Database Development with GitHub
How can you use GitHub to do team-based database development? This article proposes a process that splits development work into task-based GitHub branches, incorporates daily database builds and integration testing, and uses Redgate tools to automate tasks such as provisioning, database scripting, and testing.
In this example, we’ll assume that a team of four database developers are working together on a SQL Server database. The build process hopefully delivers the current version of the database that includes all commits to main. The build finishes by importing a standard set of development data.
The build is done after one or merges are done, but realistically, it is done as an overnight batch so that the loading of large quantities of development data isn’t a time-constraint. The build isn’t done unless a change has been committed to main in Github. The current build of the database is created by an automated process that creates it from source and fills it with data. It then runs automated tests and checks the code quality. Each build increments the version number. Each release increments the release number and zeros the version number.
Although each developer has write access to the repository, they prefer to work on their own copy of the current build of the database, and each using a branch that is dedicated to their part of the current development work.
In this diagram, Mo, Jill, Dave, and Vince are each starting on a branch, which should be named to reflect the functionality or features that they will aim to add in the branch. Each branch is represented by a copy of the database, complete with development data. Although each developer is assigned to a branch, they are free to pair on a branch where necessary. All branches are visible. They will check into that branch and work on the database that represents that branch.
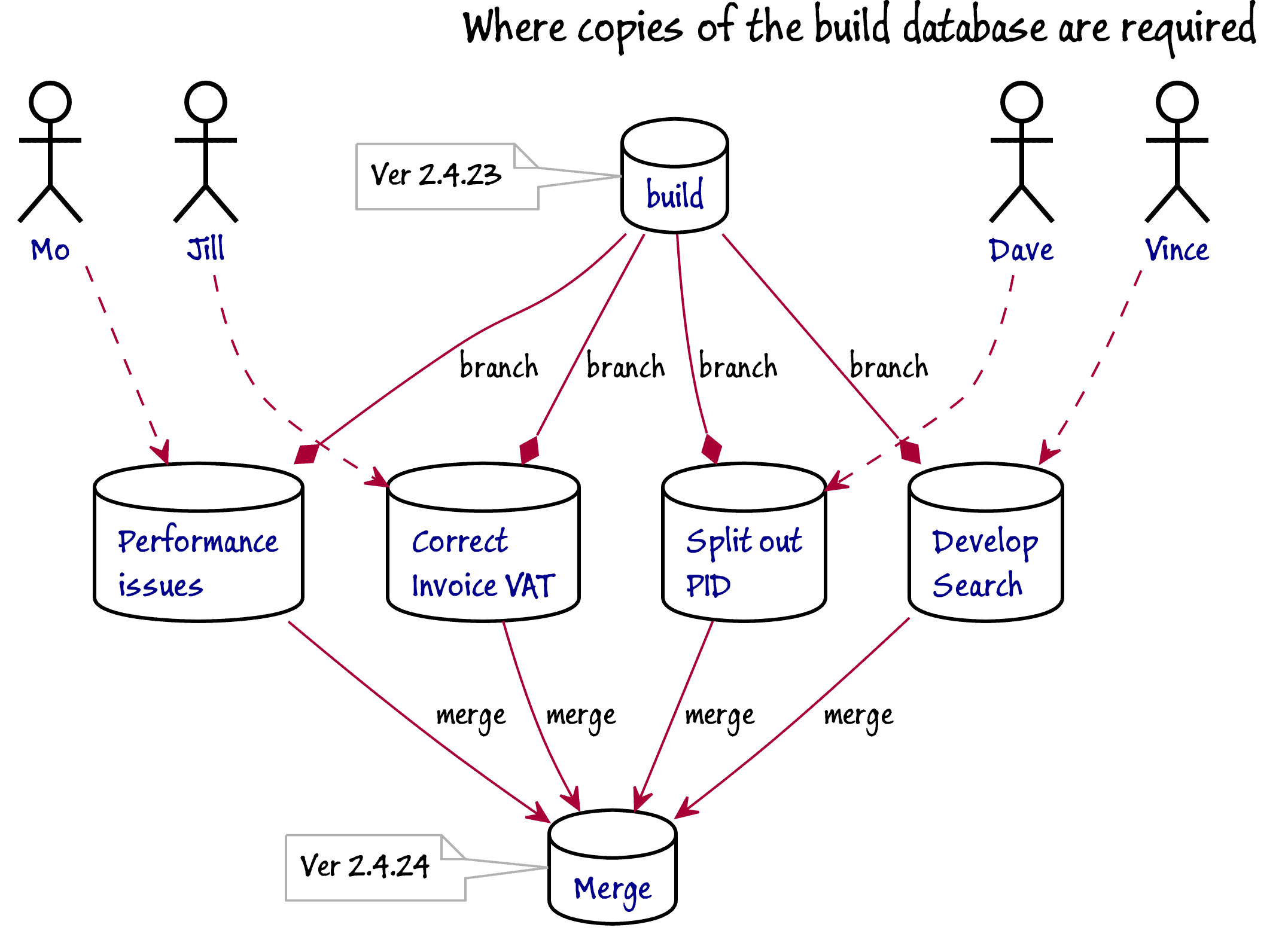
The database representing the current build will be available, either as a read-only database, a SQL clone, a script folder or a SQL Compare snapshot, and so they can generate the code for the changed objects by using SQL Compare to compare their altered database with the script folder for their branch. This allows them to script out some or all their changes either as deployment scripts or build scripts.
