
A standard way to document a SQL Server database is using extended properties (metadata attached directly to database objects via sp_addextendedproperty). An alternative approach – which this article calls ‘the Gloop’ – is to extract each object’s metadata as an individual JSON file and manage the collection outside the database: per-table JSON files, per-stored-procedure JSON files, per-index JSON files, etc.
The collection can then be edited in bulk using MongoDB-compatible tooling like Studio 3T, queried with MongoDB-style expressions, and version-controlled alongside the schema source code.
When to choose this over extended properties: when you need bulk editing of documentation across many objects, when documentation needs to live in source control alongside schema migrations, when cross-object queries over documentation are useful (for example, ‘find all columns where the description mentions PII’), or when the documentation has structure (nested notes, links, author history) that doesn’t fit extended-property free text cleanly.
This article walks through the PowerShell extraction scripts, the MongoDB-import workflow in Studio 3T, and the workflow patterns that make the approach practical.
Here, in this blog, I’m continuing a theme that I started in a previous blog, ‘What’s in that database? Getting information about routines’.
In that blog, I just wanted to provide a few examples of extracting metadata from SQL Server into Powershell and hinting about why one might want to do it. I’ll now show how to save the details of the metadata of your database, including tables and routines, in JSON files. Then I’ll demonstrate how to change and add to the descriptions of database objects and saving them to the database.
Metadata extract files are handy for documentation, study, cataloguing and change-tracking. This type of file supplements source because it can record configuration, permissions, dependencies and documentation much more clearly. It is a good way of making a start with documenting your database.
Here is a sample of a json metadata file (from AdventureWorks 2016). It was generated using GloopCollectionOfObjects.sql that is here in Github, and is being viewed in JSONBuddy. I use this format of JSON, a collection of documents representing SQL Server base objects (no parent objects) when I need to read the contents into MongoDB. The term ‘Gloop’ refers to a large query that, you’d have thought, would be better off as a procedure. Here is a typical sample of the output.

Ok. Those descriptions make a huge difference to readability. I want to be able to edit them in JSON and save them back to the database. OK. We can do that. I use #ParseJSONMetadataToUpdateTheDocumentation which is in the GitHub folder. It is a temporary stored procedure. We can either use this from a SQL batch or call it in SQL using PowerShell.
Without wishing to change our AdventureWorks file, We’ll open up a sample file called ‘Customers’ and add some descriptions. In this next screendump, I’m adding a description to a table called Customer.note

Then we save the file and execute this code.
|
1 2 3 4 5 6 7 8 9 |
USE customers DECLARE @JSON NVARCHAR(MAX); SELECT @JSON = BulkColumn FROM OpenRowset(BULK 'PathToTheData\customers.json', SINGLE_NCLOB) AS MyJSONFile; DECLARE @howManyChanges INT; EXECUTE #ParseJSONMetadataToUpdateTheDocumentation @JSON, @howManyChanges OUTPUT; SELECT Convert(VARCHAR(5),@howManyChanges)+ ' descriptions were either changed or added' |
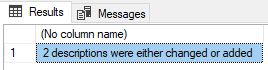
Why 2? I added a description to a column as well.
… and we can check to make sure that the right thing got changed.
If we delete all the extended properties and then re-run the batch we get this
Phew, they are all back in there.
What’s the best way to execute and write out the SQL Gloop query to get the metadata extract in the first place? It can be done in SQL, but once you’ve decided that you need to work on a whole collection of servers and their databases, or you have a regular database chore to do that involves saving to files, it is worth considering doing the chore in SQL, but using a PowerShell task that can be scheduled. I’ve included the code for this on Github called RunSQLScript.ps1
In my previous Blog, I introduced the idea of getting metadata about your database using SQL, and saving the contents into a directory, but I didn’t really go into the details about how you run such code. I also mentioned that, if you are running the same task on a number of databases, there is no shame attached to running a large query to extract the metadata from your databases. I referred to this as a ‘Gloop’. The reason for doing so is that you can run it on a number of databases but leave no trace of utility procedures on them, not even a temporary stored procedure. GloopCollectionOfObjects.sql is one of these and I’ve added others to the Github site that were written for other purposes.
Developing other uses for Metadata extracts
There are several good uses for metadata extracts of database objects and their associated columns, indexes, parameters and return values. The main reason I have for wanting to do this is to see what’s been properly documented in the database and where something is missing, adding it. There are plenty of other uses. What you collect depends on the nature and purpose of your task. I’ve added some sample Gloop queries to deliver different formats of JSON files. Beware, though, that you can’t save the documentation without altering the SQL code in the temporary procedure that shreds it into a relational table.
Whatever use that one puts these metadata extracts to, one thing always happens: When you are looking at metadata in another format than the build script, then some things, mostly mistakes and omissions, that you have just never noticed before will now stick out clearly. It seems to help to get a different view of your database.
