The Essential Tools for Standardizing SQL Server Database Development
To achieve rapid delivery of database functionality, database development must both support craftsmanship and incorporate the ideas of standardization and automation that allow for 'mass production'. This article explains how to achieve this 'balance' using the specialist database development tools in SQL Toolbelt Essentials. These tools allow database experts to work quickly and accurately, with structured and repeatable processes to ensure all required checks and coding standards are applied before delivery.
For many years, the companies that provided relational database systems also provided the software tools to use them. They imagined that the ideal tool would be an all-encompassing IDE that could accommodate all the needs of database developers. Although tools such as SQL Server Management Studio or Oracle Developer Studio work well for some purposes, there are times in the development cycle when more specialized tools are required. The database industry is now less inclined to stick with just one database provider, or even one type of database.
As such, software tools for databases have to support a wide and diverse range of settings for database servers, and a much broader usage of relational databases. Nowadays, we are more inclined to acknowledge that individual developers will want to use tools that support their particular preferred way of working. A standard IDE is fine but should be supplemented with tools that support the development task at hand and that will help standardize and scale those tasks across teams.
Make routine database development tasks easier and more repeatable
When you are developing a SQL Server database using DevOps principles, you need to ensure that the team members can use their specialist knowledge to influence the design of the database as early as possible in development, so that it is then easy to manage in a production setting. A security expert, for example, will be able to give more effective advice before the design of the access system is firmed up. An Ops specialist will want to give early input on the most effective alerting system. This means that development must be visible and adaptable, allowing all the architectural decisions to be well advised and made quickly.
To do this, the team will need a structured workflow for anything that requires decisions or judgement and make the creative aspects of the work as easy as possible for the developers.
Specialized database development tools
The most obvious way of removing time-wasting, but essential, tasks is to use specialized tools for certain aspects of database development. Creating test datasets is an obvious example, but formatting SQL scripts to the team style, creating and sharing code snippets, running unit tests, applying documentation to the database and performing code reviews are other obvious candidates for a specialized tool.
Redgate’s SQL Toolbelt Essentials provides tools to help simplify all of these tasks, and to standardize the way they are applied across teams. Of course, automation is a necessary part of standardization. After all, you can only have standardization if you can guarantee your standards are always applied and you can only do that if it’s automated.
Although this article is about the tools in Redgate’s SQL Toolbelt Essentials, I use plenty of tools from other vendors too, because I use a number of different relational and ‘document’ databases, and I rely on several general programming tools as well for scripting. I’m typical of a developer in that I also use GREP tools, programmers’ text editors, tools for creating and editing regexes, and for storing large numbers of code snippets.
Automating development tasks
Many development tasks can easily be automated, usually via PowerShell, Bash or Python. The initial tasks will probably be those that style the code in a standard format, run unit tests, regression tests and code quality checks, generate reports and so on. We need to ensure that these tasks run automatically at the appropriate point in the workflow, such as before a pull request is approved, or after a new version of the database is built.
The more sophisticated processes will require workflow systems that ensure that team members are alerted to do routine checks such as signoff, code reviews, bug-tracking, performance checks, approvals that are necessary for many commercial development processes.
By automating those repetitive development tasks that need little human intervention, the developers remain focused on delivering features, but we also ensure that the existing processes continue to function properly, and code quality remains high, as a result of the changes made to introduce each new feature. The goal is to streamline the database development process, reduce errors, and to ensure the database is reliable and secure.
The Essential Database Developer’s toolkit
Let’s consider those tasks that a database development team must perform that are ripe for attention, and how we can use the tools and automation in SQL Toolbelt Essentials to make them faster, and less effort.
