which I wouldn't recommend.
Now when you run a successful build a NuGet package will be created containing your source code. Note that if you try to create two packages with the same $packageID and $packageVersion to the same $packagePath the build will fail so you will either need to override the build number or delete the old package every time you re-run your build.
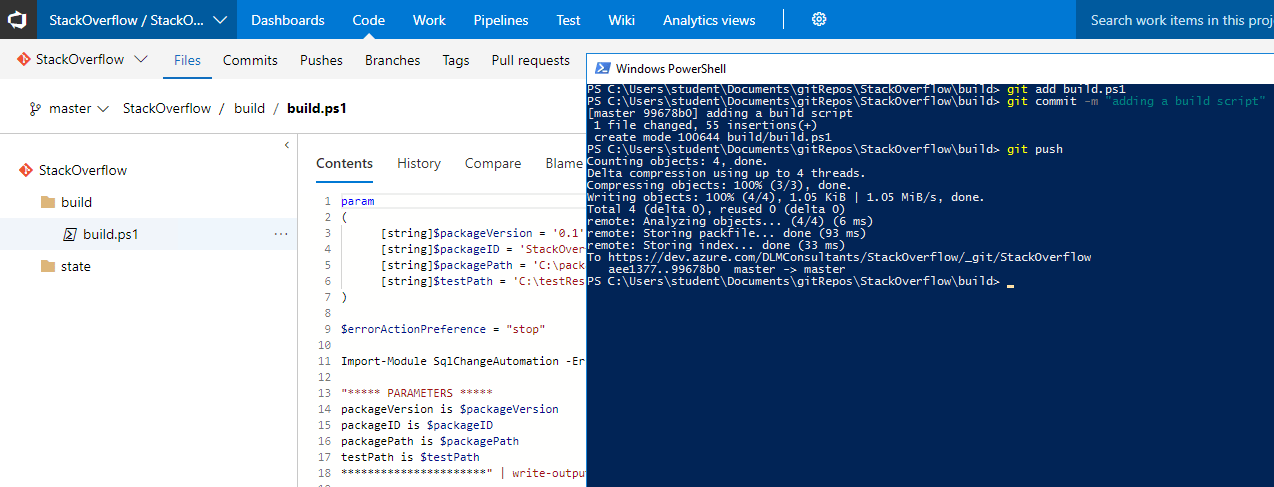
Commit your changes to source control and push them to the server.
>git add build.ps1 >git commit -m "adding a build script" >git push
Step 3: Automating your build using Azure DevOps
You now have your database code in source control and you have pushed it to Azure DevOps. If you followed the instructions under Step 2.1, you also have a PowerShell script in source control that builds your database, and you know that your source code 'compiles'. Now, we want to get Azure DevOps to build the database every time we push new changes to source control, to validate that the changes can be deployed and to catch any errors.
We will use the Redgate Azure DevOps extension to automate a database build since this does not require that you followed Step 2.1. If you did follow step 2.1, rather than using the Redgate plug-in, you may prefer to run your build script using raw PowerShell tasks that execute your build.ps1 file, overriding the default parameters as appropriate. If you take that approach, you might find this index of Azure DevOps pre-defined variables useful and you may want to use $(Build.BuildNumber) or $(Build.BuildID) to create packages with sequential version numbers.
Your automated builds will be executed by a 'build agent'. If you can already build your database in isolation on localDB, you should be able to use the hosted build agent out of the box. Otherwise, you'll need to configure a local agent on a server you host which has access to a suitable target SQL server instance for running your builds.
In Azure DevOps, hover over the Pipelines tab and select Builds from the dropdown.
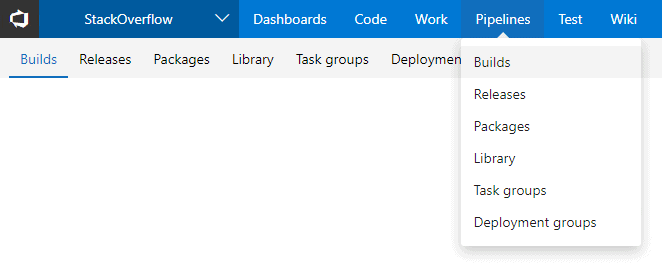
Hit the New Pipeline button and ensure you have the correct source control repository and the master branch selected. Then select Empty Job for your template.
