





Flyway Desktop in Database Development Work: An Overview
Flyway Desktop is a GUI tool that will automatically capture and track changes to a development database and then generate migration scripts that we can use for deployments.
As developers alter a development database, Flyway Desktop will use its built-in schema comparison engine to capture the current 'working state' of that database as a set of object-level scripts (the "schema model"). From this model it will then auto-generate, verify, and save versioned migration scripts. Each script describes the changes required to move a database from its current version to the next version, while preserving all existing data. It executes these scripts using the Flyway migration engine, to deploy the changes to other copies of the database (such as Test, QA, Staging, Production). All scripts are saved directly to the Flyway Desktop project, in the version control system.
This approach allows teams the freedom to do database development work in a variety of ways: directly changing a copy of the database, via object-level build scripts or by using migrations. It is a good choice for a development team that wishes to adopt Database DevOps processes with the objective of Continuous integration and deployment, but want to avoid the need for CLIs, custom scripting, toolchains and text editors that are inherent to using Flyway Community.
Components of a Flyway Desktop Project
Flyway Desktop is a graphical user-interface (GUI) that allows for the combined use of the Flyway CLI with Redgate's schema comparison tools. This provides a great deal of extra functionality that allows Flyway to be used with the full range of database methodologies.
Like a traditional Flyway CLI project, a Flyway Desktop project has a Migrations folder, which is the "source of truth" for the associated database, and a Flyway configuration file (flyway.conf). However, inclusion of the schema comparison engine means that it can also maintain and track changes to a schema-model folder, which is a set of object-level CREATE scripts defining the current 'state' of each object in the database. In addition, schema comparison enables auto-generation of migration scripts, but this requires an additional database, called the shadow database, to 'support' this process.
The three Flyway Desktop Editions
Only Flyway Desktop Enterprise edition autogenerates both the schema model and migration scripts. Flyway Desktop Teams edition supports the schema model only and requires manual scripting of migrations. In Flyway Desktop Community edition all scripting is manual. A full feature comparison for the three editions can be found in the docs.
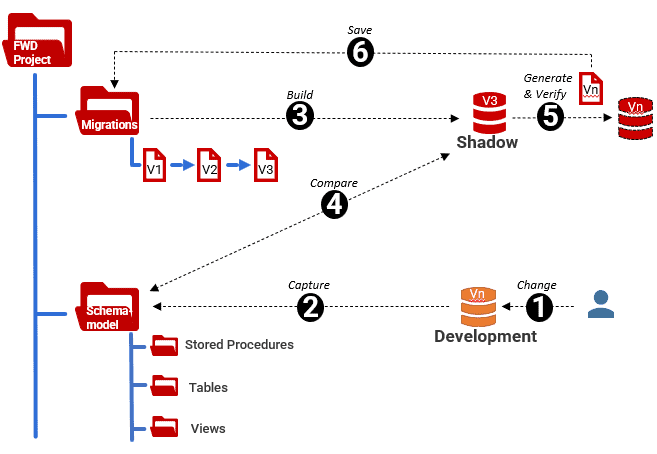
The following diagram depicts the various components of a Flyway Desktop project, plus associated databases, from the point of the individual developer using the project. Redgate recommends that each developer works on their own local copy of the 'project' and, if generating migrations, their own copy of the shadow database.

The schema model: capturing and tracking development changes
Flyway Desktop can record the current state of the database to which the project is connected in a schema model, in which every database object is matched by a script that creates it. Each type of object resides in its own directory, and the schema of each object is indicated by the filename of the scripts of the individual objects.
In the following example, the current development version, as defined by the migrations folder, is V3. However, a developer has now made some new Vn changes to their local development database (1). On the schema model tab, Flyway Desktop automatically detects these changes, by comparing the database (source) to the schema model folder (target), and displays how each object has been altered. When the developer saves the changes, it updates the schema model folder, on disk (2), to reflect the Vn changes:

Having committed these schema model changes to source control, you have a direct way of recording what was changed, when and by whom.
