





Managing SQL Server Database Documentation during Flyway Development
I'll provide a JSON query that will extract descriptions of all your tables, from the SQL Server extended properties, into a JSON document. This JSON report is single source of database documentation, providing details and descriptions of all existing tables and their columns, in a format that is both very easy to read, and extendable. I've also written a PowerShell task for Flyway, to automatically produce this report, for each version.
The idea is that the team will maintain this SQL 'data dictionary' during development, adding documentation for each new object, and improving existing descriptions. I also provide a query they can use to apply the JSON document to the database, for each new version. This can be executed independently, or as a 'callback' script, during every Flyway deployment. The query uses sp_addextendedproperty to add details of each new table and column, including an MS_description to describe the purpose of each one, and updates documentation for all existing objects.
The aim is for a single source of documentation for each database, useful for quickly familiarizing new developers with the schema, and them helping them maintain comprehensive documentation throughout development. It should allow them, and the Ops team, to instantly see what's in the database, for every version.
A single 'source of truth' for documenting database objects
The process of building and modifying a database isn't always as simple as many of the advocates of a controlled system would have us believe. There are times when you need to change the ways you do things to get the job done in reasonable time and effort. To provide a flexible system that accommodates the way you need to work, your tools need to be versatile and flexible. I must admit that my source control systems in the past have occasionally had all the order and systematization of a teenager's bedroom, mainly due to my liking for Entity-Relationship modelling tools and other visual tools for helping with database development.
Database documentation is an example of the sort of task that doesn't really fit into any methodology. You need to be able to view the complete story. Imagine, for example, that you need to provide an up-to-date description of your base tables for developers, business analysts or technical architects. If this is unnecessary for your project, then you're lucky and probably in a parallel universe.
A migration approach to database development can make the task of producing a complete data documentation more difficult because you will have tables that have been migrated in several versions via several files, with the descriptions in source code comments. You need to scoop these comments up in a way that can be easily read.
Aha, you say, just create a build script for each table, liberally sprinkled with helpful comments. Nope, this won't wash. Unlike routines such as views, functions and procedures, comments aren't preserved in the metadata, for tables. Even if they were, there is just too much detail to be scanned quickly to get the overview.
I believe that the best 'deliverable' to de-mystify the purpose of tables and their columns for other co-workers, and even yourself in the future, is a markup document, either XML or JSON, that describes each table. When I say 'table', I mean any object that is a table source, such as a view, table, or table-valued function. I've assumed that, for most of your team, you wouldn't want to document your constraints, indexes or any other child object-types of a table. It is perfectly possible, though at this stage slightly scarier.
Here is a sample table from our extended sample 'Pubs' database. The extra work was in making it readable, and extendable. This is something you can publish to co-workers, and which the developers can then alter and improve.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
{
"TableObjectName":"dbo.authors",
"Type":"user table",
"Description":"The authors of the publications. a publication can have one or more author",
"TheColumns":{
"au_id":"The key to the Authors Table",
"au_lname":"last name of the author",
"au_fname":"first name of the author",
"phone":"the author's phone number",
"address":"the authors first line address",
"city":"the city where the author lives",
"state":"the state where the author lives",
"zip":"the zip of the address where the author lives",
"contract":"had the author agreed a contract?"
}
}
|
You will want this document to become the 'source of truth', so that you can add or amend the documentation here. For this to be practical, you will, at various times, want to get this information in or out of a database, and ideally, extract comments from a script and save them into a database, or insert them into a document like this. In this article, I'll be showing a SQL script that takes the JSON document and uses it to update the descriptions for all the tables and table sources in the database, whatever the version of the database.
Documenting individual tables using database properties
In the various relational database systems, there is a way of adding and updating descriptions to various database objects like columns, indexes, tables, and functions. SQL Server has extended properties. PostgreSQL and Oracle have the COMMENT command. This is a much better, less volatile, way of commenting tables than annotating the source code. It also allows you to separate comments out from DDL code so that it isn’t registered as a metadata change.
Parsing comments in source code
If you have a lot of comments embedded in source code, and you need to turn them into documentation, it is possible to use a parser to find all the /*comment blocks */ and --inline comments, but it isn't ideal. See How to document SQL Server Tables.
