





Retrospective Database Source Control with SQL Compare
You have tripped over a database, somewhere in the IT department, that is either not in source control, or not completely in source control. What do you do?
The database may be in the middle of development, but it may even be in production. What I mean by 'not completely' is that you cannot easily trace the creation and alteration of individual objects, such as procedures or functions, because, if anything, maybe only the full build script has been put into source control.
There is nothing particularly wrong with using build scripts that incorporate several database objects: schema-based development, for example, is quite common. I'm a bit 'beard and sandals' about building a database. I don't often work away at individual database objects such as tables or procedures. When I need to develop a tangle of inter-related tables, for example, I'll use all the help I can get, including diagramming tools and design tools. I'm quite happy to develop via migration scripts. I'll also do schema-based team development on a shared development server. I know, I know, you may need a steady nerve to read this.
Whichever way one develops a database, it is wise to maintain source control at the object level because, if you are developing code for a team within an organisation, it is easily auditable: there is a record of who did what and when. It allows you the maximum flexibility in the way you work. It helps even if you are the only developer in a start-up.
This article will explain how, among this apparent chaos of development methods, you can use SQL Compare to maintain object-level source control.
Create the local Github repo
For this demonstration, I'm using Github. It should be a paid account because otherwise, when you push to origin, you can only use a public repo. First, create a new local repository, using the Github client.
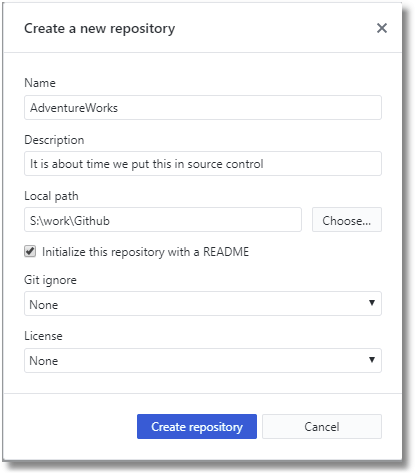
This will create the AdventureWorks directory, the local repository, as a subdirectory of the path that we specified. In it, we put the bare minimum of the documents we need, including filling in the details of what we are doing in the markdown file called README.md. This is a text file describing the repository that you add to the repo. It uses the markdown notation to signify such typographic things as bold, italic, headings and bullets.
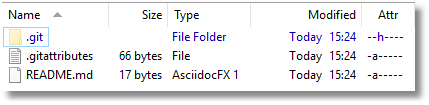
In this local repository, we'll create a directory called SQL, within which we'll generate a set of object-level build scripts, in a series of sub-directories, one for each type of object. This collection of scripts, combined, will build the database. It is best to keep the build scripts in a separate directory from all the other clutter associated with your database, such as migration scripts, SSIS projects, unit tests, PowerShell scripts, config scripts and agent scripts.
Generating the object-level build scripts using SQL Compare
Open SQL Compare and create a new project. The Source will be the rogue database we found, and the Target will be a Scripts folder, namely the SQL directory in our local repo. The initial comparison will convince SQL Compare that the database has all the objects, and the scripts folder has none. When you've entered everything satisfactorily, you can then hit the 'Compare Now' button. You can see Feodor Georgiev's article for a few more details about this process.
