




Dealing with production database drift
For the SQL Change Automation team, it's important that we take time out from development, occasionally, to explore some of the issues our customers face when automating database deployment. Following on from previous posts about cross-database and cross-server dependencies, this article shares some of our thoughts about how to deal with production database drift.
If you’re using automated deployment for your databases, direct changes to your production environment can cause a headache. These unmanaged changes are known as database drift.
To better understand the issues this can cause, our team created a test application we could work with; this was a system for a fictional company called Lightning Works. We used SQL Change Automation and Octopus Deploy to deploy two databases, a website, and associated services. The two databases were our Foreign Exchange database, Forex, and the LightningWorks database used to hold the application data.
The problem with production database drift occurred when someone added an index directly to a production database. I was making some changes to the GetLatestExchangeRate stored procedure in the Forex database. I checked my changes into SQL Source Control and then deployed them to the Quality Assurance (QA) environment. Using SQL Change Automation, the QA database is made to look exactly like the database in source control. This is done to ensure full knowledge of what the database will look like after deployment. The deployment to QA was successful.
I then tried to deploy to our production environment. Because we use SQL Change Automation in our deployment process, I could review the script that would run on the production database if I continued with the deployment. But when I looked at the script, I noticed there was a change to a table that I hadn’t touched. Someone had added an index to the ExchangeRate table in the production database.
I wanted to keep this change because querying had become slow and adding an index had improved performance. But because this index was not checked into source control, it would be dropped as part of my deployment.
The SQL Change Automation change report showed that the ExchangeRate table had been modified, even though I had only made a change to the GetLatestExchangeRate stored procedure:

Expanding the ExchangeRate table modification in the report showed the index being deleted as part of my deployment. The relevant sections of the change script are prefixed with minus signs and highlighted in red:
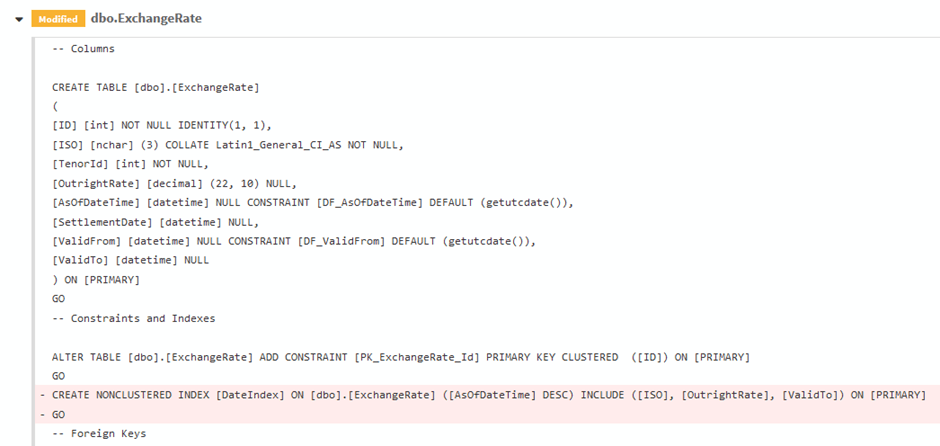
So I asked around my team to find out who had made this change and discovered it was Peter. We got together to try to solve the problem. We quickly realised that we needed to add the new index into source control. To do this, we grabbed the script that Peter had run on the production database, and executed it on my development database. This was checked into source control and then deployed to both the QA and production environments. This time when I deployed, the index was left alone. We can see this in the change report, which no longer has the ExchangeRate table marked as being modified:

