





Database Build Blockers: Cross-Server Database Dependencies
Cross-server dependencies, in one or more databases, can cause unnecessary grief in both development work and in continuous integration. Linked Servers are a useful and popular feature and shouldn't cause too many problems in development, with careful planning.
By using four-part references in SQL, to objects in linked servers, SQL Server lets you fetch and update data in databases on other servers. If the remote server is constantly accessible throughout the database lifecycle, it is all very easy. Even so, if a group of databases make cross-server references to each other such that none can be built without the existence of all the others, then it can all get rather more complicated. This article shows you how a mixture of stubs and synonyms can make it all work, first using hand-rolled scripts, then as an automated build process using SQL Change Automation.
One of the advantages of using synonyms for remote objects, which is that they do not require a check on the existence of the base object at the time that the object is created, is also a possible issue in that your builds do not fully exercise all dependencies. In other words, your build might succeed even if, for example, the definition a remote object has changed in a way that would normally make it fail. You will not find this out till you run your subsequent tests, which access the underlying base objects.
Although you can also use the synonym technique for cross database dependencies on the same server, it confers no advantages. I'd recommend instead you consider a simpler technique that uses temporary stubs and does a complete build. On other occasions you might consider simply restoring copies of all the dependent databases, before starting the build.
Handling cross-server dependencies using synonyms
On inspecting any SQL that makes cross-server calls, the most obvious difference is that we use four-part references to the objects on the linked servers, rather than the three-part references used for cross-database dependencies on the same server. Once the linked servers are defined on the SQL Server instance, the 4-part references allow us to run SQL queries, create views or call procedures on them.
However, SQL Server handles these cross-server database calls entirely differently. They are simply remote procedure calls, and their usefulness depends on the capabilities of the underlying OLE-DB provider. When using them, transactions across servers should be avoided. Linked servers are usually the only realistic option to access data whose source is outside of SQL Server.
To demonstrate the problems that cross-server dependencies can cause for a standard build process, we're going to use the same, simple two-database project with mutual dependencies as we used for the cross-database article. However, this time the databases might live on different servers.
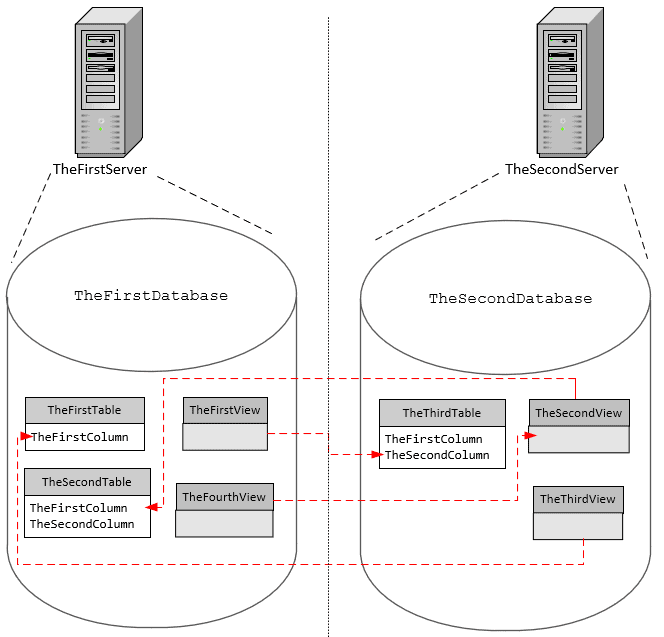
Figure 1: Simple cross-server circular (mutual) dependencies
To cope with cross-server dependencies, we generally use SQL Server Synonyms in our code in place of the actual four-part address of the object. This provides a layer of abstraction to avoid actual server instances being specified in code. It means that when the server or database name is changed, it requires just one change in the database making remote calls. A synonym's references can include three-part references to another database on the same instance, or even two-part references in the same database. If you want to change the location of the actual object, you merely delete the synonym and create a new one with the same name but pointing to the new object.