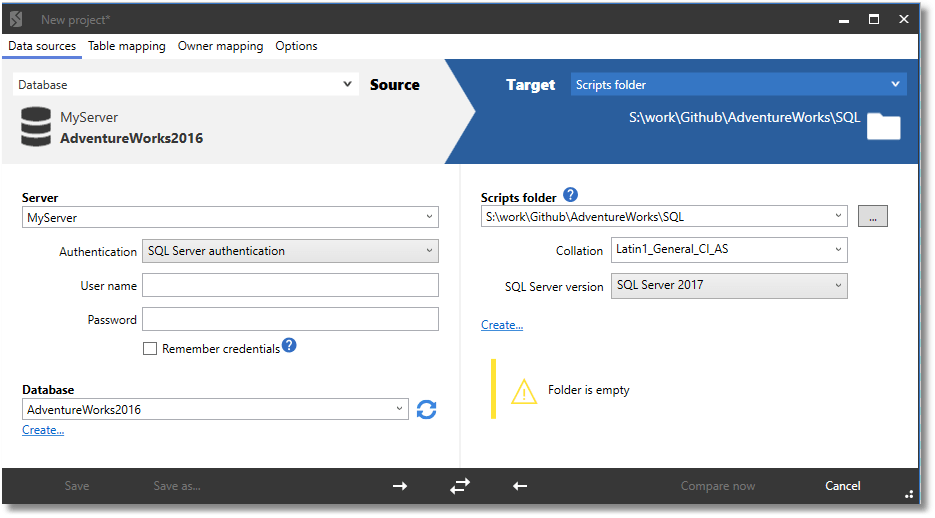
If all goes well, you will shortly see a screen displaying the differences between the source and target. When SQL Compare does its comparison work, it compares the source to the target and generates a list of objects that exist only in the source or exist only in the target or exist in both but have differences. In this case, the target was a blank directory, so we see a long list of all the objects in the database, on the left, and nothing on the right.
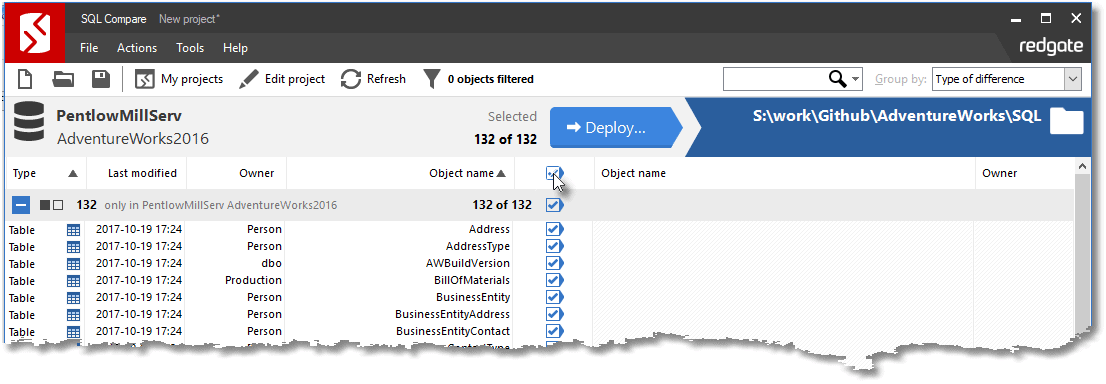
I want to 'deploy' all the objects to our local repo, so I just clicked on the checkbox that selects every object and then hit 'Deploy'. For every object that is new, or changed, a new file is created with the source in it. If it was not in the source database, the equivalent file is deleted.
The next window elicits from you the way you wish the process to end.
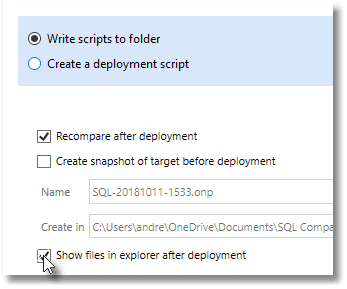
We don't want a single deployment script, which in this case would be an entire build script. We can generate this easily later. If you are asked if you wish to back up the target, you don't need that either in this case. It is comforting to re-compare the directory with the database after all the files are written. I can't remember ever having a problem, but it is good to check unless the database DDL scripts are so big that it would take too much time.