Each local database can be kept up-to-date with the changes made by the development team by pulling schema model changes from the shared version control repository, and applying them from the Schema model tab of Flyway Desktop. Alternatively, developers can apply changes locally by running the Vn migration script, once it's been generated, from the migrations tab.
The Shadow database: generating and verifying migrations
To deploy a new version of the database, Flyway Desktop needs a migration file that will migrate the current version to the new version. One option is simply to write and test the migration script then save it to the migrations folder, so Flyway can apply it to the database. However, if you have the Enterprise edition of Flyway Desktop, then for certain RDBMSs it can generate these migration scripts automatically.
If a developer is making changes directly to the database, Flyway Desktop needs some way to retrospectively capture into a migration file any changes saved to the schema model that have not yet been saved to the migrations folder. However, whereas Redgate's schema comparison engine can read a schema model as easily as a database, to do a comparison, it cannot parse the full gamut of migration files. It therefore 'materializes' the contents of the migrations folder in the shadow database. This is a live database without data. Flyway Desktop always maintains it at the current version of the database, as represented by the migration files at Flyway's 'locations'.
If you can think of the schema model as representing the state of the latest development version, then the migrations folder represents the current "releasable version" of the database, or "release candidate".
When you switch to the Generate migrations tab, Flyway Desktop builds the latest 'release candidate' (v3 in this example) in the shadow database, by running any necessary scripts in the migrations folder (3). It compares the schema model folder (source) to the shadow database (target) and displays a list of objects that are different (4). It will then generate the Vn script that captures these changes and verify it by running it on the shadow database (5). Once verified, we can save it to the migrations folder (6):
For a particularly complex migration, you may need to be manually edit the migration script to ensure data integrity, perform any necessary data changes, or to optimize the script process, before saving it.
Having now incorporated the new development changes into a new release candidate, in the migrations folder, we commit them to version control so the team can keep other databases up-to-date.
Another use of the Shadow database is to create 'undo'(u) migration files alongside versioned (v) migrations. Flyway Desktop does this simply by comparing the shadow database at Vn (after step 5 above) to the schema model on disk to produce a reverse-migration script that undoes the changes in the corresponding versioned migration script. As for the "v" script you many need to edit the "u" script before saving it.
Whether using the shared or isolated model of development, you need one shadow database per developer who is generating migrations. If one developer contributes to multiple projects, then ideally it will be one shadow database per developer per project, but one per developer is still the minimum.
Team working with Flyway Desktop
Flyway Desktop works best when each user has their own dedicated copy of the development database. This isn't always possible, so you can specify a development database at the project level if all or most of the team members will be sharing the same development database.
With Enterprise edition, rather than write migration scripts, developers are free to work directly with a database, using an ER modelling tool or a table-builder, or perhaps for more complex development work where DDL code must be applied directly, and then have Flyway Desktop auto generate the migrations retrospectively, as described above.
Setting up a team project
In the "isolated developer' model, one developer creates the initial flyway Desktop project and saves it to the version control system. A developer joining the project simply 'clones' the project repository to their local file system and connects it to their local development database. If the developer is starting from scratch, they can connect to an empty dev database, run the contents of the migrations folder to bring the schema to the latest version, and then import the development data. If connecting to an existing database, they can apply the latest schema changes to the database as well as capture migrations for any local changes that need to be part of the project.
Saving and sharing database changes
The features being developed are generally worked-on in a series of changes to the copy of the database within the project, which are saved to disk on the individual workstation, both as object-level changes and migration files, committed to version control locally and then shared with other team members
However, Flyway can support different development methods that involve using migration scripts or by altering object-level scripts.
Working on object-level scripts
In this approach, developers make changes to local databases and save them to the schema model. They share those changes by pushing the schema model changes to the shared repo and regularly pull committed changes from other developers working on the same branch (or other branches), dealing with any conflicts and updating the local object-level scripts that have changed.
Once the sprint is done, a lead developer (the "release engineer") is responsible for devising and testing the migration script to capture all the changes and ensuring all existing data will be preserved.
