





Database unit testing, are we all doing it wrong?
This week at Redgate HQ we've been lucky enough to have a visit from Dave Farley, Continuous Delivery evangelist and co-author of the book Continuous Delivery.
In one of our discussions we started talking about database unit testing. Pretty soon we realized we both meant something fundamentally different when we called something a database unit test. Have I been doing it wrong all these years?
I’ve historically used database unit tests to test small units of business logic in my database. Every time the database is changed I run this whole suite of unit tests, and am confident that my business logic works as expected. This approach is analogous to the type of unit test I write when developing application code. For example I might have a test that checks that a ‘get_user’ stored procedure returns the data I expect from the Users table.
Typically I write these tests using the tSQLt framework, which makes it easy to write self-contained tests that include their own data.
Dave Farley has taken a different unit testing approach, which focuses on testing the change you're making rather than testing the state you end up in. This type of 'migration test', as we started to refer to them as, can complement the 'business logic test' approach by testing the changes you make to objects that contain persisted data, e.g. tables. This is a pretty powerful approach, as it lets us test the data migration logic as well as the schema change.
The aim of both types of test is the same though. We're trying to prove with our tests that the code we have written has the effect we expect it to. If it doesn't our tests will fail and we can re-think our approach.
Here's an example scenario. Say I'm splitting a column in a table, in this example I'll split a 'name' column in my Users table into new 'first_name' and 'second_name' columns. To keep my data migration example simple let's assume that splitting on the first space is sufficient to separate out the names.
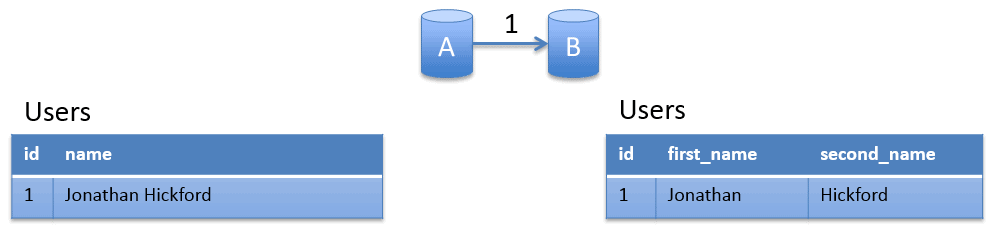
The image shows the change I want to make. On the left is my current schema and data, and on the right is what I want to end up with.
Let's follow the Test Driven Development (TDD) philosophy and write the test first.
NB - I'm borrowing the tSQLt syntax here, but this example is pseudo code. This isn't a valid stored procedure as I'm referring to columns that don't yet exist in my database. More on how to make this actually run in tSQLt later.
-- TEST 001-Split_name.sql
EXEC tSQLt.FakeTable 'dbo.Users'
INSERT into Users (id, name) values (1, 'Jonathan Hickford')
-- %% RUN MIGRATION SCRIPT 001-Split_name.sql %%
EXEC tSQLt.AssertEqual 'Jonathan', SELECT first_name from Users where id = 1
EXEC tSQLt.AssertEqual 'Hickford', SELECT second_name from Users where id = 1
EXEC tSQLt.AssertEqual 0, SELECT COUNT (*) FROM sys.columns WHERE
object_id = OBJECT_ID(N'[dbo].[Users]') AND name = 'name'
I'm mocking up, then inserting some test data into my existing Users table. Then there's a comment where I want to run my migration script. Finally there are assertions that check that the correct data is in the new locations I'm expecting and my old column has been removed.
As expected if I try and run this it will fail. Time to write my migration to try and make this test pass.
-- MIGRATION 001-Split_name.sql
ALTER TABLE Users ADD first_name NVARCHAR(50);
ALTER TABLE Users ADD second_name NVARCHAR(50);
UPDATE Users SET first_name = SUBSTRING(name, 0, CHARINDEX(' ', name));
UPDATE Users SET second_name = SUBSTRING(name, CHARINDEX(' ', name) + 1, LEN(name));
ALTER TABLE Users DROP COLUMN name;
Here I add the new columns, update the new columns with data based on the existing name, then remove the name column.
If I run my test now (and it magically substituted and ran my migration script in the middle of it) it should now pass.
Given the test passes you can then run the migration script on your local database safe in the knowledge your data won't get messed up if the script wasn't right first time.
Of course in a more realistic example you'd want to test a range of potential names "Jonathan Hickford Jr.", "Jonathan Hickford-Moore", "Jonathan Graham Hickford", "Mr Jonathan Hickford" etc. Here your test would pull out many of the problems that my over simplistic migration script will trip over!
To actually make this run in tSQLt I manually I wrapped the contents of my migration script with EXECUTE sp_executeSQL along with my block of assertions (and remembered to escape the quotes). This meant that my test was a valid stored procedure and could be saved to the database to run. I've uploaded an example similar to this on GitHub.
This testing approach has an interesting impact on how I source control my database changes, and how I apply these changes to upstream environments like the test environment. Previously I'd have deployed the latest version to my test database, then run all the unit tests to test the business logic in the latest state. That process I've have set up using a Continuous Integration server, so that it was triggered automatically when I commit the changes to a repository.
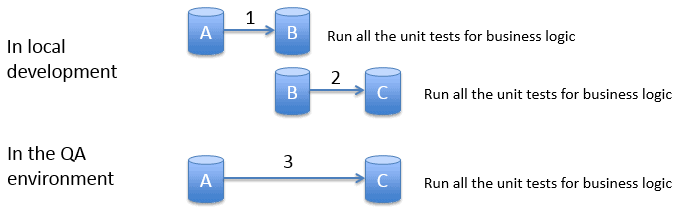
The images show my existing strategy for deploying changes and running business logic unit tests.
However for my migration tests I need a slightly different approach. In contrast to my business logic tests I only ever want to run these tests once when my database is at this specific revision. I need to walk my database through each migration sequentially, running just the single corresponding migration test each time before I run the migration itself.
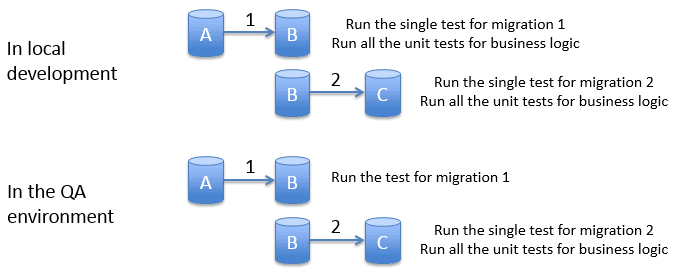
The images show the required strategy to run both business logic and migration unit tests.
In conclusion I think migrations tests are a powerful method to improve the test coverage of our database and the changes we make to it.
So is this migrations test a unit test, or something else? I think strictly speaking it is a form of unit test. It checks that the unit of code I've written works as expected. The unit in this case is the migration, not a stored procedure or function. However, I find it helpful to call this a migration test. It makes it clear that it's approach is different to a traditional application unit test.
Was I doing it wrong before? Perhaps I was, there were certainly a number of changes that I was making to tables and data that did not have an effective test. I like the way this approach lets me test the data migration, as well as the business logic. After all, data migrations are probably where I go wrong the most.
Let me know what you think in the comments below?
You may also like

Blog
Query Plan Compare for PostgreSQL in Redgate Monitor

Blog
SQL Prompt Product Updates – April 2026

Blog
Loading comments...