





Managing your server estate – can we help?
Here in the Redgate Foundry, we’ve been conducting research to understand ways to help data professionals manage their server estates more effectively.
Our aim is to support you in providing a single source of truth about what is happening in your estate, provide a foundation for you to build and plan from, and empower you to be more proactive vs reactive in delivering the best service possible to your customers.
Why is this a problem?
From our conversations, we’ve learned that despite best efforts every estate reaches a point where it’s difficult for people to keep a grip on the ever-shifting landscape and complexities of day-to-day work. This eventually forces data professionals into a reactive, rather than proactive approach to estate management.
The good news is that we think proactive estate management is possible by having a clear solution for each of the following 4 points:
- Understanding what is there across the estate
- Defining how things should be
- Identifying and understanding why things have changed, before issues become problems
- Ensuring everyone involved is aware and informed of the above
Understanding what’s there
We’ve learned that as an estate grows it becomes difficult to keep track of exactly how everything is configured and how the moving parts all relate to each other. This is amplified when people sidestep process and deploy their own instances to test things without approval. These instances can sometimes be misconfigured, and the DBA team only gets notified once something is on fire as a result.
Perhaps you’ve recently been promoted, or moved to a new business. It might seem like the environment you’ve inherited resembles a labyrinth you need to get to grips with before helping drive your business forward.
Perhaps your global business estate is a mismatch of legacy environments, autonomous teams and multiple database engines. Without having a clear picture it’s impossible to get that foundational understanding nailed down to effectively manage the spinning plates and progress further.
Defining how things should be
We’ve learned that despite best efforts to put in place best practices, this is also a really difficult task to keep track of. It requires effort to document things effectively, store them so they’re easily accessible, and even to know what ‘Best Practice’ is for your particular business needs.
How many times has someone in your team deployed a server to the best of their ability, only for a missed setting to cause problems down the line? Tracing back an issue to a configuration setting is a time-consuming task, relying on the experience and instincts of the DBA in charge to hopefully remember to check.
Are most of your servers set up using default settings applied through a Next > Next > Next installation process? Are the defaults really optimized to ensure your server performs at its best to meet your customer’s needs? If there are any specific settings for particular niche requirements how and where do you log these and ensure the right settings are applied to the right servers for the right people?
Beyond the server settings themselves, how do you track any surrounding information about why a server is set up in certain ways? What role does the server play in the wider business?
Metadata and additional context provide richer insights into why things should be configured in a certain fashion. Unfortunately, this information is often lurking in someone’s head, buried in a long email chain from weeks ago, or logged in a deep dark corner of a spreadsheet somewhere. Finding this information is time-consuming and difficult, especially when under pressure.
Identifying and understanding why things have changed
One of the key blockers to effective estate management is the ability to effectively and proactively notice that something has changed. Of course, your monitoring solution will send an alert to tell you there’s a problem that needs to be fixed, but this is still a reactive solution to a problem in the ‘now’. A problem that is already impacting your server’s performance and negatively impacting your or your customers business effectiveness.
It’s extremely difficult to proactively notice that things are changing and tackle the root cause before it gets to the stage that you need to start putting out fires. After all, if it hasn’t caused a problem yet, why would your monitoring solution tell you?
It could be that the changes that have been made are valid. It could be that they might be catastrophic. Without the awareness and control, how would you ever know until it’s too late?
A lot of our research has told us you would like to replace the amount of time firefighting with ensuring your teams and estates are supporting bigger business initiatives. Unfortunately, you’re held back by the constant need to react. This is where we feel the line between managing and monitoring lies, and is the core reason for us conducting this research.
Ensuring everyone involved is aware and informed
As mentioned above, perhaps someone has changed an element of configuration with good intentions and valid reasons, but how can an outsider ever know? How is your decision making tracked?
We’ve heard stories about globally distributed teams playing ‘config tennis’. One department makes a change to fit their requirements, which is then picked up by another team in a different time zone who change it back because they’re unaware of why it was changed in the first place. When the original team logs on again the next morning they change it once again, and so it continues …
Sure, someone might have sent an email or dropped a message in Slack explaining why the change was made, but those support tickets won’t clear themselves. Perhaps the message has got missed in the blizzard of information sources we all deal with each day.
Perhaps you have a junior new to your team and you want them to hit the ground running, but those important business meetings in your calendar take priority. Faced with an overwhelming amount of new information, how is your junior going to know where to start, and what to do?
Effective up-to-date documentation is really useful, but it’s also a huge overhead and it’s not often that businesses are able to dedicate resources to it. The simple truth is that the day-to-day work takes priority and slowly but surely the quality of the documentation erodes. At some point, either no one knows where it is, or even if they do, it’s well past its sell-by date. This means the same issues have to be diagnosed afresh over and over. It means that config tennis makes decisions hard to track, and perhaps worst of all, it means that if a vital member of your team moves on, all their knowledge is lost with them.
What we’re doing about it
We’ve got lots of ideas about potential paths to help support you with these aspects of managing your estate, as the following screenshots demonstrate:
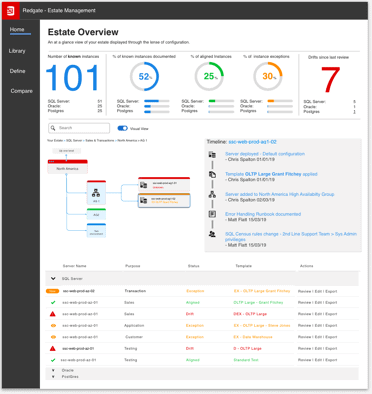
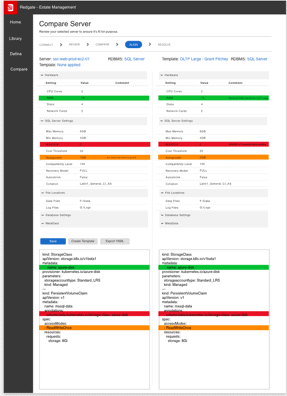
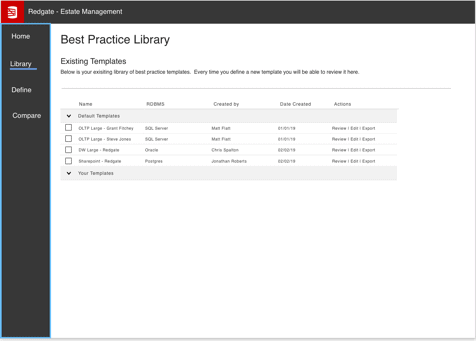
In order to kick off the foundations, we’re looking into ways to help you easily connect to and review your server settings, add metadata for important additional context, define how your servers should be, and annotate all of this with commentary.
We then aim to show when servers are drifting from their intended configuration, enabling you to step in and ensure you align settings and other aspects before they become problems.

We’re working on the first slice of this, will be launching our prototype soon and would love to work closely with Data Professionals out there who are facing some of the challenges outlined above.
Working together with our customers will ensure we’re able to progress Estate Management in a meaningful and valuable way, and we’d love to hear your thoughts on how we can help.
If any of the topics covered above have resonated with you, please head over to our sign up page to express interest and get in touch using the form provided.
You may also like

Blog
Redgate Flyway’s Product Updates – March 2026

Blog