They also have access to a copy of the current released version, which helps to check for potential data migration issues. All developers have their Git client configured with their correct email address and linked to their GitHub user. The project has one of the team nominated as a ‘code owner’ for making sure that code reviews are done in time and to administer the repository.
When the work in a branch is completed, the changes are synched where necessary, unit-tested, and a pull-request is opened. The work is reviewed, pushed to Main and merged where necessary. Once that is done, the branch can be deleted.
Sometimes things don’t go according to plan with work on a branch. There is a lot of flexibility here, two or more developers can work simultaneously on a branch, and a branch can, itself, be branched.
Handling data
It must be quick and easy to fill a database with realistic data. This data can be generated, or anonymized, but ideally conforms in its distribution and volume with the production data or the likely production data. All copies of the build of the current, released version should have the same data if possible, to aid testing. There are two possible ways of changing the data to allow it to be imported into a new development version of the database that has an altered table structure:
- Run a data migration script on the current version, before the table change, to bring it to the version after the table change, or
- Alter the data, stored as structured text (CSV, XML or JSON), outside the database.
Native BCP is the quickest way of importing data, but this requires the first approach. The small standardized datasets used for integration test runs are best kept in the source code repository as text (e.g. as SQL, CSV or JSON). Large datasets, especially native BCP, are best archived entirely separately or in large file storage.
The process
The process aims to allow changes to be released quickly and safely to production, by keeping the committed source closely in step with the work being done and automating all routine tasks in overnight unattended processes. Any build-breaking issues are quickly highlighted early on in development. They are fixed as soon as possible in main. In my experience, a team will have issues early on with the build, but a culture soon evolves that spots potential problems in the code review once pull requests are made.
Test builds of the empty database are easily done after all merges are complete to filter out anything obvious and can be easily automated. It is possible to organize the flow of the processes to allow the full build process only after a successful test build. Overnight build processes are only necessary where large datasets that are loaded into the database take more than half an hour. Even where the build is unlikely to become a release candidate, anything in main should be deployable.