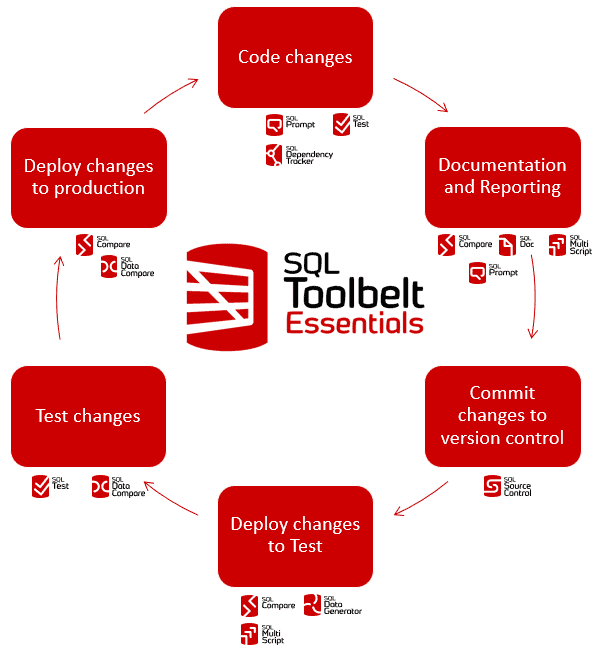
Accelerating and standardizing code changes
The development of databases has always required a variety of tools. While much of the work of database development can be done directly in DDL code, from the IDE, other tools are required as well, especially when doing the database design work for a new application. For example, ER Diagramming tools are useful here because the design diagrams can be communicated easily in discussion with the end-users and business analysts. The DDL code to build the database can then be ‘cut’ from the ER model. The use of design tools such as this emphasizes the importance of database relationships, dependencies and constraints.
SQL Toolbelt Essential provides several tools designed to improve the speed with which the team write SQL code, as well as the quality of that code, all of which work directly from your IDE, SQL Server Management Studio (SSMS):
- SQL Prompt is an IntelliSense and autocompletion tool for writing SQL, and also has useful features for automatic code formatting, static code analysis, and building shared code libraries. See, for example, How SQL Prompt Improves SQL Server Database Development
- SQL Dependency tracker – generates database dependency diagrams that will show you which objects reference an object you’re about to alter, and those it references, including foreign key references, column references and all the other details you need. It installs into SSMS but is also available as a standalone tool.
- SQL Test – an SSMS plugin that that helps you create and run unit tests, as well as other types of database tests, using the open source tSQLt testing framework
Auto Code completion and IntelliSense
For conventional database work in an IDE such as SQL Server Management Studio, SQL Prompt‘s IntelliSense and code completion features improve in many ways on what’s available natively in SSMS (see SQL IntelliSense and Autocomplete in SSMS for a comparison).
They will help teams write the required SQL code quickly and with more accuracy, providing auto-completion suggestions for the columns and tables you need to access, complex JOIN conditions, aggregations and so on. It will also qualify an object to its owner, assign aliases to tables and views, and qualify columns with the correct alias.
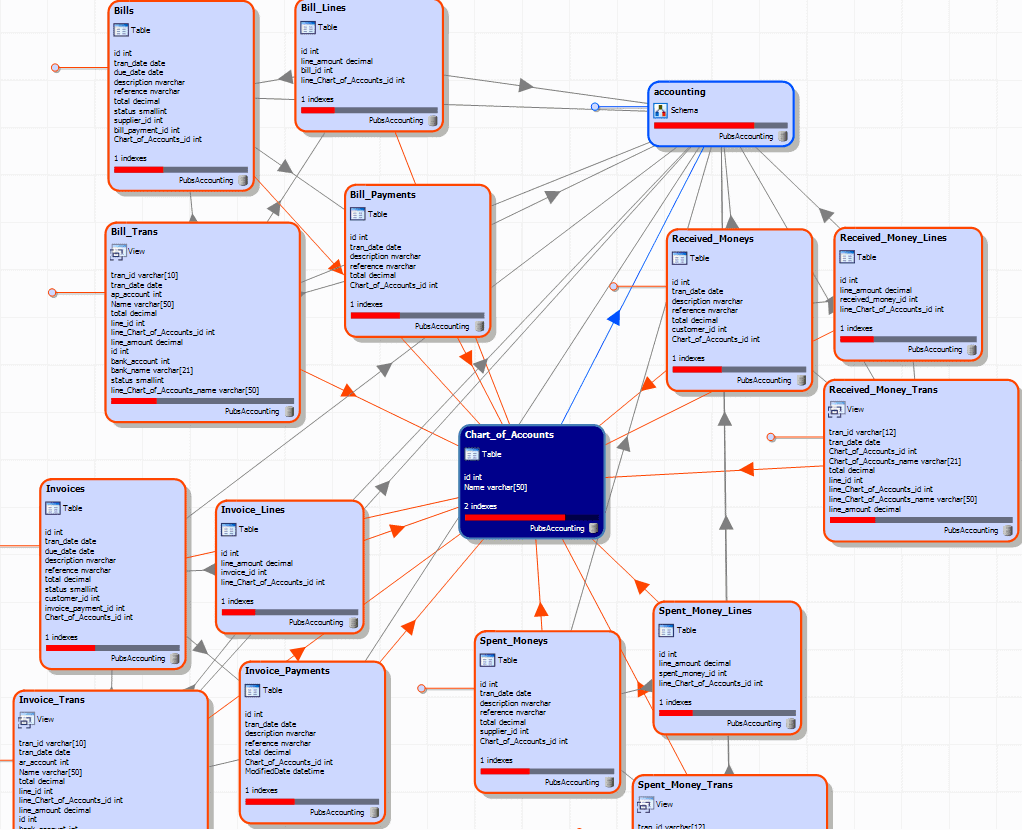
Investigating and identifying relationships and dependencies