So instead of using this view definition in our build scripts:
|
1
2
3
4
5
|
-- the first view with a direct, cross-server reference
CREATE VIEW dbo.TheFirstView
AS
SELECT TheSecondColumn FROM TheSecondServer.TheSecondDatabase.dbo.TheThirdTable;
GO
|
Listing 1: Object source script for TheFirstView
We can do this:
|
1
2
3
4
5
6
7
8
|
--the synonym
create synonym SecondDatabaseThirdTable
FOR TheSecondServer.TheSecondDatabase.dbo.TheThirdTable
-- the first view, using the synonym
Create VIEW dbo.TheFirstView
AS
SELECT TheSecondColumn FROM SecondDatabaseThirdTable;
GO
|
Listing 2: Creating TheFirstView on a synonym
With synonyms, unlike views, SQL Server doesn't check the existence of the base object at the point it creates the synonym; it checks this only at run time, when you attempt to use it. This allows you to build a database without needing that external reference to exist at the time.
Of course, in the above example we still have a problem, because we're immediately using the synonym within the view, at which point SQL Server checks that the base object assigned to the synonym exists, which it might not. To get around this, we still need a local stub to represent the remote object. In other words, we create the synonym on a local "dummy" version of the remote object, create the view using the "dummy synonym", then immediately drop the dummy synonym and replace it with the one with the real remote reference.
When building using synonyms, you'll need to make sure your subsequent post-build tests access all them all, so that the remote references are checked. Otherwise, you might get errors when you first execute a query with a synonym.
This same technique, using synonyms and local stubs, will also work when our databases are on the same server, and I've provided a CrossDBRefsUsingSynonyms script that you can try out. However, using synonyms is over-the-top for cross-database dependencies, as there are simpler ways of achieving the same ends, as I demonstrated in my previous article, Database Build Blockers: Mutually Dependent Databases. Also, for the reasons already described, I generally avoid using synonyms unless I have no choice.
Hand-scripted builds with cross-server dependencies
The real joy of the technique of creating dummy 'stubs' of remote objects, which may not exist or be in network range, and then substituting a different synonym to point to a remote server, is that you can build the database without the remote instance and its database being available. Just don't try running any of the code that contains the dependency.
We need to be able to build these databases, on their separate servers, in any order we like, whether the other remote database(s) are there or not. This means we need two hand-cut build scripts.
In this simple example (see Figure 1), TheFirstDatabase is on the server Phasael, and TheSecondDatabase is on Aristobulus. You'll need to establish each of these as a linked server for the other (you can do this in SSMS or T-SQL). Here is the script for the first database to be built, on the server Phasael.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
USE TheFirstDatabase
/*-- start of Cleanup script for TheFirstDatabase --*/
IF Object_Id('dbo.TheFirstTable') IS NOT NULL
DROP TABLE dbo.TheFirstTable;
IF Object_Id('dbo.TheSecondTable') IS NOT NULL
DROP TABLE dbo.TheSecondTable;
IF Object_Id('dbo.TheFirstView') IS NOT NULL
DROP VIEW dbo.TheFirstView;
IF Object_Id('dbo.TheFourthView') IS NOT NULL
DROP VIEW dbo.TheFourthView;
IF Object_Id('tempdb..#dummy') IS NOT NULL
DROP TABLE #dummy;
IF Object_Id('dbo.SecondDatabaseThirdTable', 'SN') IS NOT null
drop SYNONYM dbo.SecondDatabaseThirdTable
IF Object_Id('dbo.SecondDatabaseSecondView', 'SN') IS NOT null
drop SYNONYM dbo.SecondDatabaseSecondView
/*-- end of Cleanup script --*/
/*-- start of the build script --*/
USE TheFirstDatabase; --we switch to the 'TheFirstDatabase' database
GO
CREATE TABLE dbo.TheFirstTable (TheFirstColumn INT);
GO
CREATE TABLE dbo.TheSecondTable
(
TheFirstColumn INT IDENTITY NOT NULL,
CONSTRAINT pk_TheFirstTable_TheFirstColumn PRIMARY KEY CLUSTERED
(TheFirstColumn),
TheSecondColumn int NOT null
);
GO
--build the view 'TheFirstView'
--this is the 'stub' that we can use to prevent errors
IF Object_Id('tempdb..#dummy') IS NOT NULL SET NOEXEC ON
CREATE table #dummy
(TheFirstColumn int,TheSecondColumn INT)
GO
SET NOEXEC off