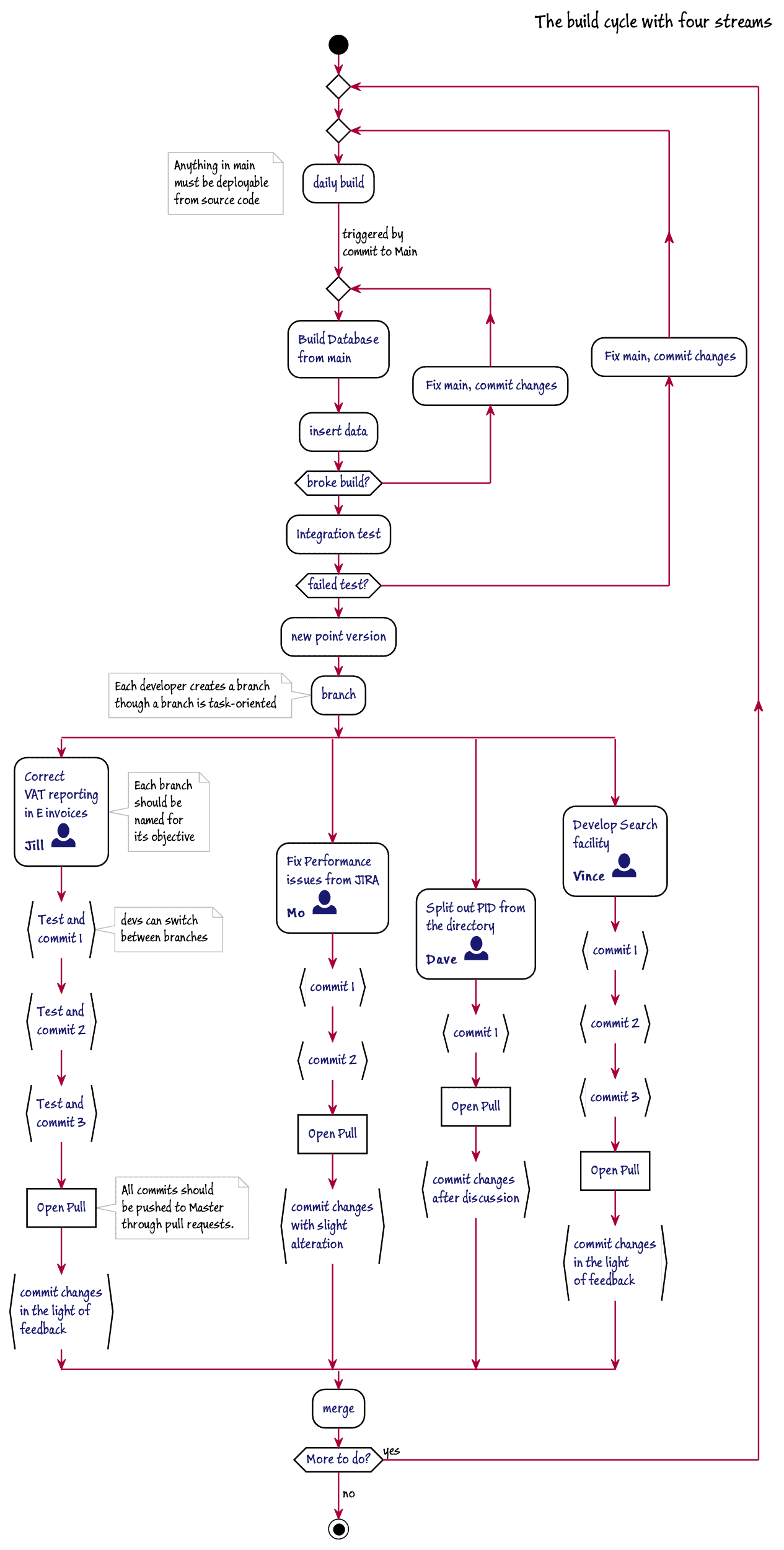
Provisioning database copies
Until recently, the cost of servers made it unrealistic to provide individual development servers on which could be deployed copies of the current build of the database. This made shared development servers a popular approach. This worked well, as long as it remained clear who did what, who had checked in what, and what code belonged to Main.
First VM technology, followed by containers, and now clones make it much easier to provide all that is required. This allowed teams to be more versatile in their database development methods. A mixture of shared and branch-based development was possible. Databases could represent branches to the point where automated integration testing of any inter-related components being developed could be done even before merging to Main.
With a clone-based approach, multiple copies of any successful build can be made available almost immediately. Any development database can be wiped clean of subsequent changes if a branch is scrapped. In the hypothetical database development project that I’ve described, there are likely to be either six or seven databases. There will be a database representing the current development version and current build, a database representing the current production version (if there is one), four development databases, one for each branch, and possibly a shared database for running tests and experiments. With Clone technology, where the data is held in just one image on the network, one can afford to be lavish.
Running unit tests and integration tests
The processes that run standard tests can give feedback as to whether the individual commits meet requirements. A tool like SQL Change Automation can bundle some of these tests directly into the build process. For example, it can check for SQL code issues and run unit tests. These tests must be saved alongside the code.