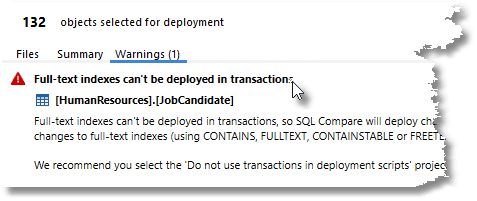
Normally, things go well. In this case, we hit a warning familiar with anyone who has tried to use AdventureWorks as a demo. SQL Compare generates a synchronization script, which it wraps within a transaction, so that it can roll back all changes should something go wrong. However, SQL Server will not allow creation of a full-index within a transaction, so SQL Compare will deploy the full-text index changes after the transaction completes. However, if the initial transaction includes changes to objects that reference that index then the deployment may fail.
You can ignore the warning at this stage, because we're deploying to a directory, but you'll need to deal with the issue when you come to use the contents of source control to deploy the database. Firstly, you'll need to install the Full-Text Search on the target, by running SQL Server Setup again to add it service into the target SQL Server for the deployment. That done, it will deploy properly if you activate the 'don't use transactions in deployment scripts' SQL Compare project option. Alternatively, you might consider Feodor's technique of excluding from the initial deployment any objects that reference the index, and then deploying them in a second step.
Hit 'Update Scripts' and SQL Compare will synchronize the source and target. In this case, we have started with an empty directory, so we’ll end up with script files being created for every database object. If we look at our source code directory to confirm this, we can see that we now have directories for all the object-level source.
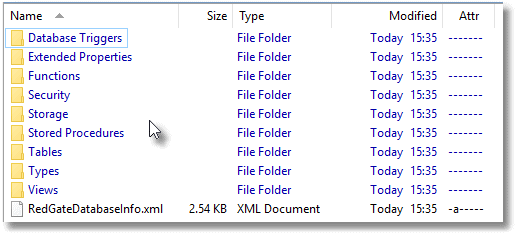
We can examine a directory, the Tables one in this case.
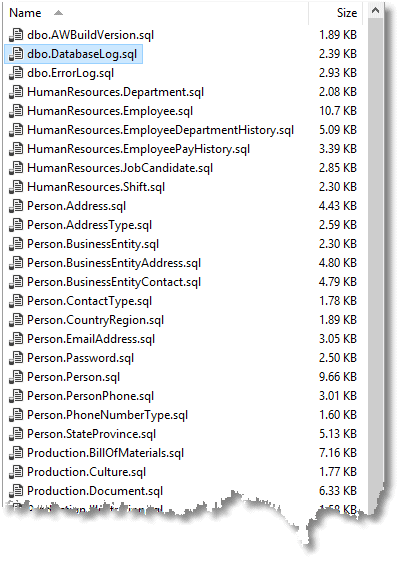
Yes, everything is there so we're ready to commit the changes to source control. First though, we must save the SQL Compare project under a name. If you don't then you would need to set SQL Compare up manually every time you run the comparison. With the project file, you can repeat the comparison by running command-line SQL Compare, specifying the project in the command line.
That done, we can go back to GitHub and do an initial commit.
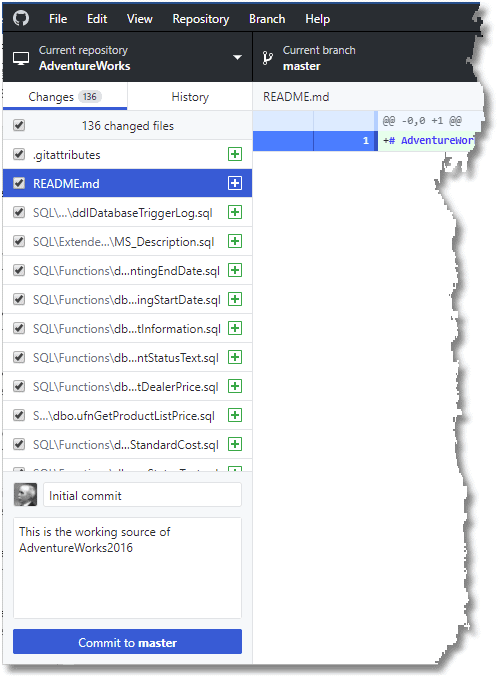
Keeping the database and source control directory in sync
So, what happens if we make a change to the database? Let's add a view and find out.