Migration-driven approach
Each developer is responsible for devising and testing a migration script for their local changes. If they want to incorporate another developer's changes into their local database, they do it by running the migration script with those changes.
Branch-based development?
In Phil Factor's Flyway branching walkthrough article, he proposes use of task-based branches, where each branch has its own development database. This allows developers freedom to experiment, reset the database, use undo scripts and so on, and also supports effective pre-merge testing since every developer has direct access to both their local feature branch database, and the development branch database. By comparing the latest development version to the version that existed when the feature branch was created, we can get a feel for any potentially conflicting changes that have been made in the meantime. We can then pull in completed migrations from the feature branch project to test the integration. The committed work from each 'feature branch' is then assessed in a pull request, and hopefully integrated smoothly into the database's development branch
There is no direct support for this "one database per branch of development" model in Flyway Desktop. In fact, it generally encourages a simple model where all developers work in the same development branch, and eventually submit a pull request to the 'release' or 'main' branch. It is assumed that the merge will happen automatically in the version control system.
However, it is very simple to create an isolated feature branch directly from Flyway Desktop so a developer can easily create from their local copy of the project. Pre-merge testing would require maintaining a separate Flyway Desktop project representing the development branch.
Settings, security, and logins
Flyway is very configurable. There are settings to control everything from the name of the overall team project, the name and location of Flyway's schema history table, to the delimiters used for placeholders.
Each user of Flyway can configure values that relate to the workstation, the current user or the current Flyway project. There are therefore three different flyway config files. The values that relate to the project details and settings should be shared with the team. The project settings shouldn't include names of users, and values that relate to the workstation, such as the license key, shouldn't be in the user area. You also can't put database connection strings in the user area because these relate to projects, and any particular config file can contain only one string.
Flyway Desktop adds two extra 'per-user settings' config files, saved separately to the main flyway.conf project file, so that each developer can use their own development database. The values in these files are similar to environment variables and parameters in that they override what is in the Flyway project file. This is done to support 'shadow databases' which aren't part of Flyway. They are likely to vary for each user of a project. These files have the .user.json extension. Any IDs and passwords are held in a credentials store.
It is possible for shadow database details to be kept in the main project file, but this will prevent you using dedicated/isolated database development. The .user.json file is automatically included in the .gitignore file so these user-specific settings are not committed to version control.
Data considerations
Development databases will need to have development data loaded into them and will usually need more than one data set, according to the database tests required. Data be loaded by a separate process and should involve a similar volume of data to that which the production version has or is expected to have.
Data sets should not be done within a versioned migration because data does not determine the version of the database in any way. The converse is true, of course, in that the development data is likely to change with each major version. Finally, you need to ensure that there is no possibility of test data leaking into production due to a data insertion within a migration.
Redgate supplies a tool, SQL Data Generator, which works well with Flyway for providing development data and can be extended by SQL, file-lists, Python or reverse-regex expressions.
Certain data is essential for a database to function, usually referred to a Static Data. This can be provided in most favors of SQL via a view that contains a VALUES expression, so that it can be introduced conveniently as read-only table-sources using DDL code. This is typically data that almost never changes such as zip/postal codes, country lists, or even application settings.
Extending the system
At the point where a release is planned, Flyway CLI begins to exhibit its power, which lies in its support for PowerShell, Java and DOS scripting.
If you're using Flyway Teams (or Community) then Flyway's callback scripts allow tasks to be executed automatically before or after a range of events such as the start or end of a migration run. These tasks might include loading of datasets for testing, reporting or automated code analysis. This system can be also used for the workflow and messaging that supports integration and release. Luckily, Phil Factor provides a Flyway Teamwork PowerShell framework that demonstrates how one might approach this, and also fills a few 'holes' in the information that Flyway will currently pass to scripts about the projects settings and current database version.
Flyway Enterprise include several built-in database build and release checks, such as a database drift check and a change report, which can be run from Flyway Desktop manually, or automated as part of a CI/CD pipeline. The Flyway documentation provides some example pipeline implementations.