SQL Dependency Tracker identifies the relationships between database objects, such as tables, views, stored procedures, functions, and triggers allows the developer to analyze SQL Server databases displays them in an interactive dependency diagram. These diagrams can be committed to source control, alongside the DDL scripts. As well as being a way of documenting a database and will help developers and administrators to understand the impact of database changes.
Bulk code formatting and code analysis
To work effectively, teams should ensure that their work is easy to understand. It should not use strange code formatting, and it should be documented sufficiently that every participant, not just developers, can understand it, maintain it, and if necessary, fix the mistakes. This must be easy to do, and easy to check. The same applies to the code itself, in that it should be as free as possible from ‘code smells’ that might cause trouble in production or result in performance problems.
SQL Prompt comes with built-in styles and automatic code formatting, so you can define and implement a standard SQL style across the team, but developers still have the freedom to apply different styles, locally, for different uses. You can use CLI-based code formatting to automate this task for legacy databases.
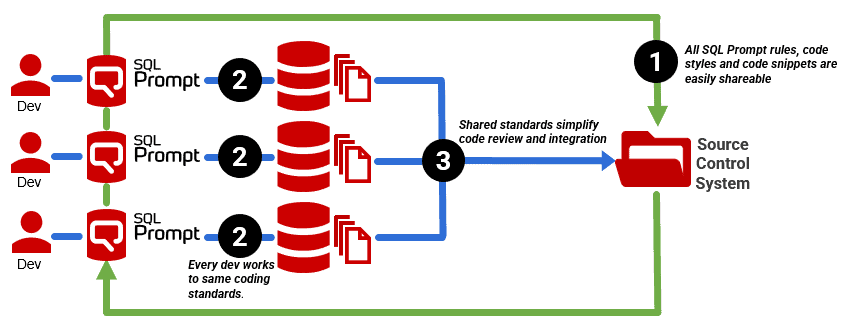
You can also perform static code analysis to help detect and remove database ‘code smells’ in the SQL codebase. These are mistakes, omissions, and vulnerabilities that make the code harder to change, can lead to unpredictable behaviour and performance and will increase maintenance costs. They are one measure of the extent of the technical debt inherent in code.
SQL Prompt helps the team both prevent technical debt, by performing the code checks during code development, and measure existing debt by running the checks on a complete build or ‘baseline’ script for any database version. You can also automatically deliver SQL Server code quality reports using the command line tool.

Shared code libraries
Shared code libraries, if well managed, are useful team resources. Obvious candidates for inclusion in this library are the many different SQL CREATE statements and also the more complex DML that few people keep inside their heads, such as Window functions.
Teams will soon accumulate other useful shared utilities, such as JSON import and export routines, or batch scripts for bulk data import, as well as admin code for checking on performance, blocking and a range of DMVs and Backup/Restore routines.