And now we refresh the project in SQL Compare.
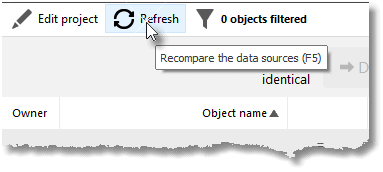
Now, having run through the process, we get the view flagged up as a change in SQL Compare
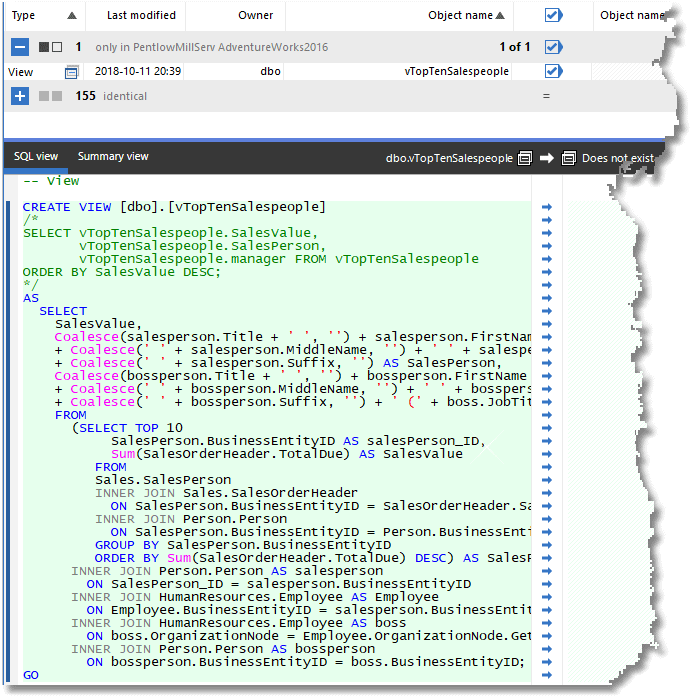
We go ahead and hit the Deploy button, and a new file has appeared in the local source control directory. Note that the time has changed, but the other files haven't changed.
Github client has detected the change in the repository and invites you to commit the change.
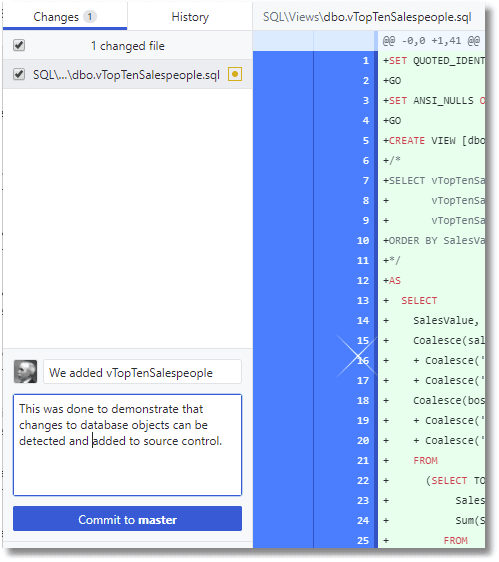
We'll commit that.
So far, we've established our Github Repository. We've shown that to save changes into the local repository, all we need to do is to refresh the SQL Server project. We can go ahead and push to origin at github.
Refining the deployment script
We've been a bit cavalier in our description of the synchronization process. There can be a wide range of requirements in the way you would want the source code. You might, for example, want to ignore changes that have no bearing on the actual functioning of the code. You might need comparisons to be case-sensitive. You might want to exclude details that concern the way that the database is installed, or the code for access control. To do this, there are a lot of knobs to twiddle to alter the way that the project runs. The reason we've been so relaxed is that we will be using SQL Compare to do all our builds and deployments, so we can be confident that these settings will work. However, the settings are all there for a reason, either for comparison or for scripting builds or deployments. For example, SQL Compare can be set to ignore certain types of difference in objects, such as collation: The 'Use case sensitive object definition' option is essential if your database is on a SQL Server with case-sensitive sort order.
