Using SQL Change Automation in SSMS to Track Static Data Changes
SQL Change Automation 4.1 now allows users to develop static data changes from SQL Server Management Studio.
Often, a database build will need to supply any ‘static’ or ‘immutable’ data required for dependent applications to function. This might include ZIP or postal codes, the names of countries or currencies, standard tax rates, and so on. This static data should be relatively small in volume and, as its name suggests, is not expected to change frequently. However, if it does change, or new static data is added, during development, then the scripts that deploy these data changes, along with those that deploy the schema changes, need to be included in the build package.
The SQL Change Automation Development tools include extensions that integrate directly into your chosen SQL Server development GUI, Visual Studio or SQL Server Management Studio. This allows teams to develop new databases and modify existing databases, using migrations, in a way that promotes DevOps practices.
In SQL Change Automation v4.1, we’ve added support for the tracking of static data tables to the SSMS extension, alongside existing support in the VS extension. In this article, I’ll show how to add static data tables that you wish to track directly through a new Data tab in the SSMS extension, and which columns within those tables. I’ll demonstrate how SCA will then automatically create migration scripts to deploy any changes to this data, allowing the team to see a preview of the changes before generating the migrations.
Configuring static data tracking from within SSMS
Version 4.1 of SQL Change Automation in SSMS adds a new Data tab to the project view, where the users can pick the tables to track. In previous versions, this had to be done manually, by adding tables to the SQL Change Automation project settings (.sqlproj) file. Users that have databases with large number of tables will also benefit from using the filter that will allow them to find the tables they want to add easily.
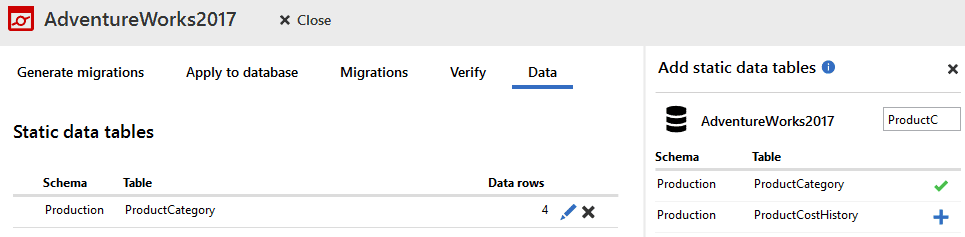
Adding tables to the Data tab
Tracking tables with large volumes of data, via migrations can deteriorate performance because SQL Change Automation generates the static data in the form of individual INSERT statements for each row, and tracks changes via a line by line comparison between data in the source and target. Our recommendation is that it’s fine to track tables with less than 10K rows, but for larger data sets we recommend the ‘Seed data‘ method, where all data is saved to a flat data file and uploaded via a BULK INSERT statement. We display the number of rows each tracked table contains helping the user set up their project in a sensible way.
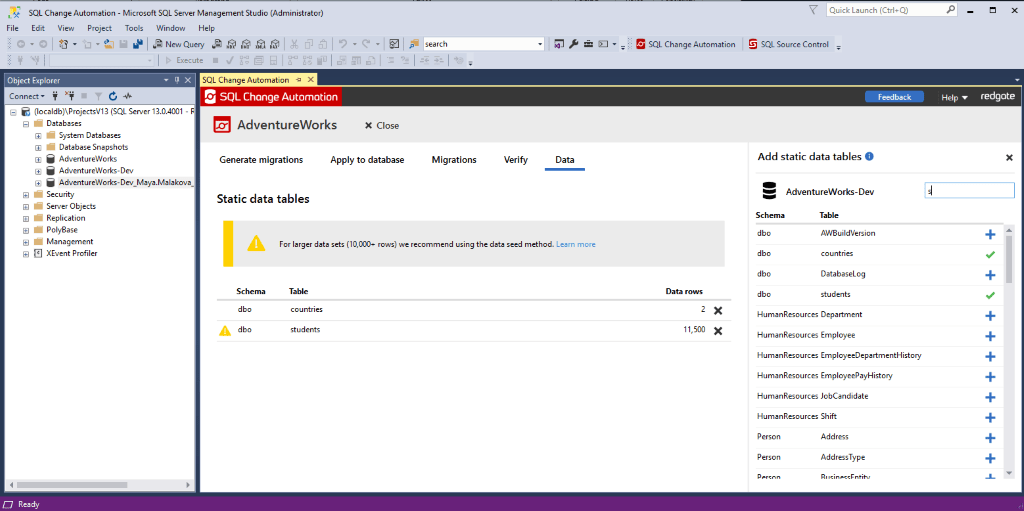 Row number warning
Row number warning
SQL Change Automation needs a primary key in order to track data so we try to make it obvious which tables can be tracked, and which ones would require adding a primary key first.
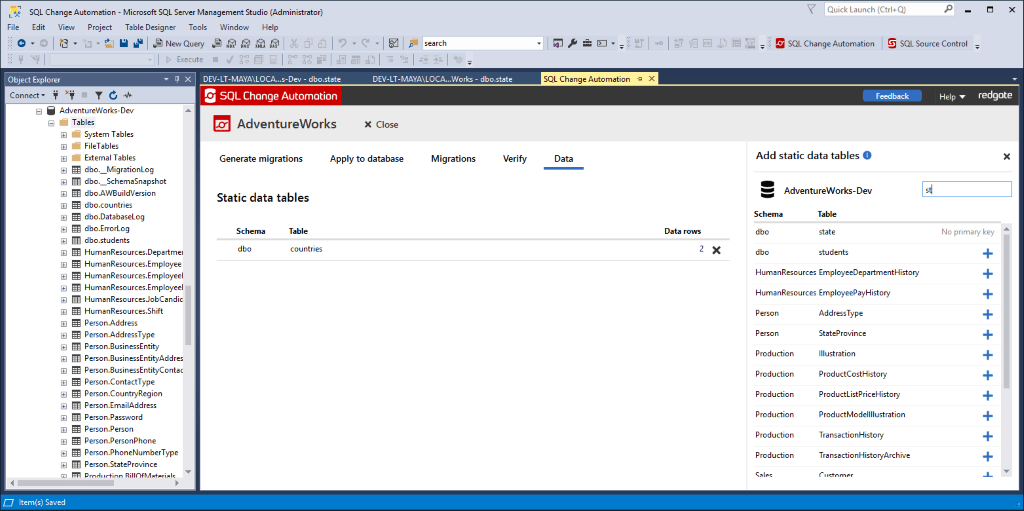 Table without primary key
Table without primary key
Column-level control of static data tracking
Some columns within static data tables, such as Date Created or Date Updated columns, might hold values that we don’t want to replace with new values from development. Just hit the Edit pencil for a table you’re tracking and select which columns you want to track (previously, it was only possible to exclude columns from tracking by manually editing the project settings file).
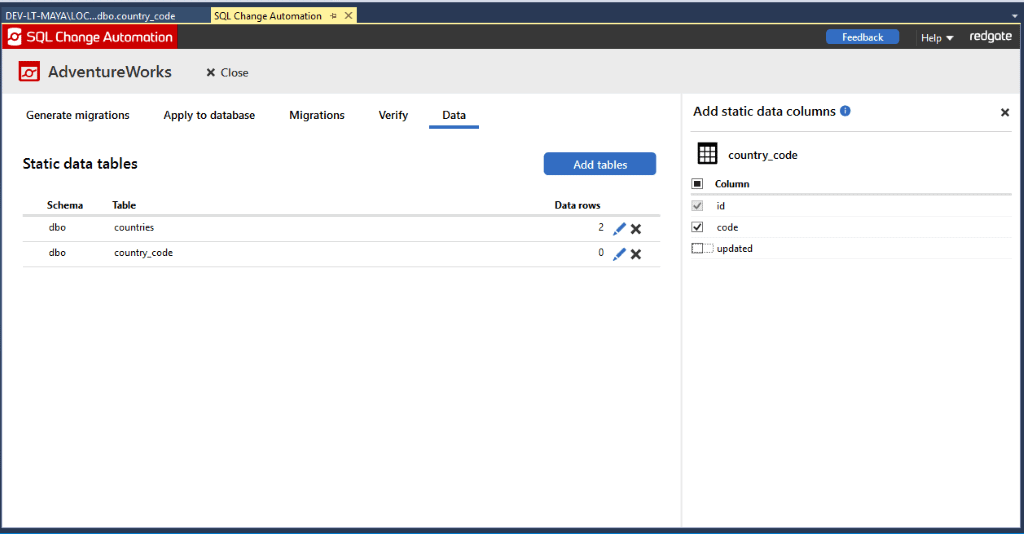 Column level configuration of static data
Column level configuration of static data
Seeing static data changes from within SSMS
Changes in static data are now visible on the Generate migrations view of the SSMS add-in.
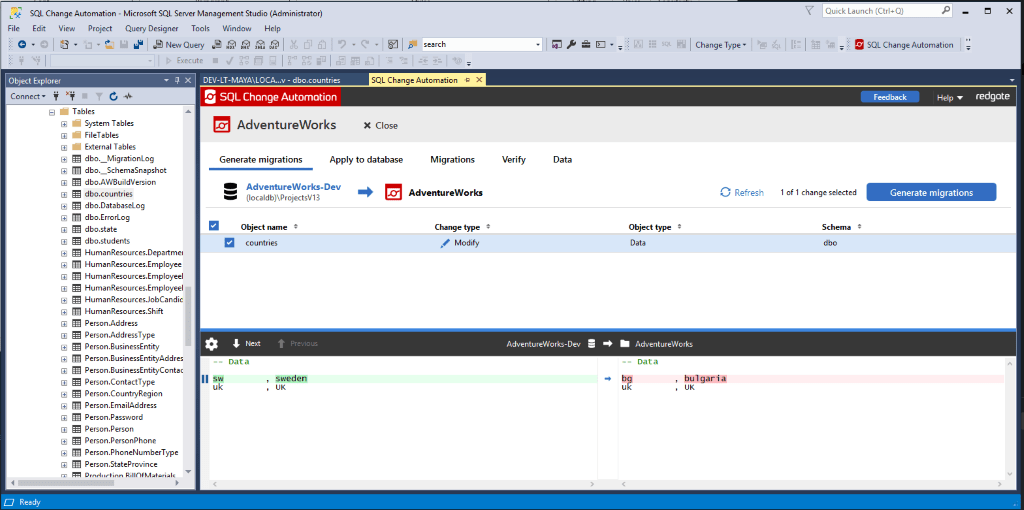 Data changes diff
Data changes diff
After confirmation, the newly generated migration gets included in the project. Once shared in version control the changes will be picked up automatically by the deployment components of SQL Change Automation, such as our Azure DevOps plugins, and deployed to a target database.
What do you think?
We’d love to find out what you think. Drop us an email at SCA-SSMS@red-gate.com
Tools in this post
You may also like
-

Article
Overcoming Database DevOps Challenges: Part 1
As part of our research for the 2021 State of Database DevOps report, we asked 3,000+ recipients what they consider to be the greatest challenge when integrating database changes into a DevOps process. According to the respondents, these are the most important challenges facing database professionals when introducing DevOps practices to database development. Three of
-

Article
Allowing for manual checks and changes during database deployments
SQL Change Automation enables users to make database changes to production safely and efficiently using PowerShell cmdlets, which can be integrated easily into any release management tool. This article will show you how to automate database deployments safely, by using SQL Change Automation from within PowerShell scripts, and how a deployment script for a release can be checked and amended as part of the process.
-
Article
Baselining a SQL Change Automation project from an existing database
This article show how to create a 'baseline' for your Visual Studio SQL Change Automation project, from an existing, target SQL Server database, so that the team can start making changes and easily deploy them to the target database.
-

Article
Handling System-named Constraints in SQL Compare
If some of your database constraints have system-generated names, they can cause 'false positives' when comparing schemas and generating build scripts using SQL Compare or SQL Change Automation. Phil Factor explains the difficulties, and the Compare option you need to enable to avoid them.
-
Article
SQL Change Automation 4.0: Collaborative Database Development Across Visual Studio and SQL Server Management Studio
SQL Change Automation's Development component for developing new databases and modifying existing databases, using migrations, now integrates directly into SQL Server Management Studio as well Visual Studio. It allows teams to collaborate effectively during development, regardless of their preferred IDE, and in a way that integrates easily with common build/integration servers and release management tools.