Adopting Flyway Desktop
Redgate maintains a checklist for the adoption of Flyway Desktop.
You will need to use a version control system such as Git for coordinating the contributions of the individual dedicated projects into the release database. This is likely to include the branching, pull requests, merges, code reviews and integration tests. It will need to track feature branches until they are due for release and ensure that they can be successfully merged.
If you change a conventional database development into a Flyway Development, Flyway Desktop will advise that you create a baseline migration script file from the "production reference" database, meaning either the production database itself, or a database that represents the current state (schema) of production. This will create a SQL script in the migrations folder with a "B" prefix, to which you assign a version number. This script will allow you to create a new copy of the database, from that version onwards. All existing copies of the database, including those in test and staging will need to be brought up to the same version by running the baseline migration. This creates a schema history table in each database so that they can be kept up to date using Flyway.
Before a release, you will also need to 'baseline' the production system at the same version number, using the Flyway baseline command, which will not make any changes to the database other than to create the flyway schema history table and establish the baseline version number.
There will need to be a build process for the release candidate that will validate the individual contributions, perform any required code analysis that are required to meet code-quality standards, and execute the automated integration tests.
When a new release candidate is made available from Flyway Desktop, by merging into a release branch, this can trigger an automated build and release pipeline of tasks, based around use of Githooks and release servers.
Flyway Desktop best practices
Although a variety of methods can be used to make changes to the isolated database, the migration files represent the 'source of truth'. However, if you edit the generated migration file to include other metadata changes before committing it, your isolated database will not have these changes and will exhibit 'drift'. It is better to make all changes to the database and make sure the schema model and database are in sync before generating the migration.
Flyway undo (U) files together with the migrations provide an excellent way of developing code on a isolate development database, because if a migration is broken, you can undo it, make the necessary changes, and then redo the migration. You only commit a migration to the development branch when you are confident that it works exactly as required.
Merges must be done to a parent branch only if there is an undo file that can remove the effects of the merge in the case that there are any conflicts or broken references. This allows a corrected migration to be applied without errors. There is nothing more horrid in a Flyway development than a series of migrations that each try to heal the problems in the previous one.
Always alter the default description field given to a filename by Flyway Desktop to provide a concise description of the nature and purpose of the migration. This will be in the flyway schema history of every copy of the database, and it is beyond tiresome to have string of nonsense in the description.
A quick glossary of Flyway Desktop jargon
Some Flyway jargon can make it difficult for the newcomer to understand the documentation. Here are some of the more opaque or unusual terms.
| Baseline command | This is a Flyway command that means inserts a special table into the database that records the version that you specify. It will subsequently record all the migrations that take place. This allows Flyway to maintain the database at the correct version. |
| Baseline migration | This is a migration file that is only used in one circumstance, for the initial migration run when a database's flyway schema history table has been 'Cleaned' or is absent, and database objects aren't there. Only the baseline file nearest to the required version is used. |
| Capturing Changes | This means ensuring that a change to the metadata of a database via DDL SQL statements that needs to be committed as a permanent change is recorded in Git along with the date, and identifier of the developer making the change |
| CI/CD Pipelines | Continuous Integration of databases requires that the process of merging and testing DDL code is almost fully automated. This helps to catch bugs early in the development cycle, where they are less expensive to fix. Continuous Delivery (CD) follows integration, and involves a highly automated process of building, testing, and deploying databases using migration files to one or more test, staging and production environments. Automated performance, security and usability tests may run during this stage. If all tests pass the database migration code can be manually approved at an approval gate for update to production. Continuous Deployment differs from Continuous Delivery in that deployment to production happens without manual approval. Examples for Flyway Desktop are here |
| Dedicated/isolated development | Each user works on an isolated copy of the data and relies on the version control system to synchronize the work. This fits better with Git which is geared towards this mode of working with procedural code. Flyway Desktop relies on Git to coordinate and integrate the work so is much easier to use with the dedicated/isolated model. |