If your script isn't right for your requirements, then the options are likely to allow you to correct it. The options are saved with your project, and then can be used either in the GUI or the command line. They are modified on the Project Configuration dialog box.
With the project honed to our requirements and saved, we now have the database in source control.
You will have noticed a flaw in what we have done. Everything has been saved under a single developer's name. Had we done this in reality we'd have emphasized this by using an 'admin' user.
As this article is about the steps we need to take to get the database into source control, we will leave the nuts and bolts of managing a Github project, but it is certainly possible for individual programmers to save their work under their own ID in Github or any other source control system, even when a process such as SQL Compare is doing the actual abstraction of the object-level source onto a network share.
Automating the work
Having saved the project file that you used for the successful generation of the source, and for the subsequent refresh that found the new file, you can rerun it from the command line to pick up all subsequent changes. Obviously, this wouldn't apply to a production server, but you can easily alter the project to compare with a backup.
To reuse the saved project, let's call it AdventureWorks.scp, from the command line you would simply use this syntax, providing the path to the project file:
sqlcompare /project:"C:\SQLCompare\Projects\AdventureWorks.scp"
There are many advantages to using a project, and not just to do with the database authorization, paths and so on. They are also particularly useful if you are only tracking a subset of objects, because all objects that were selected for comparison when you saved the project are automatically included. The only problem is with your choice of non-default options. The defaults are used instead for some reason, so you need to use the /options switch to specify any additional options you want to use. Also, you can't use the /include and /exclude switches with /project.
Once your command-line version of the project is working well, then it can be scheduled, either on the windows scheduler on the workstation or on the development SQL Server.
Conclusion
In supporting development work with databases, it is important that your tools can support the way that teams work rather than impose a way of working on the team. This is because there are so many different requirements. The database could be part of a purchased application, doing such organisational work as accounting, purchasing or payroll. The alterations to a database could be restricted to maintenance of indexes or constraints. The database alterations may be under a regime that is determined by compliance. It could be an agile environment doing continuous delivery, or a start-up racing to get an application up and running whilst it is still funded. SQL Compare is an oddly-named tool when one considers how useful it is in supporting a range of database development methodologies. It doesn't hector you into a single approach but just gets on and supports the way you need to work.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
The Database Development Stage
Phil Factor distills the basic tasks of the database development stage and explains how SQL Compare can help tackle them.

Article
Bulk Formatting of the SQL Server SQL Files
How to apply SQL formatting styles as part of an automated process, using the SQL Prompt command line formatter, with examples of bulk applying styles from the command prompt, PowerShell or a DOS batch.
Article
Comparing and Deploying SQL Server Databases using the SQL Compare Command Line on Linux or Windows
SQL Compare now includes a Linux-based command line interface (CLI), as well as a Windows-based one, for doing schema comparison and deployments of SQL Server databases. This article offers worked examples of CLI scripts for various schema comparison tasks, to get you up and running with either version.
Article
A Quick Diff Checker for SQL Server Databases
Compare the schemas of two SQL Server databases using SQL Compare command line then quickly produce a diff report showing you immediately which tables, views and functions have changed.
Article
Retrospective Database Source Control with SQL Compare
You've found a database that is not in source control. What do you do? Phil Factor shows how to use SQL Compare to generate all the missing object scripts, in Git, and then keep them up-to-date automatically, in response to any further database changes, during development.

Article
Using SQL Compare and SQL Data Compare within a PowerShell Cmdlet
SQL Compare and SQL Data Compare can be used together, from the command line, to provide a complete build process, or to script out changes to both the database and its development data. For doing this routinely, I find it easiest to script the operation using PowerShell.
Loading comments...