SQL Prompt’s shared code snippets can provide this help, at least for reasonably small libraries. I find I rely on these code libraries for cross-RDBMS work because there is too much information to keep in your head.
Unit and Integration testing
I’d argue that unit testing is such an inseparable part of database development that it is unavoidable. The experienced developer will want to work out how to test routines before building them and so the unit test harness is part of the development script. However, there is plenty that can be done with a suitable tool, such as SQL Test. See, for example, Testing SQL Server Databases Using SQL Test.
Where a more complex process is being subjected to an integration test, then this too is ripe for automation. Here again, the integration test needs to grow alongside the database process that it is testing, but when the work is complete, it can be run routinely to ensure that other work hasn’t broken the process.
Documentation and reporting for database changes
DevOps teams work best if it is easy for all the members of the team to keep in touch with all aspects of development. This way, they can make suggestions that can help avoid or resolve potential problems. This required accurate database documentation, with wide coverage. It also requires detailed reporting to track progress of the project, report on changes, and track bugs to ensure that nothing falls between the cracks.
Documenting changes
Every database object should be documented. Even if a change seems unimportant, the team need to know that it is unimportant as well as what it does.
I suggest following the industry standard of documenting every object, column, parameter and return. Documentation is best done in a build script where this is the primary ‘source of truth’, but it should be in the live database, either as a comment or, in SQL Server, as an extended property. When using a migration system, these properties can be kept and maintained separately (I keep a JSON document as a primary source, extracted where possible from the migration scripts). This can be used to ensure that the comments are kept with the objects in the database and that nothing gets lost.
While there are many approaches to team coordination and communication, my preferred approach is to maintain a local website, and update the documentation that is displayed on it on every commit. This documentation is taken from several sources including the version control system and the current version of the development database.
Documentation is one of the many database development functions that can never be fully automated, and the neglect of documentation has an insidious effect of gradually slowing the delivery of new functionality. SQL Doc is valuable to use as a UI tool so that you can add initial documentation to the tables and columns, as well as to the parameters and return-values of functions. The answer to the question ‘why has this change happened?’ has to be there too, as well as who did it and when. If you fail to document it at the time, the question may be impossible to answer when memory fades and team membership changes.
For maintaining documentation, SQL Doc has a command-line interface that will allow several databases to be documented in a number of different formats, and this process can be entirely automated.
Reporting on changes
You are mostly reporting for the benefit of the team, to make it quicker and simpler for them to check what is happening. This is likely to include at least …
- Change Request report: This reports the changes that are requested by stakeholders or users, the nature of the change, its priority, and any related tasks or dependencies.
- Status report: This report tracks progress in terms of completing development tasks and meeting project milestones. It includes information on completed tasks, tasks in progress, and tasks that are yet to be started.
- Change report: An object-level breakdown of changes made by a deployment. SQL Compare can produce these reports, either to review the effect of pending changes, or as an historical record of change for auditing, or when bug tracking.
- Code quality report: Information on the quality of the database code. As produced by SQL Prompt, they indicate code issues that may cause unpredictable behavior as well as security, performance and maintenance issues.
- Data quality report: Provides information on the quality of the data stored in the database system. It includes metrics such as data completeness, accuracy, and consistency, and can help identify areas where data needs to be cleaned or improved.
- Performance report: obtained from both the performance tests and the live production database. It provides metrics on such things as response time, query execution time, and database usage. It can help identify performance bottlenecks and areas for optimization.
- Bug report: describes any bugs, concerns or issues that have been identified in the database system during testing or development, their severity and any suggested fixes or workarounds. It tracks progress in fixing each problem. Bug and issue reporting is especially important when integrating and releasing rapidly. It helps collaboration and accountability, allows the team to measure quality as well as manage priorities and more easily determine what development practices are best for the team and the development task.
SQL Multiscript is a useful general purpose reporting tool when you need to capture the same reports on a number of databases. It will run whatever script or scripts you select, on a list of databases, and collate all the results neatly. For example, you can capture a performance report from all databases on a distribution list of servers.