This solved our problem. But this process of looking out for production drift and then getting the change into source control was error prone and inefficient. How could we stop this from happening again? We came up with two ideas:
- Install DLM Dashboard to monitor any changes to our production database
- Lock down permissions so only SQL Change Automation is allowed to make changes to the production database
Having DLM Dashboard installed would have been useful because it would have notified the team as soon as Peter had made his change to the production database. This would have prompted me to sort out the problem before I even tried to make a database deployment. For example, the production drift would have been flagged up on the DLM Dashboard homepage:
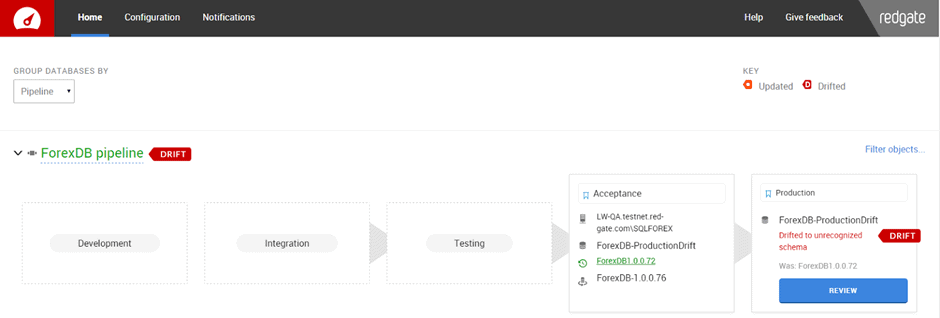
By clicking the Review button, we could have reviewed this change in the associated drift report:
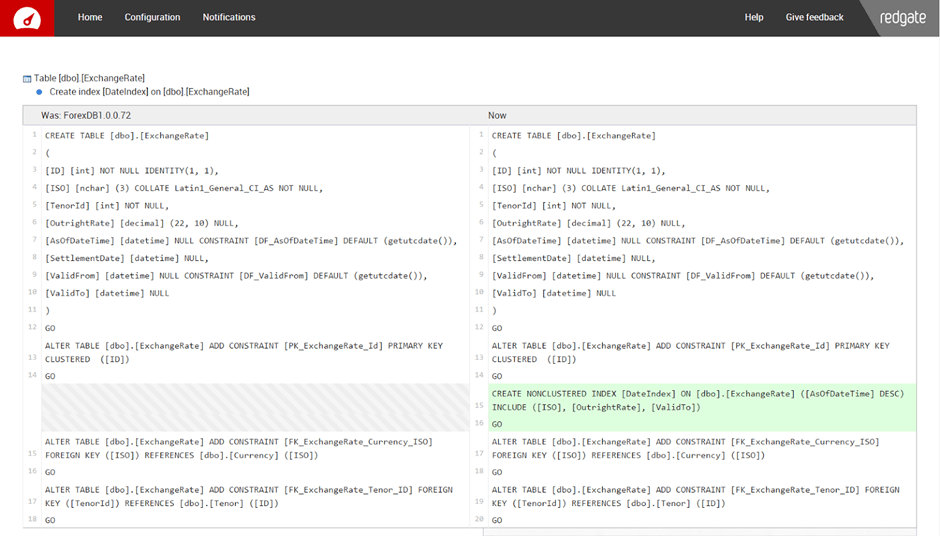
So DLM Dashboard would have helped us to spot this problem. But it wouldn’t stop people making direct changes to the production database in the first place. In order to do this, I wanted to lock down permissions.
However, Peter wasn’t convinced initially. He felt that being able to make changes directly to the production database was useful. For example, in this case the performance issue was only on the production database. However, I showed him that he could reproduce the problem and fix it on his development database. This would then be checked into source control and deployed to the production environment as part of the automated process.
Eventually we agreed this was a better solution for us, and locked down the permissions. This would make sure that all changes first go through testing and QA, and only then to the production environment.
To achieve this, we created a SQL Change Automation Windows user. Our Windows user was associated with a corresponding SQL Server user on the production server and databases. Only this user could modify the schema. Now, when Peter, or anyone else, wants to make a change to the production database, it must be checked into source control and go through the standard deployment procedure.
All in all, locking down the permissions on your production server would seem to be the best way to go. This prevents direct changes to your production database. No changes will be lost because they must be checked into source control and go through the automated deployment process. If emergency access is required to the production database, then consider using a ticketed procedure that logs exactly when and why permissions were elevated, and when they were revoked. Also, consider using DLM Dashboard to give you a heads-up on when these changes are made.
How do you deal with changes made directly to your production databases? Please share your methods in the comments section below.
Tools in this post
You may also like

Article
Build and fill a database using JSON and SQL Change Automation
Phil Factor demonstrates how to export data from a database, as JSON files, validate it using JSON Schema, then build a fresh development copy of the database using SQL Change Automation, and import all the test data from the JSON files.
Article
Database DevOps for Pragmatists: A Datafaction Case Study
Ami Adler, a Software Development Manager at Datafaction explains how they used Redgate tools, and others, to introduce automation and testing into their Database DevOps processes and so achieved a faster and more reliable deployment process for their application.

Article
Deploying cross-database dependencies to different environments
The SQL Change Automation team here at Redgate occasionally take time out from development to explore some of the issues our customers face when automating deployment of database changes. As part of one such exercise, we took a closer look at cross-database and cross-server dependencies – these can cause problems when deploying databases to multiple environments which might be configured differently. To better understand the issues, we created a test application we could work with; this was a system for a fictional company called Lightning Works. We used SQL Change Automation and Octopus Deploy to deploy two databases, a website, and
Article
Integrating SQL Server Tools into SQL Change Automation Deployments
Phil Factor shows how to integrate use of SQL Change Automation, SSMS registered servers, SMO, and BCP to automatically build or update a database on all servers in a group.

Article
Using Filters to Fine-tune Redgate Database Deployments
Filters are used by Redgate's SQL Compare, SQL Source Control, DLM Dashboard, and SQL Change Automation. A typical use for a filter is to work on just one schema within a database or just a limited set of tables and routines. You would also want to use a filter to exclude certain object, such as database users, from comparisons. Phil Factor explains how they work, and how to create, edit and then use them within the various Redgate tools.
Article
Running Linux SQL Server as a Container
Phil Factor starts a series of articles that will demonstrate the use of temporary SQL Server instances, running in Linux containers, into which we can deploy the latest database build, stocked with data, for development and testing work. This initial article shows how to set up a SQL Server instance inside a Linux Docker container, create some sample databases, and persist data locally.
Loading comments...