





Why you Should Avoid Using the @@IDENTITY Function
The @@IDENTITY function returns the last IDENTITY value created in the same session. If you have a trigger on the table, or if the table is a publication in a replication, then the value can sometimes be wrong. SQL Prompt's BP010 code analysis rule will warn you if it detects its use in your SQL code.

By contrast, SCOPE_IDENTITY() function returns the last IDENTITY created in the same scope as well and so is safer, as a direct substitute. When inserting more than one row at a time, it might be even better to re-engineer the code to use INSERT…OUTPUT to get IDENTITY values and computed columns. If you need to get the current IDENTITY value of a table, use IDENT_CURRENT('<tablename>').
The problem with @@IDENTITY
An IDENTITY column is generally added to a table to guarantee a unique reference to each row of a table. A table can have only one such column. It saves you the bother of having to create a natural, unique key from a column or combination of columns.
The IDENTITY column is declared with the 'seed', the first value that will be inserted into the column, and the 'increment', the value it should add to the previous value to create the next value. The seed value can be referenced by using the IDENT_SEED(<tablename>) function, and the increment value by the IDENT_INCR(<tablename>) function.
As rows are added, the table object keeps the 'identity' value that came initially from the seed and the increment value and uses them to make sure that it provides the correct value for rows as they are inserted. Each number is used just once. You can then enforce uniqueness by using a unique constraint or unique index on this column.
You'd have thought it would be easy to find out the IDENTITY values used when you insert into a table with an IDENTITY column, but it isn't always so, and you can't assume an unbroken sequence either. Although the value that is inserted into an IDENTITY is going to increment sequentially by the value you specify, it doesn't necessarily mean that it your next INSERT statement is going to be assigned the next value in the sequence, because it may be assigned to an INSERT performed in a different session. SQL Server is a multi-user system, so other users using the system simultaneously may 'steal' some of the values you are expecting by doing, or even attempting, an insertion, spoiling your sequence. Instead of an unbroken sequence, you could have gaps. This may be a problem if you are assigning meaning to that sequence.
@@IDENTITY contains the last IDENTITY value that is generated by the preceding statement in the current session. If you are importing data that has to be placed in more than one table, and these other tables contain foreign keys that reference the identity field, you’ll need that value. Were it not for triggers or replication, you might have some confidence that this was the IDENTITY value of the row you'd just inserted. If, however, the statement fires one or more triggers that perform inserts that, in turn, generate IDENTITY values, then there is a risk that it won't, because you no longer know for certain what the preceding INSERT statement was.
Let's show that as simply as we can. We'll pretend we are creating a database of the 10,000 Irish Saints (there was some major devaluation of the requirements for sainthood for a while, in mediaeval Ireland). In the Saints table, we try to record their names and meanings and a list of the Saints' days for each one. Each time we insert a new Saint, a trigger inserts the details of the individual days for each Saint in the SaintsDay table, which also uses an IDENTITY column as its primary key and has a foreign key reference to Saints. A third table, YearOfSainthood records the year each saint was created, and again has an IDENTITY column as its primary key and a foreign key reference to Saints.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
/* drop our objects if they already exist */
IF Object_Id('dbo.YearOfSainthood') IS not NULL
DROP TABLE dbo.YearOfSainthood
IF Object_Id('dbo.saintsDay') IS not NULL
DROP TABLE dbo.saintsDay
IF Object_Id('dbo.saints') IS not NULL
DROP TABLE dbo.Saints
go
/* create a new name/meaning table for our Irish Saints */
CREATE TABLE dbo.Saints
(
Saint_id INT IDENTITY(1, 1) PRIMARY KEY,
name VARCHAR(20) NOT NULL,
meaning VARCHAR(80) NOT NULL,
SaintsDayList VARCHAR(4000) null