-- now we deal with the objects that have cross-server references
CREATE synonym SecondDatabaseThirdTable FOR #dummy
go
Create VIEW dbo.TheFirstView
AS
SELECT TheSecondColumn FROM SecondDatabaseThirdTable;
GO
drop synonym SecondDatabaseThirdTable
create synonym SecondDatabaseThirdTable
FOR Aristobulus.TheSecondDatabase.dbo.TheThirdTable
--end of the build of the view 'TheFirstView'
--build the view ThefourthView
IF Object_Id('tempdb..#dummy') IS NOT NULL SET NOEXEC ON
CREATE table #dummy
(TheFirstColumn int,TheSecondColumn INT)
GO
SET NOEXEC OFF
CREATE synonym SecondDatabaseSecondView FOR #dummy
GO
CREATE VIEW ThefourthView AS
SELECT ThefirstColumn FROM SecondDatabaseSecondView;
GO
drop synonym SecondDatabaseSecondView
CREATE synonym SecondDatabaseSecondView
FOR Aristobulus.TheSecondDatabase.dbo.TheSecondView
--end of the build of the view 'TheFourthView'
DROP TABLE #dummy
|
Listing 3: Build script for TheFirstDatabase, with cross-server dependencies
At the start, we couldn't be sure that TheSecondDatabase was there, so we create a local stub, called 'dummy', on TheFirstDatabase that returns the columns referenced by its two views, which would otherwise require the remote database. The name of the local stub object doesn't have to match anything, so we use the name 'dummy' to emphasize why we're doing it. Using the dummy 'stub' as the base object each time, we create synonyms for each of the remote objects referenced by the views in this database (TheFirstView and TheFourthView).
We then build each of these views, using its synonyms for the remote reference. SQL Server checks the existence of the column(s) using the underlaying 'dummy' data source. If it finds the correct parameter name or column name (it does not check the datatype), it is satisfied, and the views build successfully. Once each object is successfully built, we can delete its dummy synonym and create a new one with the same name but the full, 4-part, cross-server reference. This, fortunately, isn't checked at this stage, so this sleight-of-hand isn't detected until we've ensured that the linked server references are all set up and checked.
Here is the second script that builds TheSecondDatabase, on the server Aristobulus, which works in the same fashion.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
/*-- start of Cleanup script to ensure that we start
with an empty database --*/
USE TheSecondDatabase;
IF Object_Id('dbo.TheThirdTable') IS NOT NULL
DROP TABLE dbo.TheThirdTable;
IF Object_Id('dbo.TheSecondView') IS NOT NULL
DROP VIEW dbo.TheSecondView;
IF Object_Id('dbo.TheThirdView') IS NOT NULL
DROP VIEW dbo.TheThirdView;
IF Object_Id('dbo.FirstDatabaseSecondTable', 'SN') IS NOT null
drop SYNONYM dbo.FirstDatabaseSecondTable
IF Object_Id('dbo.FirstDatabaseFirstTable', 'SN') IS NOT null
drop SYNONYM dbo.FirstDatabaseFirstTable
/*-- end of Cleanup script --*/
/*-- start of the build script --*/
--build script for TheSecondDatabase
USE TheSecondDatabase;--we switch to the 'TheSecondDatabase' database
GO
CREATE TABLE dbo.TheThirdTable
(
TheFirstColumn INT IDENTITY NOT NULL,
CONSTRAINT pk_TheThirdTable_TheSecondColumn PRIMARY KEY CLUSTERED
(TheFirstColumn),
TheSecondColumn int NOT null
);
GO
IF Object_Id('tempdb..#dummy') IS NOT NULL SET NOEXEC ON
CREATE table #dummy
(TheFirstColumn int,TheSecondColumn INT)
GO
SET NOEXEC OFF
create synonym FirstDatabaseSecondTable FOR #dummy
go
CREATE VIEW dbo.TheSecondView
AS
SELECT TheFirstColumn FROM FirstDatabaseSecondTable;
GO
drop synonym FirstDatabaseSecondTable
create synonym FirstDatabaseSecondTable
FOR Phasael.TheFirstDatabase.dbo.TheSecondTable
IF Object_Id('tempdb..#dummy') IS NOT NULL SET NOEXEC ON
CREATE table #dummy
(TheFirstColumn int,TheSecondColumn INT)
GO
SET NOEXEC off
create synonym FirstDatabaseFirstTable FOR #dummy
CREATE VIEW dbo.TheThirdView
AS
SELECT TheFirstColumn FROM FirstDatabaseFirstTable;
GO
drop synonym FirstDatabaseFirstTable
create synonym FirstDatabaseFirstTable
FOR Phasael.TheFirstDatabase.dbo.TheFirstTable
|
Listing 4: Build script for TheSecondDatabase, with cross-server dependencies
These two databases should now have been successfully built. You now need to verify them by first checking that there is a linked server on the instance for every remote database reference, and that it has the referenced database(s) with the referenced object(s). You can do this in SSMS.