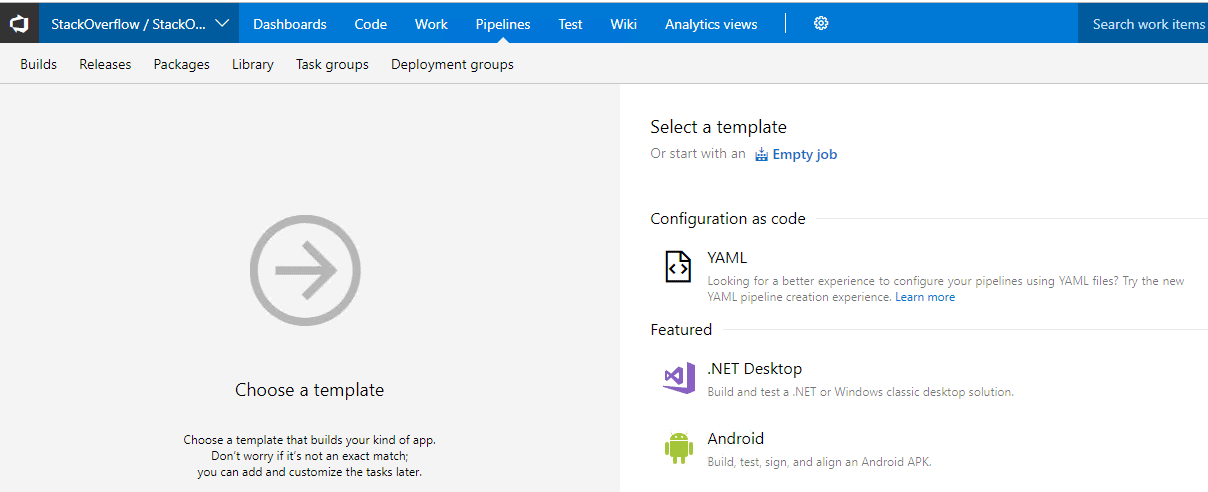
A new pipeline will be created for you with a default name (in my case StackOverflow-CI) and a default Agent queue (in my case, Hosted VS2017, which is the default for Azure DevOps. The pipeline includes a default job called Agent Job 1, although if you select it you can rename it. Let's call it Build Stack Overflow Database.
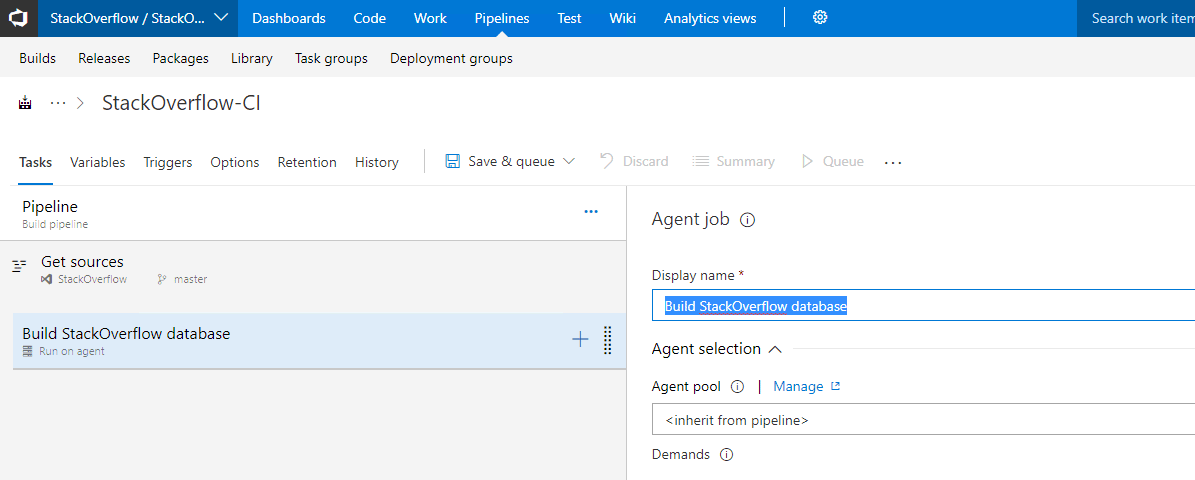
We can add Tasks to our Agent Jobs that will run MSBuild or execute PowerShell scripts and so on, to compile and test our code. To do this click the + button next to your Agent Job.