);
/* and create a new Date table for the saints days
associated with the saint name */
CREATE TABLE dbo.SaintsDay
(
SaintsDay_id INT IDENTITY PRIMARY KEY,
Saint_ID INT NOT NULL FOREIGN KEY REFERENCES dbo.Saints(Saint_id),
DayAsString VARCHAR(500) NOT NULL,
TheMonth INT NULL,
TheDay INT NULL
);
GO
CREATE TABLE dbo.YearOfSainthood
(
SainthoodYear_id INT IDENTITY PRIMARY KEY,
Saint_ID INT NOT NULL FOREIGN KEY REFERENCES dbo.Saints(Saint_id),
[Year] int
);
go
/* create a trigger that takes the list of saints' days and
inserts them into a relational table */
CREATE TRIGGER GrabTheSaintsDays
ON dbo.saints
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO dbo.SaintsDay(Saint_id, DayAsString)
SELECT saint_id, LTrim(value)
FROM inserted
OUTER APPLY STRING_SPLIT ( inserted.[SaintsDayList] , ',' )
END
GO
-- Now INSERT a set of values into the saints table
INSERT INTO saints([name], meaning,saintsDayList)
SELECT [Name], Meaning,[Saints days] FROM (VALUES
('Cruimín','crooked; bent','28 Jun'),
('Díocuill','?','17 Nov, 1 May, 28 Feb'),
('Fursa','?','16 Jun'),
('Faolchú','wolf; wolf-hound','23 May'),
('Líthghein','born with luck & prosperity','16 Jan'),
('Díomán','pet form of Diarmaid','10 Jan'),
('Onchú','fierce hound','9 Jul'),
('Fionbharr','fair-haired','4 Aug, 25 Aug, 9 Sep, 10 Sep, 25 Sep'),
('Darearca','daughter of Erc','15 Jan, 9 Sep'),
('Énán','?','29 Apr, 30 Jan'),
('Brógán','?','1 Jan, 9 Apr, 27 Jun, 8 Jul, 25 Aug, 21 Sep'),
('Faoiltiarn','lord of wolves','17 Mar'),
('Daghán','good','12 Mar, 13 Sep'),
('Laoire','calf-herd','11 May'),
('Beoc','?','16 Dec'),
('Séanait','hawk','18 Dec'),
('Brígh','high; noble','31 Jan'),
('Dúinseach','fortress?','12 Dec, 5 Aug'),
('Tuaimmíne','variant of Tómmán','12 Jun, 10 Jan'),
('Fínín','wine-birth','5 Feb'),
('Lonán','blackbird','6 Jun, 22 Jan, 7 Feb, 11 Jul, 2 Aug, 24 Sep, 1 Nov, 12 Nov'),
('Breac','freckled','15 Jan'),
('Scoithín','bloom; blossom','2 Jan'),
('Teimhnín','dark','7 Aug, 17 Aug'),
('Aoidhghean','"born of Aodh"','1 May'),
('Ceallach','bright-headed?','1 Apr, 7 Apr, 18 Jul, 7 Oct'),
('Fiachra','Battle-king?','8 Feb, 2 May, 25 Jul, 30 Aug, 28 Sep'),
('Iobhar','yew','23 Apr'),
('Conna','pet form of Colmán (''dove'')','3 Feb')
)f([Name], Meaning,[Saints days])
|
Unaware of the existence of the trigger, we now innocently try to insert the details of a Saint and his year of Sainthood:
|
1
2
3
4
5
|
INSERT INTO saints([name], meaning,saintsDayList)
VALUES ('Siadhal','','12 Feb, 8 Mar')
INSERT INTO YearOfSainthood (Saint_id, [Year])
VALUES (@@Identity,'759')
|
That year of Sainthood would reference the wrong saint, or no saint, but as we've got a foreign key constraint, it causes a foreign key constraint violation:
Msg 547, Level 16, State 0, Line 89 The INSERT statement conflicted with the FOREIGN KEY constraint "FK__YearOfSai__Saint__3F3159AB". The conflict occurred in database "master", table "dbo.Saints", column 'Saint_id'.
Unfortunately, @@IDENTITY is not limited to a specific scope, meaning the module (stored procedure, trigger, function, or batch) that is currently executing, and the trigger will be executed in the same session but a different scope. If a trigger inserts into another table that has an IDENTITY column, @@IDENTITY returns the identity value of that subsequent insert. Likewise, if your database is part of a replication article, then the @@IDENTITY value will be unreliable because it is used within the replication triggers and stored procedures.
In our example, it's simple to prove that @@IDENTITY now shows the IDENTITY field of the SaintsDay table not the Saints table:
|
1
2
3
4
5
6
|
SELECT @@Identity AS [Value of @@Identity],
Scope_Identity() AS [Value of scope_Identity],
Max(Saint_id) AS [Largest ID Assigned],
Ident_Current('dbo.saints') AS [Identity value of 'saints'],
Ident_Current('dbo.saintsDay') AS [Identity value of 'saintsDay']
FROM Saints;
|

To avoid all this, and just get the IDENTITY value for the last insert, you should then be using the SCOPE_IDENTITY() function syntax instead.
Whereas both @@IDENTITY and SCOPE_IDENTITY give you the value of the last IDENTITY field assigned in the preceding statement in that session (either ignoring scope or within scope), you may decide that you need to know the IDENTITY value of a specific table. If you do, then the IDENT_CURRENT() function gives this. You just specify the table name as a varchar.