Version Control and Change tracking
The developer will know the point at which a change needs to be in source control. Although it is currently considered that the commit is a suitable point for initiating a pipeline that adds the code to the development database, I’d be wary of the idea. It is actually a successful test that should initiate it, because there seems little point in committing work that might then fail basic tests.
It is unlikely for developers to wish to leave their work to use a separate interface to commit the changes to source control, or to apply a change script to the development database. A tool such as SQL Source Control is useful in this regard since it allows developers to commit changes directly from SSMS, as well as to be notified of changes committed by other developers on the project. It will automatically detect changes to individual database objects, in your development database, and update the corresponding object-level scripts in the version control system. This makes it very simple to track which objects changed, and how, through successive versions of the database. It will also generate the migration script that will apply the changes. Alternatively, you could set up a similar source control mechanism, albeit without direct integration into SSMS, using SQL Compare.
Where source control ceases to become routine, is when ‘diffing’ changes in a visual user interface, or in tracking the progress of complex branching. This task can’t be automated, but there are plenty of other routine tasks in managing source control that can be automated.
Testing databases
The main goal of testing, at this stage, is to prove that, in the potential release candidate, all the individual units of code always function as expected, that all the required units work together properly to implement the supported business processes, and that the database performs to specifications. These tests should be automated, as far as is possible, so that the team can perform them continuously throughout development. This will quickly pick up the slightest change that introduces an error, so makes debugging much quicker. The screaming commences soon after the offending code is committed.
Deploy changes to Test
There was a time where the time taken for testing ballooned out of control. One project I did took nine months to test. However, by running many tests in parallel within a test cell on many database servers, this time can be reduced to minutes.
Imagine it. You have a run of regression tests that take time, so your team wants to run them in parallel, on a number of identical copies of the database. Of course, every copy of the database must be the same version and have the same test dataset. At the moment, they are not so the test servers have to be provisioned to make them so. Do you leap out of bed with a spring in your step, knowing that you’ll be contentedly provisioning test databases for a few hours? No, me neither. Besides, it has to be done now and quickly. This is the perfect subject for an automated process.
The usual approach to this task is “build and fill”. We can use SQL Compare to maintain a build script for each new version of the database that we need to test, and SQL Data Generator for generating ‘fake but realistic’ development and test data sets. We then simply run the required build script and fill it with the required test data, ready for the test runs. See, for example, Build-and-fill multiple development databases using PowerShell and SQL Data Generator. As you refactor the schema and development data, you can use SQL Compare and SQL Data Compare to script out the changes.
The alternative to the “build and fill” approach is simply to run a migration script on each of the test databases, to take it to the new version. You could use SQL Multiscript for this. However, you’d then need some way to verify that both the schema and the data were in exactly the state required for testing. Once way to do this is to ensure this is to ‘version’ both the scripts and the databases (see The Database Development Stage).
Running regression and performance tests
Many of the tests run to verify a new version will be regression tests, which we run to identify any issues or defects that may have been accidentally introduced to any part of the database system as a result of changes or updates we made to the system.
It is one of the immutable laws of development that you will always find a bug in that part of a database system that seemed hardly worth testing because “there couldn’t possibly be a bug there”. Experience tells us that bugs emerge in all sorts of places, like field mushrooms.
This is why regression tests are worth repeating on every release. The most innocent-looking change, such as a database setting, can have far-reaching implications in a database. A regression test involves re-running all the database processes that are idempotent, in that the final state of the data after a process has run is always the same for a given dataset. The tests might incorporate SQL Data Compare checks to verify that the final result after running the test case is exactly as expected.
The testing process typically involves maintaining a test suite, which would include your SQL Test suite of tests, that expands alongside the database to cover as many processes and uses as possible include a variety of test cases designed to test the functionality of the database system under different conditions.
Performance tests differ in that they apply different data sets of increasing size to make sure that the database scales in performance appropriately, rather than measure accuracy. You can, of course, do both at the same time. If, reading this, you are already feeling drowsy, you need to check that you’ve automated this to the point where it is no longer a chore.