Collaborative processes
Important characteristics of a DevOps collaborative process are the CLI interfaces and hooks that allow teams to use whatever tools they prefer. This is especially important for allowing remote team working. This means that tools for issue tracking, source control, testing, code review and discussion should have a means of interacting. By using status checks from issue tracking tools, along with protected branches in GitHub, automated processes, as well as team members and ‘owners’, can check whether preconditions are met for the merge into a protected branch. Required Status checks allow automated processes such as test builds to ensure that a build will succeed before branches can be merged into the protected branch. This will also allow for code to have static checks for deprecated functions, and anything else that cuts across corporate standards.
Releases and Tags
Database releases candidates are likely to undergo testing and approval processes of various types, such as for security and legal compliance. These are mostly out of scope for this article but are worth mentioning because progress along the deployment ‘pipeline’ can be speeded greatly if experts in compliance and security can take part in various development review processes, to warn of potential issues and become familiar with the general direction of development. This also allows them to view previous releases and tags or event to comment on code reviews.
A release candidate will be designated by a tag. The most important artefact that is produced at this stage is the migration script that changes the current version of database to the new version. This will be added to source control along with a build script that creates all the database objects in the correct dependency order, used for creating the database from scratch. Both these scripts will be given their first check-over by the test team, or the developers, as part of their work of setting up a test cell for the release.
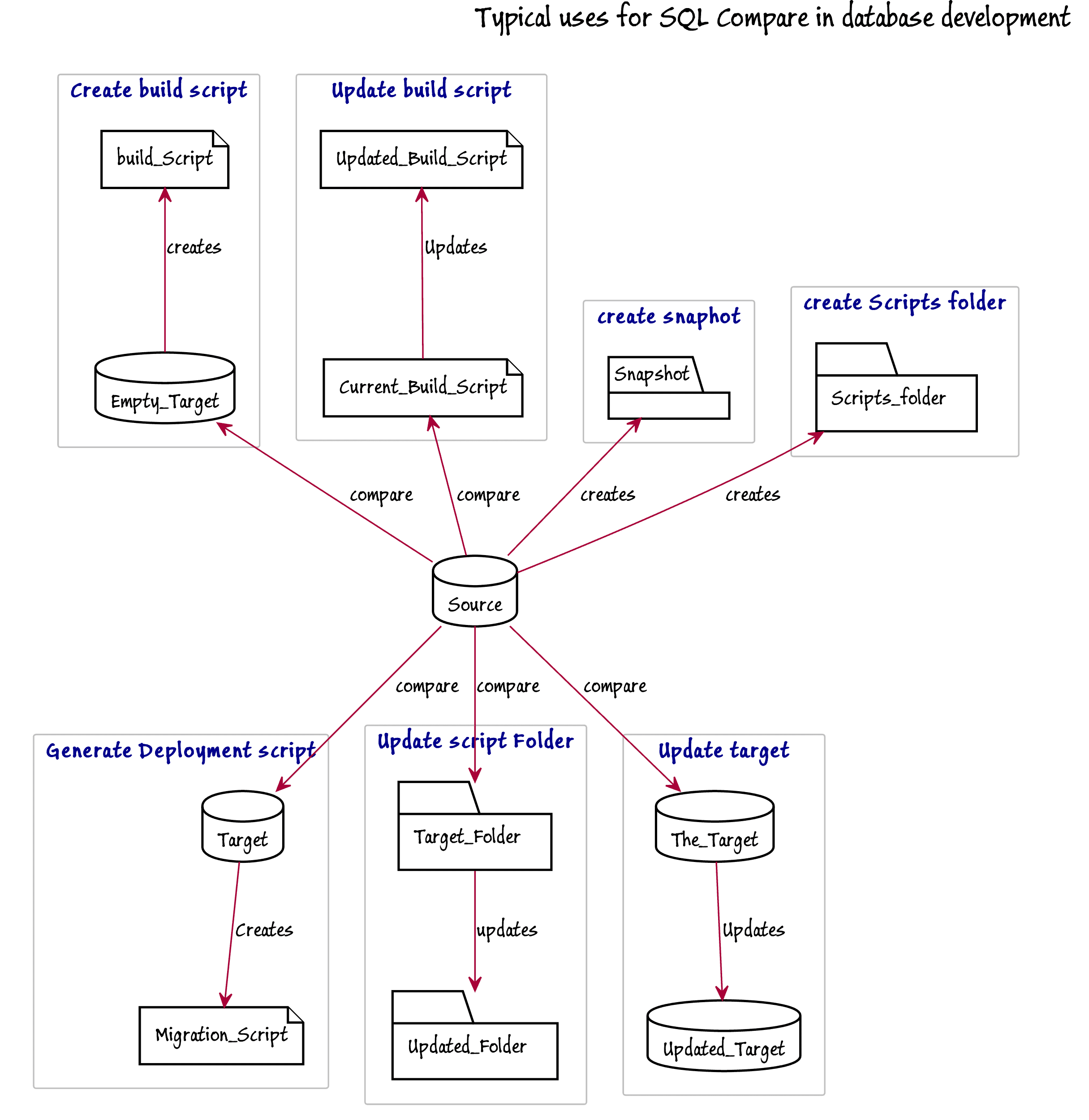
Script Generation
SQL Compare is ideal for the task of generating or updating scripts, snapshots, script folders or build scripts. It can be used to script out selected parts of a database such as a schema or a particular type of object, such as tables. Because it has been used for this for so long, it has become very versatile.