None of these methods produce easily readable comments in your source-code as you can see:
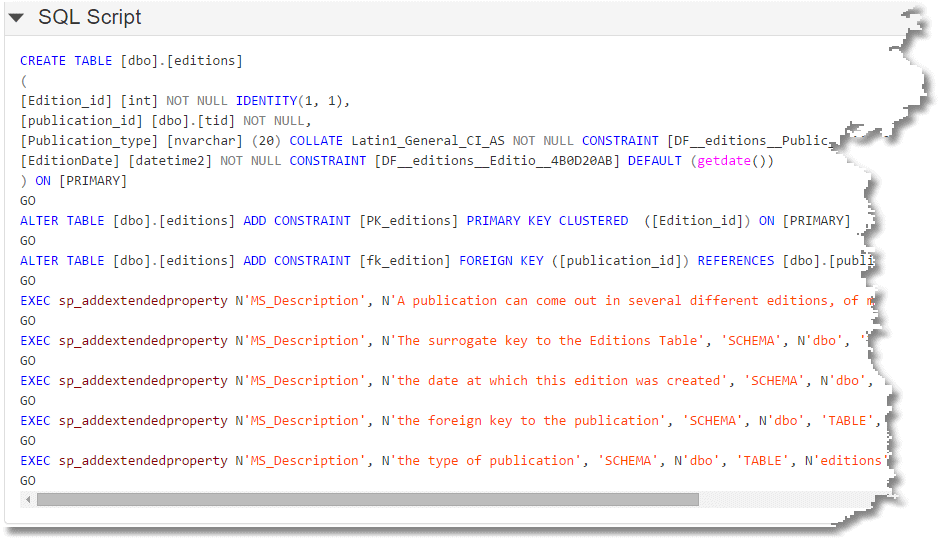
Documenting all tables in JSON
We'd like to collect all these table and table source descriptions into a structured document, such as JSON, which our developers can then embellish, and then publish it all as more readable and versatile documentation, as well as use it to update the extended property descriptions for each table.
It makes sense, then, to be able to generate the documentation in JSON form, from the database, and to be able update the database from a JSON document. It is therefore better, I reckon, to maintain just one 'master' script, throughout development, that documents the database in JSON and that we can use to insert or update the documentation that is preserved within the database properties. You'd be able to use it at the end of every build because it will only add documentation to objects that exist at the time. Whenever new objects, with or without documentation, are generated you can generate fresh JSON documentation and use it to update the master script.
The big advantage of this approach is that it can easily be accommodated by both a migration-based approach such as Flyway, and a static approach. You'd still be able to maintain an object-level source with the descriptions included with them, but the ultimate source of all documentation would be the 'data dictionary' we've created.
For this to work, the master script that we maintain for the documentation needs to work on any version of the database, or even on an empty database, or an entirely different database. Without triggering an error or warning, or in any other way becoming over-excited, it would resolutely refuse to touch any object that wasn't exactly as specified but adds documentation to tables and columns that match.
Generating the JSON Document
The task of generating a JSON document that lists out tables and their columns, along with their descriptions, if any, is best done in SQL. It's useful to refer to, so it is important to provide a JSON structure that is easy to read. I've already provided a sample output, above. To produce this for all the tables in a database, I use this code. Recent versions of SQL Server (2017 and later) can use the first query (which uses string_agg)and earlier versions will use the XML variant to produce the same result:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
DECLARE @Json NVARCHAR(MAX)
DECLARE @TheSQExpression NVARCHAR(MAX)
DECLARE @TheErrorNumber INT
SELECT @TheErrorNumber=0
BEGIN TRY
EXECUTE sp_executesql @stmt = N'Declare @null nvarchar(100)
SELECT @null=String_Agg(text,'','') FROM (VALUES (''testing''),(''testing''),(''one''),(''Two''),(''three''))f(Text)'
END TRY
BEGIN CATCH
SELECT @TheErrorNumber=Error_Number()
END CATCH;
/*On Transact SQL language the Msg 195 Level 15 - 'Is not a recognized built-in function name'
means that the function name is misspelled, not supported or does not exist. */
IF @TheErrorNumber = 0
SELECT @TheSQExpression=N'Select @TheJson=(SELECT Object_Schema_Name(TABLES.object_id) + ''.'' + TABLES.name AS TableObjectName,