Automated builds with cross-server dependencies using SQL Change Automation
Now we'll stop cheating and try to incorporate these techniques for coping with cross-server dependencies into an automated build system for doing CI. This must allow developers to update individual objects and add new functionality whilst preserving the existing data. When this essential upgrade process is practiced and tested throughout the deployment process, it can be used in staging and release to production with more confidence
We still have two databases on two servers, and we want to be able to develop them independently, and build them independently, whether to build a new version from scratch, or update an existing version of the database. We need to be able to develop and build each database from object-level scripts. Unfortunately, we can't use the technique I've illustrated above because these batches are designed to be simply executed to build the database. A standard build server will just execute every object-level script in the directory, in the sequence specified by an ordered list.
SQL Change Automation is not a straightforward build server; it uses the SQL Compare engine to do the builds, and SQL Compare doesn't use the source code that you have in source control directly. It uses the collection of scripts to create a 'model' of the database, and then compares this model to and the target database and devises a script that migrates the target database to the version represented by the 'model'. So, a build (from scratch) is simply a comparison to an empty target database. You get an entire build script, but it isn't just the individual object files concatenated. The problem for us is that our entire narrative of clever changes to synonyms and temporary stubs is stripped out because it is irrelevant to a synchronization script. You may have all sorts of migration devices in the source file, in addition to the database objects, just as I've demonstrated in the previous listings, but they won't be used.
So how do we get it all to work?
The object source scripts
In our example, each database has its conventional object-level SQL script files: 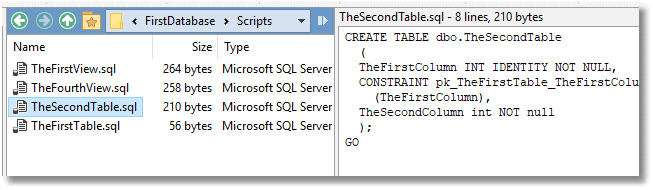
Figure 2: The build script for a table
The build scripts for the views that reference remote objects make conventional use of synonyms, just as demonstrated in Listing 2. As this is a simple demo, I've not done separate files for each Synonym, but included them with the build scripts:
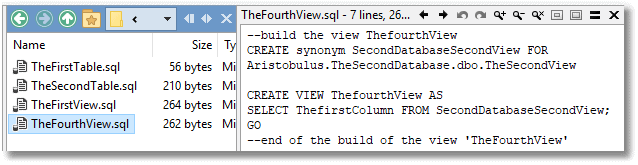
Figure 3: The build script for synonym and a view
The pre-build "stubchecks"
Each of our synonyms must, at build time, be able to reference a valid object of the correct name. For example, in order to build TheFourthView, in TheFirstDatabase, we'll need at least a 'stub' in place for TheSecondView, in the TheSecondDatabase, which will return TheFirstColumn. This stub is enough to convince SQL Server that the correct reference exists even though the stub doesn't do anything.
In short, any object that is the target of a remote reference (from Figure 1, this is all the tables plus TheSecondView) will need to have at least stubs in place, before we do any build operation with SQL Change Automation (or SQL Compare). Therefore, each database includes a script (I've called it StubCheck) that is run before any genuine building is done and checks for the existence of each of its objects that are referenced externally or is likely to be so. If a referenced object does not exist on the database, it creates a stub for it. When the SQL Change Automation build process starts, the SQL Compare or SCA changes the skeletal form of the database into the real database.
We need a StubCheck script for each participating database, and each one is hand-cut and modified whenever the interface changes. Listing 5 shows the StubCheck for TheFirstDatabase.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
/*Script to check that there are at least stubs for all objects that
are referenced by other databases, local or remote, via linked servers
This is maintained as part of the interface definition.
Note that the conditions, if true, prevent the following code from
being executed until a SET NOEXEC OFF is found, at which point it
starts executing again */
SET NOEXEC OFF
IF Object_Id('dbo.TheSecondTable','U') IS NOT NULL SET NOEXEC ON
go
CREATE TABLE dbo.TheSecondTable
(
TheFirstColumn int
);
GO
IF Object_Id('dbo.TheFirstTable','U') IS NOT NULL SET NOEXEC ON
go
CREATE TABLE dbo.TheFirstTable
(
TheFirstColumn int
);
GO
|
Listing 5: StubCheck script for TheFirstDatabase
Figure 4 shows the StubCheck for TheSecondDatabase. I've saved it in the PreScripts folder, and there is no harm to them being re-run, but it is not an official pre-script (which must be called PreScript.sql). SQL Change Automation will only ever run one of these per build operation, and we need run each stubcheck script manually, for every database, before we start the build
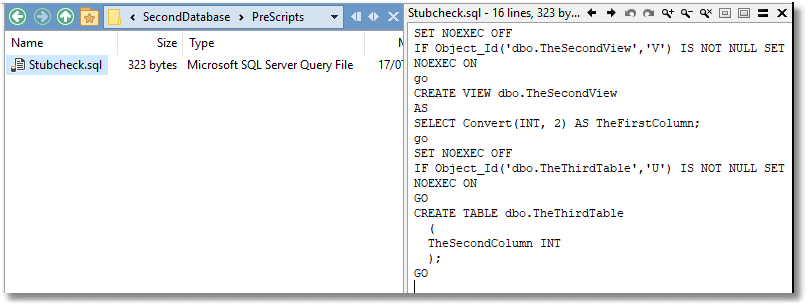
Figure 4: StubCheck script for TheSecondDatabase
If no server instance is available to do provide references, you can have a local database with stubs on it, and alter the synonyms accordingly, but you will need to change the synonyms when you deploy the database to its intended location. As long as you can compile the routines (procedures and views) without error, and you can have the synonyms in place, that's OK. You just change the synonym when it comes to provisioning the database. If you need to run tests before provisioning, then you would need to change the synonym to point to a 'mock' database that can perform what functionality is required for the test.
The PowerShell Build Script
So, we have everything in place, and can build all the contributing databases. This PowerShell code can be modified to work on just one database, but it must still do a pre-build check that the stubs exist on all the databases.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
cls
<# this is the list of participating databases, all of which have a source directory and a stub-check script. I have used connection strings for this demonstration though this would never be appropriate in reality. I've shown in previous scripts how to do this securely (it complicates the code for publication)#>
$targetsAndSources=(
@{'connection'= 'Server=Phasael;Database=TheFirstDatabase;User Id=Phil;Password=P@88w09d;Persist Security Info=False';
'source'= 'C:\MyPathToTheFirstDatabase\scripts';
'preliminaryCheck'= 'C:\MyPathToTheFirstDatabase\PreScripts\stubCheck.sql'},
@{'connection'='Server=Aristobulus;Database=TheSecondDatabase;User Id=Phil;Password=P@88w09d;Persist Security Info=False';
'source'='C:\MyPathToTheSecondDatabase\scripts';
'preliminaryCheck'= 'C:\MyPathToTheSecondDatabase\PreScripts\stubCheck.sql'}
)
$targetsAndSources|foreach {
<# pre-build check that the referenced objects exist in the participating objects so when other databases are built, the references appear to SQL Server to be legitimate. #>
$csb = New-Object System.Data.Common.DbConnectionStringBuilder
$csb.set_ConnectionString($_.connection)
Write-Output "executing stub-check on $($csb.'Server').$($csb.'Database') "
if ($csb.'user id' -ne '')
{sqlcmd -S $csb.'Server' -d $csb.'Database' -j -P $csb.'Password' -U $csb.'User ID' -i "$($_.PreliminaryCheck)"}
else
{sqlcmd -S $csb.'Server' -d $csb.'Database' -j -E -i "$($_.PreliminaryCheck)"}
}
$ReleaseArtifacts=@()
$targetsAndSources|foreach {
<# Now we acctually build or update each target. #>
$iReleaseArtifact=new-DatabaseReleaseArtifact `
-Source $_.source `
-Target $_.connection `
-AbortOnWarningLevel None
Use-DatabaseReleaseArtifact -InputObject $iReleaseArtifact -DeployTo $_.connection
$ReleaseArtifacts+=$iReleaseArtifact
}
$ii=0;
<# report on the success of the build of each database in a local browser, including the script used and the code analysis #>
$ReleaseArtifacts| foreach {$ii++;
$reportfile="$env:TEMP\changes$($ii).html";
$_.ReportHtml> $reportfile
Start $reportfile
}
|
Listing 6: SCA PowerShell script for building databases with cross-server dependencies
This arrangement can be defeated if you are updating existing databases, and two different databases change their interfaces in one revision when there are mutual dependencies. Updating the stubs won't help. The answer, of course is to not do it, but if you do, then change the Stubcheck for that build to alter the new referenced object if it already exists. Or to start with an empty database for both participants in the mutual dependency.
Conclusion
If your database makes references, and therefore has dependencies, outside the database then any complications in building or updating databases can be overcome by means of stubs, mocks and synonyms. They don't, and shouldn't, box you into any architecture or build method. The only requirements are a cool head and an understanding of the significance of build errors when they happen. The use of linked servers can be tiresome at the setting-up stage, especially if you are using ODBC providers that are flawed in any way. However, they proved an excellent way of allowing SQL Server to coexist with databases of different types and brands in the one system.
Tools in this post
You may also like

Article
Database Build Blockers: Mutually Dependent Databases
Phil Factor demonstrates a clever way to create 'stub' objects, in SQL Change Automation pre-deployment scripts, in order to overcome the problems caused by 'missing objects' when building databases that have circular, or mutual, dependencies. In the subsequent deployment, SQL Change Automation fully builds every object in each of the databases, so all dependencies are fully tested.
Article
Dealing with production database drift
For the SQL Change Automation team, it’s important that we take time out from development, occasionally, to explore some of the issues our customers face when automating database deployment. Following on from previous posts about cross-database and cross-server dependencies, this article shares some of our thoughts about how to deal with production database drift. If you’re using automated deployment for your databases, direct changes to your production environment can cause a headache. These unmanaged changes are known as database drift. To better understand the issues this can cause, our team created a test application we could work with; this was a
Article
Moving from application automation to true DevOps by including the database
This article explains the challenges of DevOps automation for databases, starting with how to manage the database, as a set of SQL scripts, in the version control system, and then how to start building an integrated and automated script pipeline for continuously testing and deploying database schema changes, alongside the application code.
Article
Integrating SQL Server Tools into SQL Change Automation Deployments
Phil Factor shows how to integrate use of SQL Change Automation, SSMS registered servers, SMO, and BCP to automatically build or update a database on all servers in a group.

Article
SQL Code Analysis from a PowerShell Deployment Script
This article shows how to define SQL code analysis rules using SQL Prompt and them run them automatically from a PowerShell script, displaying the detected code issues in a handy HTML report.

Article
Database Delivery with Docker and SQL Change Automation
Phil Factor demonstrates how to integrate SQL Change Automation into containerized workflows, such as are typical of a microservices architecture. He shows how to automate database builds into a Linux SQL Server container running on Windows, and then backup the containerized database and restore it into dedicated containerized development copies for each developer and tester.
Loading comments...