We must also decide on the format we want for our data. If we are predominately using it for documentation, then readability is important. For doing comparisons or keeping a record of database changes in source control, maybe you want something that can be read by input routines more easily. Although ordered arrays are legal JSON, they aren’t easy to produce in SQL Server because SQL Server’s JSON library is geared to produce key/value pairs. Tables have names that translate easily to keys since the schema/name combination is unique. The same is true of columns and parameters. The natural way of recording these might be to have an array of schemas, each of which have arrays of table objects using their name as a key. However, they are ordered arrays of objects. It isn’t a major difficulty because we can do what SQL Server does, and put the name as a value assigned to a ‘name’ key. It just looks clunky if you are reading the JSON. However, it makes it easier to query in MongoDB, and to read into relational table format.
Editing JSON-based metadata With Studio3T
With Studio3T, you can just import each file as a collection into a database. I use a MongoDB database Called SQLServerMetadata, and import each database as a collection under its SQL Server name. This provides me with a separate collection for each database, with a document representing a base object such as a Function, Table, Procedure or View. This allows me to edit each object individually and save it back to the collection. Then I can export it back out.
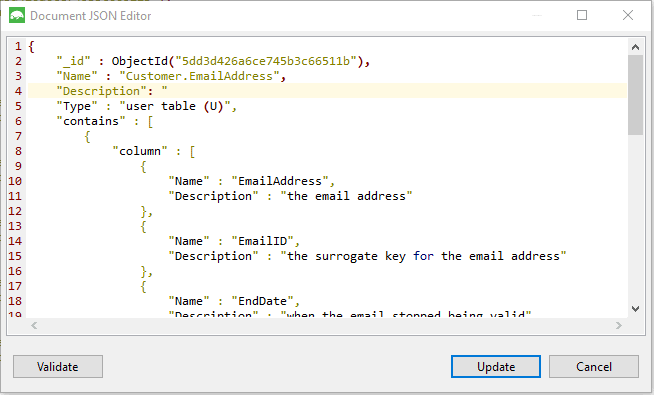
Here, I’m just beginning to document the table itself. I can edit the documentation for each table individually because each base object (Function, Table, Procedure, Rule, View or Default) is a document in MongoDB terms and I can, with Studio3T, edit each document separately and have it checked instantly as I save the edits. This means I can even edit the documentation for procedures and functions, their parameters and columns (table-valued functions and views have them- it is helpful to your team members to document them)
Having made my changes, I then save them back to the file. I do it via Studio3T’s collection-export facilities. I use
… and on the next page in the wizard …
I can even paste individual documents from Studio3T into SQL and see that I’ve made all the necessary changes. Unfortunately, MongoDB inserts surrogate primary keys in a form of ‘extended JSON’ that isn’t compatible. You need to nick them out. To do this you can use a Regex. In a file, or in SSMS, use …
‘”_id”.+’
…as the regex expression (without the single bracket delimiters!), and a blank replacement text
You can then inspect the results using the SQL that that is used within the ParseJSONMetadataToUpdateTheDocumentation.sql on Github.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
DECLARE @JSON NVARCHAR(MAX); SELECT @JSON = BulkColumn FROM OpenRowset(BULK 'PathToTheData\customers.json', SINGLE_NCLOB) AS MyJSONFile; DROP TABLE IF EXISTS #TheObjects; CREATE TABLE #TheObjects ( Name sysname NOT NULL, Type NVARCHAR(30) NOT NULL, Description NVARCHAR(3750) NULL, ParentName sysname NULL, [Contains] NVARCHAR(MAX) NULL ); INSERT INTO #TheObjects (Name, Type, Description, ParentName, [Contains]) SELECT BaseObjects.Name, BaseObjects.Type, BaseObjects.Description, NULL, [Contains] FROM OpenJson(@JSON) WITH ( Name NVARCHAR(80) '$.Name', Type NVARCHAR(80) '$.Type', Parent NVARCHAR(80) '$.Parent', Description NVARCHAR(MAX) '$.Description', [Contains] NVARCHAR(MAX) '$.contains' AS JSON ) AS BaseObjects; INSERT INTO #TheObjects (Name, Type, Description, ParentName, [Contains]) SELECT objvalues.Name, obj.[Key] AS Type, objvalues.Description, #TheObjects.Name AS ParentName, NULL AS [contains] FROM #TheObjects OUTER APPLY OpenJson(#TheObjects.