Insert clause with output clause with IDENTITY
Although the simple advice for most uses of the @@IDENTITY function is to replace it with SCOPE_IDENTITY, one must say that, where you wish to determine the IDENTITY values for an INSERT statement that results in the insertion of several rows, the use of the OUTPUT clause provides a safe way of finding the IDENTITY values for every inserted row, along with any computed columns in case you need that as well, for some other purpose. Here is a simple example to illustrate the point.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
CREATE TABLE #IrishSaintsDays
(
Saint_id INT IDENTITY,
name NVARCHAR(50) NOT NULL,
CurrentsaintsDate DATETIME2(7) NULL,
SaintsDay AS Convert(VARCHAR(6), CurrentsaintsDate, 113)
);
INSERT INTO #IrishSaintsDays (name, CurrentsaintsDate)
OUTPUT inserted.Saint_id, inserted.name, Inserted.SaintsDay
VALUES
(N'Finten, also Fintan, Munnu', '2019-10-21T00:00:00'),
(N'Énda mac Conaill', '2019-03-21T00:00:00'),
(N'Olcán', '2019-02-20T00:00:00'),
(N'Suibne moccu Urthrí', NULL),
(N'Coirpre Crom mac Feradaig', '2019-03-06T00:00:00'),
(N'Béoáed mac Ocláin', '2019-03-07T00:00:00'),
(N'Cairech Dergain', '2019-02-09T00:00:00'),
(N'Gobban Find mac Lugdach', NULL),
(N'Fáelán Amlabar, Fillan', '2019-06-20T00:00:00'),
(N'Commán mac Fáelchon, Mo Chommóc', '2019-12-26T00:00:00'),
(N'Boethian of Pierrepoint', NULL),
(N'Caomhán (Cavan, Kevin)', '2019-06-14T00:00:00'),
(N'Manchán of Mohill (Manchán of Maothail)', '2019-02-25T00:00:00'),
(N'Columba', NULL),
(N'Raoiriú', NULL),
(N'Dublitter', '2019-05-15T00:00:00'),
(N'Cuimín of Kilcummin', NULL),
(N'Fínán Cam mac Móenaig', '2019-04-07T00:00:00'),
(N'Maonacan of Athleague', '2019-02-18T00:00:00'),
(N'Scuithin', '2019-01-02T00:00:00');
|
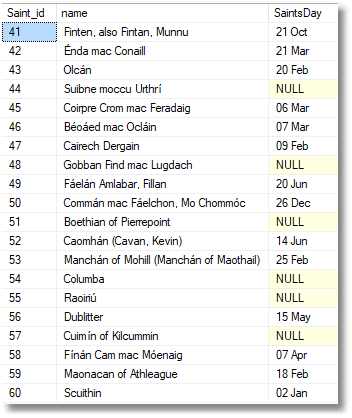
If you insert this output into a table variable, you have many opportunities to use the information from the IDENTITY column for the population of associated tables that have foreign key references to the table you've inserted into, using that IDENTITY field.
In this case, for example, I might want tables that relate to this table, to provide meanings to the various parts of the name so I can analyze all the saints whose names are taken from the name of a Celtic god (e.g. Lugh, Hus, Brij, or Finn), or maybe the prime location associated with the saint, the tribal ancestor it represents, or provide the date at which the good Christian became a saint.
Conclusions
We are nowadays much better supplied with ways of dealing with the popular use of the IDENTITY column to provide a primary key that provides a simple unique reference to rows. The @@IDENTITY function is fine in most circumstances, but it has a scope problem that can catch you out. In the heat of the moment, it is too easy to forget that the table you are inserting into has a trigger associated with it. It is much better to get into the habit of using SCOPE_IDENTITY instead or use the more powerful and versatile OUTPUT clause that wasn't even imagined in those early days when @@IDENTITY was first devised.
Tools in this post
You may also like

Article
Finding code smells using SQL Prompt: the SET NOCOUNT problem (PE008 and PE009)
Generally, you should prevent rowcount messages being sent, by adding a SET NOCOUNT ON at the start of every stored procedure, trigger and dynamically executed batch. Phil Factor demonstrates, and explains the nuances and exceptions.
Article
Finding code smells using SQL Prompt: old-style join syntax (ST001)
There are no advantages to using old-style join syntax. If SQL prompt identifies its use in legacy code, then rewriting the statements to use ANSI-standard join syntax will simplify and improve the code.
Article
Finding Correlated Rows Using EXISTS or COUNT
Should you always use
EXISTSrather thanCOUNTwhen checking for the existence of any correlating rows that match your criteria? Does the former really offer "superior performance and readability". Louis Davidson investigates.Article
Using a Variable-length Datatype Without Explicit Length: The Whys and Wherefores (BP007/8)
If you declare a variable-length string , or coerce a string, without specifying its length, you can fall foul of ‘silent’ string truncation. Some developers resort to using the
(MAX)specification, which is a mistake too. Phil Factor explains the dangers and then offers a workaround for the problem, when you're importing text and simply don't know the correct length of each string.Article
Quick SQL Prompt tip – why you should expand the wildcard
One of the great things about SQL Prompt is that it quickly removes the need to use so many keystrokes. That’s helpful and handy, but to become a really efficient T-SQL coder, you’ll want to practice incorporating a few tricks into your routine. Here’s a good one. Often I run into tables and can’t remember all the columns. One trick many people use is to type SELECT *, which gives you a quick look at a table, but isn’t what you want in production code. Instead, you’ll want to specify which fields you need to return. When I type SELECT,
Article
SQL IntelliSense and Autocomplete in SSMS
Phil Factor reviews the major features of SSMS IntelliSense and autocomplete and then explains how SQL Prompt fills in the gaps, and how to use to use the two in tandem to 'get the best of both worlds'.
Loading comments...