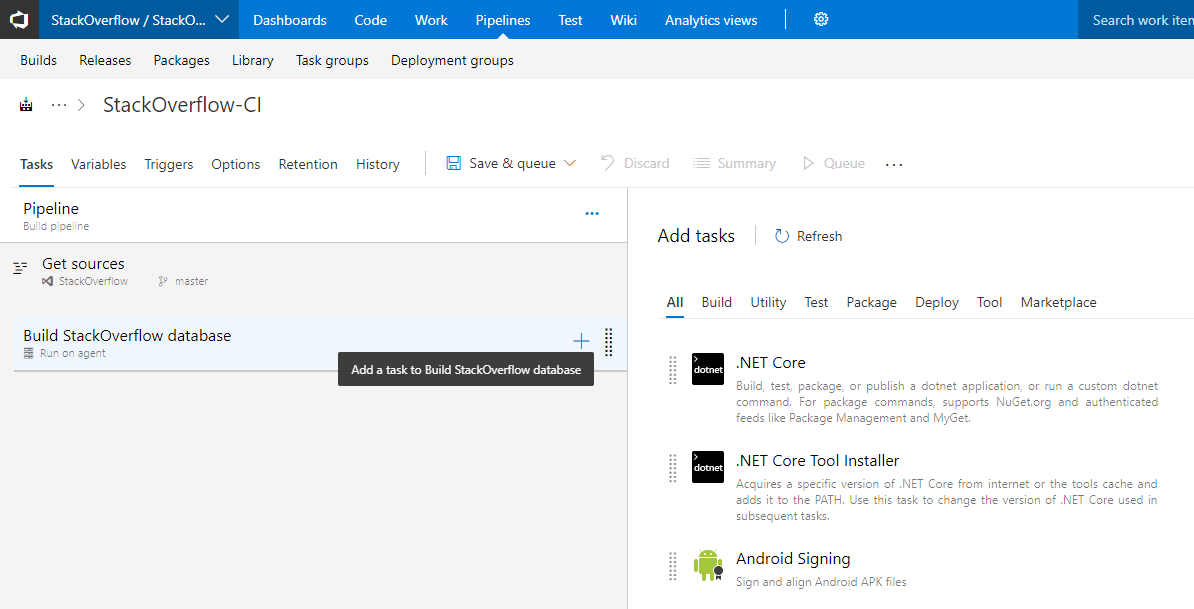
The Redgate SQL Change Automation Azure DevOps extension is not available by default, but you'll find it if you search for "Redgate" in the Marketplace tab under Add tasks. Follow the instructions to add the SQL Change Automation: Build extension.
Once installed, find your way back to your build process. You may need to click through points 2-5 above again since your new definition may not have saved. This time, if you search for "Redgate", you should find the extension is available without going through the Marketplace again, and you can just click Add.
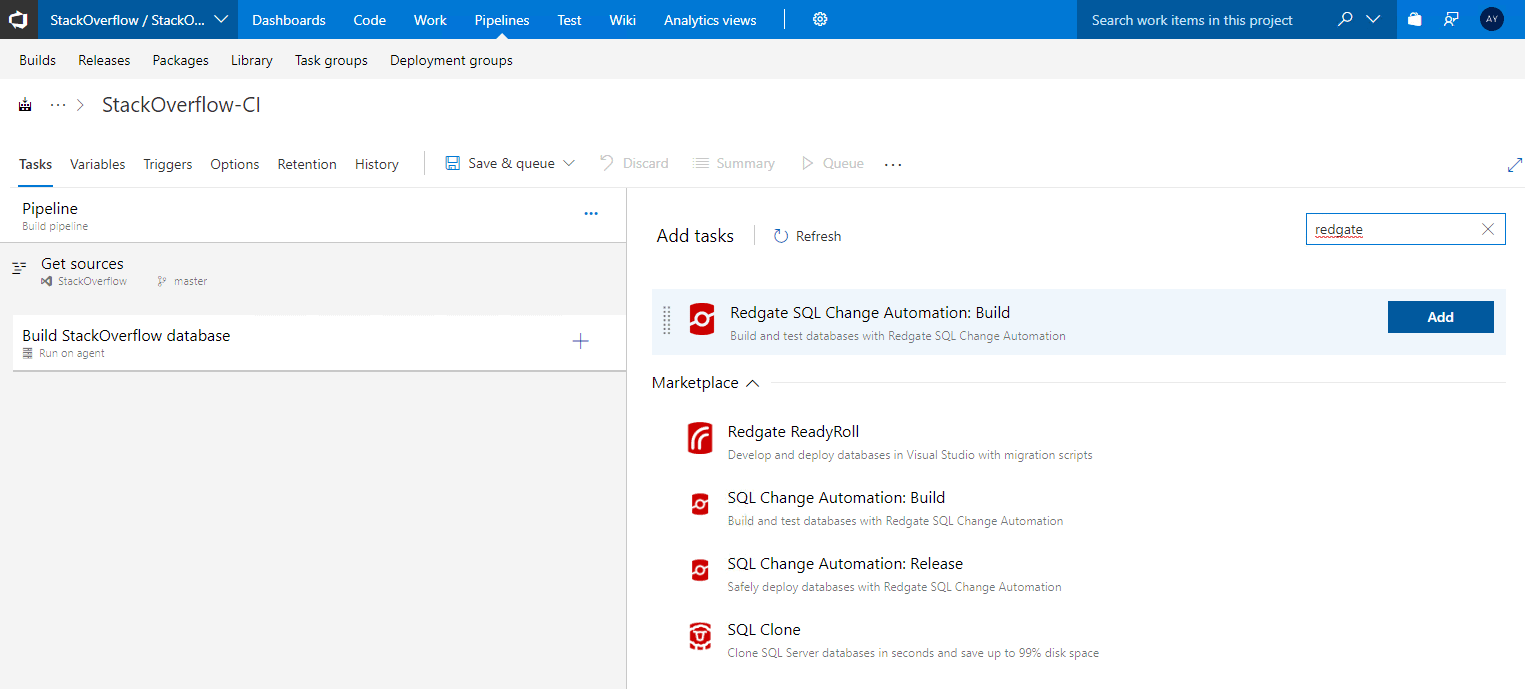
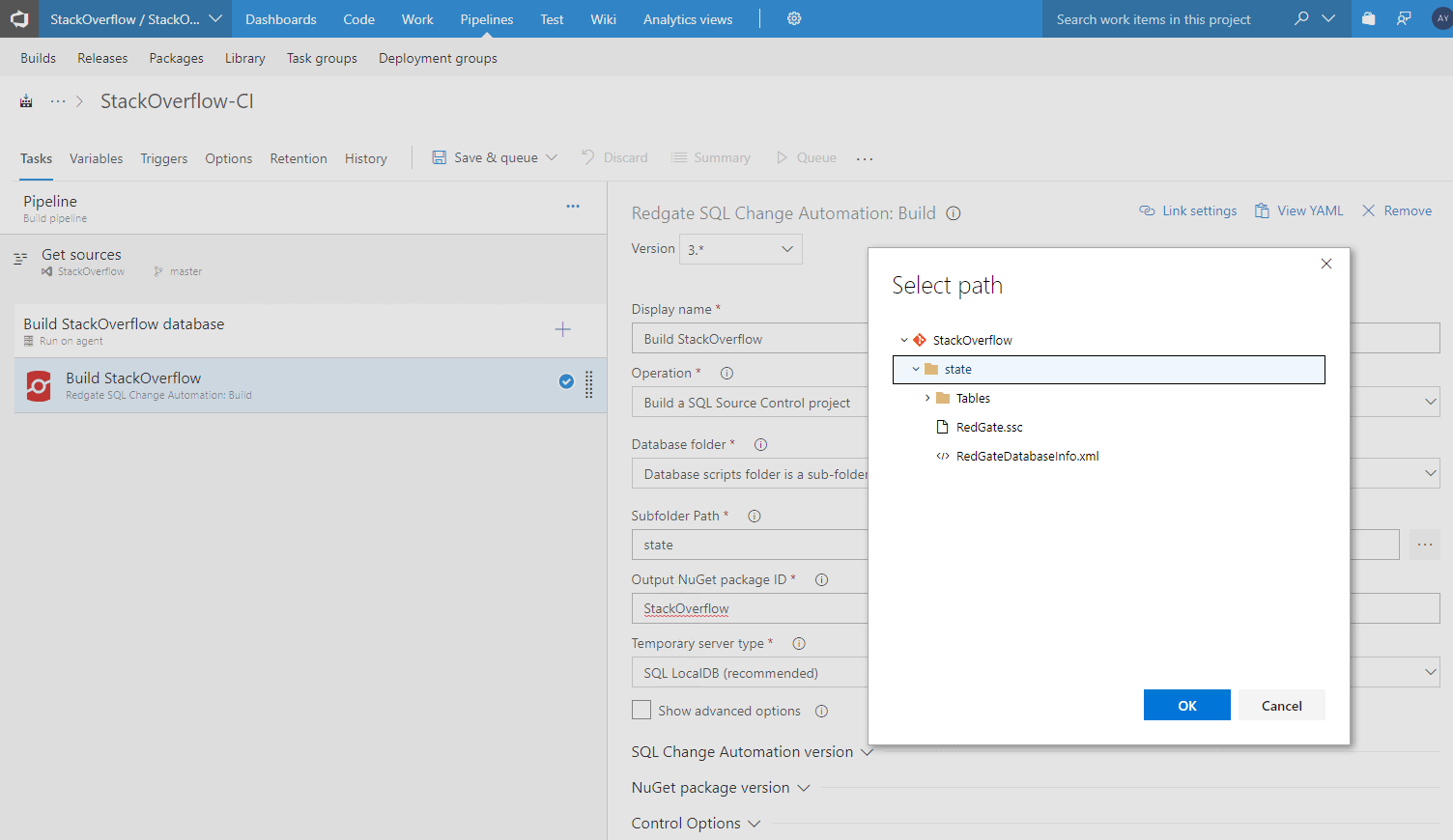
A build Task will be created under Build StackOverflow Database, with a warning that some settings need attention. Click on this build task and, under Operation, select Build a SQL Source Control project. Then, under Database folder select "Database scripts folder is a sub-folder of the VCS root", and under Subfolder Path use the wizard to select the state directory maintained by SQL Source Control (don't select the root of your Git repo which, if you followed Step 2.1, will also include your build script!).
Under Output NuGet Package ID write a name for your build artifact. Conventionally, this would be the name of your database.
Click Save & queue to manually trigger a build. The default settings should be fine. You should see a yellow notification that a build has been queued. If you click the number, it will take you to the live build logs.
A hosted agent will be assigned to you. It will then download SQL Change Automation and build your source code on its own localDB in the cloud and report back on the results.
Note that if your database won't build on a default install of local DB on the hosted build agent in Azure, your build will fail. If your database won't build on localDB, you will need to provide a separate SQL Server instance on which to run the build. Then, in your Build StackOverflow Database build task, change the Temporary server type from SQL LocalDB (recommended) to SQL Server and provide the connection details to your server instance. If you are hosting this server instance on-premise, you may need to install a local build agent that has access to your local server to run the build.
The build will probably take a few minutes. In my case, with Stack Overflow and a hosted build agent, it took about two and a half minutes. With larger and more complicated schemas you should expect it to take longer.
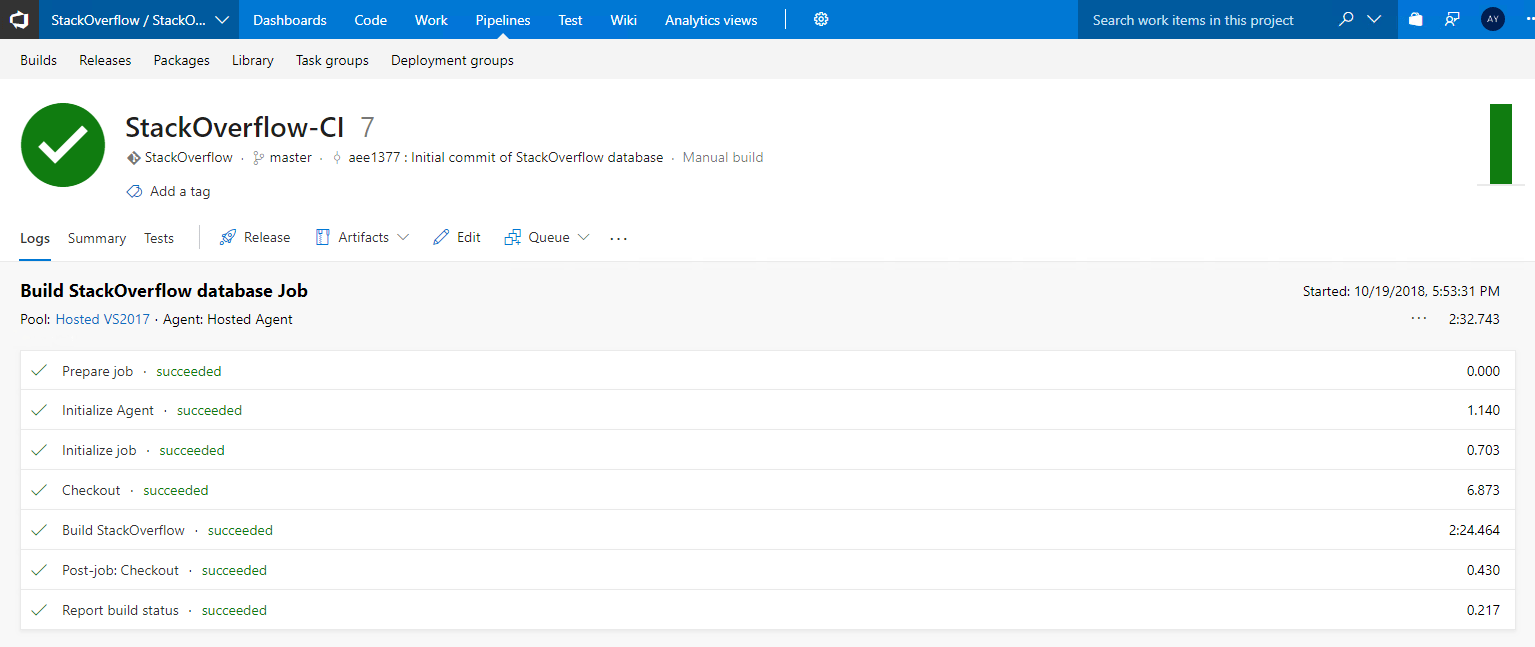
If your build fails, look for the errors in the log and troubleshoot. Common issues include missing dependencies, incorrect credentials, insufficient privileges to databases, use of features that aren't supported on localDB and broken T-SQL code. Keep plugging away until your build turns green. If you skipped Step 2.1 and are having trouble with the build, consider going back and trying Step 2.1 since it's an easier way to troubleshoot issues with your source code and may help you to work out whether the problem is related to the source code or the Azure DevOps configuration.
Once your build is green, you need to set up a build trigger to ensure the build runs every time you push new code to the Azure DevOps server. From any page in Azure DevOps, hover over Pipelines tab at the top and select Build to navigate back to your build definitions. Select your Build Definition and then select the Edit button.
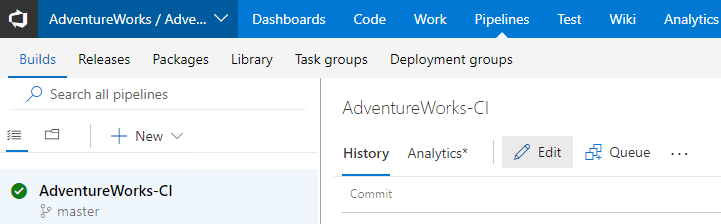
Select triggers and ensure Enable continuous integration is checked, you are done.
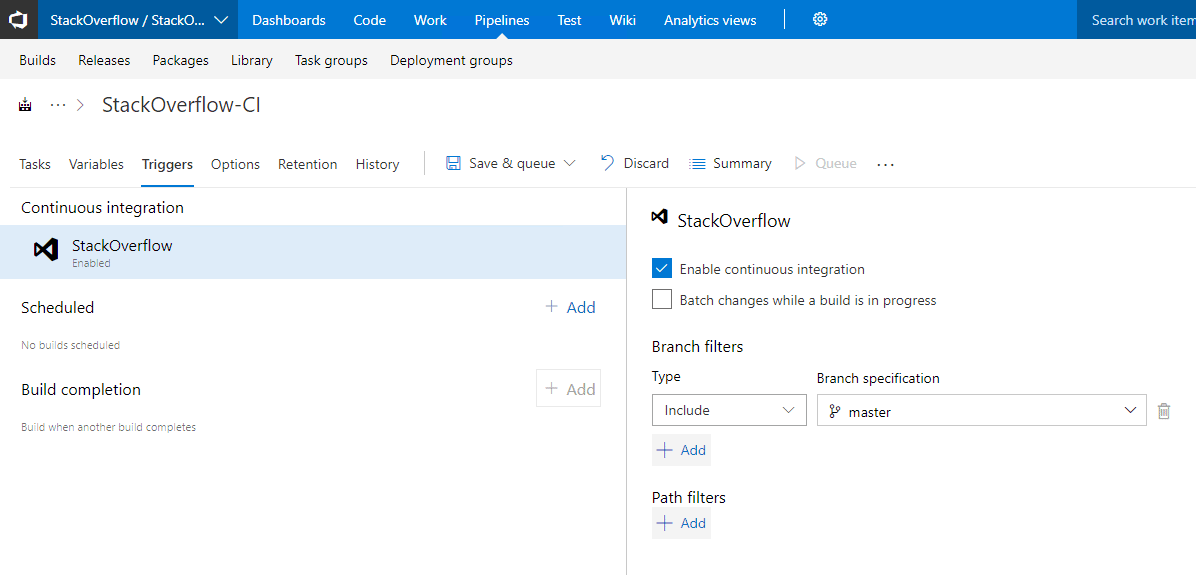
If you have got this far, and you push new code to Azure DevOps, it's going to automatically kick off a build and validate your code, and long may you continue to integrate continuously and get fast feedback on your mistakes.