Lower(Replace(type_desc,''_'','' '')) AS [Type], --the type of table source
Coalesce(Convert(NVARCHAR(3800), ep.value), '''') AS "Description",
(SELECT Json_Query(''{''+String_Agg(''"''+String_Escape(TheColumns.name,N''json'')
+''":''+''"''+Coalesce(String_Escape(Convert(NVARCHAR(3800),epcolumn.value),N''json''),'''')+''"'', '','')
WITHIN GROUP ( ORDER BY TheColumns.column_id ASC ) +''}'') Columns
FROM sys.columns AS TheColumns
LEFT OUTER JOIN sys.extended_properties epcolumn --get any description
ON epcolumn.major_id = TABLES.object_id
AND epcolumn.minor_id = TheColumns.column_id
AND epcolumn.class=1
AND epcolumn.name = ''MS_Description'' --you may choose a different name
WHERE TheColumns.object_id = TABLES.object_id)
AS TheColumns
FROM sys.objects tables
LEFT OUTER JOIN sys.extended_properties ep
ON ep.major_id = TABLES.object_id
AND ep.minor_id = 0
AND ep.name = ''MS_Description''
WHERE type IN (''IF'',''FT'',''TF'',''U'',''V'')
FOR JSON auto)'
ELSE
SELECT @TheSQExpression=N'Select @TheJson=(SELECT Object_Schema_Name(TABLES.object_id) + ''.'' + TABLES.name AS TableObjectName,
Lower(Replace(type_desc,''_'','' '')) AS [Type], --the type of table source
Coalesce(Convert(NVARCHAR(3800), ep.value), '''') AS "Description",
(SELECT Json_Query(''{''+Stuff((SELECT '', ''+''"''+String_Escape(TheColumns.name,N''json'')
+''":''+''"''+Coalesce(String_Escape(Convert(NVARCHAR(3800),epcolumn.value),N''json''),'''')+''"''
FROM sys.columns TheColumns
LEFT OUTER JOIN sys.extended_properties epcolumn --get any description
ON epcolumn.major_id = Tables.object_id
AND epcolumn.minor_id = TheColumns.column_id
AND epcolumn.class=1
AND epcolumn.name = ''MS_Description'' --you may choose a different name
WHERE TheColumns.object_id = Tables.object_id
ORDER BY TheColumns.column_id
FOR XML PATH(''''), TYPE).value(''.'', ''nvarchar(max)''),1,2,'''') +''}'' )) TheColumns
FROM sys.objects tables
LEFT OUTER JOIN sys.extended_properties ep
ON ep.major_id = TABLES.object_id
AND ep.minor_id = 0
AND ep.name = ''MS_Description''
WHERE type IN (''IF'',''FT'',''TF'',''U'',''V'')
FOR JSON AUTO)'
EXECUTE sp_EXECUTESQL @TheSQExpression,N'@TheJSON nvarchar(max) output',@TheJSON=@Json OUTPUT
SELECT @JSON
|
In the DatabaseBuildAndMigrateTasks.ps1 PowerShell task that does this, and saves the result to disk, I show how to run either of these routines based on the compatibility level of the database.
Applying the JSON document to the database
Once you've taken this JSON document and added lots of helpful descriptions, you'll want to add or update these descriptions as extended properties to the database (in Oracle or PostgreSQL you'd use COMMENTs). This script ought really to be completely idempotent, but to achieve this, you'd have to add complexity to the JSON to determine the difference between a blank comment and a non-existent comment. If you allow blank comments to be inserted into the database, they will appear in generated scripts as a mute reminder that you've yet to fill it in, and generally you can easily alter the script to 'fill in the blank'.
Here is an example in which I've severely reduced the number of tables to two. The full source is on GitHub.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
|
DECLARE @JSONTablesAndColumns NVARCHAR(MAX) =
N'[
{
"TableObjectName":"dbo.editions",
"Type":"user table",
"Description":"A publication can come out in several different editions, of maybe a different type",
"TheColumns":{
"Edition_id":"The surrogate key to the Editions Table",
"publication_id":"the foreign key to the publication",
"Publication_type":"the type of publication",
"EditionDate":"the date at which this edition was created"
}
},
{
"TableObjectName":"dbo.prices",
"Type":"user table",
"Description":"these are the current prices of every edition of every publication",
"TheColumns":{
"Price_id":"The surrogate key to the Prices Table",
"Edition_id":"The edition that this price applies to",
"price":"the price in dollars",
"advance":"the advance to the authors",
"royalty":"the royalty",
"ytd_sales":"the current sales this year",
"PriceStartDate":"the start date for which this price applies",
"PriceEndDate":"null if the price is current, otherwise the date at which it was supoerceded"
}
}
]';
DECLARE @TableSourceToDocument TABLE
(
TheOrder INT IDENTITY,
TableObjectName sysname NOT NULL,
ObjectType NVARCHAR(60) NOT NULL,
TheDescription NVARCHAR(3750) NOT NULL,
TheColumns NVARCHAR(MAX) NOT NULL
);
DECLARE @ColumnToDocument TABLE
(
TheOrder INT IDENTITY,
TheDescription NVARCHAR(3750) NOT NULL,
Level0Name sysname NOT NULL,
ObjectType VARCHAR(128) NOT NULL,
TableObjectName sysname NOT NULL,
Level2Name sysname NOT NULL
);
DECLARE @ii INT, @iiMax INT; --the iterators
--the values fetched for each row
DECLARE @TableObjectName sysname, @ObjectType NVARCHAR(60),
@Schemaname sysname, @TheDescription NVARCHAR(3750),
@TheColumns NVARCHAR(MAX), @Object_id INT, @Level0Name sysname,
@Level2Name sysname, @TypeCode CHAR(2);
INSERT INTO @TableSourceToDocument (TableObjectName, ObjectType,
TheDescription, TheColumns)
SELECT TableObjectName, [Type], [Description], TheColumns
FROM
OpenJson(@JSONTablesAndColumns)
WITH
(
TableObjectName sysname, [Type] NVARCHAR(20),
[Description] NVARCHAR(3700), TheColumns NVARCHAR(MAX) AS JSON
);
--initialise the iterator
SELECT @ii = 1, @iiMax = Max(TheOrder) FROM @TableSourceToDocument;
--loop through them all, adding the description of the table where possible
WHILE @ii <= @iiMax
BEGIN
SELECT @Schemaname = Object_Schema_Name(Object_Id(TableObjectName)),
@TableObjectName = Object_Name(Object_Id(TableObjectName)),
@ObjectType =
CASE WHEN ObjectType LIKE '%TABLE' THEN 'TABLE'
WHEN ObjectType LIKE 'VIEW' THEN 'VIEW' ELSE 'FUNCTION' END,
@TypeCode = CASE ObjectType WHEN 'clr table valued function' THEN 'FT'
WHEN 'sql inline table valued function' THEN 'IF'
WHEN 'sql table valued function' THEN 'TF'
WHEN 'user table' THEN 'U' ELSE 'View' END,
@TheColumns = TheColumns, @TheDescription = TheDescription,
@Object_id = Object_Id(TableObjectName, @TypeCode)
FROM @TableSourceToDocument
WHERE @ii = TheOrder;
IF (@Object_id IS NOT NULL) --if the table exists
BEGIN
IF NOT EXISTS --does the extended property exist?
(
SELECT 1
-- SQL Prompt formatting off
FROM sys.fn_listextendedproperty(
N'MS_Description', N'SCHEMA', @Schemaname,
@ObjectType, @TableObjectName,NULL,NULL
)
)
-- SQL Prompt formatting on
EXEC sys.sp_addextendedproperty @name = N'MS_Description',
@value = @TheDescription, @level0type = N'SCHEMA',
@level0name = @Schemaname, @level1type = @ObjectType,
@level1name = @TableObjectName;;
ELSE
EXEC sys.sp_updateextendedproperty @name = N'MS_Description',
@value = @TheDescription, @level0type = N'SCHEMA',
@level0name = @Schemaname, @level1type = @ObjectType,
@level1name = @TableObjectName;
--and add in the columns to annotate
INSERT INTO @ColumnToDocument (TheDescription, Level0Name,
ObjectType, TableObjectName, Level2Name)
SELECT [Value], @Schemaname, @ObjectType, @TableObjectName, [Key]
FROM OpenJson(@TheColumns);
END;
SELECT @ii = @ii + 1; -- on to the next one
END;
SELECT @ii = 1, @iiMax = Max(TheOrder) FROM @ColumnToDocument;
--loop through them all, adding the description of the table where possible
WHILE @ii <= @iiMax
BEGIN
SELECT @TheDescription = TheDescription, @Level0Name = Level0Name,
@ObjectType = ObjectType, @TableObjectName = TableObjectName,
@Level2Name = Level2Name
FROM @ColumnToDocument
WHERE @ii = TheOrder;
IF EXISTS --does the column exist?
(
SELECT 1
FROM sys.columns c
WHERE c.name LIKE @Level2Name
AND c.object_id = Object_Id(@Level0Name + '.' + @TableObjectName)
)
BEGIN --IF the column exists then apply the extended property
IF NOT EXISTS --does the extended property already exist?
(
SELECT 1 --does the EP exist?
FROM sys.fn_listextendedproperty(
N'MS_Description',N'SCHEMA',@Level0Name,
@ObjectType,@TableObjectName,N'Column',
@Level2Name
)
)--add it
EXEC sys.sp_addextendedproperty @name = N'MS_Description',
@value = @TheDescription, @level0type = N'SCHEMA',
@level0name = @Level0Name, @level1type = @ObjectType,
@level1name = @TableObjectName, @level2type = N'Column',
@level2name = @Level2Name;
ELSE --update it
EXEC sys.sp_updateextendedproperty @name = N'MS_Description',
@value = @TheDescription, @level0type = N'SCHEMA',
@level0name = @Level0Name, @level1type = @ObjectType,
@level1name = @TableObjectName, @level2type = N'Column',
@level2name = @Level2Name;
END;
SELECT @ii = @ii + 1; -- on to the next one
END;
GO
|
Using a query for updating or adding documentation after every migration
If you are using Flyway, you can add to your migration files a SQL afterMigrate callback script that is an expanded version of the script I've just shown. It will add or update the documentation for all existing objects. This call back script will be your 'live' data dictionary, as in this example, but with all the tables and table-sources added.
The script is called after each migration, so all you need to do is keep this version up-to-date, and it is applied, where possible, to every version.
Maintaining your JSON table-documentation
If you generate a new JSON document of your documentation from the latest version of the database, any 'blank' documentation strings will immediately highlight missing documentation. You will also see all new objects that have been properly created with their documentation. You can then use this to update the afterMigrate callback script.
Automatically generating the JSON table-documentation
I've written a PowerShell task $ExecuteTableDocumentationReport to produce the JSON report of the documentation that is in place for each version. It is here in DatabaseBuildAndMigrateTasks.ps1.
Conclusion
A documentation of a database is something you need to see, as a whole, so it fits uneasily in a purely migration-based database development. It is so much easier to see all the documentation for a database in a single place. The major relational databases have ways of applying notes and descriptions to database objects, and by using them, you can ensure that they are to hand for the database developer. By placing these annotations into a JSON report, they become accessible to other ways of publishing documentation, such as in PDF, eBook or on a website. They are also eminently searchable. In short, it is good practice to have a data catalog like this readily available. I have used SQL Server in this example, but this applies for Oracle and PostgreSQL with only minor modifications.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
DevOps Collaboration and Process Visibility in Flyway Developments
A brief history of the DevOps movement and a discussion of the pivotal role of a tool like Flyway in the DevOps toolchain, when developing and delivering database changes.
Article
Automating Migrations for Multiple Databases using Flyway
During development you need a fast, automated way to build multiple copies of a database on any development or test server, with each database at the right version. This article provides a PowerShell automation script for Flyway that will do the job.
Article
Getting Started with TOML Configuration in Flyway
This article discusses Flyway's transition from CONF to TOML configuration files. It highlights the advantages of TOML, such as improved readability, flexibility in managing complex database configurations, and support for specifying multiple database environments. It also discusses a few of the differences to be aware of when switching existing Flyway projects to the new config system.
Article
Flyway V10 has landed
We are excited to announce that the latest version of Flyway. Version 10 includes a number of major changes which enhance the capabilities of Flyway and will allow all users to stay up to date on the most secure version of Flyway ever released regardless of which database you are using.
Article
What is Flyway Enterprise?
How Flyway Enterprise will help you ensure that databases and applications can grow and develop in step, and to implement a workflow for delivery of database changes that is resilient, repeatable, fast and visible.

Article
Redgate’s roadmap for cross-database DevOps
At Redgate, we strongly believe that all databases should be managed and orchestrated in the same way, with the same standards of security and quality in releases. For the past few years, we’ve been leading the adoption of database DevOps by focusing on the most challenging parts of the process like version control, continuous integration and making deployments consistent, predictable and repeatable. Our solutions help automate the process of testing and promoting database changes across the pipeline, just as you would expect to do with application code. That’s not just with the popular database platforms like SQL Server and Oracle.
Loading comments...