Deploying database changes
When using SQL Toolbelt Essentials, we can run ‘state-based’ deployments by using SQL Compare. It will compare the schema of a source and target database and generate a synchronization script to update the target database, making its schema the same as the source. It will preserve the existing data wherever possible and issue a warning if it’s not. It will also generate a range of other types of scripts and build artifacts (such as snapshots) that can be useful in preparing for and testing deployments.
Developers need to ‘flag’ those schema changes that might affect existing data in unpredictable ways, as early in development as possible, as it may be necessary to use pre- and post-deployment scripts to successfully preserve all data. This process needs to be tested thoroughly before deploying to production.
Instead of running state-based deployments, you might prefer a migration approach using a tool such as Flyway. In that case, you can use SQL Compare to generate a first-cut Flyway migration script, as demonstrated in Creating Flyway Migration Files using Redgate Schema Comparison Tools.
Summary
In order to achieve the rapid delivery of database functionality in response to demand, database development has had to transition from the age of the craftsman to the ideals of mass-production. One common, and growing, feature in DevOps practice, therefore, is in supplementing the use of a general-purpose IDE with additional, specialist tools.
SQL Toolbelt Essentials provides this special-purpose toolkit for standardizing SQL Server development. It will provide the foundations for DevOps automation and embed the team processes required for it to be sustainable. It includes tools like SQL Prompt that will increase SQL coding productivity and help the team produce code that is readable, consistently formatted, and SQL Doc to ensure that it is well-documented. This makes the code much easier to share and review, including by those whose job it will be to deploy those changes. Other tools, like SQL Source control and SQL Compare, will remove the chore of tracking all of the development changes, devising scripts to deploy them, and reporting on them, making those changes much more visible to other roles and teams within the organization.
Each tool has a narrow focus, but they are easily strung together to construct a workflow, using a CLI-based interface. In this way, we give the experts all the tools and information they need to work quickly on the project deliverables, while the database development process as a whole becomes more repeatable, reliable and efficient.
Tools in this post
SQL Toolbelt Essentials
10 simple tools for fast, reliable and consistent SQL Server development.
You may also like
-

Webinar
Six ways to unlock efficiency in your SQL Server database development featuring SQL Prompt and more
According to a recent IDC report, by 2026, more than 90% of organizations worldwide will feel the pain of the IT skills crisis, amounting to some $5.5 trillion in losses caused by product delays, impaired competitiveness, and loss of business. Consequently, teams are grappling with heavier workloads and experiencing decreased satisfaction among both customers and
-

Article
A Fresh Look at the NHS Autumn Budget: Opportunities for IT Teams
Over £2 billion has been earmarked for the IT modernisation of the NHS. Let's explore some of what this means for IT teams and how Redgate can help.
-

Article
Searching for Objects in SQL Server Databases
How to get the most out of SQL Search, a free database search tool for SQL Server Management Studio (SSMS) and Visual Studio that will locate database objects based on their names, columns, or text.
-
Article
Start the year strong: make SQL Server development faster, more reliable, and more consistent
As the new year begins, development teams are looking to build momentum, set clear goals, and establish reliable, scalable processes that will help them deliver value consistently throughout 2026. That’s why many teams are turning to SQL Toolbelt Essentials: a powerful, easy-to-adopt toolkit that helps teams speed up database development, reduce risk, and standardize workflows.
-

Article
Finding Dependencies in SQL Server Databases using SQL Dependency Tracker
Before you alter a database object, you need to understand what other objects will be affected. This article shows how to generate a simple dependency diagram that reveals both those objects that reference the target object, and those referenced by it, and includes foreign key references, column references and all the other details you need.
-

Article
SQL Prompt Product Updates – January 2026
SQL Prompt’s January release brings support for Microsoft Fabric and an exciting new preview feature. Microsoft Fabric support SQL Prompt v11.3.2 now supports Microsoft Fabric, extending autocomplete suggestions and formatting rules to Fabric-specific queries. This includes support for key Fabric Data Warehouse statements such as COPY INTO, OPENROWSET BULK, CTAS (Create Table As Select), and