| Downstream databases | Any copies of the development database after the creation of the build that will be used in the deployment workflow, such as test, including the eventual target, the production database. Normally, this term refers to reporting systems such as OLAP databases that are part of the wider application being developed. |
| Downstream environments | The network hosting, settings, security and context of the databases required to undertake the tasks of deployment, such as testing, signoff, and staging |
| Flyway schema history table | This is a database table inserted into a database to allow Flyway to maintain its version, ensure the integrity of the migration files, and apply any type of migration appropriately to reach the required version of the database. |
| Per-user database | This is a development technique that makes it easier to track who made particular changes to a database in development, using Git. Some RDBMSs allow you to record this easily, but most don't. |
| Project | This means a flyway project, which is a directory containing a configuration file called flyway.conf. When Flyway starts, it will scan the installation directory, user area and finally the current working directory for all files with this name and reads the settings from them. Values are over-written. The final flyway.conf will provide the details of the project such as the JDBC connection string to the database. Flyway Desktop has extra config details for items such as the Shadow database. |
| Shadow Database | A database created purely from the migration files in the flyway 'locations', to give a live copy of the current version. |
| 'Source of Truth' | This is the source of the DDL SQL code that defines the version of the database. For a Flyway development, this is the migration code that alters the database from one version to either the next version (a 'Version migration') or the previous ('Undo'): To make it easier to explore how individual objects change, it is usual to save object-level scripts as well, but these supplement the 'source of truth'. |
Conclusions
Flyway Desktop will help the end-to-end developer who is familiar with Git, because it provides a way of developing a database as if it were procedural coding. It hides the complexities of using Git, SQL Compare and Flyway together. It will provide a great deal of what the developer requires and is ideal for the database application that must be developed with application and database in close synchronization.
Where next?
Getting Started with Flyway Desktop walks you through the process of creating a Flyway Desktop project for an existing database. It demonstrates the basics of building a schema model, generating and running migration scripts, and saving changes to source control.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
Redgate Flyway Desktop
Redgate Flyway Desktop helps you easily and safely version control your database schema and prepare validated deployments
You may also like

Article
Flyway Alerting and Notifications
Once a scripted Flyway task is tested and bedded-in, it should rarely cause errors, so when one happens the team need to be notified immediately, especially if it is part of an automated deployment process. This article provides a PowerShell cmdlet that will execute any Flyway command, process and filter the Flyway output and send any errors to the chosen notification system. You can receive the Flyway error alerts on your mobile phone, if required!
Article
Making Full Use of Environment Variables for Flyway Settings
Environment Variables make interactive use of Flyway much easier, and they are essential when developing callback scripts. This article explains the range of configuration details you can provide and how, and demos a PowerShell script to auto-convert the parameter values stored in Flyway .conf files into environment variables.
Article
Getting an Overview of Changes to a PostgreSQL Database using Flyway
How to use Flyway and PowerShell to automatically generate a database build script every time Flyway successfully created a new version. You can then investigate schema changes between versions simply by using a Diff tool to compare build scripts.
Article
Piping, Filtering and Using Flyway Output in PowerShell
Flyway's output is often overwhelmed with verbose messages, most of which we can ignore but some of which provide vital warnings about failed compilations, or useful details about what a migration or callback did. I'll show how to use some pipeline-aware PowerShell functions to filter out and save the bits we want and pass the results along in a form that is useful to the next process in the pipeline.
Article
Flyway Database Drift and How it Happens
Flyway's approach to database migrations is based on strict versioning, but there is a limit to what a single process can do to prevent 'drift'. This article explains how drift can happen, and why you also need source control and external processes that log changes, to prevent it.
Article
Introducing Spawn: the instant way to create free database copies in the cloud
Imagine a world without the open source database migrations tool, Flyway. Migration scripts being run in the wrong order, changes getting overwritten, having to dump hours of work because you started with an out-of-date version. Flyway is so popular today because it sorts out the issue of database migrations in such a simple and elegant way. No one is going back to how things used to be done. Getting your database migrations process under control is a big win, but schema migrations are only half the story. The data within the database can have huge implications on the behavior of your
Loading comments...