[Contains]) AS child OUTER APPLY OpenJson(child.Value) AS obj OUTER APPLY OpenJson(obj.Value) WITH (Name NVARCHAR(80) '$.Name', Description NVARCHAR(MAX) '$.Description') AS objvalues; DROP TABLE IF EXISTS #EPParentObjects; CREATE TABLE #EPParentObjects ( TheOneToDo INT IDENTITY(1, 1), level0_type VARCHAR(128) NULL, level0_Name sysname NULL, level1_type VARCHAR(128) NULL, level1_Name sysname NULL, level2_type VARCHAR(128) NULL, level2_Name sysname NULL, [Description] NVARCHAR(3750), ); INSERT INTO #EPParentObjects (level0_type, level0_Name, level1_type, level1_Name, level2_type, level2_Name, Description) SELECT 'schema' AS level0_type, ParseName(Name, 2) AS level0_Name, CASE WHEN Type LIKE '%FUNCTION%' THEN 'FUNCTION' WHEN Type LIKE '%TABLE%' THEN 'TABLE' WHEN Type LIKE '%PROCEDURE%' THEN 'PROCEDURE' WHEN Type LIKE '%RULE%' THEN 'RULE' WHEN Type LIKE '%VIEW%' THEN 'VIEW' WHEN Type LIKE '%DEFAULT%' THEN 'DEFAULT' WHEN Type LIKE '%AGGREGATE%' THEN 'AGGREGATE' WHEN Type LIKE '%LOGICAL FILE NAME%' THEN 'LOGICAL FILE NAME' WHEN Type LIKE '%QUEUE%' THEN 'QUEUE' WHEN Type LIKE '%RULE%' THEN 'RULE' WHEN Type LIKE '%SYNONYM%' THEN 'SYNONYM' WHEN Type LIKE '%TYPE%' THEN 'TYPE' WHEN Type LIKE '%XML SCHEMA COLLECTION%' THEN 'XML SCHEMA COLLECTION' ELSE'UNKNOWN' END AS level1_type, ParseName(Name, 1) AS level1_Name, NULL AS level2_type, NULL AS level2_Name, Description FROM #TheObjects WHERE ParentName IS NULL; INSERT INTO #EPParentObjects (level0_type, level0_Name, level1_type, level1_Name, level2_type, level2_Name, Description) SELECT level0_type, level0_Name, level1_type, level1_Name, CASE WHEN Type LIKE '%COLUMN%' THEN 'COLUMN' WHEN Type LIKE '%CONSTRAINT%' THEN 'CONSTRAINT' WHEN Type LIKE '%EVENT NOTIFICATION%' THEN 'EVENT NOTIFICATION' WHEN Type LIKE '%INDEX%' THEN 'INDEX' WHEN Type LIKE '%PARAMETER%' THEN 'PARAMETER' WHEN Type LIKE '%TRIGGER%' THEN 'TRIGGER' ELSE 'UNKNOWN' END AS Level2_type, #TheObjects.Name AS Level2_name, #TheObjects.Description FROM #EPParentObjects INNER JOIN #TheObjects ON level1_Name = ParseName(ParentName, 1) AND level0_Name =ParseName(ParentName, 2); SELECT * FROM #EPParentObjects AS EPO |
If you think that this table looks suspiciously like the parameters you’d need to use for the various SQL system procedures that you’d need to use, you’re right. That is the underlying purpose of the code!
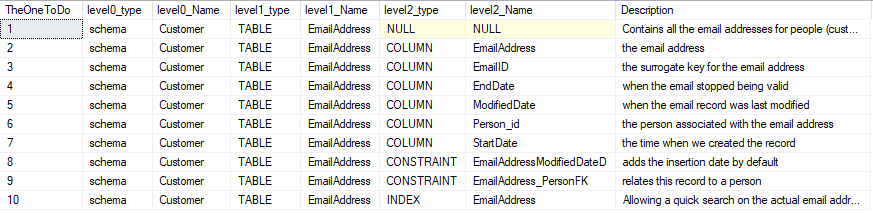
Hmm. Looks good.
Studio3T has the option of putting the resulting JSON for a database on the clipboard so you can even do the job without having to think of a way of reading the JSON into SQL Server. However, I’ve already demonstrated an easy way of doing that.
So with ParseJSONMetadataToUpdateTheDocumentation.sql, along with the Gloop, you have the means to get a report of your database in JSON, edit it to add or change the documentation and then read it back into the database to update it.
Conclusions
This is an approach to documentation that suits me fine. I can see a great deal about each table or routine while I check through the documentation. I can add information or make changes and save the results back to the development database. If you know of a better way, let me know! There are a number of different ways that you can do this, so all you need to do is to edit the Gloop to be closer to what you need. Make sure that, if you change the structure of the JSON produced by the Gloop, you make the equivalent changes to the SQL that shreds the JSON into a relational format for updating your documentation.
Just as a thought. If you put the JSON for your documentation in source control, you can then use it for inserting the documentation into a database build. It is a lot easier than the conventional way. It means that, if you keep it up to date, it also allows you to track the changes in the database even if you are using a migrations-scripts-first approach.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments