





Solving Visual Studio database delivery problems with SQL Change Automation
For .NET developers working with Visual Studio (VS), the introduction of Database Projects with SQL Server Data Tools (SSDT) brought to VS the ability to manage changes to the database schema and code objects, just like any other type of application code. An added advantage is that the declarative style of SSDT’s project files lends itself to effective version control practices, such as being able to view an audit trail of database changes at the object level.
However, at the point where you need to deploy your changes and preserve existing data in the target database, certain modifications to database tables need careful handling. There will always be some updates, such as splitting or merging columns or changing the data type or size of a column, where the SSDT model of storing the required database state in version control may contain insufficient information to determine how existing data in the target database should be preserved. In such cases, the developer needs to be able to tweak the generated migration script manually.
This is where a tool such as Redgate SQL Change Automation can be very useful. It integrates directly into VS and is actually built on top of the SSDT database project system, but offers a different and more versatile migrations/state hybrid approach. Changes to database code objects can be automated using a state-driven approach. SQL Change Automation will auto-generate migration scripts to handle table changes, while making it very easy to customize that script as required, in order to handle delicate migrations.
State-based deployment challenges
Despite SSDT's ability at designing and deploying SQL Server databases in VS, there are a number of database change scenarios where problems can arise. The reason for these issues is related to the fact that SSDT uses a purely state-based approach to database deployment (also referred to as the model-driven approach), as opposed to the migrations-based approach of more traditional database change management processes.
Figure 1 shows how SSDT generates its deployment (upgrade) scripts using the state-based method:
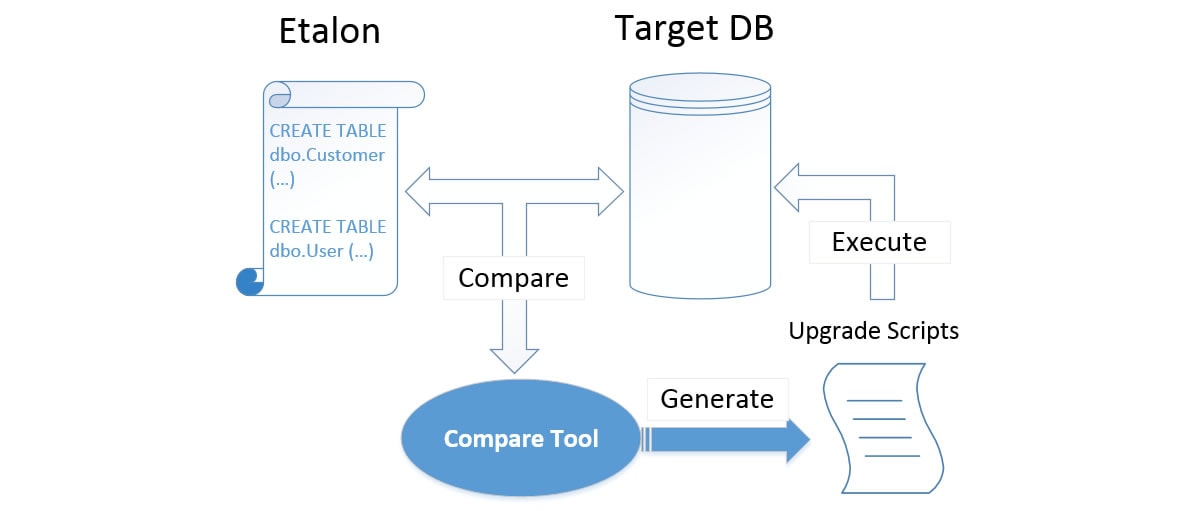
Figure 1 (source: blog post by Vladimir Khorikov)
This approach involves comparing the project model to the target database in order to generate a deployment script. Though the declarative object files (which form the basis of the project model) are capable of capturing the target state of the database in great detail, they don't provide the developer with any semantics to express the intent of a change. This means it is left to the comparison engine to infer what the intent of the developer was and subsequently decide how the transition should be carried out.
The result is that the state-based approach tends to favor additive changes (new tables, new columns, and so on), as well as changes to programmable objects (stored procedures, views, functions), more so than changes that involve data transformation or table refactoring in general. It does support some very basic refactoring, such as the ability to rename or move an object to another schema, but will not recognize the need to split or merge a table or column. Ultimately, the engine behind SSDT is a black box that follows a pre-defined set of rules, so even a seemingly straightforward change, like adding a CHECK constraint to a table, can end up with unintended or confusing results if the transition is misinterpreted by the engine.
If automated deployments are in place (or desired), which is a growing trend as DevOps adoption increases, it's important the scripts that run are accurate and the changes the script makes are exactly what was intended. It just takes one failure without a simple workaround to break the pipeline.
Migrations to the rescue?
A pure migrations-based approach, by contrast, sees the database only in terms of transitions. It takes the view that all database changes need special handling, regardless of whether a table is being transformed or a stored procedure is simply being altered. The result is that any nuances about how the schema needs to be transformed are always captured up-front, making the business of propagating the changes to each target environment a simple matter of playing the migrations back in the pre-defined order.

Figure 2 (source: blog post by Vladimir Khorikov)
Though this approach leads to very predictable and consistent deployment results, making it ideal for automation, it ignores the realities faced by modern day agile development team. Having multiple developers work on the same stored procedure is likely to result in the dreaded 'last one in wins' problem, where code from one developer will overwrite any changes made by another. Also, treating every transition as a special case nullifies the productivity benefits associated with the state-driven method, resulting in valuable time lost to hand-coding mountains of boilerplate T-SQL code.
An alternative solution: the migrations/state hybrid
SQL Change Automation, on the other hand, is a migrations-first hybrid tool that aims to offer the best of both worlds. It takes the predictability and reliability of the migrations-driven method and combines it with the productivity benefits of the state-driven approach offered by SSDT.

Figure 3
Instead of defining every change as a migration, it uses migrations only for objects that require careful handling, such as tables and the data within them, and state-like object files for programmable objects such as stored procedures. Rather than requiring the developer to write repetitive T-SQL code, SQL Change Automation uses the Redgate SQL Compare engine to generate the migration scripts automatically. Unlike the pure state-based method, however, the migrations can be tweaked depending on the unique transformation needs of each change scenario.
How do SSDT and SQL Change Automation compare?
Despite the different approaches taken to managing database changes, there are also some similarities between SSDT and SQL Change Automation. In fact, SQL Change Automation itself is built on top of the SSDT database project system, so at first glance they are somewhat similar: deployment of pending changes is performed by pressing the Start button (or Deploy Solution command), and it supports SQLCMD variables as well as Pre and Post-Deployment scripts. SQL Change Automation even maintains a per-object file structure, called the offline schema model which, from a version control point of view, is very similar to that of the SSDT project structure, as shown in Figure 4:
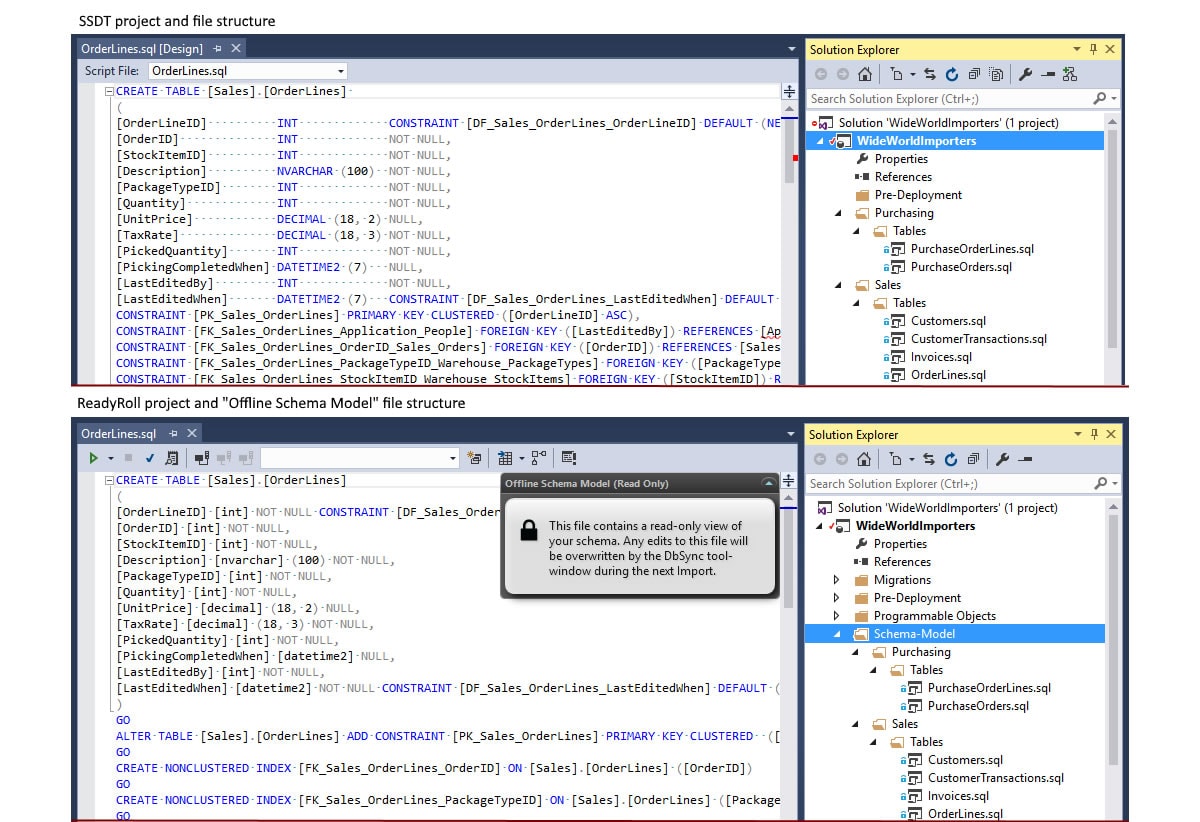
Figure 4
Where the styles of the two tools diverge, however, is when you begin authoring a change. Figure 5 shows how the development workflows of SSDT and SQL Change Automation differ:
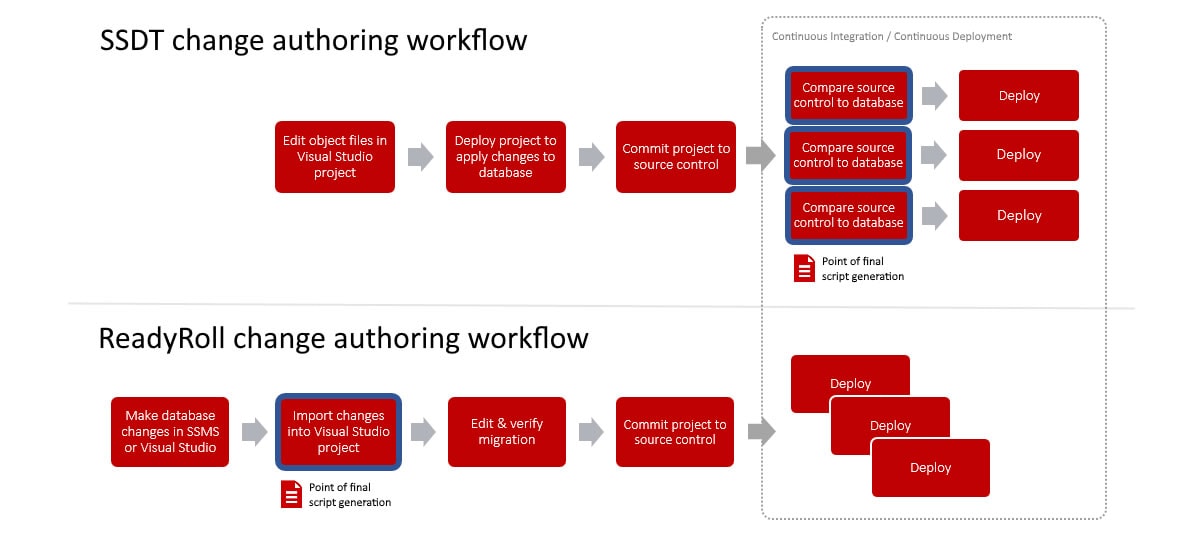
Figure 5
Notice how the point of final script generation is different. This is because SQL Change Automation pulls forward the creation of scripts to the point where the change was actually made by the developer, rather than leaving it to the last stage of the development lifecycle, where editing of the generated script isn't an option.
It does this by enabling the developer to make the changes directly to their private database environment (e.g. using SSMS query editor or the SQL Server Object Explorer in Visual Studio). This connected style of editing, which according to a recent Microsoft poll is the most popular way of developing for SQL Server, allows the developer to experiment with and test different changes to both schema and static data, and revert changes back as needed. When the developer imports the changes, a migration is generated by SQL Change Automation's schema and data comparison engine and assigned the next number in the sequence, along with a customizable suffix containing the date/time and username of the developer (e.g. 002_20160913-1304_smithj.sql).
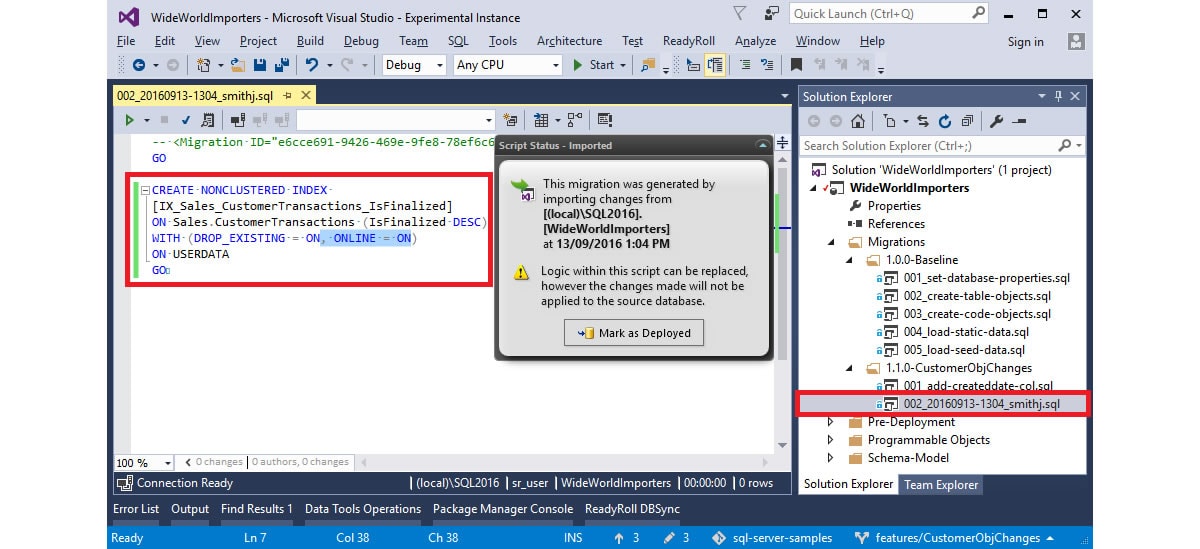
Figure 6
If SQL Change Automation's scripting engine doesn't get the migration quite right, customizations can then be made to the script contents and/or ordering of changes prior to verifying the migration. In Figure 6, the developer has made a change to an index using SSMS, imported the change and then edited the migration to add the ONLINE=ON clause to the CREATE INDEX statement.
To ensure the deployment order is preserved across concurrent streams of work, such as when branching and merging in version control, collections of related migrations can be organized within semantically versioned folders.
Once the migration is checked into version control, further edits should not be made to the migration; if a change to the schema is required, another migration should be authored. However, the trade-off with this enforced immutability is that it enables SQL Change Automation to provide your team with predictable and repeatable deployments to your database environments directly from version control.
Conclusion
In this article, we've looked at the strengths and weaknesses of the purely state-based deployment approach of SSDT. We also examined how the migrations-first database deployment approach of SQL Change Automation compares, including how it makes it easier to automate parts of your database deployment process with greater predictability and control over what is being deployed.
If you like the sound of this approach, check out my companion article over on Simple Talk, which covers 10 common SSDT database deployment snags , some problems you might encounter when tackling them using the tools available in SSDT, and alternate solutions with or without Redgate SQL Change Automation.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Product article
Why Digital Operational Resilience Act (DORA) Compliance Requires Auditable Database Change Management

Product article
Monitor for Overprovisioned SQL Server Cores to Cut Licensing and Cloud Costs

Product article
Loading comments...