This diagram illustrates many of the tasks that SQL Compare can perform as part of development work. It is also able to use an SCA project or SQL Source Control directory as a source or target for a comparison.
‘Versioning’ the database
One of the particular problems that database developers come across is that of ‘versioning’ a database. A database is one of the few software artefacts that is altered as well as built. Whereas it is easy to attach a version number to a software application, a database can ‘drift’, or be updated to a new version. You can easily attach a version number to a database in an extended property, but what if you make changes? A deployment script is usually only valid to change a database from one specific version to another, so it must check first that the target of the deployment is at the correct version, and abort the deployment if it isn’t at the right version. After it is run successfully, it must update the version number. To check whether there is an ‘uncontrolled’ change to the version, you need to check whether the metadata has changed.
Where the organization requires meticulous checks to make sure that target versions of databases are really at the version attributed to them when deploying to production, the deployment process must test this rather than take it on trust. If uncontrolled changes have been made in production or staging, they must be saved, and the deployment process must be restarted. SCA supports this process securely.
Conclusions
The best way of using Git or GitHub in database development is to adopt it wholeheartedly and use its strengths rather than just to regard it as just another source control system. This means exploiting the ease with which one can create branches and merge them. It is rather closer to the informal way that database developers have worked in the past. Git can be an obvious help to a database development team once all its features are used. Whereas the raw command-line Git can be baffling at times, several tools are now available for Git and GitHub integration and they allow the developer to adopt Git without coaching or lengthy initiation. SQL Compare is a very useful tool in this context because it can save a lot of difficult and error-prone work, particularly in creating and maintaining deployment scripts.
References
- Testing Databases: What’s Required?
- SQL Code Analysis from a PowerShell Deployment Script
- The Database Development Stage
- Managing branches
- Administering a repository
- Viewing branches in your repository
- Syncing your branch
- About pull requests
- Merging a pull request
- Managing the automatic deletion of branches
- Managing large files
- About status checks
- About required status checks
- Viewing your repository’s releases and tags – GitHub Docs)
- Git – Tagging
Tools in this post
You may also like
-

Article
Static Data and Database Builds
Whichever way you wish to ensure that a database, when built, has all the data that will enable it to function properly, there are reasonably simple ways of doing it. Phil Factor explains the alternatives.
-

Article
A whole new way to see differences in SQL Compare
SQL Compare 12.4 adds the Summary view, a tab that sits alongside SQL view and provides a more concise breakdown of the differences between two objects.
-
Article
Database Build Breakers: Avoiding Constraint Violations during SQL Server Deployments
A common database build breaker is data that violates the conditions of any of the CHECK, UNIQUE or FOREIGN KEY constraints, and unique non-clustered indexes, designed to protect the consistency and integrity of your data. Phil Factor explain how to avoid this problem, using SQL Compare and some custom stored procedures to discover which rows will cause violations, and fixing them, before running the build.
-

Article
How to automatically provision sanitized data using SQL Clone, Data Masker and PowerShell
Chris Unwin describes a strategy, using data masking, cloned databases and PowerShell, which will allow you to sanitize data before provisioning test or development environments.
-
Article
You just Build It don't you? 12 Common Database Build Blockers
Database deployments, like the sheep of exasperated hill-farmers, often find strange and unexpected ways to self-destruct. Phil Factor describes the most common things that can go wrong, and how a reliable automated database build process can prevent messy accidents.





