





Unlocking the value of frequent database deployments
Since the release of the State of DevOps report by Puppet Labs ten years ago, various organizations have looked at how we could build better software. The generally agreed finding is the need to deliver more value to our customers, and how we can make the delivery of that value as smooth as possible.
Interestingly, the database has mostly been ignored in State of DevOps reports. Redgate created the State of Database DevOps report in 2017 in order to address this gap and get the relevant information out there. And in 2018 the DORA’s Accelerate State of DevOps report was the first to acknowledge the database as a key technical practice which can drive high performance in DevOps. Gene Kim discusses the absence of the database in earlier reports in this webinar.
For Redgate’s State of Database DevOps report, this year saw over 2000 participants from all over the world, of all different sectors, roles, and different stages of their DevOps journeys. The findings from this report were able to give us an insight into the state of database development and how that might relate to DevOps.
One of the key findings has helped us understand where frequent deployments come into play and how this can help organizations produce more value from their software:
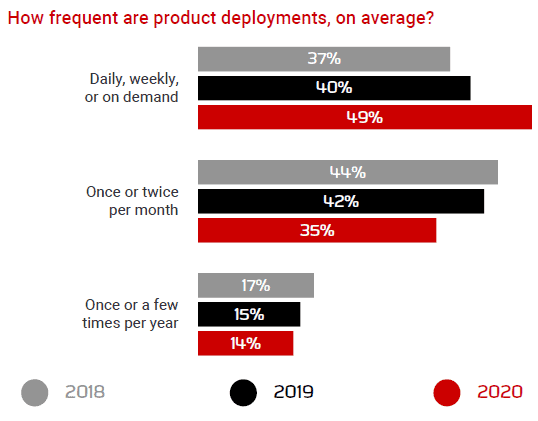
We can see from this graph that the frequency of deployments is increasing. More organizations are seeing the value of shorter release cycles. That isn’t to say that deployments have to take place daily or every week, rather that you should be able to deploy when you need to, on demand.
The biggest concern we see about increasing the frequency of deployments is the rise in risk. How can frequent releases improve the quality of the code? With testing, we often find this is delayed until we get near the end of the development process, which means it is crunched and not done as well as we would like, resulting in poor quality code. Operations are rightly going to be concerned that by releasing more frequently we will have more of the same issues in our systems. What we find in DevOps is the opposite thing.
It’s not a question of releasing those same deployments more frequently. Instead, with a low cycle time, there is less risk involved because there are fewer changes, and a smaller batch size. If we wait longer, the changes stack up to a deployment with a higher risk.
Microsoft is a good example. Visual Studio historically released once a year, or once every few years. The cycle time was large, meaning the number of changes was huge. Bugs would be apparent upon release almost immediately. Service packs to patch the system would not be released for months after, resulting in customers having to live with those bugs for months at a time. Now, we see Visual Studio updates more often, including database software updates, and monthly or bi-monthly patches with a far lower risk of bugs.
When working on a large deployment it’s hard to be agile or adjust what you’re working on. If you are making small, incremental, changes every week or every two weeks, adjusting priorities or changing focus becomes easier to line it up for the next release. Working in this agile way, software developers use tools like Agile, Lean, and Kanban, and database developers are starting to do the same. DevOps asks us to work in these small batches with short cycle times, and then refocus as needed.
Adapting what those changes include can also improve the maintenance of the code. Firstly, only making additive changes to software, and not deleting things where possible. This doesn’t mean avoiding clean-up, but in general, we want the changes made to be backwards-compatible, easily made changes that won’t interrupt the workflow. When it does come to clean up, by spreading the complexity out across multiple deployments over time, each one is a low risk operation and if there is an issue, it can be recovered from quickly.
Finding and fixing bugs are a source or pain for both developers and customers. Fixing those defects requires resources and time. The longer we spend fixing bugs, the more time is spent on rework, instead of value-added work.
The vast majority of developers are not good at reviewing huge amounts of code, things can get missed, focus is lost. Smaller deployments do help with this because we simply have less code to physically look at, and we are more likely to catch the defect.
Keeping releases frequent also ensures we have a better understanding of what is happening with that code, and the idea behind it. Meaning we can identify and find the fix quickly, ensuring customers deal with bugs for less amount of time. It’s harder to get into the mindset of code written two months ago as part of a larger release.
In the 2020 State of Database DevOps report, only 47% of those who say they deploy weekly or more frequently say they are using version control for the database. In other words, the majority of those deploying database changes frequently are making changes to the databases directly, and not storing those changes in version control.
The graph below indicates that those deploying database changes weekly or more frequently who do use version control for database code are more likely to report that 1% or less of deployments contain defects that require hotfixes. Those who do not use version control are notably more likely to report that more than 10% of deployments contain defects that require hotfixes.
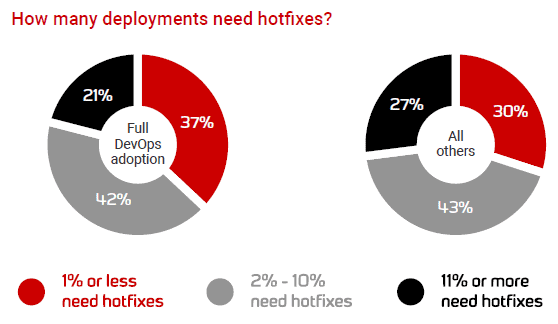
It’s worth emphasizing here that every percentage change increases the efficiency a great deal, because it means we’re not spending time on rework, we’re spending it on value, on new things that need to be done. Enhancements, improvements, and brand-new features. As we move to a DevOps process with smaller batch sizes and the agility to adapt to a changing environment, we find less hotfixes are required. Ultimately, delivering more value for our organizations.
To try and unlock more value from software means we must get more value work done, and we can do that really in two ways. One is by reducing rework, and the other is getting quicker feedback on our changes, which helps us focus in on things we want to do.
Releasing every week doesn’t mean spending only a week on that release. It could be three or four weeks, but in the meantime there’s other work that is getting released. As teams scale, there may be multi-week cycles, but that deployment is done with correct modelling, and with efficiently written code that tests well and adheres to standards so they can be released quickly. We want to follow all the best practices we can both on the application and the database side.
If you’re interested in speaking with Redgate about your DevOps initiative, get in touch now.
To find out more about unlocking the value of frequent database deployments, you might also like to watch the Redgate webinar hosted by Steve Jones which formed the basis for this article.
You may also like

Blog
Redgate Flyway’s Product Updates – March 2026

Blog