Further extensions
Automating your database builds is just the first step. All this will test is that your source code is deployable. It doesn't test that your stored procedures work as designed. It doesn't automatically update an integration database so that it is always up to date with source control. It doesn't deploy your code for you to your test, staging and production servers.
Firstly, and most importantly, you need to start writing tests for your databases that will run automatically with every build. Check out tSQLt and Redgate SQL Test.
If using the PowerShell script written in Step 2.1, and you have installed the tSQLt framework on your database and committed it to source control, you can run the tests as part of your build by un-commenting lines under # Run tests. If you have not committed the tSQLt framework to source control this will fail. You should also ensure that the $testPath default parameter is set to an existing directory that is outside your git repo. As with packages, you will need to override $packageVersion each time you run a build.
If you would like your build to deploy your changes to an integration database, uncomment lines under # Sync a test database and set the default values for $targetServerInstance and $targetDatabase appropriately.
If you're using the Redgate SQL Change Automation extension, in Azure DevOps, the you'll need to:
- Add a SQL Change Automation: Build task with the operation set to "Test a build artifact from a SQL Source Control project using tSQLt tests". Again, this won't work unless you already have the tSQLt framework and your tests in source control.
- Add a SQL Change Automation: Build task with the operation set to "Sync a build artifact from a SQL Source Control project to a target database".
And once you've done that, you might like to experiment with the Release functionality in Azure DevOps and the "SQL Change Automation: Release" extension to create deployment pipelines that are fit for production.
Happy deployments! And if you get stuck or want any Database DevOps training/consulting, get in touch:
Tools in this post
You may also like

Article
Insert Statement Without Column List (BP004)
Many production databases have failed embarrassingly as a result of
INSERTcode that omits a column list, usually in mysterious ways and often without generating errors. Phil Factor demonstrates the problem, and advocates a 'defense-in-depth' approach to writing SQL, in order to avoid it.
Article
Azure SQL Elastic Pools and Redgate Monitor
This article explains the Azure-tailored metrics and alerts in Redgate Monitor that track use of the limited compute resources available to an Azure SQL Elastic Pool, and to each of the databases in it.

Article
How to deploy changes to Azure SQL Database using SQL Compare and Azure Active Directory
Describing SQL Compare's built-in Active Directory Authentication mode, which makes it easier and more secure to, for example, deploy schema changes from version control to an Azure SQL Database.

Article
Redgate and the Cloud: How we can help you
*Updated for 2023* For many of us, our cloud undertakings are growing and growing, and it can be dauting to embark on a cloud migration initiative of any scale. The good news is, Redgate is right there with you. Many of our tools already work with the cloud. Also, we work with the cloud. Our own knowledge and understanding there is constantly expanding. I’d like to share a bunch of training and resources that we’ve put together from more general tips on migration projects, through to specific, Azure, AWS and Google-related content. Non-technical tips for cloud migration initiatives While there’s
Article
Using SQL Compare with Row Level Security
As you test your row-level security in various environments, you can use SQL Compare to script out and deploy those changes to other databases.

Article
How to Add a Filter to an Existing SQL Change Automation Project
Kendra Little demonstrates how to create a SQL Compare filter file and save it to a SQL Change Automation project folder, so that it will be used automatically during development.
Loading comments...